Spring 5 的主要特点是对响应式编程的支持,包括 Spring WebFlux,这是一个全新的响应式 web 框架,它借鉴了 Spring MVC 的编程模型,允许开发人员创建可更好地扩展和使用更少线程的 web 应用程序。
第一部分 Spring 基础
第一章中,快速概述 Spring 和 Spring Boot 的要点,并展示如何在 Taco Cloud 上初始化第一个 Spring 项目。
第二章中,深入研究 Spring MVC,并了解如何在浏览器中呈现模型数据以及如何处理并验证表单输入,还将获得选择视图模板库的一些提示。
第三章中,将在 Taco Cloud 应用程序中添加数据持久性,我们将介绍使用 Spring 的 JDBC 模板,如何插入数据以及如何使用 Spring Data 声明 JPA 存储库。
第四章中,介绍了 Spring 应用程序的安全性,包括自动配置 Spring Security,定义自定义用户存储,自定义登录页面并防止跨站点请求伪造(CSRF)攻击。
第五章中,介绍配置属性,将学习如何微调自动配置的 bean 和应用配置属性到应用程序组件,并与 Spring 的 profile 文件一起使用。
第 1 章 Spring 入门
本章内容:
- Spring 和 Spring Boot 概述
- 初始化一个 Spring 项目
- 纵览 Spring
什么是 Spring?
Spring 的核心是一个容器,通常称为 Spring 应用程序上下文,用于创建和管理应用程序组件。
将 bean 连接在一起的行为是基于一种称为依赖注入(DI)的模式。容器创建和维护所有组件,并将这些组件注入需要它们的 bean。通常通过构造函数参数或属性访问器方法完成此操作。
基于 XML 文件配置
1 | <bean id="inventoryService" class="com.example.InventoryService" /> |
基于 Java 的配置
1 |
|
@Configuration注解表明这是一个配置类,它将为 Spring 应用程序上下文提供 beans。- 带有
@Bean注解的类方法,指示返回的对象作为 beans 添加到应用程序上下文中(默认情况下,它们各自的 bean IDs 将与定义它们的方法的名称相同)。
仅当 Spring 无法自动配置组件时,才需要使用 Java 或 XML 进行显式配置。
自动配置起源于 Spring 技术,即 自动装配 和 组件扫描。
- 借助组件扫描,Spring 可以自动从应用程序的类路径中发现组件,并将其创建为 Spring 应用程序上下文中的 bean。
- 通过自动装配,Spring 会自动将组件与它们依赖的其他 bean 一起注入。
Spring Boot 相对于 Spring 框架提供的最著名的增强功能是 自动配置,在这种配置中,Spring Boot 可以根据类路径中的条目、环境变量和其他因素,合理地猜测需要配置哪些组件,并将它们连接在一起。
初始化 Spring 应用程序
Spring Initializr 既是一个基于浏览器的 Web 应用程序,又是一个 REST API,它们可以生成一个基本的 Spring 项目结构,可以使用所需的任何功能充实自己。 使用 Spring Initializr 的几种方法如下:
- 从 Web 应用程序 http://start.spring.io 创建
- 使用
curl命令从命令行创建 - 使用 Spring Boot 命令行接口从命令行创建
- 使用 Spring Tool Suite 创建一个新项目的时候
- 使用 IntelliJ IDEA 创建一个新项目的时候
- 使用 NetBeans 创建一个新项目的时候
使用 Spring Tool Suite 初始化 Spring 项目
转到 “文件” 菜单并选择 “新建”,然后选择 “Spring Starter Project”。

向导的第一页要求提供一些常规项目信息,例如项目名称、描述和其他基本信息。
选择要添加到项目中的依赖项。此时,可以单击完成以生成项目并将其添加到工作区。如果感到有点危险,请再次单击 “下一步”,以查看新的 starter 项目向导的最后一页。
默认情况下,新项目向导在 http://start.spring.io 上调用 Spring Initializr 以生成项目。
检查 Spring 项目结构
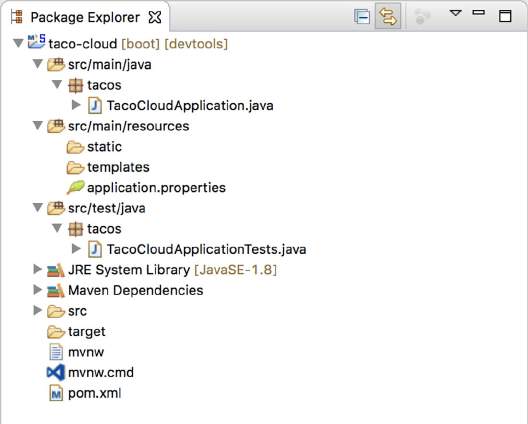
在该项目结构中,需要注意以下事项:
mvnw和mvnw.cmd—— 这些是 Maven 包装器脚本。即使你的计算机上没有安装 Maven,也可以使用这些脚本构建项目。pom.xml—— 这是 Maven 构建规范。TacoCloudApplication.java—— 这是引导项目的 Spring Boot 主类。application.properties—— 该文件最初为空,但提供了一个可以指定配置属性的地方。static—— 在此文件夹中,可以放置要提供给浏览器的任何静态内容(图像、样式表、JavaScript 等),最初为空。templates—— 在此文件夹中,放置用于向浏览器呈现内容的模板文件。最初为空,但很快会添加 Thymeleaf 模板。TacoCloudApplicationTests.java—— 这是一个简单的测试类,可确保成功加载 Spring 应用程序上下文。
探索构建规范
填写 Initializr 表单时,指定应使用 Maven 构建项目。因此,Spring Initializr 给了你一个 pom.xml 文件,该文件已经填充了你所做的选择。
1 |
|
<packaging> 元素将应用程序构建为可执行的 JAR 文件。Spring Initializr 默认为 JAR 打包。
<parent> 元素指定项目将 spring-boot-starter-parent 作为它的父 POM。
<dependencies> 元素下依赖项的特殊之处在于,它们本身通常没有任何库代码,而是间接地引入其他库。这些 starter 依赖提供了三个主要的好处:
- 构建的文件将会小得多,也更容易管理,因为不需要对每一个可能需要的库都声明一个依赖项。
- 可以根据它们提供的功能来考虑需要的依赖关系,而不是根据库名来考虑。
- 不用担心 library 版本问题。
最后,构建规范以 Spring Boot 插件结束。这个插件执行一些重要的功能:
- 提供了一个 Maven 编译目标,让你能够使用 Maven 运行应用程序。
- 确保所有的依赖库都包含在可执行的 JAR 文件中,并且在运行时类路径中可用。
- 在 JAR 文件中生成一个 manifest 文件,表示引导类(在本书例子中是
TacoCloudApplication)是可执行 JAR 的主类。
引导应用程序
1 | package tacos; |
@SpringBootApplication 注释表明这是一个 Spring 引导应用程序。@SpringBootApplication 是一个组合了其他三个注释的复合应用程序:
@SpringBootConfiguration—— 指定这个类为配置类。@EnableAutoConfiguration—— 启用 Spring 自动配置。@ComponentScan—— 启用组件扫描。这允许你声明其他带有@Component、@Controller、@Service等注释的类,以便让 Spring 自动发现它们并将它们注册为 Spring 应用程序上下文中的组件。
TacoCloudApplication 的另一个重要部分是 main() 方法。这个方法将在执行 JAR 文件时运行。在大多数情况下,这种方法是样板代码;编写的每个 Spring 引导应用程序都有一个类似或相同的方法(尽管类名不同)。
main() 方法调用 SpringApplication 类上的静态 run() 方法,该方法执行应用程序的实际引导,创建Spring 应用程序上下文。传递给 run() 方法的两个参数是一个配置类和命令行参数。虽然传递给 run() 的配置类不必与引导类相同,但这是最方便、最典型的选择。
测试应用程序
1 | package tacos; |
这个测试类执行了必要的检查,以确保 Spring 应用程序上下文能够成功加载。
@RunWith 是一个 JUnit 注释,提供了一个测试运行器来引导 JUnit 运行测试用例。在本例中,JUnit 被赋予了 SpringRunner,这是一个由 Spring 提供的测试运行程序,它提供了创建一个 Spring 应用程序上下文的功能,以供测试运行。
其他名字的测试运行器
SpringRunner 是 SpringJUnit4ClassRunner 的别名,它是在 Spring 4.3 中引入的,用于删除与特定版本的 JUnit (例如,JUnit4)的关联。
@SpringBootTest 告诉 JUnit 使用 Spring 引导功能引导测试。现在,把它看作是在 main() 方法中调用 SpringApplication.run() 的测试类就足够了。
编写 Spring 应用程序
在刚刚开始的时候,添加到 Taco Cloud 应用程序的第一个功能是主页。当你添加主页,你将创建两个代码构件:
- 一个处理主页请求的控制器类
- 一个视图模板,定义了主页的外观
处理 web 请求
Spring MVC 的核心是控制器的概念,这是一个处理请求并使用某种信息进行响应的类。对于面向浏览器的应用程序,控制器的响应方式是可选地填充模型数据并将请求传递给视图,以生成返回给浏览器的 HTML。
1 | package tacos; |
@Controller 的主要目的是将该类识别为组件扫描的组件。
home() 方法使用 @GetMapping 进行注释,如果接收到根路径 / 的 HTTP GET 请求,则此方法应该处理该请求。返回 home 的 String 值被解释为视图的逻辑名称。
模板名称由逻辑视图名称派生而来,它的前缀是 /templates/,后缀是 .html。模板的结果路径是 /templates/home.html。因此,需要将模板放在项目的 /src/main/resources/templates/home.html 中。
定义视图
1 |
|
<img> 标记使用一个 Thymeleaf 的 th:src 属性和一个 @{…} 表达式引用具有上下文相对路径的图片。除去这些,它只是一个 Hello World 页面。
该图片是通过上下文相对路径 /images/TacoCloud.png 进行引用的。
测试控制器
测试将对根路径 / 执行一个 HTTP GET 请求并期望得到一个成功的结果,其中视图名称为 home,结果内容包含短语 “Welcome to…”。
1 | package tacos; |
@WebMvcTest 注释是 Spring Boot 提供的一个特殊测试注释,它安排测试在 Spring MVC 应用程序的上下文中运行。测试类被注入了一个 MockMvc 对象中,以此用来测试来驱动模型。
testHomePage() 方法定义了要对主页执行的测试。它从 MockMvc 对象开始,执行针对 /(根路径)的 HTTP GET 请求。该请求规定了下列期望值:
- 响应应该有一个HTTP 200(OK)状态。
- 视图应该有一个合理主页名称。
- 呈现的视图应该包含 “Welcome to…”
构建并运行应用程序
现在应用程序已经启动,将 web 浏览器指向 http://localhost:8080(或单击 Spring Boot Dashboard 中地球仪样子的按钮),应该会看到类似图 1.8 所示的内容。
了解 Spring Boot DevTools
DevTools 为 Spring 开发人员提供了一些方便的开发同步工具。这些是:
- 当代码更改时自动重启应用程序
- 当以浏览器为目标的资源(如模板、JavaScript、样式表等)发生变化时,浏览器会自动刷新
- 自动禁用模板缓存
- 如果 H2 数据库正在使用,则在 H2 控制台中构建
DevTools 不是 IDE 插件。仅用于开发目的,在部署生产环境时禁用。
自动重启应用程序
当 DevTools 起作用时,应用程序被加载到 Java 虚拟机(JVM)中的两个单独的类加载器中。一个类装入器装入 Java 代码、属性文件以及项目的 src/main/path 中的几乎所有东西。这些项目可能会频繁更改。另一个类加载器加载了依赖库,它们不太可能经常更改。
当检测到更改时,DevTools 只重新加载包含项目代码的类加载器,并重新启动 Spring 应用程序上下文,但不影响其他类加载器和 JVM。
自动刷新浏览器和禁用模板缓存
默认情况下,模板选项(如 Thymeleaf 和 FreeMarker)被配置为缓存模板解析的结果,这样模板就不需要对它们所服务的每个请求进行修复。这在生产中非常有用,因为它可以带来一些性能上的好处。
但是,缓存的模板在开发时不是很好。DevTools 通过自动禁用所有模板缓存来解决这个问题。
在 H2 控制台中构建
如果选择使用 H2 数据库进行开发,DevTools 还将自动启用一个 H2 控制台,你可以从 web 浏览器访问该控制台。只需将 web 浏览器指向 http://localhost:8080/h2-console,就可以深入了解应用程序正在处理的数据。
回顾
以下是构建基于 Spring 的 Taco Cloud 应用程序的步骤:
- 使用 Spring Initializr 创建了一个初始项目结构。
- 写了一个控制器类来处理主页请求。
- 定义了一个视图模板来呈现主页。
- 写了一个简单的测试类来检验上诉工作。
为了理解 Spring 在做什么,让我们从构建规范开始。
在 pom.xml 文件中,声明了对 Web 和 Thymeleaf 启动器的依赖。这两个依赖关系带来了一些其他的依赖关系,包括:
- Spring MVC 框架
- 嵌入式 Tomcat
- Thymeleaf 和 Thymeleaf 布局方言
它还带来了 Spring Boot 的自动配置库。当应用程序启动时,Spring Boot 自动配置自动检测这些库并自动执行:
- 在 Spring 应用程序上下文中配置 bean 以启用 Spring MVC
- 将嵌入式 Tomcat 服务器配置在 Spring 应用程序上下文中
- 为使用 Thymeleaf 模板呈现 Spring MV C视图,配置了一个 Thymeleaf 视图解析器
简而言之,自动配置完成了所有繁重的工作,让你专注于编写实现应用程序功能的代码。
俯瞰 Spring 风景线
要了解 Spring 的风景线,只需查看完整版 Spring Initializr web 表单上的大量复选框列表即可。
Spring 核心框架
Spring 核心框架是 Spring 领域中其他一切的基础。它提供了核心容器和依赖注入框架。但它也提供了一些其他的基本特性。
其中包括 Spring MVC 和 Spring web 框架。已经了解了如何使用 Spring MVC 编写控制器类来处理 web 请求。但是,您还没有看到的是,Spring MVC 也可以用于创建产生非 HTML 输出的 REST API。
Spring 核心框架还提供了一些基本数据持久性支持,特别是基于模板的 JDBC 支持。
在 Spring 的最新版本(5.0.8)中,添加了对响应式编程的支持,包括一个新的响应式 web 框架 —— Spring WebFlux,它大量借鉴了 Spring MVC。
Spring Boot
Spring Boot 的好处包括启动依赖项和自动配置。还提供了一些其他有用的特性:
- Actuator 提供了对应用程序内部工作方式的运行时监控,包括端点、线程 dump 信息、应用程序健康状况和应用程序可用的环境属性。
- 灵活的环境属性规范。
- 在核心框架的测试辅助之外,还有额外的测试支持。
此外,Spring Boot 提供了一种基于 Groovy 脚本的替代编程模型,称为 Spring Boot CLI(命令行界面)。使用 Spring Boot CLI,可以将整个应用程序编写为 Groovy 脚本的集合,并从命令行运行它们。
Spring Data
Spring Data 提供了一些非常惊人的功能:将应用程序的数据存储库抽象为简单的 Java 接口,同时当定义方法用于如何驱动数据进行存储和检索的问题时,对方法使用了命名约定。
Spring Data 能够处理几种不同类型的数据库,包括关系型(JPA)、文档型(Mongo)、图型(Neo4j)等。
Spring Security
Spring Security 解决了广泛的应用程序安全性需求,包括身份验证、授权和 API 安全性。
Spring Integration 和 Spring Batch
Spring Integration 解决了实时集成,即数据在可用时进行处理。相反,Spring Batch 解决了批量集成的问题,允许在一段时间内收集数据,直到某个触发器(可能是一个时间触发器)发出信号,表示该处理一批数据了。
Spring Cloud
微服务是一个热门话题,解决了几个实际的开发和运行时问题。然而,在这样做的同时,他们也带来了自己的挑战。这些挑战都将由 Spring Cloud 直接面对,Spring Cloud 是一组用 Spring 开发云本地应用程序的项目。
小结
- Spring 的目标是让开发人员轻松应对挑战,比如创建 web 应用程序、使用数据库、保护应用程序和使用微服务。
- Spring Boot 构建在 Spring 之上,简化了依赖管理、自动配置和运行时监控,让 Spring 变得更加简单。
- Spring 应用程序可以使用 Spring Initializr 进行初始化,它是基于 web 的,并且在大多数 Java 开发环境中都支持它。
- 在 Spring 应用程序上下文中,组件(通常称为 bean)可以用 Java 或 XML 显式地声明,可以通过组件扫描进行发现,也可以用 Spring Boot 进行自动配置。
第 2 章 开发 Web 应用程序
本章内容:
- 在浏览器中展示模型数据
- 处理和验证表单输入
- 选择视图模板库
展示信息
在 Spring web 应用程序中,获取和处理数据是控制器的工作。视图的工作是将数据渲染成 HTML 并显示在浏览器中。将创建以下组件来支持 Taco 创建页面:
- 一个定义玉米卷成分特性的领域类
- 一个 Spring MVC 控制器类,它获取成分信息并将其传递给视图
- 一个视图模板,在用户的浏览器中呈现一个成分列表
建立域
应用程序的域是它所处理的主题领域 —— 影响应用程序理解的思想和概念。
在领域中,玉米饼配料是相当简单的对象。每一种都有一个名称和一个类型,这样就可以在视觉上对其进行分类(蛋白质、奶酪、酱汁等)。每一个都有一个 ID,通过这个 ID 可以轻松、明确地引用它。下面的成分类定义了需要的域对象。
1 | package tacos; |
这是一个普通的 Java 域类,定义了描述一个成分所需的三个属性。
创建控制器类
控制器是 Spring MVC 框架的主要参与者。它们的主要工作是处理 HTTP 请求,或者将请求传递给视图以呈现 HTML(浏览器显示),或者直接将数据写入响应体(RESTful)。
对于 Taco Cloud 应用程序,需要一个简单的控制器来执行以下操作:
- 处理请求路径为
/design的 HTTP GET 请求 - 构建成分列表
- 将请求和成分数据提交给视图模板,以 HTML 的形式呈现并发送给请求的 web 浏览器
下面的 DesignTacoController 类处理这些需求。
1 | package tacos.web; |
@Slf4j 是 Lombok 提供的注释,在运行时将自动生成类中的 SLF4J(Java 的简单日志门面,https://www.slf4j.org/)记录器。这个适当的注释具有与显式地在类中添加以下行相同的效果:
1 | private static final org.slf4j.Logger log = org.slf4j.LoggerFactory.getLogger(DesignTacoController.class); |
@Controller 注释用于将该类标识为控制器并将其标记为组件扫描的候选对象,以便 Spring 将发现该类并在 Spring 应用程序上下文中自动创建 DesignTacoController 实例作为 bean。
@RequestMapping 注释在类级应用时,指定该控制器处理的请求的类型。在本例中,它指定 DesignTacoController 将处理路径以 /design 开头的请求。
处理 GET 请求
类级别的 @RequestMapping 注释用于 showDesignForm() 方法时,可以用 @GetMapping 注释进行改进。@GetMapping 与类级别的 @RequestMapping 配对使用,指定何时接收 /design 的 HTTP GET 请求,showDesignForm() 将用来处理请求。
@GetMapping 是一个相对较新的注释,是在 Spring 4.3 中引入的。在 Spring 4.3 之前,可能使用了一个方法级别的 @RequestMapping 注释:
| 注释 | 描述 |
|---|---|
| @RequestMapping | 通用请求处理 |
| @GetMapping | 处理 HTTP GET 请求 |
| @PostMapping | 处理 HTTP POST 请求 |
| @PutMapping | 处理 HTTP PUT 请求 |
| @DeleteMapping | 处理 HTTP DELETE 请求 |
| @PatchMapping | 处理 HTTP PATCH 请求 |
一旦准备好了原料列表,接下来的几行 showDesignForm() 将根据原料类型过滤该列表。然后将成分类型列表作为属性添加到传递到 showDesignForm() 的 Model 对象。Model 是一个对象,它在控制器和负责呈现数据的视图之间传输数据。最后,放置在 Model 类属性中的数据被复制到 servlet 响应属性中,视图可以在其中找到它们。showDesignForm() 方法最后返回 “design”,这是将用于向浏览器呈现 Model 的视图的逻辑名称。
设计视图
下面的 <dependency> 条目使用了 Spring Boot 的 Thymeleaf starter,使 Thymeleaf 渲染要创建的视图:
1 | <dependency> |
在运行时,Spring Boot 自动配置将看到 Thymeleaf 位于类路径中,并将自动创建支持 Spring MVC 的 Thymeleaf 视图的 bean。
像 Thymeleaf 这样的视图库被设计成与任何特定的 web 框架解耦。因此,他们不知道 Spring 的模型抽象,并且无法处理控制器放置在模型中的数据。但是它们可以处理 servlet 请求属性。因此,在 Spring 将请求提交给视图之前,它将模型数据复制到请求属性中,而 Thymeleaf 和其他视图模板选项可以随时访问这些属性。
Thymeleaf 模板只是 HTML 与一些额外的元素属性,指导模板在渲染请求数据。例如,如果有一个请求属性,它的键是 “message”,你希望它被 Thymeleaf 渲染成一个 HTML <p> 标签,你可以在你的 Thymeleaf 模板中写以下内容:
1 | <p th:text="${message}">placeholder message</p> |
当模板被呈现为 HTML 时,<p> 元素的主体将被 servlet 请求属性的值替换,其键值为 “message”。th:text 是一个 Thymeleaf 的命名空间属性,用于需要执行替换的地方。${} 操作符告诉它使用请求属性的值(在本例中为 “message”)。
Thymeleaf 还提供了另一个属性 th:each,它遍历元素集合,为集合中的每个项目呈现一次 HTML。例如,要呈现 “wrap” 配料列表,可以使用以下 HTML 片段:
1 | <h3>Designate your wrap:</h3> |
在这里,我们在 <div> 标签中填充 th:each 属性,用来对发现于 wrap 请求属性中的集合中的每一个项目进行重复呈现。在每次迭代中,成分项都绑定到一个名为 ingredient 的 Thymeleaf 变量中。
在 <div> 元素内部,有一个复选框 <input> 元素和一个 <span> 元素,用于为复选框提供标签。复选框使用 Thymeleaf 的 th:value 元素,它将把 <iuput> 元素的 value 属性呈现为在成分 id 属性中找到的值。<span> 元素使用 th:text 属性把 “INGREDIENT” 占位符替换为成分 name 属性的值。
当使用实际的模型数据呈现时,这个 <div> 循环迭代一次可能是这样的:
1 | <div> |
最后,前面的 Thymeleaf 片段只是一个更大的 HTML 表单的一部分,通过它,玉米饼艺术家用户将提交他们美味的作品。完整的 Thymeleaf 模板(包括所有成分类型和表单)如下所示。
1 |
|
可以看到,对于每种类型的配料,都要重复 <div> 片段。还包括一个提交按钮和一个字段,用户可以在其中命名他们的创建。
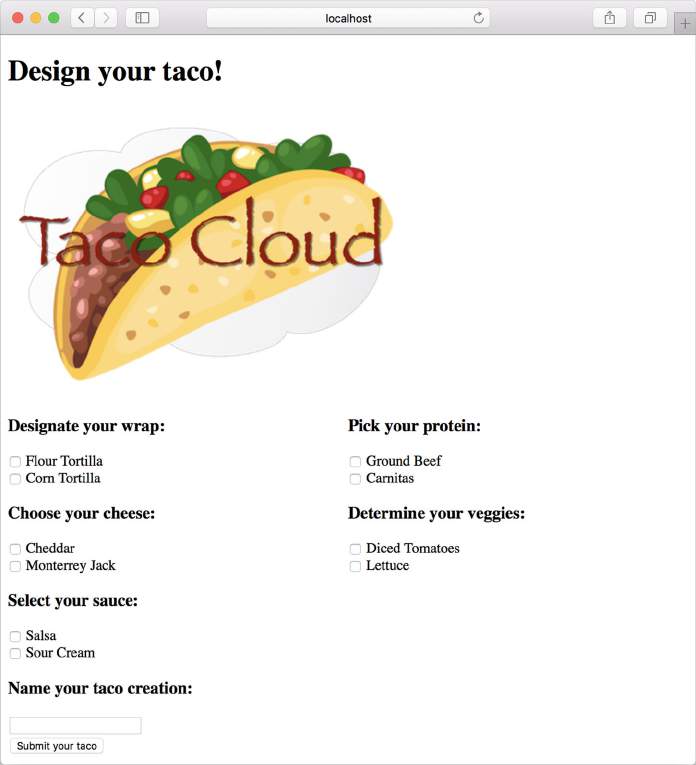
启动 Taco Cloud 应用程序使用浏览器访问 http://localhost:8080/design。应该看到类似图 2.2 的页面。
处理表单提交
<form> 标签的 method 属性被设置为 POST。而且,<form> 没有声明 action 属性。这意味着在提交表单时,浏览器将收集表单中的所有数据,并通过 HTTP POST 请求将其发送到服务器,发送到显示表单的 GET 请求的同一路径 —— /design 路径。
因此,需要在该 POST 请求的接收端上有一个控制器处理程序方法。
使用 @PostMapping 处理 POST 请求。
1 |
|
提交表单时,表单中的字段被绑定到 Taco 对象的属性,该对象作为参数传递给 processDesign()。
1 | package tacos; |
Taco 是一个简单的 Java 域对象,具有两个属性。
从 processDesign() 返回的值的前缀是 “redirect:”,表示这是一个重定向视图。更具体地说,它表明在 processDesign() 完成之后,用户的浏览器应该被重定向到相对路径 /order/current。
1 | package tacos.web; |
orderForm 视图由一个名为 orderForm.html 的 Thymeleaf 模板提供,如下面显示的。
1 |
|
<form> 元素指定了一个表单操作。指定表单应该提交到 /orders(使用 Thymeleaf 的 @{…} 操作符作为上下文相关路径)。
1 |
|
当调用 processOrder() 方法来处理提交的订单时,它将获得一个 order 对象,其属性绑定到提交的表单字段。
1 | package tacos; |
打开浏览器访问 http://localhost:8080/design,为你的玉米饼选择一些原料,然后点击 Submit Your Taco 按钮。应该会看到类似于图 2.3 所示的表单。
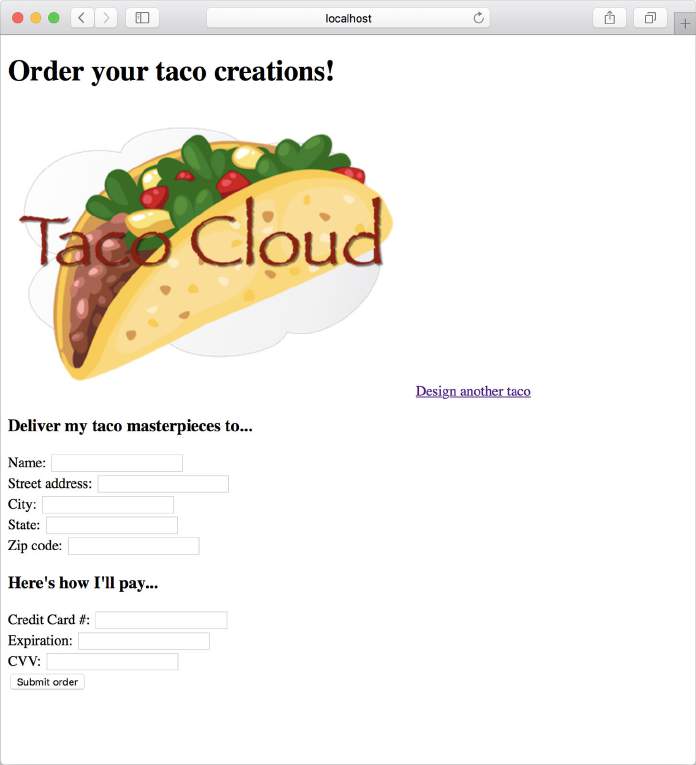
在表单中填写一些字段,然后按 Submit Order 按钮。日志条目看起来像这样(重新格式化以适应这个页面的宽度):
1 | Order submitted: Order(name=Craig Walls,street1=1234 7th Street, city=Somewhere, state=Who knows?, zip=zipzap, ccNumber=Who can guess?,ccExpiration=Some day, ccCVV=See-vee-vee) |
表单中的大多数字段包含的数据可能是不正确的。需要添加一些验证,以确保提供的数据至少与所需的信息类型相似。
验证表单输入
执行表单验证的一种方法是在 processDesign() 和 processOrder() 方法中加入一堆 if/then 块,检查每个字段以确保它满足适当的验证规则。但是这样做会很麻烦,并且难于阅读和调试。
Spring 支持 Java’s Bean Validation API(也称为 JSR-303;https://jcp.org/en/jsr/detail?id=303)。
- 对要验证的类声明验证规则:特别是 Taco 类。
- 指定验证应该在需要验证的控制器方法中执行,具体来说就是:DesignTacoController 的 processDesign() 方法和 OrderController 的 processOrder() 方法。
- 修改表单视图以显示验证错误。
声明验证规则
下面的程序清单显示了一个更新后的 Taco 类,它使用 @NotNull 和 @Size 来声明这些验证规则。
1 | package tacos; |
你会发现,除了要求 name 属性不为 null,同时你声明它应该有一个值是至少 5 个字符的长度。
下面程序清单列出了验证 Order 类所需要的改变。
1 | package tacos; |
对于地址的属性,只需要确保用户没有留下任何空白字段。对于这一点,将使用 Hibernate Validator 的 @NotBlank 注解。
支付领域的验证需要确保 ccNumber 属性不为空,还要确保它包含的是一个有效的信用卡号码的值。该 ccExpiration 属性必须符合 MM/YY(两位数的年/月)格式。而 ccCVV 属性必须是一个三位的数字。为了实现这种验证,需要使用一些其他的 Java Bean Validation API 注释,同时需要从 Hibernate Validator 集合中借用一些验证注解。
ccNumber 属性用 @CreditCardNumber 进行了注释。该注释声明属性的值必须是通过 Luhn 算法(https://en.wikipedia.org/wiki/Luhn_algorithm)检查过的有效信用卡号。这可以防止用户出错的数据和故意错误的数据,但不能保证信用卡号码实际上被分配到一个帐户,或该帐户可以用于交易。
没有现成的注释来验证 ccExpiration 属性的 MM/YY 格式。 @Pattern 注释提供了一个正则表达式,以确保属性值符合所需的格式。
@Digits 注释 ccCVV 属性,以确保值恰好包含三个数字。
所有的验证注释都包含一个消息属性,该属性定义了如果用户输入的信息不符合声明的验证规则的要求时将显示给用户的消息。
在表单绑定时执行验证
要验证提交的 Taco,需要将 Java Bean Validation API 的 @Valid 注释添加到 DesignTacoController 的 processDesign() 方法的 Taco 参数中。
1 |
|
@Valid 注解告诉 Spring MVC 在提交的 Taco 对象绑定到提交的表单数据之后,以及调用 processDesign() 方法之前,对提交的 Taco 对象执行验证。如果存在任何验证错误,这些错误的详细信息将在传递到 processDesign() 的错误对象中捕获。processDesign() 的前几行查询 Errors 对象,询问它的 hasErrors() 方法是否存在任何验证错误。如果有,该方法结束时不处理 Taco,并返回 “design” 视图名,以便重新显示表单。
1 |
|
在这两种情况下,如果没有验证错误,则允许该方法处理提交的数据。如果存在验证错误,则请求将被转发到表单视图,以便用户有机会纠正其错误。
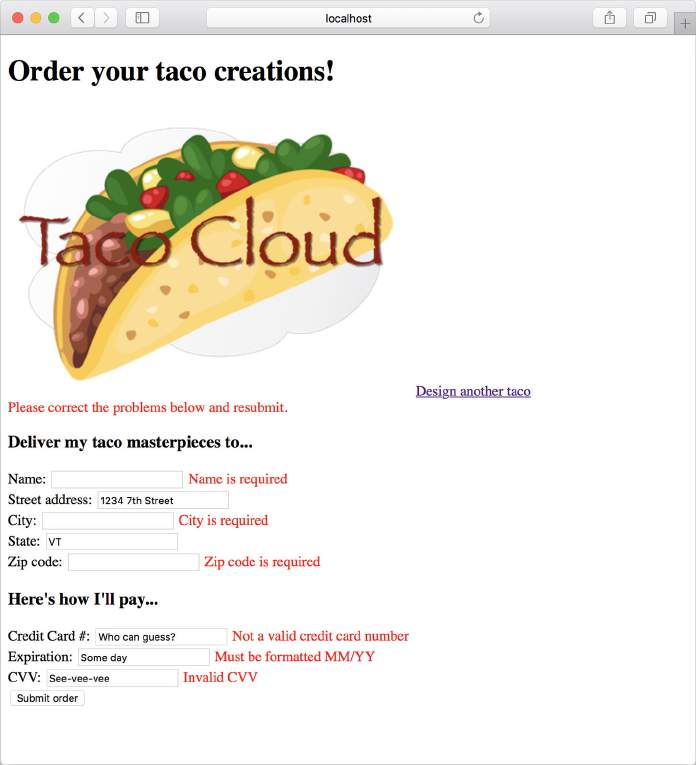
显示验证错误
Thymeleaf 通过 fields 属性及其 th:errors 属性提供了对 Errors 对象的便捷访问。例如,要在信用卡号字段上显示验证错误,可以添加一个 <span> 元素,该元素将这些错误引用用于订单模板,如下所示。
1 | <label for="ccNumber">Credit Card #: </label> |
除了可以用来设置错误样式以引起用户注意的 class 属性外,<span> 元素还使用 th:if 属性来决定是否显示 <span>。fields 属性的 hasErrors() 方法检查 ccNumber 字段中是否有任何错误。如果有错误,<span> 将被渲染。
th:errors 属性引用 ccNumber 字段,并且假设该字段存在错误,它将用验证消息替换 元素的占位符内容。
使用视图控制器
尽管每个控制器在应用程序的功能上都有不同的用途,但它们几乎都遵循相同的编程模型:
- 它们都用 @Controller 进行了注解,以表明它们是控制器类,应该由 Spring 组件扫描自动发现,并在 Spring 应用程序上下文中作为 bean 进行实例化。
- 除了 HomeController 之外,所有的控制器都在类级别上使用 @RequestMapping 进行注释,以定义控制器将处理的基本请求模式。
- 它们都有一个或多个方法,这些方法都用 @GetMapping 或 @PostMapping 进行了注释,以提供关于哪些方法应该处理哪些请求的细节。
即将编写的大多数控制器都将遵循这种模式。但是,如果一个控制器足够简单,不填充模型或流程输入(就像 HomeController 一样),那么还有另一种定义控制器的方法。请查看下一个程序清单,了解如何声明视图控制器 —— 一个只将请求转发给视图的控制器。
1 | package tacos.web; |
关于 @WebConfig 最值得注意的是它实现了 WebMvcConfigurer 接口。WebMvcConfigurer 定义了几个配置 Spring MVC 的方法。尽管它是一个接口,但它提供了所有方法的默认实现,因此只需覆盖所需的方法。在本例中,覆盖了 addViewControllers() 方法。
addViewControllers() 方法提供了一个 ViewControllerRegistry,可以使用它来注册一个或多个视图控制器。在这里,在注册表上调用 addViewController(),传入 “/”,这是视图控制器处理 GET 请求的路径。该方法返回一个 ViewControllerRegistration 对象,在该对象上立即调用 setViewName() 来指定 home 作为应该转发 “/” 请求的视图。
就像这样,已经能够用配置类中的几行代码替换 HomeController。现在可以删除 HomeController,应用程序的行为应该与以前一样。
这里,已经创建了一个新的 WebConfig 配置类来存放视图控制器声明。但是任何配置类都可以实现 WebMvcConfigurer 并覆盖 addViewController() 方法。例如,可以将相同的视图控制器声明添加到引导 TacoCloudApplication 类中,如下所示:
1 |
|
通过扩展现有的配置类,可以避免创建新的配置类,从而降低项目工件数量。但是我倾向于为每种配置(web、数据、安全性等等)创建一个新的配置类,保持应用程序引导配置的简洁。
选择视图模板库
表 2.2 列出了 Spring Boot 自动配置支持的模板选项。
| 模板 | Spring Boot starter 依赖 |
|---|---|
| FreeMarker | spring-boot-starter-freemarker |
| Groovy Templates | spring-boot-starter-groovy-templates |
| JavaServer Page(JSP) | None (provided by Tomcat or Jetty) |
| Mustache | spring-boot-starter-mustache |
| Thymeleaf | spring-boot-starter-thymeleaf |
如果希望使用不同的模板库,只需在项目初始化时选择它,或者编辑现有的项目构建以包含新选择的模板库。
例如,假设想使用 Mustache 而不是 Thymeleaf。没有问题。只需访问项目 pom.xml 文件,将:
1 | <dependency> |
替换为:
1 | <dependency> |
当然,需要确保使用 Mustache 语法而不是 Thymeleaf 标签来编写所有模板。
在表 2.2 中请注意,JSP 在构建中不需要任何特殊的依赖关系。这是因为 servlet 容器本身(默认 Tomcat)实现了 JSP 规范,因此不需要进一步的依赖关系。
但是如果选择使用 JSP,就会遇到一个问题。事实证明,Java servlet 容器 —— 包括嵌入式 Tomcat 和 Jetty 容器 —— 通常在 /WEB-INF 下寻找 jsp。但是如果将应用程序构建为一个可执行的 JAR 文件,就没有办法满足这个需求。因此,如果将应用程序构建为 WAR 文件并将其部署在传统的 servlet 容器中,那么 JSP 只是一个选项。如果正在构建一个可执行的 JAR 文件,必须选择 Thymeleaf、FreeMarker 或表 2.2 中的其他选项之一。
缓存模板
默认情况下,模板在第一次使用时只解析一次,解析的结果被缓存以供后续使用。对于生产环境来说,这是一个很好的特性,因为它可以防止对每个请求进行冗余的模板解析,从而提高性能。
但是,在开发时,这个特性并不那么好。假设启动了应用程序并点击了玉米饼设计页面,并决定对其进行一些更改。当刷新 web 浏览器时,仍然会显示原始版本。查看更改的惟一方法是重新启动应用程序,这非常不方便。
幸运的是,有一种方法可以禁用缓存。只需将 templateappropriate 高速缓存属性设置为 false。表 2.3 列出了每个支持的模板库的缓存属性。
| 模板 | 缓存使能属性 |
|---|---|
| Freemarker | spring.freemarker.cache |
| Groovy Templates | spring.groovy.template.cache |
| Mustache | spring.mustache.cache |
| Thymeleaf | spring.thymeleaf.cache |
默认情况下,所有这些属性都设置为 true 以启用缓存。可以通过将其缓存属性设置为 false 来禁用所选模板引擎的缓存。例如,要禁用 Thymeleaf 缓存,请在 application.properties 中添加以下行:
1 | = false |
惟一的问题是,在将应用程序部署到生产环境之前,一定要删除这一行(或将其设置为 true)。一种选择是在 profile 文件中设置属性。
一个更简单的选择是使用 Spring Boot 的 DevTools。在 DevTools 提供的许多有用的开发时帮助中,它将禁用所有模板库的缓存,但在部署应用程序时将禁用自身(从而重新启用模板缓存)。
小结
- Spring 提供了一个强大的 web 框架,称为 Spring MVC,可以用于开发 Spring 应用程序的 web 前端。
- Spring MVC 是基于注解的,可以使用 @RequestMapping、@GetMapping 和 @PostMapping 等注解来声明请求处理方法。
- 大多数请求处理方法通过返回视图的逻辑名称来结束,例如一个 Thymeleaf 模板,请求(以及任何模型数据)被转发到该模板。
- Spring MVC 通过 Java Bean Validation API 和 Hibernate Validator 等验证 API 的实现来支持验证。
- 视图控制器可以用来处理不需要模型数据或处理的 HTTP GET 请求。
- 除了 Thymeleaf,Spring 还支持多种视图选项,包括 FreeMarker、Groovy Templates 和 Mustache。
第 3 章 处理数据
本章内容:
- 使用 Spring JdbcTemplate
- 使用 SimpleJdbcInsert 插入数据
- 使用 Spring Data 声明 JPA repositories
使用 JDBC 读写数据
在处理关系数据时,Java 开发人员有多个选择。两个最常见的选择是 JDBC 和 JPA。
Spring JDBC 支持起源于 JdbcTemplate 类。JdbcTemplate 提供了一种方法,通过这种方法,开发人员可以对关系数据库执行 SQL 操作,与通常使用 JDBC 不同的是,这里不需要满足所有的条件和样板代码。
1 |
|
很难在 JDBC 的混乱代码中找到查询指针。它被创建连接、创建语句和通过关闭连接、语句和结果集来清理的代码所包围。
更糟糕的是,在创建连接或语句或执行查询时,可能会出现许多问题。这要求捕获一个 SQLException,这可能有助于(也可能无助于)找出问题出在哪里或如何解决问题。
SQLException 是一个被检查的异常,它需要在 catch 块中进行处理。但是最常见的问题,如未能创建到数据库的连接或输入错误的查询,不可能在 catch 块中得到解决,可能会重新向上抛出以求处理。相反,要是考虑使用 JdbcTemplate 的方法。
1 | private JdbcTemplate jdbc; |
程序清单 3.2 中的代码显然比程序清单 3.1 中的原始 JDBC 示例简单得多;没有创建任何语句或连接。而且,在方法完成之后,不会对那些对象进行任何清理。最后,这样做不会存在任何在 catch 块中不能处理的异常。剩下的代码只专注于执行查询(调用 JdbcTemplate 的 queryForObject() 方法)并将结果映射到 Ingredient 对象(在 mapRowToIngredient() 方法中)。
为域适配持久化
在将对象持久化到数据库时,通常最好有一个惟一标识对象的字段。Ingredient 类已经有一个 id 字段,但是需要向 Taco 和 Order 添加 id 字段。
1 |
|
Order 类也需要做类似的修改,如下所示:
1 |
|
域类现在已经为持久化做好了准备。
使用 JdbcTemplate
在开始使用 JdbcTemplate 之前,需要将它添加到项目类路径中。
1 | <dependency> |
还需要一个存储数据的数据库。
1 | <dependency> |
定义 JDBC 存储库
Ingredient repository 需要执行以下操作:
- 查询所有的 Ingredient 使之变成一个 Ingredient 的集合对象
- 通过它的 id 查询单个 Ingredient
- 保存一个 Ingredient 对象
以下 IngredientRepository 接口将这三种操作定义为方法声明:
1 | package tacos.data; |
尽管该接口体现了需要 Ingredient repository 做的事情的本质,但是仍然需要编写一个使用 JdbcTemplate 来查询数据库的 IngredientRepository 的实现。
1 | package tacos.data; |
通过使用 @Repository 对 JdbcIngredientRepository 进行注解,这样它就会由 Spring 组件在扫描时自动发现,并在 Spring 应用程序上下文中生成 bean 实例。
当 Spring 创建 JdbcIngredientRepository bean 时,通过 @Autowired 注解将 JdbcTemplate 注入到 bean 中。构造函数将 JdbcTemplate 分配给一个实例变量,该变量将在其他方法中用于查询和插入数据库。
1 |
|
findAll() 和 findById() 都以类似的方式使用 JdbcTemplate。期望返回对象集合的 findAll() 方法使用了 JdbcTemplate 的 query() 方法。query() 方法接受查询的 SQL 以及 Spring 的 RowMapper 实现,以便将结果集中的每一行映射到一个对象。findAll() 还接受查询中所需的所有参数的列表作为它的最后一个参数。但是,在本例中,没有任何必需的参数。
findById() 方法只期望返回单个成分对象,因此它使用 JdbcTemplate 的 queryForObject() 方法而不是 query()。queryForObject() 的工作原理与 query() 非常相似,只是它返回的是单个对象,而不是对象列表。在本例中,它给出了要执行的查询、一个 RowMapper 和要获取的 Ingredient 的 id,后者用于代替查询 SQL 中 的 ?。
如程序清单 3.5 所示,findAll() 和 findById() 的 RowMapper 参数作为 mapRowToIngredient() 方法的方法引用。当使用 JdbcTemplate 作为显式 RowMapper 实现的替代方案时,使用 Java 8 的方法引用和 lambda 非常方便。但是,如果出于某种原因,想要或是需要一个显式的 RowMapper,那么 findAll() 的以下实现将展示如何做到这一点:
1 |
|
从数据库读取数据只是问题的一部分。在某些情况下,必须将数据写入数据库以便能够读取。因此,让我们来看看如何实现 save() 方法。
插入一行
JdbcTemplate 的 update() 方法可用于在数据库中写入或更新数据的任何查询。并且,如下面的程序清单所示,它可以用来将数据插入数据库。
1 |
|
因为没有必要将 ResultSet 数据映射到对象,所以 update() 方法要比 query() 或 queryForObject() 简单得多。它只需要一个包含 SQL 的字符串来执行,以及为任何查询参数赋值。在本例中,查询有三个参数,它们对应于 save() 方法的最后三个参数,提供了 Ingredient 的 id、name 和 type。
完成了 JdbcIngredientRepository后,现在可以将其注入到 DesignTacoController 中,并使用它来提供一个 Ingredient 对象列表,而不是使用硬编码的值(正如第 2 章中所做的那样)。DesignTacoController 的变化如下所示。
1 |
|
请注意,showDesignForm() 方法的第 2 行现在调用了注入的 IngredientRepository 的 findAll() 方法。findAll() 方法从数据库中提取所有 Ingredient,然后将它们对应到到模型的不同类型中。
定义模式并预加载数据
除了 Ingredient 表之外,还需要一些保存订单和设计信息的表。图 3.1 说明了需要的表以及这些表之间的关系。
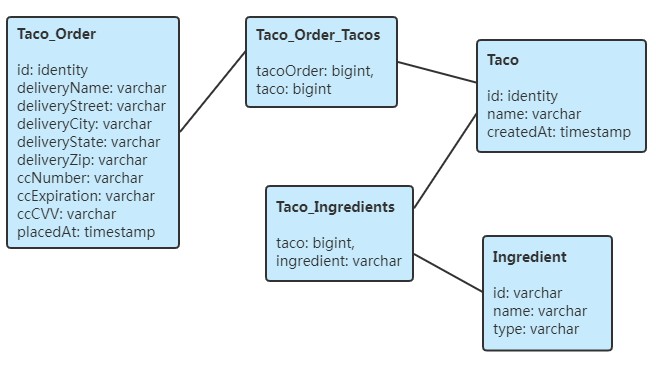
图 3.1中的表有以下用途:
- Ingredient - 保存着原料信息
- Taco - 保存着关于 taco 设计的重要信息
- Taco_Ingredient - 包含 Taco 表中每一行的一个或多行数据,将 Taco 映射到该 Taco 的 Ingredient
- Taco_Order - 保存着重要的订单细节
- Taco_Order_Tacos - 包含 Taco_Order 表中的每一行的一个或多行数据,将 Order 映射到 Order 中的Tacos
1 | create table if not exists Ingredient ( |
如果有一个名为 schema.sql 的文件。在应用程序的类路径根目录下执行 sql,然后在应用程序启动时对数据库执行该文件中的 SQL。因此,应该将程序清单 3.8 的内容写入一个名为 schema.sql 的文件中,然后放在项目的 src/main/resources 文件夹下。
还需要用一些 Ingredient 数据来预加载数据库。幸运的是,Spring Boot 还将执行一个名为 data.sql 的文件,这个文件位于根路径下。因此,可以使用 src/main/resources/data.sql 中的下面程序清单中的 insert 语句来加载包含 Ingredient 数据的数据库。
1 | delete from Taco_Order_Tacos; |
即使只开发了 Ingredient 数据的存储库,也可以启动 Taco Cloud 应用程序并访问设计页面,查看JdbcIngredientRepository 的运行情况。
插入数据
到此,已经了解了如何使用 JdbcTemplate 向数据库写入数据。JdbcIngredientRepository 中的 save() 方法使用 JdbcTemplate 的 update() 方法将 Ingredient 对象保存到数据库中。
虽然这是第一个很好的例子,但是它可能有点太简单了。保存数据可能比 JdbcIngredientRepository 所需要的更复杂。使用 JdbcTemplate 保存数据的两种方法包括:
- 直接使用 update() 方法
- 使用 SimpleJdbcInsert 包装类
让我们首先看看,当持久话需求比保存一个 Ingredient 所需要的更复杂时,如何使用 update() 方法。
使用 JdbcTemplate 保存数据
目前,Taco 和 Order 存储库需要做的惟一一件事是保存它们各自的对象。为了保存 Taco 对象,TacoRepository 声明了一个 save() 方法,如下所示:
1 | package tacos.data; |
类似地,OrderRepository 也声明了一个 save() 方法:
1 | package tacos.data; |
保存一个 Taco 设计需要将与该 Taco 关联的 Ingredient 保存到 Taco_Ingredient 表中。同样,保存 Order 也需要将与 Order 关联的 Taco 保存到 Taco_Order_Tacos 表中。这使得保存 Taco 和 Order 比 保存 Ingredient 更有挑战性。
要实现 TacoRepository,需要一个 save() 方法,该方法首先保存基本的 Taco 设计细节(例如,名称和创建时间),然后为 Taco 对象中的每个 Ingredient 在 Taco_Ingredients 中插入一行。下面的程序清单显示了完整的 JdbcTacoRepository 类。
1 | package tacos.data; |
save() 方法首先调用私有的 saveTacoInfo() 方法,然后使用该方法返回的 Taco id 调用 saveIngredientToTaco(),它保存每个成分。关键在于 saveTacoInfo() 的细节。
在 Taco 中插入一行时,需要知道数据库生成的 id,以便在每个 Ingredient 中引用它。保存 Ingredient 数据时使用的 update() 方法不能获得生成的 id,因此这里需要一个不同的 update() 方法。
需要的 update() 方法接受 PreparedStatementCreator 和 KeyHolder。KeyHolder 将提供生成的 Taco id,但是为了使用它,还必须创建一个 PreparedStatementCreator。
如程序清单 3.10 所示,创建 PreparedStatementCreator 非常重要。首先创建一个 PreparedStatementCreatorFactory,为它提供想要执行的 SQL,以及每个查询参数的类型。然后在该工厂上调用 newPreparedStatementCreator(),在查询参数中传递所需的值以生成 PreparedStatementCreator。
通过使用 PreparedStatementCreator,可以调用 update(),传入 PreparedStatementCreator 和 KeyHolder(在本例中是 GeneratedKeyHolder 实例)。update() 完成后,可以通过返回 keyHolder.getKey().longValue() 来返回 Taco id。
回到 save() 方法,循环遍历 Taco 中的每个成分,调用 saveIngredientToTaco() 方法。saveIngredientToTaco() 方法使用更简单的 update() 形式来保存对 Taco_Ingredient 表引用。
TacoRepository 剩下所要做的就是将它注入到 DesignTacoController 中,并在保存 Taco 时使用它。下面的程序清单显示了注入存储库所需的改变。
1 |
|
构造函数包含一个 IngredientRepository 和一个TacoRepository。它将这两个变量都赋值给实例变量,以便它们可以在 showDesignForm() 和 processDesign() 方法中使用。
说到 processDesign() 方法,它的更改比 showDesignForm() 所做的更改要广泛一些。下一个程序清单显示了新的 processDesign() 方法。
1 |
|
与 taco() 方法一样,order() 方法上的 @ModelAttribute 注解确保在模型中能够创建 Order 对象。
类级别的 @SessionAttributes 注解指定了任何模型对象,比如应该保存在会话中的 order 属性,并且可以跨多个请求使用。
taco 设计的实际处理发生在 processDesign() 方法中,除了 Taco 和 Errors 对象外,该方法现在还接受 Order 对象作为参数。Order 参数使用 @ModelAttribute 进行注解,以指示其值应该来自模型,而 Spring MVC 不应该试图给它绑定请求参数。
在检查验证错误之后,processDesign() 使用注入的 TacoRepository 来保存 Taco。然后,它将 Taco 对象添加到保存于 session 中 Order 对象中。
实际上,Order 对象仍然保留在 session 中,直到用户完成并提交 Order 表单才会保存到数据库中。此时,OrderController 需要调用 OrderRepository 的实现来保存订单。我们来写一下这个实现。
使用 SimpleJdbcInsert 插入数据
保存一个 taco 不仅要将 taco 的名称和创建时间保存到 Taco 表中,还要将与 taco 相关的配料的引用保存到 Taco_Ingredient 表中。对于这个操作还需要知道 Taco 的 id,这是使用 KeyHolder 和 PreparedStatementCreator 来获得的。
在保存订单方面,也存在类似的情况。不仅必须将订单数据保存到 Taco_Order 表中,还必须引用 Taco_Order_Tacos 表中的每个 taco。但是不是使用繁琐的 PreparedStatementCreator, 而是使用 SimpleJdbcInsert, SimpleJdbcInsert 是一个包装了 JdbcTemplate 的对象,它让向表插入数据的操作变得更容易。
首先创建一个 JdbcOrderRepository,它是 OrderRepository 的一个实现。但是在编写 save() 方法实现之前,让我们先关注构造函数,在构造函数中,将创建两个 SimpleJdbcInsert 实例,用于将值插入 Taco_Order 和 Taco_Order_Tacos 表中。下面的程序清单显示了 JdbcOrderRepository(没有 save() 方法)。
1 | package tacos.data; |
与 JdbcTacoRepository 一样,JdbcOrderRepository 也通过其构造函数注入了 JdbcTemplate。但是,构造函数并没有将 JdbcTemplate 直接分配给一个实例变量,而是使用它来构造两个 SimpleJdbcInsert 实例。
第一个实例被分配给 orderInserter 实例变量,它被配置为使用 Taco_Order 表,并假定 id 属性将由数据库提供或生成。分配给 orderTacoInserter 的第二个实例被配置为使用 Taco_Order_Tacos 表,但是没有声明如何在该表中生成任何 id。
构造函数还创建 ObjectMapper 实例,并将其分配给实例变量。尽管 Jackson 用于 JSON 处理,但稍后将看到如何重新使用它来帮助保存订单及其关联的 tacos。
现在让我们看看 save() 方法如何使用 SimpleJdbcInsert 实例。下一个程序清单显示了 save() 方法,以及几个用于实际工作的 save() 委托的私有方法。
1 |
|
save() 方法实际上并不保存任何东西。它定义了保存订单及其关联 Taco 对象的流,并将持久性工作委托给 saveOrderDetails() 和 saveTacoToOrder()。
SimpleJdbcInsert 有两个执行插入的有用方法:execute() 和 executeAndReturnKey()。两者都接受 Map<String, Object>,其中 Map 键对应于数据插入的表中的列名,映射的值被插入到这些列中。
通过将 Order 中的值复制到 Map 的条目中,很容易创建这样的 Map。但是 Order 有几个属性,这些属性和它们要进入的列有相同的名字。因此,在 saveOrderDetails() 中,我决定使用 Jackson 的 ObjectMapper 及其 convertValue() 方法将 Order 转换为 Map。这是必要的,否则 ObjectMapper 会将 Date 属性转换为 long,这与 Taco_Order 表中的 placedAt 字段不兼容。
随着 Map 中填充完成订单数据,我们可以在 orderInserter 上调用 executeAndReturnKey() 方法了。这会将订单信息保存到 Taco_Order 表中,并将数据库生成的 id 作为一个 Number 对象返回,调用 longValue() 方法将其转换为从方法返回的 long 值。
saveTacoToOrder() 方法要简单得多。不是使用 ObjectMapper 将对象转换为 Map,而是创建 Map 并设置适当的值。同样,映射键对应于表中的列名。对 orderTacoInserter 的 execute() 方法的简单调用就能执行插入操作。
现在可以将 OrderRepository 注入到 OrderController 中并开始使用它。下面的程序清单显示了完整的 OrderController,包括因使用注入的 OrderRepository 而做的更改。
1 | package tacos.web; |
除了将 OrderRepository 注入控制器之外,OrderController 中惟一重要的更改是 processOrder() 方法。在这里,表单中提交的 Order 对象(恰好也是在 session 中维护的 Order 对象)通过注入的 OrderRepository 上的 save() 方法保存。
一旦订单被保存,就不再需要它存在于 session 中了。事实上,如果不清除它,订单将保持在 session 中,包括其关联的 tacos,下一个订单将从旧订单中包含的任何 tacos 开始。因此需要 processOrder() 方法请求 SessionStatus 参数并调用其 setComplete() 方法来重置会话。
所有的 JDBC 持久化代码都准备好了。现在,可以启动 Taco Cloud 应用程序并进行测试。你想要多少 tacos 和多少 orders 都可以。
可能还会发现在数据库中进行挖掘是很有帮助的。因为使用 H2 作为嵌入式数据库,而且 Spring Boot DevTools 已经就位,所以应该能够用浏览器访问 http://localhost:8080/h2-console 来查看 H2 控制台。虽然需要确保 JDBC URL 字段被设置为 JDBC:h2:mem:testdb,但是默认的凭证应该可以让你进入。登录后,应该能够对 Taco Cloud 模式中的表发起查询。
Spring 的 JdbcTemplate 和 SimpleJdbcInsert 使得使用关系数据库比普通 JDBC 简单得多。但是可能会发现 JPA 使它更加简单。让我们回顾一下之前的工作,看看如何使用 Spring 数据使数据持久化更加容易。
使用 Spring Data JPA 持久化数据
Spring Data 项目是一个相当大的伞形项目,几个子项目组成,其中大多数子项目关注于具有各种不同数据库类型的数据持久化。一些最流行的 Spring 数据项目包括:
- Spring Data JPA - 针对关系数据库的持久化
- Spring Data Mongo - 针对 Mongo 文档数据库的持久化
- Spring Data Neo4j - 针对 Neo4j 图形数据库的持久化
- Spring Data Redis - 针对 Redis 键值存储的持久化
- Spring Data Cassandra - 针对 Cassandra 数据库的持久化
Spring Data 为所有这些项目提供的最有意思和最有用的特性之一是能够基于存储库规范接口自动创建存储库。
添加 Spring Data JPA 到数据库中
Spring Data JPA 可用于具有 JPA starter 的 Spring Boot 应用程序。这个 starter 依赖不仅带来了 Spring Data JPA,还包括 Hibernate 作为 JPA 的实现:
1 | <dependency> |
如果想使用不同的 JPA 实现,那么至少需要排除 Hibernate 依赖,并包含所选择的 JPA 库。例如,要使用 EclipseLink 而不是 Hibernate,需要按如下方式更改构建:
1 | <dependency> |
请注意,根据对 JPA 实现的选择,可能需要进行其他更改。详细信息请参阅选择的 JPA 实现的文档。现在,让我们重新查看域对象并对它们进行注解以实现 JPA 持久化。
注解域作为实体
1 | package tacos; |
为了将其声明为 JPA 实体,必须使用 @Entity 注解。它的 id 属性必须使用 @Id 进行注解,以便将其指定为惟一标识数据库中实体的属性。
JPA 要求实体有一个无参构造函数,所以 Lombok 的 @NoArgsConstructor 实现了这一点。但是要是不希望使用它,可以通过将 access 属性设置为 AccessLevel.PRIVATE 来将其设置为私有。因为必须设置 final 属性,所以还要将 force 属性设置为 true,这将导致 Lombok 生成的构造函数将它们设置为 null。
@Data 隐式地添加了一个必需的有参构造函数,但是当使用 @NoArgsConstructor 时,该构造函数将被删除。显式的 @RequiredArgsConstructor 确保除了私有无参数构造函数外,仍然有一个必需有参构造函数。
1 | package tacos; |
与 Ingredient 一样,Taco 类现在使用 @Entity 注解,其 id 属性使用 @Id 注解。因为依赖于数据库自动生成 id 值,所以还使用 @GeneratedValue 注解 id 属性,指定自动策略。
要声明 Taco 及其相关 Ingredient 列表之间的关系,可以使用 @ManyToMany 注解 ingredient 属性。一个 Taco 可以有很多 Ingredient,一个 Ingredient 可以是很多 Taco 的一部分。
还有一个新方法 createdAt(),它用 @PrePersist 注解。将使用它将 createdAt 属性设置为保存 Taco 之前的当前日期和时间。
1 | package tacos; |
@Table注解指定订单实体应该持久化到数据库中名为 Taco_Order 的表中。尽管可以在任何实体上使用这个注解,但它对于 Order 是必需的。没有它,JPA 将默认将实体持久化到一个名为 Order 的表中,但是 Order 在 SQL 中是一个保留字,会导致问题。现在实体已经得到了正确的注解,该编写 repository 了。
声明 JPA repository
在存储库的 JDBC 版本中,显式地声明了希望 repository 提供的方法。但是使用 Spring Data,扩展 CrudRepository 接口。例如,这是一个新的 IngredientRepository 接口:
1 | package tacos.data; |
CrudRepository 为 CRUD(创建、读取、更新、删除)操作声明了十几个方法。注意,它是参数化的,第一个参数是存储库要持久化的实体类型,第二个参数是实体 id 属性的类型。对于 IngredientRepository,参数应该是 Ingredient 和 String 类型。
也可以这样定义 TacoRepository:
1 | package tacos.data; |
IngredientRepository 和 TacoRepository 之间唯一显著的区别是对于 CrudRepository 的参数不同。在这里,它们被设置为 Taco 和 Long 去指定 Taco 实体(及其 id 类型)作为这个 respository 接口的持久化单元。最后,同样的更改可以应用到 OrderRepository:
1 | package tacos.data; |
现在有了这三个 repository,可能认为需要为这三个 repository 编写实现,还包括每种实现的十几个方法。但这就是 Spring Data JPA 优秀的地方 —— 不需要编写实现!当应用程序启动时,Spring Data JPA 会动态地自动生成一个实现。这意味着 repository 可以从一开始就使用。只需将它们注入到控制器中,就像在基于 JDBC 的实现中所做的那样。
CrudRepository 提供的方法非常适合用于实体的通用持久化。但是如果有一些基本持久化之外的需求呢?让我们看看如何自定义 repository 来执行域特有的查询。
自定义 JPA repository
想象一下,除了 CrudRepository 提供的基本 CRUD 操作之外,还需要获取投递给指定邮政编码的所有订单。事实证明,通过在 OrderRepository 中添加以下方法声明可以很容易地解决这个问题:
1 | List<Order> findByDeliveryZip(String deliveryZip); |
在生成 repository 实现时,Spring Data 检查存储库接口中的任何方法,解析方法名称,并尝试在持久化对象的上下文中理解方法的用途(在本例中是 Order)。本质上,Spring Data 定义了一种小型的领域特定语言(DSL),其中持久化细节用 repository 中的方法签名表示。
Spring Data 知道这个方法是用来查找订单的,因为已经用 Order 参数化了 CrudRepository。方法名 findByDeliveryZip() 表明,该方法应该通过将其 deliveryZip 属性与作为参数,传递给匹配的方法来查找所有订单实体。
findByDeliveryZip() 方法非常简单,但是 Spring Data 也可以处理更有趣的方法名。repository 的方法由一个动词、一个可选的主语、单词 by 和一个谓词组成。在 findByDeliveryZip() 中,动词是 find,谓词是 DeliveryZip,主语没有指定,暗示是一个 Order。
让我们考虑另一个更复杂的例子。假设需要查询在给定日期范围内投递给指定邮政编码的所有订单。在这种情况下,当添加到 OrderRepository 时,下面的方法可能会被证明是有用的:
1 | List<Order> readOrdersByDeliveryZipAndPlacedAtBetween(String deliveryZip, Date startDate, Date endDate); |
图 3.2 说明了在生成 respository 实现时,Spring Data 如何解析和理解 readOrdersByDeliveryZipAndPlacedAtBetween() 方法。可以看到,readOrdersByDeliveryZipAndPlacedAtBetween() 中的动词是 read。Spring Data 还将 find、read 和 get 理解为获取一个或多个实体的同义词。另外,如果只希望方法返回一个带有匹配实体计数的 int,也可以使用 count 作为动词。
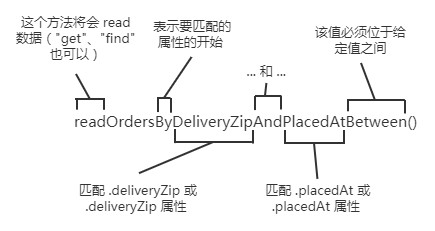
尽管该方法的主语是可选的,但在这里它表示 Order。Spring Data 会忽略主题中的大多数单词,因此可以将方法命名为 readPuppiesBy…它仍然可以找到 Order 实体,因为这是 CrudRepository 参数化的类型。
谓词跟在方法名中的 By 后面,是方法签名中最有趣的部分。在本例中,谓词引用两个 Order属性:deliveryZip 和 placedAt。deliveryZip 属性必须与传递给方法的第一个参数的值一致。Between 关键字表示 deliveryZip 的值必须位于传入方法最后两个参数的值之间。
除了一个隐式的 Equals 操作和 Between 操作外,Spring Data 方法签名还可以包括以下任何操作:
- IsAfter, After, IsGreaterThan, GreaterThan
- IsGreaterThanEqual, GreaterThanEqual
- IsBefore, Before, IsLessThan, LessThan
- IsLessThanEqual, LessThanEqual
- IsBetween, Between
- IsNull, Null
- IsNotNull, NotNull
- IsIn, In
- IsNotIn, NotIn
- IsStartingWith, StartingWith, StartsWith
- IsEndingWith, EndingWith, EndsWith
- IsContaining, Containing, Contains
- IsLike, Like
- IsNotLike, NotLike
- IsTrue, True
- IsFalse, False
- Is, Equals
- IsNot, Not
- IgnoringCase, IgnoresCase
作为 IgnoringCase 和 IgnoresCase 的替代方法,可以在方法上放置 AllIgnoringCase 或 AllIgnoresCase 来忽略所有 String 比较的大小写。例如,考虑以下方法:
1 | List<Order> findByDeliveryToAndDeliveryCityAllIgnoresCase(String deliveryTo, String deliveryCity); |
最后,还可以将 OrderBy 放在方法名的末尾,以便根据指定的列对结果进行排序。例如,通过 deliveryTo 属性来订购:
1 | List<Order> findByDeliveryCityOrderByDeliveryTo(String city); |
虽然命名约定对于相对简单的查询很有用,但是对于更复杂的查询,不需要太多的想象就可以看出方法名称可能会失控。在这种情况下,可以随意将方法命名为任何想要的名称,并使用 @Query 对其进行注解,以显式地指定调用方法时要执行的查询,如下例所示:
1 |
|
在这个 @Query 的简单用法中,请求在西雅图交付的所有订单。但是也可以使用 @Query 来执行几乎任何想要的查询,即使通过遵循命名约定来实现查询很困难或不可能。
小结
- JdbcTemplate 大大简化了 JDBC 的工作。
- 当需要知道数据库生成的 id 时,可以同时使用 PreparedStatementCreator 和 KeyHolder。
- 为了方便执行数据插入,使用 SimpleJdbcInsert。
- Spring Data JPA 使得 JPA 持久化就像编写存储库接口一样简单。
第 4 章 Spring 安全
本章内容:
- 自动配置 Spring Security
- 自定义用户存储
- 自定义登录页面
- 防御 CSRF 攻击
- 了解你的用户
启用 Spring Security
保护 Spring 应用程序的第一步是将 Spring Boot security starter 依赖项添加到构建中。
1 | <dependency> |
启动应用程序并访问主页(或任何页面)。将提示使用 HTTP 基本身份验证对话框进行身份验证。要想通过认证,需要提供用户名和密码。用户名是 user。密码是随机生成并写入了应用程序日志文件。日志条目应该是这样的:
1 | Using default security password: 087cfc6a-027d-44bc-95d7-cbb3a798a1ea |
假设正确地输入了用户名和密码,将被授予对应用程序的访问权。
在项目构建中添加 security starter,就可以获得以下安全特性:
- 所有的 HTTP 请求路径都需要认证。
- 不需要特定的角色或权限。
- 没有登录页面。
- 身份验证由 HTTP 基本身份验证提供。
- 只有一个用户;用户名是 user。
如果要正确地保护 Taco Cloud 应用程序,还有更多的工作要做。至少需要配置 Spring Security 来完成以下工作:
- 提示使用登录页面进行身份验证,而不是使用 HTTP 基本对话框。
- 为多个用户提供注册页面,让新的 Taco Cloud 用户可以注册。
- 为不同的请求路径应用不同的安全规则。例如,主页和注册页面根本不需要身份验证。
配置 Spring Security
1 | package tacos.security; |
如果再次尝试访问 Taco Cloud 主页,仍然会提示需要登录。但是,将看到一个类似于图 4.2 的登录表单,而不是一个 HTTP 基本身份验证对话框提示。
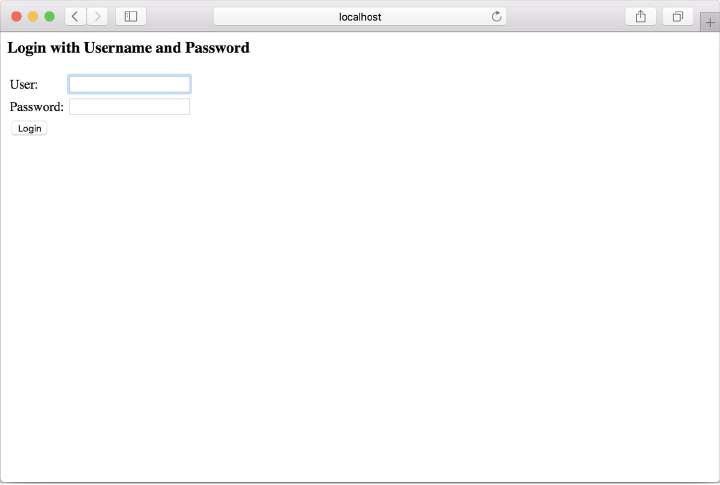
Spring Security 为配置用户存储提供了几个选项,包括:
- 一个内存用户存储
- 基于 JDBC 的用户存储
- 由 LDAP 支持的用户存储
- 定制用户详细信息服务
无论选择哪个用户存储,都可以通过重写 WebSecurityConfigurerAdapter 配置基类中定义的 configure() 方法来配置它。首先,你需要在 SecurityConfig 类中添加以下方法:
1 |
|
现在,只需要使用使用给定 AuthenticationManagerBuilder 的代码来替换这些省略号,以指定在身份验证期间如何查找用户。
内存用户存储
用户信息可以保存在内存中。假设只有少数几个用户,这些用户都不可能改变。在这种情况下,将这些用户定义为安全配置的一部分可能非常简单。
例如,下一个清单显示了如何在内存用户存储中配置两个用户 “buzz” 和 “woody”。
1 |
|
AuthenticationManagerBuilder 使用构造器风格的 API 来配置身份验证细节。在这种情况下,对 inMemoryAuthentication() 方法的调用,可以直接在安全配置本身中指定用户信息。
给 withUser() 的值是用户名,而密码和授予的权限是用 password() 和 authority() 方法指定的。
内存中的用户存储应用于测试或非常简单的应用程序时非常方便,但是它不允许对用户进行简单的编辑。如果需要添加、删除或更改用户,则必须进行必要的更改,然后重新构建、部署应用程序。
基于 JDBC 的用户存储
下面的程序清单显示了如何配置 Spring Security,并将用户信息通过 JDBC 保存在关系型数据库中,来进行身份认证。
1 |
|
configure() 的这个实现在给定的 AuthenticationManagerBuilder 上调用 jdbcAuthentication()。然后,必须设置 DataSource,以便它知道如何访问数据库。这里使用的数据源是由自动装配提供的。
重写默认用户查询
虽然这个最小配置可以工作,但它对数据库模式做了一些假设。它期望已经存在某些表,用户数据将保存在这些表中。更具体地说,以下来自 Spring Security 内部的代码片段显示了在查找用户详细信息时将执行的 SQL 查询:
1 | public static final String DEF_USERS_BY_USERNAME_QUERY = |
第一个查询检索用户的用户名、密码以及是否启用它们,此信息用于对用户进行身份验证;下一个查询查询用户授予的权限,以进行授权;最后一个查询查询作为组的成员授予用户的权限。
如果可以在数据库中定义和填充满足这些查询的表,那么就没有什么其他要做的了。但是,数据库很可能不是这样的,需要对查询进行更多的控制。在这种情况下,可以配置自己的查询。
1 |
|
在本例中,仅重写了身份验证和基本授权查询,也可以通过使用自定义查询调用 groupAuthoritiesByUsername() 来重写组权限查询。
在将默认 SQL 查询替换为自己设计的查询时,一定要遵守查询的基本约定。它们都以用户名作为唯一参数。身份验证查询选择用户名、密码和启用状态;授权查询选择包含用户名和授予的权限的零个或多个行的数据;组权限查询选择零个或多个行数据,每个行有一个 group id、一个组名和一个权限。
使用编码密码
如果密码以纯文本形式存储,就会受到黑客的窥探。但是如果在数据库中对密码进行编码,身份验证将失败,因为它与用户提交的明文密码不匹配。
为了解决这个问题,你需要通过调用 passwordEncoder() 方法指定一个密码编码器
1 |
|
passwordEncoder() 方法接受 Spring Security 的 passwordEncoder 接口的任何实现。Spring Security 的加密模块包括几个这样的实现:
- BCryptPasswordEncoder —— 采用 bcrypt 强哈希加密
- NoOpPasswordEncoder —— 不应用任何编码
- Pbkdf2PasswordEncoder —— 应用 PBKDF2 加密
- SCryptPasswordEncoder —— 应用了 scrypt 散列加密
- StandardPasswordEncoder —— 应用 SHA-256 散列加密
上述代码使用了 StandardPasswordEncoder。但是,如果没有现成的实现满足你的需求,你可以选择任何其他实现,甚至可以提供你自己的自定义实现。PasswordEncoder 接口相当简单:
1 | public interface PasswordEncoder { |
无论使用哪种密码编码器,重要的是要理解数据库中的密码永远不会被解码。相反,用户在登录时输入的密码使用相同的算法进行编码,然后将其与数据库中编码的密码进行比较。比较是在 PasswordEncoder 的 matches() 方法中执行的。
最后,将在数据库中维护 Taco Cloud 用户数据。但是,我没有使用 jdbcAuthentication(),而是想到了另一个身份验证选项。但在此之前,让我们先看看如何配置 Spring Security 以依赖于另一个常见的用户数据源:使用 LDAP(轻量级目录访问协议)接入的用户存储。
LDAP 支持的用户存储
要为基于 LDAP 的身份验证配置 Spring Security,可以使用 ldapAuthentication() 方法。这个方法与 jdbcAuthentication() 类似。下面的 configure() 方法演示了用于 LDAP 身份验证的简单配置:
1 |
|
userSearchFilter() 和 groupSearchFilter() 方法用于为基本 LDAP 查询提供过滤器,这些查询用于搜索用户和组。默认情况下,用户和组的基本查询都是空的,这表示将从 LDAP 层次结构的根目录进行搜索。但你可以通过指定一个查询基数来改变这种情况:
1 |
|
userSearchBase() 方法提供了查找用户的基本查询。同样,groupSearchBase() 方法指定查找组的基本查询。这个示例不是从根目录进行搜索,而是指定要搜索用户所在的组织单元是 people,组应该搜索组织单元所在的 group。
配置密码比较
针对 LDAP 进行身份验证的默认策略是执行绑定操作,将用户通过 LDAP 服务器直接进行验证。另一种选择是执行比较操作,这包括将输入的密码发送到 LDAP 目录,并要求服务器将密码与用户的密码属性进行比较。因为比较是在 LDAP 服务器中进行的,所以实际的密码是保密的。
如果希望通过密码比较进行身份验证,可以使用 passwordCompare() 方法进行声明:
1 |
|
默认情况下,登录表单中给出的密码将与用户 LDAP 条目中的 userPassword 属性值进行比较。如果密码保存在不同的属性中,可以使用 passwordAttribute() 指定密码属性的名称:
1 |
|
在本例中,指定密码属性应该与给定的密码进行比较。此外,还可以指定密码编码器,在进行服务器端密码比较时,最好在服务器端对实际密码加密。但是尝试的密码仍然会通过网络传递到 LDAP 服务器,并且可能被黑客截获。为了防止这种情况,可以通过调用 passwordEncoder() 方法来指定加密策略。
在前面的示例中,使用 bcrypt 密码散列函数对密码进行加密,这里的前提是密码在 LDAP 服务器中也是使用 bcrypt 加密的。
引用远程 LDAP 服务器
到目前为止,我们忽略了 LDAP 服务器和数据实际驻留的位置,虽然已经将 Spring 配置为根据 LDAP 服务器进行身份验证,但是该服务器在哪里呢?
默认情况下,Spring Security 的 LDAP 身份验证假设 LDAP 服务器正在本地主机上监听端口 33389。但是,如果 LDAP 服务器位于另一台机器上,则可以使用 contextSource() 方法来配置位置:
1 |
|
contextSource() 方法返回 ContextSourceBuilder,其中提供了 url() 方法,它允许指定 LDAP 服务器的位置。
配置嵌入式 LDAP 服务器
如果没有 LDAP 服务器去做身份验证,Spring Security 可提供一个嵌入式 LDAP 服务器。可以通过 root() 方法为嵌入式服务器指定根后缀,而不是将 URL 设置为远程 LDAP 服务器:
1 |
|
当 LDAP 服务器启动时,它将尝试从类路径中找到的任何 LDIF 文件进行数据加载。LDIF(LDAP 数据交换格式)是在纯文本文件中表示 LDAP 数据的标准方法,每个记录由一个或多个行组成,每个行包含一个 name:value 对,记录之间用空行分隔。
如果不希望 Spring 在类路径中寻找它能找到的 LDIF 文件,可以通过调用 ldif() 方法来更明确地知道加载的是哪个 LDIF 文件:
1 |
|
这里,特别要求 LDAP 服务器从位于根路径下的 users.ldif 文件中加载数据。如果你感兴趣,这里有一个LDIF 文件,你可以使用它来加载内嵌 LDAP 服务器的用户数据:
1 | dn: ou=groups,dc=tacocloud,dc=com |
Spring Security 的内置用户存储非常方便,涵盖了一些常见的用例。但是 Taco Cloud 应用程序需要一些特殊的东西。当开箱即用的用户存储不能满足需求时,需要创建并配置一个定制的用户详细信息服务。
自定义用户身份验证
在上一章中,决定了使用 Spring Data JPA 作为所有 taco、配料和订单数据的持久化选项。因此,以同样的方式持久化用户数据是有意义的,这样做的话,数据最终将驻留在关系型数据库中,因此可以使用基于 JDBC 的身份验证。但是更好的方法是利用 Spring Data 存储库来存储用户。
不过,还是要先做重要的事情,让我们创建表示和持久存储用户信息的域对象和存储库接口。
当 Taco Cloud 用户注册应用程序时,他们需要提供的不仅仅是用户名和密码。他们还会告诉你,他们的全名、地址和电话号码,这些信息可以用于各种目的,不限于重新填充订单(更不用说潜在的营销机会)。
为了捕获所有这些信息,将创建一个 User 类,如下所示。程序清单 4.5 定义用户实体
1 | package tacos; |
毫无疑问,你已经注意到 User 类比第 3 章中定义的任何其他实体都更加复杂。除了定义一些属性外,User 还实现了来自 Spring Security 的 UserDetails 接口。
UserDetails 的实现将向框架提供一些基本的用户信息,比如授予用户什么权限以及用户的帐户是否启用。
getAuthorities() 方法应该返回授予用户的权限集合。各种 isXXXexpired() 方法返回一个布尔值,指示用户的帐户是否已启用或过期。
对于 User 实体,getAuthorities() 方法仅返回一个集合,该集合指示所有用户将被授予 ROLE_USER 权限。而且,至少现在,Taco Cloud 还不需要禁用用户,所以所有的 isXXXexpired() 方法都返回 true 来表示用户处于活动状态。
定义了 User 实体后,现在可以定义存储库接口:
1 | package tacos.data; |
除了通过扩展 CrudRepository 提供的 CRUD 操作之外,UserRepository 还定义了一个 findByUsername() 方法,将在用户详细信息服务中使用该方法根据用户名查找 User。
如第 3 章所述,Spring Data JPA 将在运行时自动生成该接口的实现。因此,现在可以编写使用此存储库的自定义用户详细信息服务了。
创建用户详细信息服务
Spring Security 的 UserDetailsService 是一个相当简单的接口:
1 | public interface UserDetailsService { |
这个接口的实现是给定一个用户的用户名,期望返回一个 UserDetails 对象,如果给定的用户名没有显示任何结果,则抛出一个 UsernameNotFoundException。
由于 User 类实现了 UserDetails,同时 UserRepository 提供了一个 findByUsername() 方法,因此它们非常适合在自定义 UserDetailsService 实现中使用。
1 | package tacos.security; |
UserRepositoryUserDetailsService 通过 UserRepository 实例的构造器进行注入。然后,在它的 loadByUsername() 方法中,它调用 UserRepository 中的 findByUsername() 方法去查找 User;
loadByUsername() 方法只有一个简单的规则:不允许返回 null。因此如果调用 findByUsername() 返回 null,loadByUsername() 将会抛出一个 UsernameNotFoundExcepition。除此之外,被找到的 User 将会被返回。
@Service 注解是 Spring 的另一种构造型注释,它将该类标记为包含在 Spring 的组件扫描中,因此不需要显式地将该类声明为 bean。Spring 将自动发现它并将其实例化为 bean。
但是,仍然需要使用 Spring Security 配置自定义用户详细信息服务。因此,将再次返回到 configure() 方法:
1 |
|
这次,只需调用 userDetailsService() 方法,将自动生成的 userDetailsService 实例传递给 SecurityConfig。
与基于 JDBC 的身份验证一样,也可以(而且应该)配置密码编码器,以便可以在数据库中对密码进行编码。为此,首先声明一个 PasswordEncoder 类型的bean,然后通过调用 PasswordEncoder() 将其注入到用户详细信息服务配置中:
1 |
|
我们必须讨论 configure() 方法中的最后一行,它出现了调用 encoder() 方法并将其返回值传递给 passwordEncoder()。但实际上,因为 encoder() 方法是用 @Bean 注释的,所以它将被用于在 Spring 应用程序上下文中声明一个 PasswordEncoder bean,然后拦截对 encoder() 的任何调用,以从应用程序上下文中返回 bean 实例。
既然已经有了一个通过 JPA 存储库读取用户信息的自定义用户详细信息服务,那么首先需要的就是一种让用户进入数据库的方法。需要为 Taco Cloud 用户创建一个注册页面,以便注册该应用程序。
用户注册
尽管 Spring Security 处理安全性的很多方面,但它实际上并不直接涉及用户注册过程,因此将依赖于 Spring MVC 来处理该任务。下面程序清单中的 RegistrationController 类展示并处理注册表单。
1 | package tacos.security; |
使用 @RequestMapping 进行注解,以便处理路径为 /register 的请求。
更具体地说,registerForm() 方法将处理 /register 的 GET 请求,它只返回注册的逻辑视图名。下面的程序清单显示了定义注册视图的 Thymeleaf 模板。
1 |
|
提交表单时,HTTP POST 请求将由 processRegistration() 方法处理。processRegistration() 的 RegistrationForm 对象绑定到请求数据,并使用以下类定义:
1 | package tacos.security; |
在大多数情况下,RegistrationForm 只是一个支持 Lombok 的基本类,只有少量属性。但是 toUser() 方法使用这些属性创建一个新的 User 对象,processRegistration() 将使用注入的 UserRepository 保存这个对象。
毫无疑问,RegistrationController 被注入了一个密码编码器。这与之前声明的 PasswordEncoder bean 完全相同。在处理表单提交时,RegistrationController 将其传递给 toUser() 方法,该方法使用它对密码进行编码,然后将其保存到数据库。通过这种方式,提交的密码以编码的形式写入,用户详细信息服务将能够根据编码的密码进行身份验证。
现在 Taco Cloud 应用程序拥有完整的用户注册和身份验证支持。但是如果在此时启动它,你会注意到,如果不是提示你登录,你甚至无法进入注册页面。这是因为,默认情况下,所有请求都需要身份验证。让我们看看 web 请求是如何被拦截和保护的,以便可以修复这种奇怪的先有鸡还是先有蛋的情况。
保护 web 请求
Taco Cloud 的安全需求应该要求用户在设计 tacos 或下订单之前进行身份验证。但是主页、登录页面和注册页面应该对未经身份验证的用户可用。
要配置这些安全规则,需要介绍一下 WebSecurityConfigurerAdapter 的另一个 configure() 方法:
1 |
|
这个 configure() 方法接受 HttpSecurity 对象,可以使用该对象来配置如何在 web 级别处理安全性。可以配置 HttpSecurity 的属性包括:
- 在允许服务请求之前,需要满足特定的安全条件
- 配置自定义登录页面
- 使用户能够退出应用程序
- 配置跨站请求伪造保护
拦截请求以确保用户拥有适当的权限是配置 HttpSecurity 要做的最常见的事情之一。让我们确保 Taco Cloud 的客户满足这些要求。
保护请求
需要确保 /design 和 /orders 的请求仅对经过身份验证的用户可用;应该允许所有用户发出所有其他请求。下面的 configure() 实现就是这样做的:
1 |
|
对 authorizeRequests() 的调用返回一个对象(ExpressionInterceptUrlRegistry),可以在该对象上指定 URL 路径和模式以及这些路径的安全需求。在这种情况下,指定两个安全规则:
- 对于 /design 和 /orders 的请求应该是授予 ROLE_USER 权限的用户的请求。
- 所有的请求都应该被允许给所有的用户。
这些规则的顺序很重要。首先声明的安全规则优先于较低级别声明的安全规则。如果交换这两个安全规则的顺序,所有请求都将应用 permitAll(),那么关于 /design 和 /orders 请求的规则将不起作用。
hasRole() 和 permitAll() 方法只是声明请求路径安全需求的两个方法。表 4.1 描述了所有可用的方法。
| 方法 | 做了什么 |
|---|---|
| access(String) | 如果 SpEL 表达式的值为 true,则允许访问 |
| anonymous() | 默认用户允许访问 |
| authenticated() | 认证用户允许访问 |
| denyAll() | 无条件拒绝所有访问 |
| fullyAuthenticated() | 如果用户是完全授权的(不是记住用户),则允许访问 |
| hasAnyAuthority(String…) | 如果用户有任意给定的权限,则允许访问 |
| hasAnyRole(String…) | 如果用户有任意给定的角色,则允许访问 |
| hasAuthority(String) | 如果用户有给定的权限,则允许访问 |
| hasIpAddress(String) | 来自给定 IP 地址的请求允许访问 |
| hasRole(String) | 如果用户有给定的角色,则允许访问 |
| not() | 拒绝任何其他访问方法 |
| permitAll() | 无条件允许访问 |
| rememberMe() | 允许认证了的同时标记了记住我的用户访问 |
表 4.1 中的大多数方法为请求处理提供了基本的安全规则,但是它们是自我限制的,只支持那些方法定义的安全规则。或者,可以使用 access() 方法提供 SpEL 表达式来声明更丰富的安全规则。Spring Security 扩展了 SpEL,包括几个特定于安全性的值和函数,如表 4.2 所示。
| Security 表达式 | 意指什么 |
|---|---|
| authentication | 用户认证对象 |
| denyAll | 通常值为 false |
| hasAnyRole(list of roles) | 如果用户有任何给定的角色,则为 true |
| hasRole(role) | 如果用户有给定的角色,则为 true |
| hasIpAddress(IP Address) | 如果请求来自给定 IP 地址,则为 true |
| isAnonymous() | 如果用户是默认用户,则为 true |
| isAuthenticated() | 如果用户是认证了的,则为 true |
| isFullyAuthenticated() | 如果用户被完全认证了的(不是使用记住我进行认证),则为 true |
| isRememberMe() | 如果用户被标记为记住我后认证了,则为 true |
| permitAll() | 通常值为 true |
| principal | 用户 pricipal 对象 |
表 4.2 中的大多数安全表达式扩展对应于表 4.1 中的类似方法。实际上,使用 access() 方法以及 hasRole() 和 permitAll 表达式,可以按如下方式重写 configure()。
1 |
|
乍一看,这似乎没什么大不了的。毕竟,这些表达式只反映了已经对方法调用所做的工作。但是表达式可以灵活得多。例如,假设(出于某种疯狂的原因)只想允许具有 ROLE_USER 权限的用户在周二(例如,在周二)创建新的 Taco;你可以重写表达式如下:
1 |
|
使用基于 SpEL 的安全约束,这种可能性实际上是无限的。我敢打赌,你已经在构思基于 SpEL 的有趣的安全约束了。
只需使用 access() 和程序清单 4.9 中的 SpEL 表达式,就可以满足 Taco Cloud 应用程序的授权需求。现在,让我们来看看如何定制登录页面来适应 Taco Cloud 应用程序的外观。
创建用户登录页面
默认的登录页面比你开始时使用的笨拙的 HTTP 基本对话框要好得多,但它仍然相当简单,不太适合 Taco Cloud 应用程序的其余部分。
要替换内置的登录页面,首先需要告诉 Spring Security 自定义登录页面的路径。这可以通过调用传递给 configure() 的 HttpSecurity 对象上的 formLogin() 来实现:
1 |
|
请注意,在调用 formLogin() 之前,需要使用对 and() 的调用来连接这一部分的配置和前面的部分。and() 方法表示已经完成了授权配置,并准备应用一些额外的 HTTP 配置。在开始新的配置部分时,将多次使用 and()。
连接之后,调用 formLogin() 开始配置自定义登录表单。之后对 loginPage() 的调用指定了将提供自定义登录页面的路径。当 Spring Security 确定用户未经身份验证并且需要登录时,它将把用户重定向到此路径。
现在需要提供一个控制器来处理该路径上的请求。因为你的登录页面非常简单 —— 除了一个视图什么都没有 —— 在 WebConfig 中声明它为一个视图控制器是很容易的。下面的 addViewControllers() 方法在将 “/” 映射到主控制器的视图控制器旁边设置登录页面视图控制器:
1 |
|
最后,需要定义 login 页面视图本身,因为使用 Thymeleaf 作为模板引擎,下面的 Thymeleaf 模板应该做得很好:
1 |
|
关于这个登录页面需要注意的关键事情是,它发布到的路径以及用户名和密码字段的名称。默认情况下,Spring Security 在 /login 监听登录请求,并期望用户名和密码字段命名为 username 和 password。但是,这是可配置的。例如,以下配置自定义路径和字段名:
1 | .and() |
这里,指定 Spring Security 应该监听请求 /authenticate 请求以处理登录提交。此外,用户名和密码字段现在应该命名为 user 和 pwd。
默认情况下,当 Spring Security 确定用户需要登录时,成功的登录将直接将用户带到他们所导航到的页面。如果用户要直接导航到登录页面,成功的登录将把他们带到根路径(例如,主页)。但你可以通过指定一个默认的成功页面来改变:
1 | .and() |
按照这里的配置,如果用户在直接进入登录页面后成功登录,那么他们将被引导到 /design 页面。
另外,可以强制用户在登录后进入设计页面,即使他们在登录之前已经在其他地方导航,方法是将 true 作为第二个参数传递给 defaultSuccessUrl:
1 | .and() |
现在已经处理了自定义登录页面,让我们来看看身份验证的另一面 —— 如何让用户登出。
登出
与登录应用程序同样重要的是登出。要启用登出功能,只需调用 HttpSecurity 对象上的 logout:
1 | .and() |
这将设置一个安全筛选器来拦截发送到 /logout 的请求。因此,要提供登出功能,只需在应用程序的视图中添加登出表单和按钮:
1 | <form method="POST" th:action="@{/logout}"> |
当用户单击按钮时,他们的 session 将被清除,他们将退出应用程序。默认情况下,它们将被重定向到登录页面,在那里它们可以再次登录。但是,如果希望它们被发送到另一个页面,可以调用 logoutSucessFilter() 来指定一个不同的登出后的登录页面:
1 | .and() |
在这个例子中,用户在登出后将被跳转到主页。
阻止跨站请求伪造攻击
跨站请求伪造(CSRF)是一种常见的安全攻击。它涉及到让用户在一个恶意设计的 web 页面上编写代码,这个页面会自动(通常是秘密地)代表经常遭受攻击的用户向另一个应用程序提交一个表单。例如,在攻击者的网站上,可能会向用户显示一个表单,该表单会自动向用户银行网站上的一个 URL 发送消息(该网站的设计可能很糟糕,很容易受到这种攻击),以转移资金。用户甚至可能不知道攻击发生了,直到他们注意到他们的帐户中少了钱。
为了防止此类攻击,应用程序可以在显示表单时生成 CSRF token,将该 token 放在隐藏字段中,然后将其存储在服务器上供以后使用。提交表单时,token 将与其他表单数据一起发送回服务器。然后服务器拦截请求,并与最初生成的 token 进行比较。如果 token 匹配,则允许继续执行请求。否则,表单一定是由一个不知道服务器生成的 token的恶意网站呈现的。
幸运的是,Spring Security 有内置的 CSRF 保护。更幸运的是,它是默认启用的,不需要显式地配置它。只需确保应用程序提交的任何表单都包含一个名为 _csrf 的字段,该字段包含 CSRF token。
Spring Security 甚至可以通过将 CSRF token 放在名为 _csrf 的请求属性中来简化这一过程。因此,可以使用以下代码,在 Thymeleaf 模板的一个隐藏字段中呈现 CSRF token:
1 | <input type="hidden" name="_csrf" th:value="${_csrf.token}"/> |
如果使用 Spring MVC 的 JSP 标签库或带有 Spring 安全方言的 Thymeleaf,那么甚至不需要显式地包含一个隐藏字段,隐藏字段将自动呈现。
在 Thymeleaf 中,只需确保 <form> 元素的一个属性被前缀为 Thymeleaf 属性。因为让 Thymeleaf 将路径呈现为上下文相关是很常见的,所以这通常不是问题。例如,Thymeleaf 渲染隐藏字段所需要的仅仅是 th:action 属性:
1 | <form method="POST" th:action="@{/login}" id="loginForm"> |
当然也可以禁用 CSRF 支持,但我不太愿意展示如何禁用。CSRF 保护很重要,而且在表单中很容易处理,所以没有理由禁用它,但如果你坚持禁用它,你可以这样调用 disable():
1 | .and() |
我再次提醒你不要禁用 CSRF 保护,特别是对于生产环境中的应用程序。
所有 web 层安全性现在都配置到 Taco Cloud 了。除此之外,现在有了一个自定义登录页面,并且能够根据 JPA 支持的用户存储库对用户进行身份验证。现在让我们看看如何获取有关登录用户的信息。
了解你的用户
通常,仅仅知道用户已经登录是不够的。通常重要的是要知道他们是谁,这样才能调整他们的体验。
例如,在 OrderController 中,当最初创建绑定到订单表单的订单对象时,如果能够用用户名和地址预先填充订单就更好了,这样他们就不必为每个订单重新输入它。也许更重要的是,在保存订单时,应该将订单实体与创建订单的用户关联起来。
为了在 Order 实体和 User 实体之间实现所需的连接,需要向 Order 类添加一个新属性:
1 |
|
此属性上的 @ManyToOne 注解表明一个订单属于单个用户,相反,一个用户可能有多个订单。
在 OrderController 中,processOrder() 方法负责保存订单。需要对其进行修改,以确定经过身份验证的用户是谁,并调用 Order 对象上的 setUser() 以将 Order 与该用户连接起来。
有几种方法可以确定用户是谁。以下是一些最常见的方法:
- 将主体对象注入控制器方法
- 将身份验证对象注入控制器方法
- 使用 SecurityContext 获取安全上下文
- 使用 @AuthenticationPrincipal 注解的方法
例如,可以修改 processOrder() 来接受 java.security.Principal 作为参数。然后可以使用主体名从 UserRepository 查找用户:
1 |
|
这可以很好地工作,但是它会将与安全性无关的代码与安全代码一起丢弃。可以通过修改 processOrder() 来减少一些特定于安全的代码,以接受 Authentication 对象作为参数而不是 Principal:
1 |
|
有了身份验证,可以调用 getPrincipal() 来获取主体对象,在本例中,该对象是一个用户。注意,getPrincipal() 返回一个 java.util.Object,因此需要将其转换为 User。
然而,也许最干净的解决方案是简单地接受 processOrder() 中的用户对象,但是使用 @AuthenticationPrincipal 对其进行注解,以便它成为身份验证的主体:
1 |
|
@AuthenticationPrincipal 的优点在于它不需要强制转换(与身份验证一样),并且将特定于安全性的代码限制为注释本身。当在 processOrder() 中获得 User 对象时,它已经准备好被使用并分配给订单了。
还有一种方法可以识别通过身份验证的用户是谁,尽管这种方法有点麻烦,因为它包含了大量与安全相关的代码。你可以从安全上下文获取一个认证对象,然后像这样请求它的主体:
1 | Authentication authentication = |
尽管这个代码段充满了与安全相关的代码,但是它与所描述的其他方法相比有一个优点:它可以在应用程序的任何地方使用,而不仅仅是在控制器的处理程序方法中,这使得它适合在较低级别的代码中使用。
小结
- Spring Security 自动配置是一种很好的开始学习安全的方式,但大多数应用程序需要明确地配置安全,以满足其独特的安全需求。
- 用户细节可以在关系数据库、LDAP 或完全自定义实现支持的用户存储中进行管理。
- Spring Security 自动防御 CSRF 攻击。
- 通过 SecurityContext 对象(从 SecurityContextHolder. getcontext() 中返回)或使用 @AuthenticationPrincipal 注入控制器中,可以获得认证用户的信息。
第 5 章 使用配置属性
本章内容:
- 微调自动配置 bean
- 将配置属性应用于应用程序组件
- 使用 Spring 配置文件
微调自动配置
在我们深入研究配置属性之前,有必要确定在 Spring 中有两种不同(但相关)的配置
- Bean wiring —— 它声明应用程序组件将在 Spring 应用程序上下文中作为 bean 创建,以及它们应该如何相互注入。
- Property injection —— 在 Spring 应用程序上下文中设置 bean 的值。
下面的 @Bean 方法,它为嵌入式 H2 数据库声明了一个数据源:
1 |
|
这里的 addScript() 和 addScripts() 方法设置了一些带有 SQL 脚本名称的字符串属性,这些 SQL 脚本应该在数据源准备好后应用到数据库中。如果不使用 Spring Boot,那么这就是配置 DataSource bean 的方式,而自动配置使此方法完全没有必要。
如果 H2 依赖项在运行时类路径中可用,那么 Spring Boot 将在 Spring 应用程序上下文中自动创建适当的数据源 bean。bean 应用于 schema.sql 和 data.sql 脚本的读取。
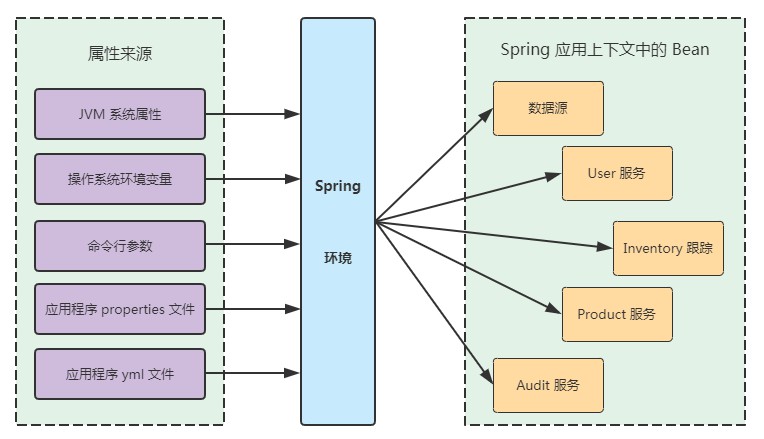
理解 Spring 环境抽象
Spring 环境抽象是任何可配置属性的一站式商店。它抽象了属性的起源,以便需要这些属性的 bean 可以从 Spring 本身使用它们。Spring 环境来自几个属性源,包括:
- JVM 系统属性
- 操作系统环境变量
- 命令行参数
- 应用程序属性配置文件
然后,它将这些属性聚合到单一的源中,从这个源中可以注入 Spring bean。图 5.1 演示了来自属性源的属性是如何通过 Spring 环境抽象流到 Spring bean 中的。
通过 Spring Boot 自动配置的 bean 都可以通过从 Spring 环境中提取的属性进行配置。作为一个简单的例子,假设希望应用程序的底层 servlet 容器侦听某些端口上的请求,而不是默认端口 8080。为此,通过在 src/main/resources/application.properties 文件中的 server.port 属性来指定一个不同的接口,如下所示:
1 | =9090 |
就我个人而言,我更喜欢在设置配置属性时使用 YAML。因此,我可能设置在 /src/main/resources/application.yml 文件中的 server.port 的值,而不是使用 application.properties 文件,如下所示:
1 | server: port: 9090 |
如果希望在外部配置该属性,还可以在启动应用程序时使用命令行参数指定端口:
1 | $ java -jar tacocloud-0.0.5-SNAPSHOT.jar --server.port=9090 |
如果想让应用程序总是在一个特定的端口上启动,可以把它设置为一个操作系统环境变量:
1 | $ export SERVER_PORT=9090 |
注意,在将属性设置为环境变量时,命名风格略有不同,以适应操作系统对环境变量名称的限制。Spring 能够将其分类并将 SERVER_PORT 转译为 server.port。
配置数据源
虽然可以显式地配置 DataSource bean,但这通常是不必要的。相反,通过配置属性为数据库配置 URL 和凭据更简单。例如,如果打算开始使用 MySQL 数据库,可以将以下配置属性添加到 application.yml:
1 | spring: |
虽然需要将适当的 JDBC 驱动程序添加到构建中,但通常不需要指定 JDBC 驱动程序类;Spring Boot 可以从数据库 URL 的结构中找到它。但如果有问题,可以试着设置 spring.datasource.schema 和 spring.datasource.data 属性:
1 | spring: |
可能显式数据源配置不是你的风格。相反,你可能更喜欢在 JNDI 中配置数据源,并让 Spring 从那里查找它。在这种情况下,通过配置 spring.datasource.jndi-name 来设置数据源:
1 | spring: |
如果设置了 spring.datasource.jndi-name 属性,那么其他数据源的连接属性(如果设置了)会被忽略。
配置嵌入式服务器
如果把 server.port 设置为 0 会发生什么:
1 | server: port: 0 |
尽管正在显式地设置 server.port 为 0,但是服务器不会在端口 0 上启动。相反,它将从随机选择的可用端口启动。这在运行自动化集成测试以确保任何并发运行的测试不会在硬编码端口号上发生冲突时非常有用。
但是底层服务器不仅仅是一个端口。需要对底层容器做的最常见的事情之一是将其设置为处理 HTTPS 请求。要做到这一点,你必须做的第一件事是通过使用 JDK 的 keytool 命令行工具创建一个密钥存储:
1 | $ keytool -keystore mykeys.jks -genkey -alias tomcat -keyalg RSA |
你将会被问到几个关于你的名字和公司的问题,这些问题大部分都是无关紧要的。但当被要求输入密码时,记住你的密码。对于本例,我选择 letmein 作为密码。
接下来,需要设置一些属性,用于在嵌入式服务器中启用 HTTPS。可以在命令行中指定它们,但是那样会非常不方便。相反,可能会在 application.properties 或 application.yml 文件中设置它们。在 application.yml 中,属性可能是这样的:
1 | server: |
在这里 server.port 属性设置为 8443,这是开发 HTTPS 服务器的常用选择。server.ssl.key-store 属性设置为创建密钥存储库文件的路径。这里显示了一个 file:// URL 来从文件系统加载它,但是如果将它打包到应用程序 JAR 文件中,将使用一个 classpath: URL来引用它。同时 server.ssl.key-store-password 和 server.ssl.key-password 属性都被设置为创建密钥存储时指定的密码值。
有了这些属性,应用程序应该侦听端口 8443 上的 HTTPS 请求。根据使用的浏览器,可能会遇到服务器无法验证其身份的警告。在开发期间从本地主机提供服务时,这没有什么可担心的。
配置日志
默认情况下,Spring Boot 通过 Logback 配置日志,默认为 INFO 级别,然后写入控制台。在运行应用程序和其他示例时,可能已经在应用程序日志中看到了大量的 INFO 级别的日志条目。
要完全控制日志配置,可以在类路径的根目录(在 src/main/resources 中)创建 log .xml 文件。下面是一个简单的 log .xml 文件的例子:
1 | <configuration> |
除了用于日志的模式外,Logback 配置或多或少与没有 log .xml 文件时得到的默认配置相同。但是通过编辑 logback.xml,可以完全控制应用程序的日志文件。
对日志配置最常见的更改是更改日志级别,可能还会指定应该写入日志的文件。使用 Spring Boot 配置属性,可以在不创建 log .xml 文件的情况下进行这些更改。
要设置日志记录级别,需要创建以 logging.level 为前缀的属性,后面接上要为其设置日志级别的日志记录器的名称。例如,假设想将 root 日志级别设置为 WARN,但是将 Spring 安全日志设置为 DEBUG 级别。可以像下面这样设置:
1 | logging: |
另外,可以将 Spring Security 包的名称折叠成一行,以便于阅读:
1 | logging: |
现在,假设希望将日志条目写入位于 /var/logs/ 文件夹下的 TacoCloud.log 文件。loggin.path 和 logging.file 属性可以帮助实现这一点:
1 | logging: |
假设应用程序对 /var/logs/ 文件夹有写权限,那么日志将被写到 /var/logs/TacoCloud.log 文件中。默认情况下,日志文件在大小达到 10 MB 时就会进行循环写入。
使用特殊的属性值
在设置属性时,不限于将它们的值声明为硬编码的字符串和数值。相反,可以从其他配置属性派生它们的值。
例如,假设(不管出于什么原因)想要设置一个名为 greeting.welcome 的属性,用于返回另一个名为 spring.application.name 的属性的值。为此,在设置 greeting.welcome 时可以使用 ${} 占位符标记:
1 | greeting: |
你甚至可以把这个占位符嵌入到其他文本中:
1 | greeting: |
正如你所看到的,使用配置属性配置 Spring 自己的组件可以很容易地将值注入这些组件的属性并调整自动配置。配置属性并不专属于 Spring 创建的 bean。只需稍加努力,就可以利用你自己的 bean 中的配置属性。接下来让我们来看看怎么做。
创建自己的配置属性
正如前面提到的,配置属性只不过是指定来接受 Spring 环境抽象配置的 bean 的属性。没有提到的是如何指定这些 bean 来使用这些配置。
为了支持配置属性的属性注入,Spring Boot 提供了@ConfigurationProperties 注释。当放置在任何 Spring bean 上时,它指定可以从 Spring 环境中的属性注入到该 bean 的属性。
为了演示 @ConfigurationProperties 是如何工作的,假设已经将以下方法添加到 OrderController 中,以列出经过身份验证的用户之前的订单:
1 |
|
除此之外,还需要向 OrderRepository 添加了必要的 findByUser() 方法:
1 | List<Order> findByUserOrderByPlaceAtDesc(User user); |
请注意,此存储库方法是用 OrderByPlacedAtDesc 子句命名的。OrderBy 部分指定一个属性,通过该属性对结果排序 —— 在本例中是 placedAt 属性。最后的 Desc 让排序按降序进行。因此,返回的订单列表将按时间倒序排序。
如前所述,在用户下了一些订单之后,这个控制器方法可能会很有用。但对于最狂热的 taco 鉴赏家来说,它可能会变得有点笨拙。在浏览器中显示的一些命令是有用的;一长串没完没了的订单只是噪音。假设希望将显示的订单数量限制为最近的 20 个订单,可以更改 ordersForUser():
1 |
|
随着这个改变,OrderRepository 跟着需要变为:
1 | List<Order> findByUserOrderByPlaceAtDesc(User user, Pageable pageable); |
这里,已经更改了 findByUserOrderByPlacedAtDesc() 方法的签名,以接受可分页的参数。可分页是 Spring Data 通过页码和页面大小选择结果子集的方式。在 ordersForUser() 控制器方法中,构建了一个 PageRequest 对象,该对象实现了 Pageable 来请求第一个页面(page zero),页面大小为 20,以便为用户获得最多 20 个最近下的订单。
虽然这工作得非常好,但它让我感到有点不安,因为已经硬编码了页面大小。如果后来发现 20 个订单太多,而决定将其更改为 10 个订单,该怎么办?因为它是硬编码的,所以必须重新构建和重新部署应用程序。
可以使用自定义配置属性来设置页面大小,而不是硬编码页面大小。首先,需要向 OrderController 添加一个名为 pageSize 的新属性,然后在 OrderController 上使用 @ConfigurationProperties 注解 ,如下面的程序清单所示。
1 |
|
程序清单 5.1 中最重要的变化是增加了 @ConfigurationProperties 注解。其 prefix 属性设置为 taco。这意味着在设置 pageSize 属性时,需要使用一个名为 taco.orders.pageSize 的配置属性。
新的 pageSize 属性默认为 20。但是可以通过设置 taco.orders.pageSize 属性轻松地将其更改为想要的任何值。例如,可以在 application.yml 中设置此属性:
1 | taco: |
或者,如果需要在生产环境中进行快速更改,可以通过设置 taco.orders.pageSize 属性作为环境变量来重新构建和重新部署应用程序:
1 | $ export TACO_ORDERS_PAGESIZE=10 |
可以设置配置属性的任何方法,都可以用来调整最近订单页面的大小。接下来,我们将研究如何在属性持有者中设置配置数据。
定义配置属性持有者
这里没有说 @ConfigurationProperties 必须设置在控制器或任何其他特定类型的 bean 上,@ConfigurationProperties 实际上经常放在 bean 上。在应用程序中,这些 bean 的惟一目的是作为配置数据的持有者,这使控制器和其他应用程序类不涉及特定于配置的细节,它还使得在几个可能使用该信息的 bean 之间共享公共配置属性变得很容易。
对于 OrderController 中的 pageSize 属性,可以将其提取到一个单独的类中。下面的程序清单以这种方式使用了 OrderProps 类。
1 | package tacos.web; |
正如在 OrderController 中所做的,pageSize 属性默认为 20,同时 OrderProps 使用 @ConfigurationProperties 进行注解,以具有 taco.orders 前缀。
它还带有 @Component 注解,因此 Spring 组件扫描时将自动发现它并在 Spring 应用程序上下文中将其创建为 bean。这很重要,因为下一步是将 OrderProps bean 注入到 OrderController 中。
关于配置属性持有者,没有什么特别的。它们是从 Spring 环境中注入属性的 bean。它们可以被注入到任何需要这些属性的其他 bean 中。对于 OrderController,这意味着从 OrderController 中删除 pageSize 属性,而不是注入并使用 OrderProps bean:
1 |
|
现在 OrderController 不再负责处理它自己的配置属性。这使得 OrderController 中的代码稍微整洁一些,并允许在任何其他需要它们的 bean 中重用 OrderProps 中的属性。此外,正在收集与一个地方的订单相关的配置属性:OrderProps 类。如果需要添加、删除、重命名或以其他方式更改其中的属性,只需要在 OrderProps 中应用这些更改。
例如,假设在其他几个 bean 中使用 pageSize 属性,这时最好对该属性应用一些验证,以将其值限制为不小于 5 和不大于 25。如果没有持有者 bean,将不得不对 OrderController、pageSize 属性以及使用该属性的所有其他类应用验证注解。但是因为已经将 pageSize 提取到 OrderProps 中,所以只需要更改 OrderProps:
1 | package tacos.web; |
尽管可以很容易地将 @Validated、@Min 和 @Max 注解应用到 OrderController(以及可以注入 OrderProps 的任何其他 bean),但这只会使 OrderController 更加混乱。通过使用配置属性持有者 bean,就在在一个地方收集了配置属性的细节,使得需要这些属性的类相对干净。
声明配置属性元数据
根据 IDE 的情况,你可能已经注意到 application.yml(或是 appication.properties)中的 taco.orders.pageSize 属性有一个警告,说类似未知属性 ‘taco’ 之类的东西。出现此警告是因为缺少关于刚刚创建的配置属性的元数据。图 5.2 显示了我将鼠标悬停在 Spring Tool Suite 中 taco 属性时的效果。
配置属性元数据是完全可选的,并不会阻止配置属性的工作。但是元数据对于提供有关配置属性的最小文档非常有用,特别是在 IDE 中。
例如,当我将鼠标悬停在 security.user.password 属性上时,如图5.3所示,虽然悬停帮助你获得的是最小的,但它足以帮助你了解属性的用途以及如何使用它。
为了帮助那些可能使用你定义的配置属性(甚至可能是你自己定义的)的人,通常最好是围绕这些属性创建一些元数据,至少它消除了 IDE 中那些恼人的黄色警告。
要为自定义配置属性创建元数据,需要在 META-INF(例如,在项目下的 src/main/resources/META-INF 中)中创建一个名为 addition-spring-configuration-metadata.json 的文件。
快速修复缺失的元数据。
如果正在使用 Spring Tool Suite,则有一个用于创建丢失的属性元数据的快速修复选项。将光标放在缺少元数据警告的行上,然后按下 Mac 上的 CMD-1 或 Windows 和 Linux 上的 Ctrl-1 弹出的快速修复(参见图 5.4)。
然后选择 Create Metadata for… 选项来为属性添加一些元数据(在 additional-spring-configuration-metadata 中)。如果该文件不存在,则创建该文件。
对于 taco.orders.pageSize 属性,可以用以下 JSON 设置元数据:
1 | { |
注意,元数据中引用的属性名是 taco.orders.pagesize。Spring Boot 灵活的属性命名允许属性名的变化,比如 taco.orders.page-size 相当于 taco.orders.pageSize。
有了这些元数据,警告就应该消失了。更重要的是,如果你悬停在 taco.orders.pageSize 属性,你将看到如图 5.5 所示的描述。
另外,如图 5.6 所示,可以从 IDE 获得自动完成帮助,就像 Springprovided 的配置属性一样。

配置属性对于调整自动配置的组件和注入到应用程序 bean 中的细节非常有用。但是,如果需要为不同的部署环境配置不同的属性呢?让我们看看如何使用 Spring 配置文件来设置特定于环境的配置。
使用 profile 文件进行配置
当应用程序部署到不同的运行时环境时,通常会有一些配置细节不同。例如,数据库连接的细节在开发环境中可能与在 QA 环境中不一样,在生产环境中可能还不一样。在一个环境中唯一配置属性的一种方法是使用环境变量来指定配置属性,而不是在 application.properties 或 application.yml 中定义它们。
例如,在开发期间,可以依赖于自动配置的嵌入式 H2 数据库。但在生产中,可以将数据库配置属性设置为环境变量,如下所示:
1 | export SPRING_DATASOURCE_URL=jdbc:mysql://localhost/tacocloud |
尽管这样做是可行的,但是将一两个以上的配置属性指定为环境变量就会变得有点麻烦。此外,没有跟踪环境变量更改的好方法,也没有在出现错误时轻松回滚更改的好方法。
相反,我更喜欢利用 Spring profile 文件。profile 文件是一种条件配置类型,其中根据运行时激活的 profile 文件应用或忽略不同的 bean、配置类和配置属性。
例如,假设出于开发和调试的目的,希望使用嵌入式 H2 数据库,并且希望将 Taco Cloud 代码的日志级别设置为 DEBUG。但是在生产中,需要使用一个外部 MySQL 数据库,并将日志记录级别设置为 WARN。在开发环境中,很容易不设置任何数据源属性并获得自动配置的 H2 数据库。至于 DEBUG 级别的日志记录,可以在 application.yml 中设置 logging.level.tacos 属性。
1 | logging: |
这正是开发目的所需要的。但是,如果要将此应用程序部署到生产环境中,而不需要对 application.yml 进行进一步更改,仍然可以获得对于 tacos 包的调试日志和嵌入式 H2 数据库。需要的是定义一个具有适合生产的属性的 profile 文件。
定义特定 profile 的属性
定义特定 profile 文件的属性的一种方法是创建另一个仅包含用于生产的属性的 YAML 或属性文件。文件的名称应该遵循这个约定:application-{profile 名称}.yml 或 application-{profile 名称}.properties。然后可以指定适合该配置文件的配置属性。例如,可以创建一个名为 application-prod.yml 的新文件,包含以下属性:
1 | spring: |
另一种指定特定 profile 文件的属性的方法只适用于 YAML 配置。它涉及在应用程序中将特定 profile 的属性与非 profile 的属性一起放在 application.yml 中,由三个连字符分隔。将生产属性应用于 application.yml 时,整个 application.yml 应该是这样的:
1 | logging: |
这个 application.yml 文件由一组三重连字符(—)分成两个部分。第二部分为 spring.profiles 指定一个值,这个值指示了随后应用于 prod 配置文件的属性。另一方面,第一部分没有为 spring.profiles 指定值。因此,它的属性对于所有 profile 文件都是通用的,或者如果指定的 profile 文件没有设置其他属性,它就是默认的。
无论应用程序运行时哪个配置文件处于活动状态,tacos 包的日志级别都将通过默认配置文件中的属性设置为 DEBUG。但是,如果名为 prod 的配置文件是活动的,那么 logging.level.tacos 属性将会被重写为 WARN。同样,如果 prod 配置文件是活动的,那么数据源属性将设置为使用外部 MySQL 数据库。
通过创建使用 application-{profile 名称}.yml 或 application-{profile 名称}.properties 这种模式命名的其他 YAML 或 properties 文件,可以为任意数量的 profile 文件定义属性。或者在 application.yml 中再输入三个破折号通过 spring.profiles 来指定配置文件名称。然后添加需要的所有特定 profile 文件的属性。
激活 profile 文件
设置特定 profile 属性没有什么意思,除非这些 profile 处于活动状态。但是要如何激活一个 profile 文件呢?让一个 profile 文件处于激活状态需要做的只是将 spring.profiles.active 属性的值指定为需要激活的 profile 的名称。例如,可以像下面这样设置 application.yml 中的这个属性:
1 | spring: |
但是这可能是设定一个活动 profile 最糟糕的方式了。如果在 application.yml 中设置了激活的 profile,然后那个 profile 文件就变成了默认 profile 文件,那么就没有达到生产环境特定属性与开发环境特定属性分离的目的。相反,我推荐使用环境变量设置激活的 profile。在生产环境,像下面这样设置 SPRING_PROFILES_ACTIVE:
1 | % export SPRING_PROFILES_ACTIVE=prod |
这样设置完成后,部署于那台机器的任何应用程序将会使用 prod profile,同时相应的配置属性将优先于默认配置文件中的属性。
如果使用可执行的 JAR 文件来运行应用程序,你可能也可以通过命令行设置激活的 profile 文件,如下所示:
1 | % java -jar taco-cloud.jar --spring.profiles.active=prod |
请注意 spring.profiles.active 属性名包含的是复数单词 profiles。这意味着可以指定多个活动 profiles 文件。通常,这是一个逗号分隔的列表,当它设置一个环境变量:
1 | % export SPRING_PROFILES_ACTIVE=prod,audit,ha |
但是在 YAML 中,需要像下面这样指定它:
1 | spring: |
同样值得注意的是,如果将 Spring 应用程序部署到 Cloud Foundry 中,一个名为 cloud 的配置文件会自动激活。如果 Cloud Foundry 是生产环境,那么需要确保在 cloud profile 文件中指定了特定于生产环境的属性。
事实证明,配置文件只对在 Spring 应用程序中有条件地设置配置属性有用。让我们看看如何声明特定活动 profile 文件的 bean。
有条件地使用 profile 文件创建 bean
有时候,为不同的配置文件提供一组惟一的 bean 是很有用的。通常,不管哪个 profile 文件是活动的,Java 配置类中声明的任何 bean 都会被创建。但是,假设只有在某个配置文件处于活动状态时才需要创建一些 bean,在这种情况下,@Profile 注解可以将 bean 指定为只适用于给定的 profile 文件。
例如,在 TacoCloudApplication 中声明了一个 CommandLineRunner bean,用于在应用程序启动时加载嵌入式数据库中的成分数据。这对于开发来说很好,但是在生产应用程序中是不必要的(也是不受欢迎的)。为了防止在每次应用程序在生产部署中启动时加载成分数据,可以使用 @Profile 像下面这样注解 CommandLineRunner bean 方法:
1 |
|
或是假设需要在 dev profile 或是 qa profile 被激活时创建 CommandLineRunner,在这种情况下,可以列出需要的 profile:
1 |
|
这样成分数据只会在 dev 或是 qa profile 文件被激活时才会被加载。这就意味着需要在开发环境运行应用程序时,将 dev profile 激活。如果这个 CommandLineRunner bean 总是被创建,除非 prod 配置文件是活动的,那就更方便了。在这种情况下,你可以像这样应用 @Profile:
1 |
|
在这里,感叹号 !否定了配置文件名称。实际上,它声明如果 prod 配置文件不是活动的,就会创建 CommandLineRunner bean。
也可以在整个 @Configuration 注解的类上使用 @Profile。例如,假设要将 CommandLineRunner bean 提取到一个名为 DevelopmentConfig 的单独配置类中。然后你可以用 @Profile 来注解 DevelopmentConfig:
1 |
|
在这里,CommandLineRunner bean(以及在 DevelopmentConfig 中定义的任何其他 bean)仅在 prod 和 qa 配置文件都不活动的情况下才会被创建。
小结
- 可以使用 @ConfigurationProperties 注解 Spring bean,以支持从几个属性源之一注入值。
- 可以在命令行参数、环境变量、JVM 系统属性、属性文件或 YAML 文件等选项中设置配置属性。
- 配置属性可用于覆盖自动配置设置,包括指定数据源 URL 和日志级别的能力。
- Spring profile 文件可以与属性源一起使用,根据活动配置文件有条件地设置配置属性。
第二部分 集成 Spring
第 2 部分的章节介绍了一些有助于将 Spring 应用程序与其他应用程序集成在一起的主题。
第 6 章 创建 REST 服务
本章内容:
- 在 Spring MVC 中定义 REST 端点
- 启用超链接 REST 资源
- 自动生成基于存储库的 REST 端点
许多应用程序采用了一种常见的设计:将用户界面推近客户端,而服务器公开一个 API,通过该 API,所有类型的客户端都可以与后端进行交互。
在本章中,将使用 Spring 为 Taco Cloud 应用程序提供 REST API。
编写 RESTful 控制器
Spring MVC 为各种类型的 HTTP 请求支持少量其他注解,如表 6.1 所示。
| 注解 | HTTP 方法 | 典型用法 |
|---|---|---|
| @GetMapping | HTTP GET 请求 | 读取资源数据 |
| @PostMapping | HTTP POST 请求 | 创建资源 |
| @PutMapping | HTTP PUT 请求 | 更新资源 |
| @PatchMapping | HTTP PATCH 请求 | 更新资源 |
| @DeleteMapping | HTTP DELETE 请求 | 删除资源 |
| @RequestMapping | 通用请求处理 |
从服务器获取数据
处理 /design/recent 接口的 GET 请求 ,并使用一个最新设计的 taco 列表进行响应。
1 | package tacos.web.api; |
@RestController 注解有两个用途。首先,它是一个原型注解,通过组件扫描来标记一个类。与 REST 的讨论最相关的是,@RestController 注解告诉 Spring,控制器中的所有处理程序方法都应该将它们的返回值直接写入响应体,而不是在模型中被带到视图中进行呈现。
或者,可以使用 @Controller 来注解 DesignTacoController,就像使用任何 Spring MVC 控制器一样。但是,还需要使用 @ResponseBody 注解所有处理程序方法,以获得相同的结果。另一个选项是返回一个 ResponseEntity 对象。
类级别的 @RequestMapping 注解与 recentTacos() 方法上的 @GetMapping 注解一起工作,以指定 recentTacos() 方法负责处理 /design/recent 接口的 GET 请求。
注意,@RequestMapping 注解还设置了一个 produces 属性。这指定了 DesignTacoController 中的任何处理程序方法只在请求的 Accept 头包含 “application/json” 时才处理请求。这不仅限制了 API 只生成 JSON 结果,还允许另一个控制器(可能是第 2 章中的 DesignTacoController)处理具有相同路径的请求,只要这些请求不需要 JSON 输出。
在程序清单 6.2 中可能注意到的另一件事是,该类是用 @CrossOrigin 注解了的。由于应用程序的 Angular 部分将运行在独立于 API 的主机或端口上(至少目前是这样),web 浏览器将阻止 Angular 客户端使用 API。这个限制可以通过在服务器响应中包含 CORS(跨源资源共享)头来克服。Spring 使得使用 @CrossOrigin 注解应用 CORS 变得很容易。正如这里所应用的,@CrossOrigin 允许来自任何域的客户端使用 API。
recentTacos() 方法中的逻辑相当简单。它构造了一个 PageRequest 对象,该对象指定只想要包含 12 个结果的第一个(第 0 个)页面,结果按照 taco 的创建日期降序排序。简而言之就是你想要一打最新设计的 tacos。PageRequest 被传递到 TacoRepository 的 findAll() 方法的调用中,结果页面的内容被返回给客户机(如程序清单 6.1 所示,它将作为模型数据显示给用户)。
现在,假设需要提供一个端点,该端点通过其 ID 获取单个 taco。通过在处理程序方法的路径中使用占位符变量并接受 path 变量的方法,可以捕获该 ID 并使用它通过存储库查找 taco 对象:
1 |
|
这个控制器方法处理 /design/{id} 的 GET 请求,其中路径的 {id} 部分是占位符。请求中的实际值指定给 id 参数,该参数通过 @PathVariable 映射到 {id}占位符。
在 tacoById() 内部,将 id 参数传递给存储库的 findById() 方法来获取 Taco。findById() 返回一个可选的
如果 ID 不匹配任何已知的 taco,则返回 null,然而,这并不理想。通过返回 null,客户端接收到一个空体响应和一个 HTTP 状态码为 200(OK)的响应。客户端会收到一个不能使用的响应,但是状态代码表明一切正常。更好的方法是返回一个带有 HTTP 404(NOT FOUND)状态的响应。
正如它目前所写的,没有简单的方法可以从 tacoById() 返回 404 状态代码。但如果你做一些小的调整,你可以设置适当的状态代码: