全书分为 4 部分。第 1 部分介绍 Spring 框架的核心知识。第 2 部分在此基础上介绍了如何使用 Spring 构建 Web 应用程序。第 3 部分告别前端,介绍了如何在应用程序的后端使用 Spring。第 4 部分描述了如何使用 Spring 与其他的应用和服务进行集成。
Spring 的核心
spring 的主要特性是依赖注入 (dependency injection, DI) 和面向切面编程 (aspect-oriented programming, AOP)
Spring 之旅
本章内容
- 探索 Spring 的核心模块
- 解耦应用对象
- 使用 AOP 横切关注点
- Spring 的 Bean 容器
在诞生之初,创建 Spring 的主要目的是用来替代更加重量级的企业级 Java 技术,尤其是 EJB。
简化 Java 开发
Spring 是一个开源框架,最早由 Rod Johnson 创建,并在《Expert One-on-One:J2EE Design and Development》(http://amzn.com/076454385)这本著作中进行了介绍。
一个 Spring 组件可以是任何形式的 POJO。在本书中,我采用 JavaBean 的广泛定义,即 POJO 的同义词。
Spring 最根本的使命:简化 Java 开发。
为了降低 Java 开发的复杂性,Spring 采用了以下 4 种策略::
- 基于 POJO 的轻量级和最小侵入性编程
- 通过依赖注入和面向接口实现松耦合
- 基于切面和惯例进行声明式编程
- 通过切面和模板减少样板式代码
几乎 Spring 所做的任何事情都可以追溯到上述的一条或多条策略。
激发 POJO 的潜能
Spring 不会强迫你实现 Spring 规范的接口或继承Spring 规范的类,相反,在基于 Spring 构建的应用中,它的类通常没有任何痕迹表明你使用了 Spring。最坏的场景是,一个类或许会使用 Spring 注解,但它依旧是 POJO。
1 | package com.habuma.spring; |
可以看到,这是一个简单普通的 Java 类 —— POJO。没有任何地方表明它是一个 Spring 组件。Spring 的非侵入编程模型意味着这个类在 Spring 应用和非 Spring 应用中都可以发挥同样的作用。Spring 赋予 POJO 魔力的方式之一就是通过 DI 来装配它们。
依赖注入
任何一个有实际意义的应用都是由两个或更多的类组成,这些类之间相互协作完成特定的业务逻辑。通常,每个对象负责管理与自己相互协作的对象(即它所以来的对象)的引用,这将会导致高度耦合和难以测试的代码。
1 | package com.springinaction.knights; |
第一:DamselRescuingKnight 紧密地和 RescueDamselQuest 耦合到了一起,骑士只能拯救少女,无法进行其他的探险任务。
第二:DamselRescuingKnight 将无法进行测试。
耦合具有两面性(two-headed beast)。一方面,紧密耦合的代码难以测试、难以复用、难以理解,并且典型地表现出“打地鼠”式的 bug 特性(修复一个 bug,将会出现一个或者更多新的 bug)。另一方面,一定程度的耦合又是必须的——完全没有耦合的代码什么也做不了。为了完成有实际意义的功能,不同的类必须以适当的方式进行交互。总而言之,耦合是必须的,但应当被小心谨慎地管理。
通过依赖注入 (DI),对象的依赖关系将由负责协调系统中各个对象的第三方组件在创建对象时设定。对象无需自行创建或管理它们的依赖关系,如图 1.1 所示,依赖关系将被自动注入到需要它们的对象当中去。
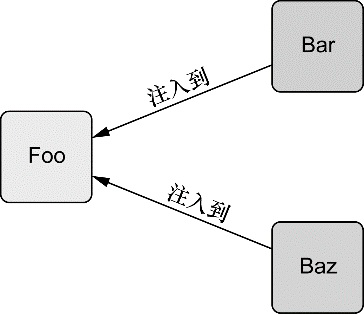
为了展示这一点,让我们看一看程序清单 1.3 中的 BraveKnight,这个骑士不仅勇敢,而且能挑战任何形式的探险。
1 | public class BraveKnight implements Knight{ |
BraveKnight 没有自行创建探险任务,而是在构造时把探险任务作为构造器参数传入——这是依赖注入的方式之一,即构造器注入。
更重要的是,它被传入的探险类型是 Quest,也就是一个所有探险任务都必须实现的接口。所以,BraveKnight 能够相应任意一种 Quest 实现。
这里的要点是 BraveKnight 没有与任何特定的 Quest 实现发生耦合。这就是依赖注入最大的好处——松耦合。如果一个对象只通过接口(而不是具体实现或初始化的过程)来表明依赖关系,那么这种依赖就能够在对象本身毫不知情的情况下,用不同的具体实现进行替换。
对依赖进行替换的一个最常用方法就是在测试的时候使用 mock 实现。
1 | package com.springinaction.knights; |
你可以使用 mock 框架 Mockito 去创建一个 Quest 接口的 mock 实现。通过这个 mock 对象,就可以创建一个新的 BraveKnight 实例,并通过构造器注入这个 mock Quest。当调用 embarkOnQuest() 方法时,你可以要求 Mockito 框架验证 Quest 的 mock 实现的 embark() 方法仅仅被调用了一次。
将Quest注入到Knight中
假设,希望 BraveKnight 所要进行探险任务是杀死一只怪龙,那么 SlayDragonQuest 也许是挺合适的。
1 | import java.io.PrintStream; |
与其他的 Java 入门样例有所不同,SlayDragonQuest 没有使用 System.out.println(),而是在构造方法中请求一个更为通用的 PrintStream。
创建应用组件之间协作的行为通常称为装配 (wiring)。Spring 有多种装配 Bean 的方式,采用 XML 配置是常用装配方式之一。
1 |
|
在这里,BraveKnight 和 SlayDragonQuest 被声明为 Spring 中的 bean。就 BraveKnight bean 来讲,它在构造时传入了对 SlayDragonQuest bean 的引用,将其作为构造器参数。同时,SlayDragonQuest bean 的声明使用了 Spring 表达式语言(Spring Expression Language),将 System.out(这是一个PrintStream) 传入到了 SlayDragonQuest 的构造器中。
如果 XML 配置不符合你的喜好的话,Spring 还支持使用 Java 来描述配置。比如,程序清单 1.7 展现了基于 Java 的配置,它的功能与程序清单 1.6 相同。
1 | import org.springframework.context.annotation.Bean; |
Spring 通过它的配置,可以在不改变所依赖的类的情况下,修改依赖关系。
现在已经声明了BraveKnight 和 Quest 的关系,接下来我们只需要装载 XML 配置文件,并把应用启动起来。
观察它如何工作
Spring 通过应用上下文 (Application Context) 装载 Bean 的定义并把它们组装起来。Spring 应用上下文全权负责对象的创建和组装。Spring 自带了多种应用上下文的实现,它们之间的主要区别是如何加载它们的配置。
因为 knights.xml 中的 bean 是使用 XML 文件进行配置的,所以选择 ClassPathXmlApplicationContext 作为应用上下文相对是比较合适的。该类加载位于应用程序类路径下的一个或多个 XML 配置文件。程序清单 1.8 中的 main() 方法调用ClassPathXmlApplicationContext 加载 knights.xml,并获得 Knight 对象的引用。
1 | package com.springinaction.knights; |
这里的 main() 方法基于 knights.xml 文件创建了 Spring 应用上下文。随后它调用该应用上下文获取一个 ID 为 knight 的 bean。得到 Knight 对象的引用后,只需简单调用 embarkOnQuest() 方法就可以执行所赋予的探险任务了。注意这个类完全不知道我们的英雄骑士接受哪种探险任务,而且完全没有意识到这是由 BraveKnight 来执行的。只有 knights.xml 文件知道哪个骑士执行哪种探险任务。
应用切面
依赖注入让相互协作的软件组件保持松散耦合,而 AOP 编程允许你把遍布应用各处的功能分离出来形成可重用的组件。
面向切面编程往往被定义为促使应用程序分离关注点的一项技术。系统由许多不同组件组成,每一个组件各负责一块特定的功能。除了实现自身核心的功能之外,这些组件还经常承担着额外的职责。诸如日志、事务管理和安全此类的系统服务经常融入到有自身核心业务逻辑的组件中去,这些系统服务通常被称为横切关注点,因为它们总是跨越系统的多个组件。
如果将这些关注点分散到多个组件中去,代码将引入双重复杂性:
- 遍布系统的关注点实现代码将会重复出现在多个组件中。这意味着如果你要改变这些关注点的逻辑,你必须修改各个模块的相关实现。
- 组件会因为那些与自身核心业务无关的代码而变得混乱。一个向地址簿增加地址条目的方法应该只关注如何添加地址,而不应该关注它是不是安全的或者是否需要支持事务。
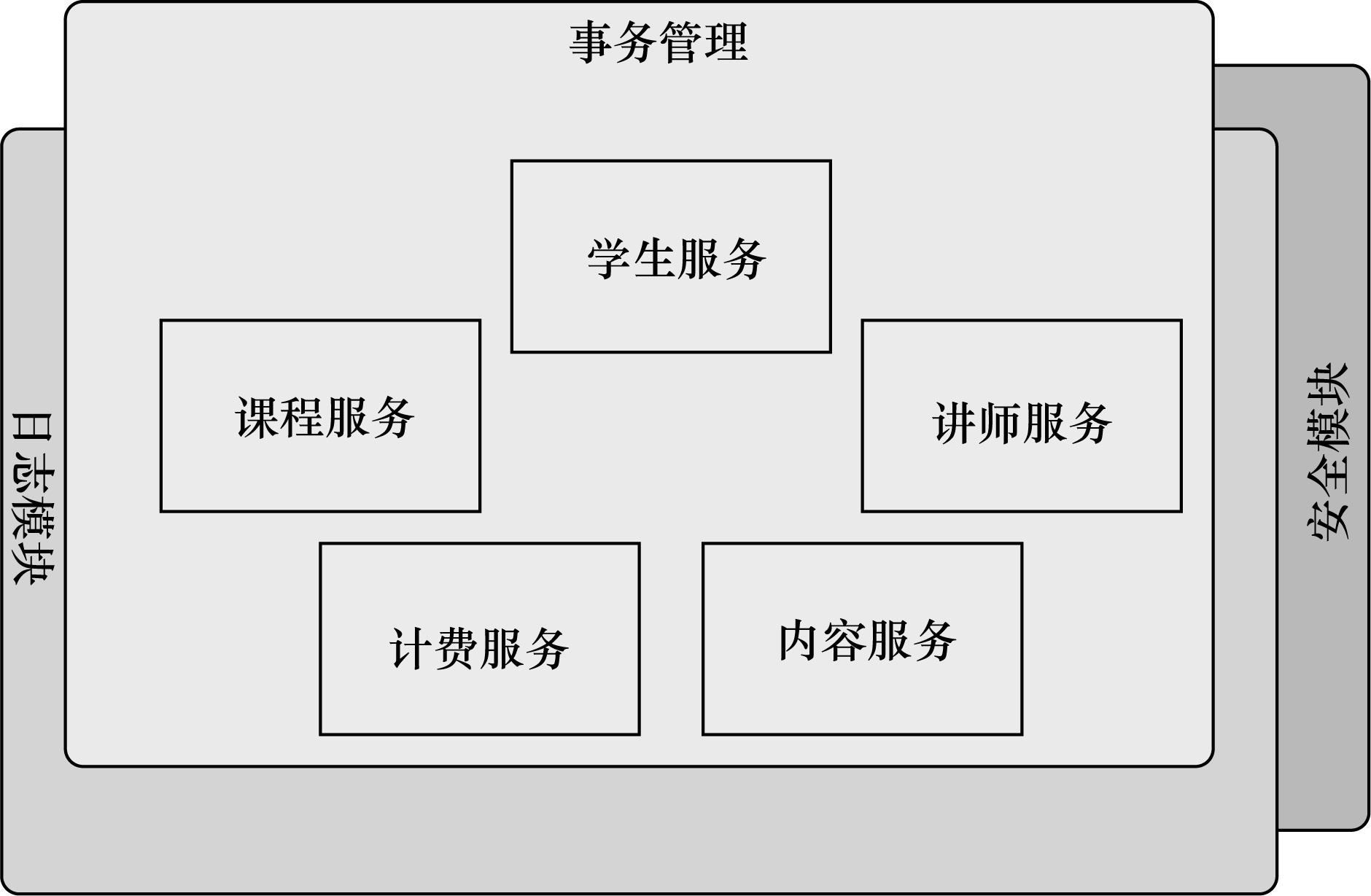
图 1.2 展示了这种复杂性。左边的业务对象与系统级服务结合得过于紧密。每个对象不但要知道它需要记日志、进行安全控制和参与事务,还要亲自执行这些服务。
AOP 使这些服务模块化,并以声明的方式将它们应用到需要的组件中去。结果是这些组件具有更高的内聚性以及更加关注自身业务,完全不需要了解可能涉及的系统服务的复杂性。总之,AOP 确保 POJO 保持简单。
如图 1.3 所示,我们可以把切面想象为覆盖在很多组件之上的一个外壳。应用是由那些实现各自业务功能的模块组成的。借助 AOP,可以使用各种功能层去包裹核心业务层。这些层以声明的方式灵活地应用到系统中,你的核心应用甚至根本不知道它们的存在。这是一个非常强大的理念,可以将安全、事务和日志关注点与核心业务逻辑相分离。
为了示范在 Spring 中如何应用切面,让我们重新回到骑士的例子,并为它添加一个切面。
AOP 应用
每一个人都熟知骑士所做的任何事情,这是因为吟游诗人用诗歌记载了骑士的事迹并将其进行传唱。假设我们需要使用吟游诗人这个服务类来记载骑士的所有事迹。程序清单 1.9 展示了我们会使用的 Minstrel 类。
1 | import java.io.PrintStream; |
正如你所看到的那样,Minstrel 是只有两个方法的简单类。在骑士执行每一个探险任务之前,singBeforeQuest() 方法会被调用;在骑士完成探险任务之后,singAfterQuest() 方法会被调用。在这两种情况下,Minstrel 都会通过一个 PrintStream 类来歌颂骑士的事迹,这个类是通过构造器注入进来的。
把 Minstrel 加入你的代码中并使其运行起来,这对你来说是小事一桩。我们适当做一下调整从而让 BraveKnight 可以使用 Minstrel。程序清单 1.10 展示了将 BraveKnight 和 Minstrel 组合起来的第一次尝试。
1 | package com.springinaction.knights; |
这应该可以达到预期效果。现在,你所需要做的就是回到 Spring 配置中,声明 Minstrel bean 并将其注入到 BraveKnight的构造器之中。
管理他的吟游诗人真的是骑士职责范围内的工作吗?为什么骑士还需要提醒吟游诗人去做他份内的事情呢?
此外,因为骑士需要知道吟游诗人,所以就必须把吟游诗人注入到 BarveKnight 类中。这不仅使 BraveKnight 的代码复杂化了,而且还让我疑惑是否还需要一个不需要吟游诗人的骑士呢?如果 Minstrel 为 null 会发生什么呢?我是否应该引入一个空值校验逻辑来覆盖该场景?
简单的 BraveKnight 类开始变得复杂,如果你还需要应对没有吟游诗人时的场景,那代码会变得更复杂。但利用 AOP,你可以声明吟游诗人必须歌颂骑士的探险事迹,而骑士本身并不用直接访问 Minstrel 的方法。
要将 Minstrel 抽象为一个切面,你所需要做的事情就是在一个 Spring 配置文件中声明它。程序清单 1.11 是更新后的knights.xml 文件,Minstrel 被声明为一个切面。
1 |
|
这里使用了 Spring 的 AOP 配置的命名空间把 Minstrel Bean 声明为一个切面。首先,必须把 Minstrel 声明为一个 Bean,然后再 <aop:aspect> 元素中引用该 Bean。为了进一步定义切面,必须使用 <aop:before> 来声明在 embarkOnQuest() 方法执行前调用 Minstrel 的 singBeforeQuest() 方法。这种方式称为前置通知。同时,使用 <aop:after> 的方式被称为后置通知。
在这两种方式中,pointcut-ref 属性都引用了名字为 embark 的切入点。该切入点是在前边的 <pointcut> 元素中定义的,并配置 expression 属性来选择所应用的通知。表达式的语法采用的是 AspectJ 的切点表达式语言。
通过少量的 XML 配置,就可以把 Minstrel 声明为一个 Spring 切面。现在我们可以从这个示例中获得两个重要的观点。
首先,Minstrel 仍然是一个 POJO,没有任何代码表明它要被作为一个切面使用。当我们按照上面那样进行配置后,在 Spring 的上下文中,Minstrel 实际上已经变成一个切面了。
其次,也是最重要的,Minstrel 可以被应用到 BraveKnight 中,而 BraveKnight 不需要显式地调用它。实际上,BraveKnight 完全不知道 Minstrel 的存在。
必须还要指出的是,尽管我们使用 Spring 魔法把 Minstrel 转变为一个切面,但首先要把它声明为一个Spring bean。能够为其他 Spring bean 做到的事情都可以同样应用到 Spring 切面中,例如为它们注入依赖。
使用模板消除样板式代码
你是否写过这样的代码,当编写的时候总会感觉以前曾经这么写过?我的朋友,这不是似曾相识。这是样板式的代码(boilerplate code)。通常为了实现通用的和简单的任务,你不得不一遍遍地重复编写这样的代码。
遗憾的是,它们中的很多是因为使用 Java API 而导致的样板式代码。样板式代码的一个常见范例是使用 JDBC 访问数据库查询数据。举个例子,如果你曾经用过 JDBC,那么你或许会写出类似下面的代码。
1 | public Employee getEmployeeById(long id) { |
正如你所看到的,这段 JDBC 代码查询数据库获得员工姓名和薪水。我打赌你很难把上面的代码逐行看完,这是因为少量查询员工的代码淹没在一堆 JDBC 的样板式代码中。首先你需要创建一个数据库连接,然后再创建一个语句对象,最后你才能进行查询。为了平息 JDBC 可能会出现的怒火,你必须捕捉 SQLException,这是一个检查型异常,即使它抛出后你也做不了太多事情。最后,毕竟该说的也说了,该做的也做了,你不得不清理战场,关闭数据库连接、语句和结果集。同样为了平息 JDBC 可能会出现的怒火,你依然要捕捉 SQLException。
程序清单 1.12 中的代码和你实现其他 JDBC 操作时所写的代码几乎是相同的。只有少量的代码与查询员工逻辑有关系,其他的代码都是 JDBC 的样板代码。
JDBC 不是产生样板式代码的唯一场景。在许多编程场景中往往都会导致类似的样板式代码,JMS、JNDI 和使用 REST 服务通常也涉及大量的重复代码。
Spring 旨在通过模板封装来消除样板式代码。Spring 的 JdbcTemplate 使得在执行数据库操作时,避免传统的 JDBC 样板式代码称为了可能。
举个例子,使用 Spring 的 JdbcTemplate(利用了 Java 5 特性的 JdbcTemplate 实现)重写的 getEmployeeById() 方法仅仅关注于获取员工数据的核心逻辑,而不需要迎合 JDBC API 的需求。程序清单 1.13 展示了修订后的 getEmployeeById() 方法。
1 | public Employee getEmployeeByid(long id) { |
正如你所看到的,新版本的 getEmployeeById() 简单多了,而且仅仅关注于从数据库中查询员工。模板的 queryForObject() 方法需要一个 SQL 查询语句,一个 RowMapper 对象(把数据映射为一个域对象),零个或多个查询参数。GetEmployeeById() 方法再也看不到以前的 JDBC 样板式代码了,它们全部被封装到了模板中。
我已经向你展示了 Spring 通过面向 POJO 编程、DI、切面和模板技术来简化 Java 开发中的复杂性。在这个过程中,我展示了在基于 XML 的配置文件中如何配置 bean 和切面,但这些文件是如何加载的呢?它们被加载到哪里去了?让我们再了解下 Spring 容器,这是应用中的所有 bean 所驻留的地方。
容纳你的 Bean
在基于 Spring 的应用中,应用对象生存于 Spring 容器中。Spring 容器创建对象,装配它们,配置它们,管理它们的整个生命周期,从生存到死亡(或者从创建到销毁)。
在下一章,你将了解如何配置Spring,从而让它知道该创建、配置和组装哪些对象。但首先,最重要的是了解容纳对象的容器。理解容器将有助于理解对象是如何被管理的。
容器是 Spring 框架的核心。Spring 容器使用 DI 管理构成应用的组件,它会创建相互协作的组件之间的关联。毫无疑问,这些对象更简单干净,更易于理解,更易于重用并且更易于进行单元测试。
Spring 容器并不是只有一个。Spring 自带了多个容器实现,可以归为两种不同的类型。bean 工厂(由 org.springframework.beans.factory.beanFactory 接口定义)是最简单的容器,提供基本的 DI 支持。应用上下文(由 org.springframework.context.ApplicationContext 接口定义)基于 BeanFactory 构建,并提供应用框架级别的服务,例如从属性文件解析文本信息以及发布应用事件给感兴趣的事件监听者。虽然我们可以在 bean 工厂和应用上下文之间任选一种,但 bean 工厂对大多数应用来说往往太低级了,因此,应用上下文要比 bean 工厂更受欢迎。
使用应用上下文
Spring 自带了多种类型的应用上下文。下面罗列的几个是你最有可能遇到的。
- AnnotationConfigApplicationContext:从一个或多个基于 Java 的配置类中加载 Spring 应用上下文。
- AnnotationConfigWebApplicationContext:从一个或多个基于 Java 的配置类中加载 Spring Web 应用上下文。
- ClassPathXmlApplicationContext:从类路径下的一个或多个 XML 配置文件中加载上下文定义,把应用上下文的定义文件作为类资源。
- FileSystemXmlapplicationcontext:从文件系统下的一个或多个 XML 配置文件中加载上下文定义。
- XmlWebApplicationContext:从 Web 应用下的一个或多个 XML 配置文件中加载上下文定义。
无论是从文件系统中装载应用上下文还是从类路径下装载应用上下文,将 bean 加载到 bean 工厂的过程都是相似的。例如,如下代码展示了如何加载一个 FileSystemXmlApplicationContext:
1 | ApplicationContext context = new FileSystemXmlApplicationContext("c:/kinght.xml"); |
类似地,你可以使用 ClassPathXmlApplicationContext 从应用的类路径下加载应用上下文:
1 | Application context = new ClassPathXmlApplicationContext("kight.xml"); |
使用 FileSystemXmlApplicationContext 和使用 ClassPathXmlApplicationContext 的区别在于:FileSystemXmlApplicationContext 在指定的文件系统路
径下查找 knight.xml 文件;而 ClassPathXmlApplicationContext 是在所有的类路径(包含 JAR 文件)下查找 knight.xml 文件。
如果你想从 Java 配置中加载应用上下文,那么可以使用 AnnotationConfigApplicationContext:
1 | ApplicationContext context = new AnnotationConfigApplicationContext(com.springinaction.knights.config.KnightConfig.class); |
在这里没有指定加载 Spring 应用上下文所需的 XML 文件,AnnotationConfigApplicationContext 通过一个配置类加载 bean。
应用上下文准备就绪之后,我们就可以调用上下文的 getBean() 方法从 Spring 容器中获取 bean。
现在你应该基本了解了如何创建 Spring 容器,让我们对容器中 bean 的生命周期做更进一步的探究。
Bean 的生命周期
在传统的 Java 应用中,bean 的生命周期很简单。使用 Java 关键字 new 进行 bean 实例化,然后该 bean 就可以使用了。一旦该 bean 不再被使用,则由 Java 自动进行垃圾回收。
相比之下,Spring 容器中的 bean 的生命周期就显得相对复杂多了。正确理解 Spring bean 的生命周期非常重要,因为你或许要利用 Spring 提供的扩展点来自定义 bean 的创建过程。图 1.5 展示了 bean 装载到 Spring应用上下文中的一个典型的生命周期过程。
正确理解 Spring Bean 的生命周期非常重要,因为你或许要利用 Spring 提供的扩展点来自定义 Bean 的创建过程。
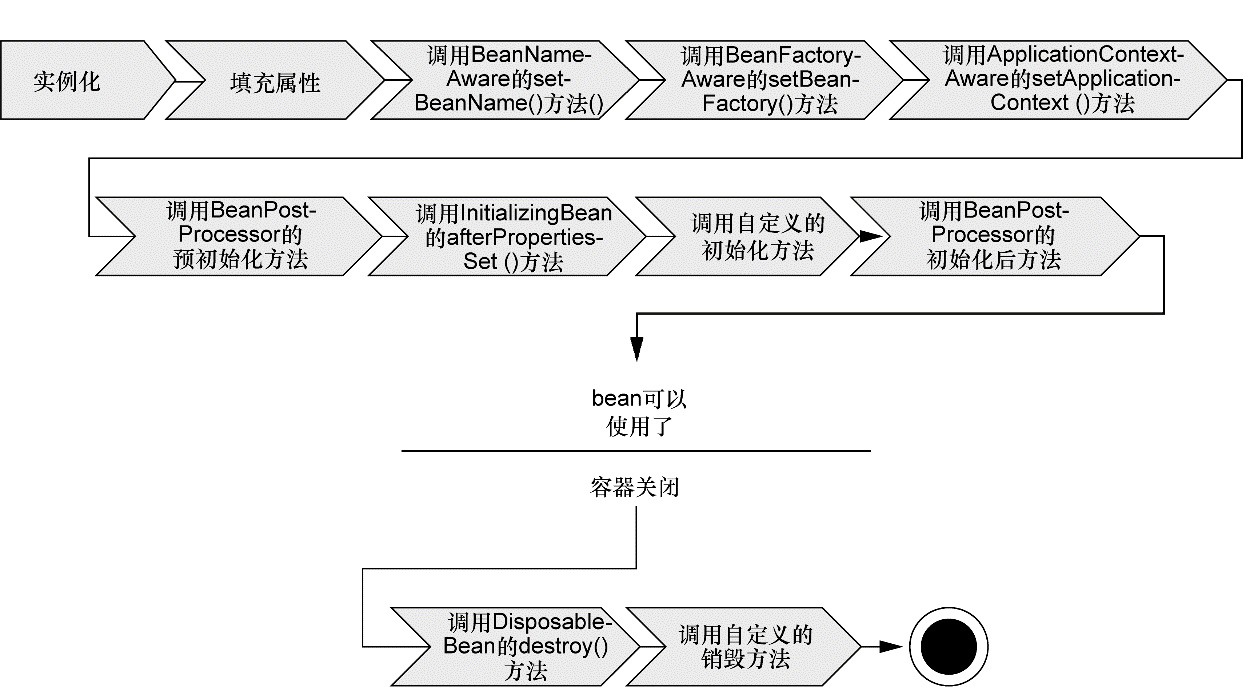
正如你所见,在 bean 准备就绪之前,bean 工厂执行了若干启动步骤。我们对图 1.5 进行详细描述:
- Spring 对 Bean 进行初始化
- Spring 将值和 Bean 的引用注入进 Bean 对应的属性中
- 如果 Bean 实现了 BeanNameAware 接口,Spring 将 Bean 的 ID 传递给 setBeanName() 接口方法
- 如果 Bean 实现了 BeanFactoryAware 接口,Spring 将调用 setBeanFactory() 接口方法,将 BeanFactory 容器实例传入
- 如果 Bean 实现了 ApplicationContextAware 接口,Spring 将调用 setApplicationContext() 接口方法,将应用上下文的引用传入
- 如果 Bean 实现了 BeanPostProcessor 接口,Spring 将调用 postProcessorBeforeInitialization() 接口方法
- 如果 Bean 实现了 InitializingBean 接口,Spring 将调用它们的 afterPropertiesSet() 接口。类似的,如果 Bean 使用 init-method 声明了初始化方法,该方法也会被调用
- 如果 Bean 实现了 BeanPostProcessor 接口,Spring 将调用 postProcessorAfterInitialization() 方法
- 此时,Bean 已经准备就绪,可以被应用程序使用了,它们将一直驻留在应用上下文中,知道该应用上下文被销毁
- 如果 Bean 实现了 DisposableBean 接口,Spring 将调用 destory() 接口方法。同样,如果 Bean 使用 destory-method 声明了销毁方法,该方法也会被调用
现在你已经了解了如何创建和加载一个 Spring 容器。但是一个空的容器并没有太大的价值,在你把东西放进去之前,它里面什么都没有。为了从 Spring 的 DI 中受益,我们必须将应用对象装配进 Spring 容器中。我们将在第2章对bean装配进行更详细的探讨。
我们现在首先浏览一下 Spring 的体系结构,了解一下 Spring 框架的基本组成部分和最新版本的 Spring 所发布的新特性。
俯瞰 Spring 的风景线
正如你所看到的,Spring 框架关注于通过 DI、AOP 和消除样板式代码来简化企业级 Java 开发。即使这是 Spring 所能做的全部事情,那 Spring 也值得一用。但是,Spring 实际上的功能超乎你的想象。
在 Spring 框架的范畴内,你会发现 Spring 简化 Java 开发的多种方式。但在 Spring 框架之外还存在一个构建在核心框架之上的庞大生态圈,它将 Spring 扩展到不同的领域,例如 Web 服务、REST、移动开发以及 NoSQL。
首先让我们拆开 Spring 框架的核心来看看它究竟为我们带来了什么,然后我们再浏览下 Spring Portfolio 中的其他成员。
Spring 模块
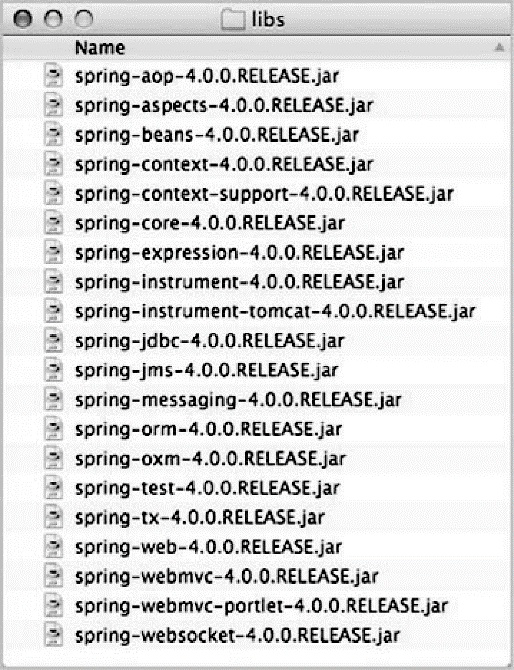
当我们下载 Spring 发布版本并查看其 lib 目录时,会发现里面有多个 JAR 文件。在 Spring 4.0 中,Spring 框架的发布版本包括了 20 个不同的模块,每个模块会有 3 个 JAR 文件(二进制类库、源码的 JAR 文件以及 JavaDoc 的 JAR 文件)。完整的库 JAR 文件如图 1.6 所示。
这些模块依据其所属的功能可以划分为 6 类不同的功能,如图 1.7 所示。
总体而言,这些模块为开发企业级应用提供了所需的一切。但是你也不必将应用建立在整个 Spring 框架之上,你可以自由地选择适合自身应用需求的 Spring 模块;当 Spring 不能满足需求时,完全可以考虑其他选择。事实上,Spring 甚至提供了与其他第三方框架和类库的集成点,这样你就不需要自己编写这样的代码了。
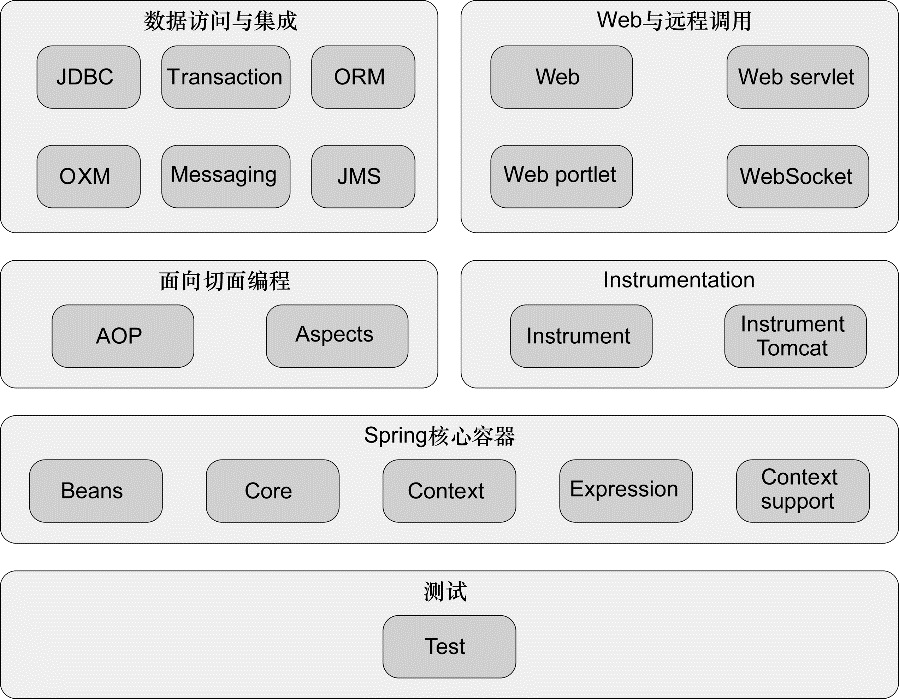
让我们逐一浏览 Spring 的模块,看看它们是如何构建起Spring整体蓝图的。
核心 Spring 容器
容器是 Spring 框架最核心的部分,它负责 Spring 应用中的 Bean 的创建、配置和管理。在该模块中, Spring 的 Bean 工厂提供了依赖注入,在 Bean 工厂之上,有几种 Spring 应用上下文的实现,每一种提供了配置 Spring 的不同方式。
除了 bean 工厂和应用上下文,该模块也提供了许多企业服务,例如 Email、JNDI 访问、EJB 集成和调度。
所有的 Spring 模块都构建于核心容器之上。当你配置应用时,其实你隐式地使用了这些类。贯穿本书,我们都会涉及到核心模块,在第 2 章中我们将会深入探讨 Spring 的 DI。
AOP 模块
在 AOP 模块中,Spring 对面向切面编程提供了丰富的支持。这个模块是 Spring 应用系统中开发切面的基础。与 DI 一样,AOP 可以帮助应用对象解耦。借助 AOP,可以将遍布应用的关注点(例如事务和安全)从它们所应用的对象中解耦出来。
我们将在第4章深入探讨Spring对AOP支持。
数据集成和访问
使用 JDBC 编写代码通常会导致大量的样板式代码,例如获得数据库连接、创建语句、处理结果集到最后关闭数据库连接。Spring 的 JDBC 和 DAO (data access objects) 封装了这些样板式代码,使我们的数据库代码变得简单明了,还可以避免因为释放数据库资源而引发的问题。该模块在几种数据库服务的错误信息之上构建了一个语义丰富的异常层,以后我们再也不需要解释哪些隐晦专有的 SQL 错误信息了。
Spring 为那些喜欢 ORM (object-relational mapping) 工具的开发者提供了 ORM 模块。Spring 的 ORM 模块建立在对 DAO 的支持之上,并为某些 ORM 框架提供了一种构建 DAO 的简便方式。Spring 没有去创建自己的 ORM 解决方案,而是对许多流行的 ORM 框架进行了集成。Spring 的事务管理支持所有的 ORM 框架以及 JDBC。
在第 10 章讨论 Spring 数据访问时,你会看到 Spring 基于模板的 JDBC 抽象层能够极大地简化 JDBC 代码。
本模块同样包含了在 JMS(Java Message Service)之上构建的 Spring 抽象层,它会使用消息以异步的方式与其他应用集成。从 Spring 3.0 开始,本模块还包含对象到 XML 映射的特性,它最初是 Spring WebService 项目的一部分。
除此之外,本模块会使用 Spring AOP 模块为 Spring 应用中的对象提供事务管理服务。
Web 和远程调用
MVC (Model-View-Controller) 模式已经被普遍的接受为构建 Web 应用的方法,它有助于将用户界面逻辑和业务逻辑分离。Java 从来不缺少 MVC 框架,Apache 的Struts、JSF、WebWork 和 Tapestry 都是可选的最流行的 MVC 框架。
虽然 Spring 集成了多种流行的 MVC 框架,但它的 Web 和远程调用模块自带了一个强大的 MVC 框架,有助于应用提升 Web 层技术的松散耦合。在第 5 章到第 7 章中,我们将会学习 Spring 的 MVC 框架。
除了面向用户的 Web 应用,该模块还提供了多种构建与其他应用交互的远程调用方案。Spring 远程调用功能集成了 RMI(Remote Method Invocation)、Hessian、Burlap、JAX-WS,同时 Spring 还自带了一个远程调用框架:HTTP invoker。Spring 还提供了暴露和使用 REST API 的良好支持。
我们将会在第 15章 讨论 Spring 的远程调用功能。在第 16 章学习如何创建和使用 REST API。
Instrumentation
Spring 的 Instrumentation 模块提供了为 JVM 添加代理 (agent) 的功能。具体来讲,它为 Tomcat 提供了一个织入代理,能够为 Tomcat 传递类文件,就像这些文件是被类加载器加载的一样。
如果这听起来有点难以理解,不必对此过于担心。这个模块所提供的 Instrumentation 使用场景非常有限,在本书中,我们不会介绍该模块。
测试
鉴于开发者自测的重要性,Spring 提供了测试模块以致力于 Spring 应用的测试。
通过该模块,你会发现 Spring 为使用 JNDI、Servlet 和 Portlet 编写单元测试提供了一系列的 mock 对象实现。对于集成测试,该模块为加载 Spring 应用上下文中的 bean 集合以及与 Spring 上下文中的 bean 进行交互提供了支持。
在本书中,有很多的样例都是测试驱动的,将会使用到 Spring 所提供的测试功能。
Spring Portfolio
当谈论 Spring时,其实它远远超出我们的想象。事实上,Spring 远不是 Spring 框架所下载的那些。如果仅仅停留在核心的 Spring 框架层面,我们将错过 Spring Portfolio 所提供的巨额财富。整个 Spring Portfolio 包括多个构建于核心 Spring 框架之上的框架和类库。概括地讲,整个 Spring Portfolio 包括多个构建于核心 Spring 框架之上的框架和类库。概括地讲,整个 Spring Portfolio 几乎为每一个领域的 Java 开发都提供了 Spring 编程模型。
或许需要几卷书才能覆盖 Spring Portfolio 所提供的所有内容,这也远远超出了本书的范围。不过,我们会介绍 Spring Portfolio 中的一些项目,同样,我们将体验一下核心框架之外的另一番风景。
Spring Web Flow
Spring Web Flow 建立于 Spring MVC 框架之上,它为基于流程的会话式 Web 应用(可以想一下购物车或者向导功能)提供了支持。我们将在第 8 章讨论更多关于 Spring Web Flow 的内容,你还可以访问 Spring Web Flow 的主页(http://projects.spring.io/spring-webflow/)。
Spring Web Service
虽然核心的 Spring 框架提供了将 Spring bean 以声明的方式发布为 Web Service 的功能,但是这些服务是基于一个具有争议性的架构(拙劣的契约后置模型)之上而构建的。这些服务的契约由bean的接口来决定。 Spring Web Service 提供了契约优先的 Web Service 模型,服务的实现都是为了满足服务的契约而编写的。
本书不会再探讨 Spring Web Service,但是你可以浏览站点 http://docs.spring.io/spring- ws/site/ 来了解更多关于 Spring Web Service 的信息。
Spring Security
安全对于许多应用都是一个非常关键的切面。利用 Spring AOP,Spring Security 为 Spring 应用提供了声明式的安全机制。你将会在第 9 章看到如何为应用的 Web 层添加 Spring Security 功能。同时,我们还会在第 14 章重新回到 Spring Security 的话题,学习如何保护方法调用。你可以在主页 http://projects.spring.io/spring-security/ 上获得关于 Spring Security 的更多信息。
Spring Integration
许多企业级应用都需要与其他应用进行交互。Spring Integration 提供了多种通用应用集成模式的 Spring 声明式风格实现。
我们不会在本书覆盖 Spring Integration 的内容,但是如果你想了解更多关于 Spring Integration 的信息,我推荐 Mark Fisher、Jonas Partner、Marius Bogoevici 和 Iwein Fuld 编写的《Spring Integration in Action》(Manning,2012,www.manning.com/fisher/);或者你还可以访问 Spring Integration 的主页 http://projects.spring.io/spring-integration/。
Spring Batch
当我们需要对数据进行大量操作时,没有任何技术可以比批处理更胜任这种场景。如果需要开发一个批处理应用,你可以通过 Spring Batch,使用 Spring 强大的面向 POJO 的编程模型。
Spring Batch 超出了本书的范畴,但是你可以阅读 ArnaudCogoluegnes、Thierry Templier、Gary Gregory 和 Olivier Bazoud 编写的 《Spring Batch in Action》(Manning,2012,www.manning.com/templier/),或者访问 Spring Batch的主页 http://projects.spring.io/ spring-batch/。
Spring Data
Spring Data 使得在 Spring 中使用任何数据库都变得非常容易。尽管关系型数据库统治企业级应用多年,但是现代化的应用正在认识到并不是所有的数据都适合放在一张表中的行和列中。一种新的数据库种类,通常被称之为 NoSQL 数据库,提供了使用数据的新方法,这些方法会比传统的关系型数据库更为合适。
不管你使用文档数据库,如 MongoDB,图数据库,如 Neo4j,还是传统的关系型数据库,Spring Data 都为持久化提供了一种简单的编程模型。这包括为多种数据库类型提供了一种自动化的 Repository 机制,它负责为你创建 Repository 的实现。
我们将会在第 11 章看到如何使用 Spring Data 简化 Java PersistenceAPI(JPA)开发,然后在第 12 章,将相关的讨论拓展至几种 NoSQL 数据库。
Spring Social
社交网络是互联网领域中新兴的一种潮流,越来越多的应用正在融入社交网络网站,例如 Facebook 或者 Twitter。如果对此感兴趣,你可以了解一下 Spring Social,这是 Spring 的一个社交网络扩展模块。
不过,Spring Social 并不仅仅是 tweet 和好友。尽管名字是这样,但 Spring Social 更多的是关注连接(connect),而不是社交(social)。它能够帮助你通过 REST API 连接Spring应用,其中有些 Spring 应用可能原本并没有任何社交方面的功能目标。
限于篇幅,我们在本书中不会涉及 Spring Social。但是,如果你对 Spring 如何帮助你连接 Facebook 或 Twitter 感兴趣的话,可以查看网址 https://spring.io/guides/gs/accessing- facebook/ 和 https://spring.io/guides/gs/accessing-twitter/中的入门指南。
Spring Mobile
移动应用是另一个引人瞩目的软件开发领域。智能手机和平板设备已成为许多用户首选的客户端。Spring Mobile 是 Spring MVC 新的扩展模块,用于支持移动 Web 应用开发。
Spring for Android
与 Spring Mobile 相关的是 Spring Android 项目。这个新项目,旨在通过 Spring 框架为开发基于 Android 设备的本地应用提供某些简单的支持。
最初,这个项目提供了 Spring RestTemplate 的一个可以用于 Android 应用之中的版本。它还能与 Spring Social 协作,使得原生应用可以通过 REST API 进行社交网络的连接。
本书中,我不会讨论 Spring for Android,不过你可以通过 http://projects.spring.io /spring-android/ 了解更多内容。
Spring Boot
Spring 极大地简化了众多的编程任务,减少甚至消除了很多样板式代码,如果没有 Spring 的话,在日常工作中你不得不编写这样的样板代码。Spring Boot 是一个崭新的令人兴奋的项目,它以 Spring 的视角,致力于简化 Spring 本身。
Spring Boot 大量依赖于自动配置技术,它能够消除大部分(在很多场景中,甚至是全部)Spring 配置。它还提供了多个Starter 项目,不管你使用 Maven 还是 Gradle,这都能减少 Spring 工程构建文件的大小。
在本书即将结束的第 21 章,我们将会学习 Spring Boot。
Spring 新功能
当本书的第 3 版交付印刷的时候,当时 Spring 的最新版本是 3.0.5。那大约是在 3 年前,从那时到现在发生了很多的变化。Spring 框架经历了 3 个重要的发布版本——3.1、3.2 以及现在的 4.0——每个版本都带来了新的特性和增强,以简化应用程序的研发。Spring Portfolio 中的一些成员项目也经历了重要的变更。
本书也进行了更新,试图涵盖这些发布版本中众多最令人兴奋和有用的特性。但现在,我们先简要地了解一下 Spring 带来了哪些新功能。
Spring 3.1 新特性
Spring 3.1 带来了多项有用的新特性和增强,其中有很多都是关于如何简化和改善配置的。除此之外,Spring 3.1 还提供了声明式缓存的支持以及众多针对 Spring MVC的功能增强。
- 为了解决各种环境下(如开发、测试和生产)选择不同配置的问题,Spring 3.1 引入了环境 profile 功能。借助于 profile,就能根据应用部署在什么环境之中选择不同的数据源 bean;
- 在 Spring 3.0 基于 Java 的配置之上,Spring 3.1 添加了多个 enable 注解,这样就能使用这个注解启用 Spring 的特定功能;
- 添加了 Spring 对声明式缓存的支持,能够使用简单的注解声明缓存边界和规则,这与你以前声明事务边界很类似;
- 新添加的用于构造器注入的 c 命名空间,它类似于 Spring 2.0 所提供的面向属性的p命名空间,p 命名空间用于属性注入,它们都是非常简洁易用的;
- Spring 开始支持 Servlet 3.0,包括在基于 Java 的配置中声明 Servlet 和 Filter,而不再借助于 web.xml;
- 改善 Spring 对 JPA 的支持,使得它能够在 Spring 中完整地配置 JPA,不必再使用 persistence.xml 文件。
Spring 3.1 还包含了多项针对 Spring MVC 的功能增强:
- 自动绑定路径变量到模型属性中;
- 提供了@RequestMappingproduces和consumes属性,用于匹配请求中的Accept和Content-Type头部信息;
- 提供了@RequestPart注解,用于将multipart请求中的某些部分绑定到处理器的方法参数中;
- 支持Flash属性(在redirect请求之后依然能够存活的属性)以及用于在请求间存放flash属性的RedirectAttributes类型。
Spring 的 JpaTemplate 和 JpaDaoSupport 类被废弃掉了
现在,让我们看一下 Spring 3.2 提供了什么新功能。
Spring 3.2 新特性
Spring 3.2 是主要关注 Spring MVC 的一个发布版本。
- Spring 3.2 的控制器(Controller)可以使用 Servlet 3.0 的异步请求,允许在一个独立的线程中处理请求,从而将 Servlet 线程解放出来处理更多的请求;
- Spring 3.2 引入了 Spring MVC 测试框架,用于为控制器编写更为丰富的测试,断言它们作为控制器的行为行为是否正确,而且在使用的过程中并不需要 Servlet 容器;
- 基于 RestTemplate 的客户端的测试支持,在测试的过程中,不需要往真正的 REST 端点上发送请求;
- @ControllerAdvice 注解能够将通用的 @ExceptionHandler、@InitBinder 和 @ModelAttributes 方法收集到一个类中,并应用到所有控制器上;
- 在 Spring 3.2 之前,只能通过 ContentNegotiatingViewResolver 使用完整的内容协商(full content negotiation)功能。但是在 Spring 3.2 中,完整的内容协商功能可以在整个 Spring MVC 中使用,即便是依赖于消息转换器(message converter)使用和产生内容的控制器方法也能使用该功能;
- Spring MVC 3.2 包含了一个新的 @MatrixVariable 注解,这个注解能够将请求中的矩阵变量(matrix variable)绑定到处理器的方法参数中;
- 基础的抽象类 AbstractDispatcherServletInitializer 能够非常便利地配置 DispatcherServlet,而不必再使用 web.xml。与之类似,当你希望通过基于 Java 的方式来配置 Spring 的时候,可以使用 Abstract- AnnotationConfigDispatcherServletInitializer 的子类;
- 新增了 ResponseEntityExceptionHandler,可以用来替代 DefaultHandlerExceptionResolver。ResponseEntityExceptionHandler方法会返回
ResponseEntity<Object>,而不是 ModelAndView;RestTemplate 和 @RequestBody 的参数可以支持范型; - RestTemplate 和 @RequestMapping 可以支持 HTTP PATCH 方法;
- 在拦截器匹配时,支持使用 URL 模式将其排除在拦截器的处理功能之外。
虽然 Spring MVC 是 Spring 3.2 改善的核心内容,但是它依然还增加了多项非 MVC 的功能改善。下面列出了 Spring 3.2 中几项最为有意思的新特性:
- @Autowired、@Value 和 @Bean 注解能够作为元注解,用于创建自定义的注入和bean声明注解;
- @DateTimeFormat 注解不再强依赖 JodaTime。如果提供了 JodaTime,就会使用它,否则的话,会使用 SimpleDateFormat;
- Spring 的声明式缓存提供了对 JCache 0.5 的支持;
- 支持定义全局的格式来解析和渲染日期与时间;
- 在集成测试中,能够配置和加载 WebApplicationContext;
- 在集成测试中,能够针对 request 和 session 作用域的 bean 进行测试。
在本书的多个章节中,都能看到Spring 3.2的特性,尤其是在Web和REST相关的章节中。
Spring 4.0 新特性
当编写本书时,Spring 4.0 是最新的发布版本。在 Spring 4.0 中包含了很多令人兴奋的新特性,包括:
- Spring 提供了对 WebSocke t编程的支持,包括支持 JSR-356 ——Java API for WebSocket;
- 鉴于 WebSocket 仅仅提供了一种低层次的 API,急需高层次的抽象,因此 Spring 4.0 在 WebSocket 之上提供了一个高层次的面向消息的编程模型,该模型基于SockJS,并且包含了对 STOMP 协议的支持;
- 新的消息(messaging)模块,很多的类型来源于 Spring Integration 项目。这个消息模块支持 Spring 的 SockJS/STOMP 功能,同时提供了基于模板的方式发布消息;
- Spring 是第一批(如果不说是第一个的话)支持 Java 8 特性的 Java 框架,比如它所支持的 lambda 表达式。别的暂且不说,这首先能够让使用特定的回调接口(如 RowMapper 和 JdbcTemplate)更加简洁,代码更加易读;
- 与 Java 8 同时得到支持的是 JSR-310 —- Date 与 Time API,在处理日期和时间时,它为开发者提供了比 java.util.Date 或 java.util.Calendar 更丰富的API;
- 为 Groovy 开发的应用程序提供了更加顺畅的编程体验,尤其是支持非常便利地完全采用 Groovy 开发 Spring 应用程序。随这些一起提供的是来自于 Grails 的BeanBuilder,借助它能够通过 Groovy 配置 Spring 应用;
- 添加了条件化创建 bean 的功能,在这里只有开发人员定义的条件满足时,才会创建所声明的 bean;
- Spring 4.0 包含了 Spring RestTemplate的一个新的异步实现,它会立即返回并且允许在操作完成后执行回调;
- 添加了对多项 JEE 规范的支持,包括 JMS 2.0、JTA 1.2、JPA 2.1 和 Bean Validation 1.1。
可以看到,在 Spring 框架的最新发布版本中,包含了很多令人兴奋的新特性。在本书中,我们将会看到很多这样的新特性,同时也会学习 Spring 中长期以来一直存在的特性。
小结
现在,你应该对 Spring 的功能特性有了一个清晰的认识。Spring 致力于简化企业级 Java 开发,促进代码的松散耦合。成功的关键在于依赖注入和 AOP。
在本章,我们先体验了 Spring 的 DI。DI 是组装应用对象的一种方式,借助这种方式对象无需知道依赖来自何处或者依赖的实现方式。不同于自己获取依赖对象,对象会在运行期赋予它们所依赖的对象。依赖对象通常会通过接口了解所注入的对象,这样的话就能确保低耦合。
除了 DI,我们还简单介绍了 Spring 对 AOP 的支持。AOP 可以帮助应用将散落在各处的逻辑汇集于一处——切面。当 Spring 装配 bean 的时候,这些切面能够在运行期编织起来,这样就能非常有效地赋予 bean 新的行为。
依赖注入和 AOP 是 Spring 框架最核心的部分,因此只有理解了如何应用 Spring 最关键的功能,你才有能力使用 Spring 框架的其他功能。在本章,我们只是触及了 Spring DI 和 AOP 特性的皮毛。在以后的几章,我们将深入探讨 DI 和 AOP。
闲言少叙,我们立即转到第2章学习如何在 Spring 中使用 DI 装配对象。
装配 Bean
本章内容:
- 声明 bean
- 构造器注入和 Setter 方法注入
- 装配 bean
- 控制 bean 的创建和销毁
在看电影的时候,你曾经在电影结束后留在位置上继续观看片尾字幕吗?一部电影需要由这么多人齐心协力才能制作出来,这真是有点令人难以置信!除了主要的参与人员——演员、编剧、导演和制片人,还有那些幕后人员——音乐师、特效制作人员和艺术指导,更不用说道具师、录音师、服装师、化妆师、特技演员、广告师、第一助理摄影师、第二助理摄影师、布景师、灯光师和伙食管理员(或许是最重要的人员)了。
现在想象一下,如果这些人彼此之间没有任何交流,你最喜爱的电影会变成什么样子?让我这么说吧,他们都出现在摄影棚中,开始各做各的事情,彼此之间互不合作。如果导演保持沉默不喊“开机”,摄影师就不会开始拍摄。或许这并没什么大不了的,因为女主角还呆在她的保姆车里,而且因为没有雇佣灯光师,一切处于黑暗之中。或许你曾经看过类似这样的电影。但是大多数电影(总之,都还是很优秀的)都是由成千上万的人一起协作来完成的,他们有着共同的目标:制作一部广受欢迎的佳作。
在这方面,一个优秀的软件与之相比并没有太大区别。任何一个成功的应用都是由多个为了实现某一个业务目标而相互协作的组件构成的。这些组件必须彼此了解,并且相互协作来完成工作。例如,在一个在线购物系统中,订单管理组件需要和产品管理组件以及信用卡认证组件协作。这些组件或许还需要与数据访问组件协作,从数据库读取数据以及把数据写入数据库。
但是,正如我们在第 1 章中所看到的,创建应用对象之间关联关系的传统方法(通过构造器或者查找)通常会导致结构复杂的代码,这些代码很难被复用也很难进行单元测试。如果情况不严重的话,这些对象所做的事情只是超出了它应该做的范围;而最坏的情况则是,这些对象彼此之间高度耦合,难以复用和测试。
在 Spring 中,对象无需自己查找或创建与其所关联的其他对象。相反,容器负责把需要相互协作的对象引用赋予各个对象。例如,一个订单管理组件需要信用卡认证组件,但它不需要自己创建信用卡认证组件。订单管理组件只需要表明自己两手空空,容器就会主动赋予它一个信用卡认证组件。
创建应用对象之间协作关系的行为通常称为装配(wiring),这也是依赖注入(DI)的本质。在本章我们将介绍使用 Spring 装配 bean 的基础知识。因为 DI 是 Spring 的最基本要素,所以在开发基于 Spring 的应用时,你随时都在使用这些技术。
在 Spring 中装配 bean 有多种方式。作为本章的开始,我们先花一点时间来介绍一下配置 Spring 容器最常见的三种方法。
Spring 配置的可选方案
如第 1 章中所述,Spring 容器负责创建应用程序中的 bean 并通过 DI 来协调这些对象之间的关系。但是,作为开发人员,你需要告诉 Spring 要创建哪些 bean 并且如何将其装配在一起。当描述 bean 如何进行装配时,Spring 具有非常大的灵活性,它提供了三种主要的装配机制:
- 在 XML 中进行显式配置。
- 在 Java 中进行显式配置。
- 隐式的 bean 发现机制和自动装配。
乍看上去,提供三种可选的配置方案会使 Spring 变得复杂。每种配置技术所提供的功能会有一些重叠,所以在特定的场景中,确定哪种技术最为合适就会变得有些困难。但是,不必紧张——在很多场景下,选择哪种方案很大程度上就是个人喜好的问题,你尽可以选择自己最喜欢的方式。
Spring 有多种可选方案来配置 bean,这是非常棒的,但有时候你必须要在其中做出选择。
这方面,并没有唯一的正确答案。你所做出的选择必须要适合你和你的项目。而且,谁说我们只能选择其中的一种方案呢?Spring 的配置风格是可以互相搭配的,所以你可以选择使用 XML 装配一些 bean,使用 Spring 基于 Java 的配置(JavaConfig)来装配另一些 bean,而将剩余的 bean 让 Spring 去自动发现。
即便如此,我的建议是尽可能地使用自动配置的机制。显式配置越少越好。当你必须要显式配置 bean 的时候(比如,有些源码不是由你来维护的,而当你需要为这些代码配置bean 的时候),我推荐使用类型安全并且比 XML 更加强大的 JavaConfig。最后,只有当你想要使用便利的 XML 命名空间,并且在 JavaConfig 中没有同样的实现时,才应该使用 XML。
在本章中,我们会详细介绍这三种技术并且在整本书中都会用到它们。现在,我们会尝试一下每种方法,对它们是什么样子的有一个直观的印象。作为Spring配置的开始,我们先看一下Spring的自动化配置。
自动化装配 Bean
在本章稍后的内容中,你会看到如何借助 Java 和 XML 来进行 Spring 装配。尽管你会发现这些显式装配技术非常有用,但是在便利性方面,最强大的还是 Spring 的自动化配置。如果 Spring 能够进行自动化装配的话,那何苦还要显式地将这些 bean 装配在一起呢?
Spring 从两个角度来实现自动化装配:
- 组件扫描(component scanning):Spring 会自动发现应用上下文中所创建的 bean。
- 自动装配(autowiring):Spring 自动满足 bean 之间的依赖。
组件扫描和自动装配组合在一起就能发挥出强大的威力,它们能够将你的显式配置降低到最少。
为了阐述组件扫描和装配,我们需要创建几个 bean,它们代表了一个音响系统中的组件。首先,要创建 CompactDisc 类,Spring 会发现它并将其创建为一个bean。然后,会创建一个 CDPlayer 类,让 Spring 发现它,并将 CompactDisc bean 注入进来。
创建可被发现的 bean
在这个 MP3 和流式媒体音乐的时代,CD(compact disc)显得有点典雅甚至陈旧。它不像卡带机、八轨磁带、塑胶唱片那么普遍,随着以物理载体进行音乐交付的方式越来越少,CD 也变得越来越稀少了。
尽管如此,CD 为我们阐述 DI 如何运行提供了一个很好的样例。如果你不将 CD 插入(注入)到 CD 播放器中,那么 CD 播放器其实是没有太大用处的。所以,可以这样说,CD 播放器依赖于 CD 才能完成它的使命。
为了在 Spring 中阐述这个例子,让我们首先在 Java 中建立 CD 的概念。程序清单 2.1 展现了 CompactDisc,它是定义 CD 的一个接口:
1 | package soundsystem;public interface CompactDisc { void play();} |
CompactDisc 的具体内容并不重要,重要的是你将其定义为一个接口。作为接口,它定义了 CD 播放器对一盘 CD 所能进行的操作。它将 CD 播放器的任意实现与CD 本身的耦合降低到了最小的程度。
1 | package soundsystem;import org.springframework.stereotype.Component; class SgtPeppers implements CompactDisc { private String title = "Sgt. Pepper's Lonely Hearts Club Band"; private String artist = "The Beatles"; public void play() { System.out.println("Playing " + title + " by " + artist); } } |
和 CompactDisc 接口一样,SgtPeppers 的具体内容并不重要。你需要注意的就是 SgtPeppers 类上使用了@Component 注解。@Component 注解表明该类会作为组件类,并告知 Spring 要为这个类创建 bean。没有必要显式配置 SgtPeppers bean,因为这个类使用了 @Component 注解,所以 Spring 会为你把事情处理妥当。
不过,组件扫描默认是不启用的。我们还需要显式配置一下 Spring,从而命令它去寻找带有 @Component 注解的类,并为其创建 bean。程序清单 2.3 的配置类展现了完成这项任务的最简洁配置。
1 | package soundsystem;import org.springframework.context.annotation.ComponentScan;import org.springframework.context.annotation.Configuration; class CDPlayerConfig { } |
类 CDPlayerConfig 通过 Java 代码定义了 Spring 的装配规则。在 2.3 节中,我们还会更为详细地介绍基于 Java 的 Spring 配置。不过,现在我们只需观察一下 CDPlayerConfig 类并没有显式地声明任何 bean,只不过它使用了@ComponentScan 注解,这个注解能够在 Spring 中启用组件扫描。
如果没有其他配置的话,@ComponentScan 默认会扫描与配置类相同的包。因为 CDPlayerConfig 类位于 soundsystem 包中,因此 Spring 将会扫描这个包以及这个包下的所有子包,查找带有 @Component 注解的类。这样的话,就能发现 CompactDisc,并且会在 Spring 中自动为其创建一个 bean。
如果你更倾向于使用 XML 来启用组件扫描的话,那么可以使用 Spring context 命名空间的 <context:component-scan> 元素。程序清单 2.4 展示了启用组件扫描的最简洁 XML 配置。
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:c="http://www.springframework.org/schema/c" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <context:component-scan base-package="soundsystem" /></beans> |
尽管我们可以通过 XML 的方案来启用组件扫描,但是在后面的讨论中,我更多的还是会使用基于 Java 的配置。如果你更喜欢XML的话,<context:component-scan> 元素会有与@ComponentScan注解相对应的属性和子元素。
可能有点让人难以置信,我们只创建了两个类,就能对功能进行一番尝试了。为了测试组件扫描的功能,我们创建一个简单的 JUnit 测试,它会创建 Spring 上下文,并判断 CompactDisc 是不是真的创建出来了。程序清单 2.5 中的 CDPlayerTest 就是用来完成这项任务的。
1 | package soundsystem;import static org.junit.Assert.*;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.test.context.ContextConfiguration;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;public class CDPlayerTest { private CompactDisc cd; public void cdShouldNotBeNull() { assertNotNull(cd); }} |
CDPlayerTest 使用了 Spring 的 SpringJUnit4ClassRunner,以便在测试开始的时候自动创建 Spring 的应用上下文。注解 @ContextConfiguration 会告诉它需要在 CDPlayerConfig 中加载配置。因为 CDPlayerConfig 类中包含了@ComponentScan,因此最终的应用上下文中应该包含 CompactDiscbean。
为了证明这一点,在测试代码中有一个 CompactDisc 类型的属性,并且这个属性带有 @Autowired 注解,以便于将 CompactDiscbean 注入到测试代码之中。最后,会有一个简单的测试方法断言 cd 属性不为 null。如果它不为 null 的话,就意味着 Spring 能够发现 CompactDisc 类,自动在 Spring 上下文中将其创建为 bean 并将其注入到测试代码之中。
这个代码应该能够通过测试,并以测试成功的颜色显示(在你的测试运行器中,或许会希望出现绿色)。你第一个简单的组件扫描练习就成功了!尽管我们只用它创建了一个 bean,但同样是这么少的配置能够用来发现和创建任意数量的 bean。在 soundsystem 包及其子包中,所有带有 @Component 注解的类都会创建为 bean。只添加一行 @ComponentScan 注解就能自动创建无数个 bean,这种权衡还是很划算的。
现在,我们会更加深入地探讨 @ComponentScan 和 @Component,看一下使用组件扫描还能做些什么。
为组件扫描的 bean 命名
Spring 应用上下文中所有的 bean 都会给定一个 ID。在前面的例子中,尽管我们没有明确地为 SgtPeppers bean 设置 ID,但 Spring 会根据类名为其指定一个ID。具体来讲,这个 bean 所给定的 ID 为 sgtPeppers,也就是将类名的第一个字母变为小写。
如果想为这个 bean 设置不同的 ID,你所要做的就是将期望的 ID 作为值传递给 @Component 注解。比如说,如果想将这个 bean 标识为 lonelyHeartsClub,那么你需要将 SgtPeppers 类的 @Component 注解配置为如下所示:
1 | public class SgtPeppers implements CompactDisc {} |
使用 Java 依赖注入规范(Java Dependency Injection)中所提供的 @Named 注解来为 bean 设置 ID:
1 | import javax.inject.Named;public class SgtPeppers implements CompactDisc {} |
Spring 支持将 @Named 作为 @Component 注解的替代方案。两者之间有一些细微的差异,但是在大多数场景中,它们是可以互相替换的。
话虽如此,我更加强烈地喜欢 @Component 注解,而对于 @Named…… 怎么说呢,我感觉它的名字起得很不好。它并没有像 @Component 那样清楚地表明它是做什么的。因此在本书及其示例代码中,我不会再使用 @Named。
设置组件扫描的基础包
到现在为止,我们没有为 @ComponentScan 设置任何属性。这意味着,按照默认规则,它会以配置类所在的包作为基础包(basepackage)来扫描组件。但是,如果你想扫描不同的包,那该怎么办呢?或者,如果你想扫描多个基础包,那又该怎么办呢?
有一个原因会促使我们明确地设置基础包,那就是我们想要将配置类放在单独的包中,使其与其他的应用代码区分开来。如果是这样的话,那默认的基础包就不能满足要求了。
要满足这样的需求其实也完全没有问题!为了指定不同的基础包,你所需要做的就是在 @ComponentScan 的 value 属性中指明包的名称:
1 | public class CDPlayerConfig { } |
如果你想更加清晰地表明你所设置的是基础包,那么你可以通过 basePackages 属性进行配置:
1 | public class CDPlayerConfig { } |
如果想要设置多个基础包,只需要将 basePackages 属性设置为要扫描包的一个数组即可:
1 | public class CDPlayerConfig { } |
在上面的例子中,所设置的基础包是以 String 类型表示的。我认为这是可以的,但这种方法是类型不安全(not type-safe)的。如果你重构代码的话,那么所指定的基础包可能就会出现错误了。
除了将包设置为简单的 String 类型之外,@ComponentScan 还提供了另外一种方法,那就是将其指定为包中所包含的类或接口:
1 | public class CDPlayerConfig { } |
可以看到,basePackages属性被替换成了basePackageClasses。同时,我们不是再使用String类型的名称来指定包,为basePackageClasses属性所设置的数组中包含了类。这些类所在的包将会作为组件扫描的基础包。
尽管在样例中,我为basePackageClasses设置的是组件类,但是你可以考虑在包中创建一个用来进行扫描的空标记接口(marker interface)。通过标记接口的方式,你依然能够保持对重构友好的接口引用,但是可以避免引用任何实际的应用程序代码(在稍后重构中,这些应用代码有可能会从想要扫描的包中移除掉)。
在你的应用程序中,如果所有的对象都是独立的,彼此之间没有任何依赖,就像 SgtPeppersbean 这样,那么你所需要的可能就是组件扫描而已。但是,很多对象会依赖其他的对象才能完成任务。这样的话,我们就需要有一种方法能够将组件扫描得到的 bean 和它们的依赖装配在一起。要完成这项任务,我们需要了解一下 Spring 自动化配置的另外一方面内容,那就是自动装配。
通过为 bean 添加注解实现自动装配
简单来说,自动装配就是让 Spring 自动满足 bean 依赖的一种方法,在满足依赖的过程中,会在 Spring 应用上下文中寻找匹配某个 bean 需求的其他 bean。为了声明要进行自动装配,我们可以借助 Spring 的 @Autowired 注解。
比方说,考虑程序清单 2.6 中的 CDPlayer 类。它的构造器上添加了 @Autowired 注解,这表明当 Spring 创建 CDPlayer bean 的时候,会通过这个构造器来进行实例化并且会传入一个可设置给 CompactDisc 类型的 bean。
1 | package soundsystem;import org.springframework.beans.factory.annotation.Autowired;public class CDPlayer implements MediaPlayer { private CompactDisc cd; public CDPlayer(CompactDisc cd) { this.cd = cd; } public void play() { cd.play(); }} |
@Autowired 注解不仅能够用在构造器上,还能用在属性的 Setter 方法上。比如说,如果 CDPlayer 有一个 setCompactDisc() 方法,那么可以采用如下的注解形式进行自动装配:
1 | void setCompactDisc(CompactDisc cd) { this.cd = cd;} |
在 Spring 初始化 bean 之后,它会尽可能得去满足 bean 的依赖,在本例中,依赖是通过带有@Autowired注解的方法进行声明的,也就是setCompactDisc()。
实际上,Setter 方法并没有什么特殊之处。@Autowired 注解可以用在类的任何方法上。假设 CDPlayer 类有一个 insertDisc() 方法,那么 @Autowired 能够像在 setCompactDisc() 上那样,发挥完全相同的作用:
1 | void insertDisc(CompactDisc cd) { this.cd = cd;} |
不管是构造器、Setter 方法还是其他的方法,Spring 都会尝试满足方法参数上所声明的依赖。假如有且只有一个 bean 匹配依赖需求的话,那么这个 bean 将会被装配进来。
如果没有匹配的 bean,那么在应用上下文创建的时候,Spring 会抛出一个异常。为了避免异常的出现,你可以将 @Autowired 的 required 属性设置为 false:
1 | public CDPlayer(CompactDisc cd) { this.cd = cd;} |
将 required 属性设置为 false 时,Spring 会尝试执行自动装配,但是如果没有匹配的 bean 的话,Spring 将会让这个 bean 处于未装配的状态。但是,把 required 属性设置为false时,你需要谨慎对待。如果在你的代码中没有进行 null 检查的话,这个处于未装配状态的属性有可能会出现 NullPointerException。
如果有多个 bean 都能满足依赖关系的话,Spring 将会抛出一个异常,表明没有明确指定要选择哪个 bean 进行自动装配。在第 3 章中,我们会进一步讨论自动装配中的歧义性。
@Autowired 是 Spring 特有的注解。如果你不愿意在代码中到处使用 Spring 的特定注解来完成自动装配任务的话,那么你可以考虑将其替换为 @Inject:
1 | package soundsystem;import javax.inject.Inject;import javax.inject.Named; class CDPlayer implements MediaPlayer { public CDPlayer(CompactDisc cd) { this.cd = cd; }} |
@Inject 注解来源于 Java 依赖注入规范,该规范同时还为我们定义了 @Named 注解。在自动装配中,Spring 同时支持 @Inject 和 @Autowired。尽管 @Inject 和 @Autowired 之间有着一些细微的差别,但是在大多数场景下,它们都是可以互相替换的。
在 @Inject 和 @Autowired 中,我没有特别强烈的偏向性。实际上,在有的项目中,我会发现我同时使用了这两个注解。不过在本书的样例中,我会一直使用 @Autowired,而你可以根据自己的情况,选择其中的任意一个。
验证自动装配
现在,我们已经在 CDPlayer 的构造器中添加了 @Autowired 注解,Spring 将把一个可分配给 CompactDisc 类型的 bean 自动注入进来。为了验证这一点,让我们修改一下 CDPlayerTest,使其能够借助 CDPlayer bean 播放 CD:
1 | package soundsystem;import static org.junit.Assert.*;import org.junit.Rule;import org.junit.Test;import org.junit.contrib.java.lang.system.StandardOutputStreamLog;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.test.context.ContextConfiguration;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;public class CDPlayerTest { public final StandardOutputStreamLog log = new StandardOutputStreamLog(); private MediaPlayer player; private CompactDisc cd; public void cdShouldNotBeNull() { assertNotNull(cd); } public void play() { player.play(); assertEquals( "Playing Sgt. Pepper's Lonely Hearts Club Band by The Beatles\n", log.getLog()); }} |
现在,除了注入 CompactDisc,我们还将 CDPlayerbean 注入到测试代码的player成员变量之中(它是更为通用的 MediaPlayer 类型)。在 play() 测试方法中,我们可以调用 CDPlayer 的 play() 方法,并断言它的行为与你的预期一致。
在测试代码中使用 System.out.println() 是稍微有点棘手的事情。因此,该样例中使用了 StandardOutputStreamLog,这是来源于 System Rules 库(http://stefanbirkner.github.io/systemrules/index.html)的一个 JUnit 规则,该规则能够基于控制台的输出编写断言。在这里,我们断言 SgtPeppers.play() 方法的输出被发送到了控制台上。
现在,你已经了解了组件扫描和自动装配的基础知识,在第 3 章中,当我们介绍如何处理自动装配的歧义性时,还会继续研究组件扫描。
但是现在,我们先将组件扫描和自动装配放在一边,看一下在 Spring 中如何显式地装配 bean,首先从通过 Java 代码编写配置开始。
通过 Java 代码装配 bean
尽管在很多场景下通过组件扫描和自动装配实现 Spring 的自动化配置是更为推荐的方式,但有时候自动化配置的方案行不通,因此需要明确配置 Spring。比如说,你想要将第三方库中的组件装配到你的应用中,在这种情况下,是没有办法在它的类上添加 @Component 和 @Autowired 注解的,因此就不能使用自动化装配的方案了。
在这种情况下,你必须要采用显式装配的方式。在进行显式配置的时候,有两种可选方案:Java 和 XML。在这节中,我们将会学习如何使用 Java配置,接下来的一节中将会继续学习 Spring 的 XML 配置。
就像我之前所说的,在进行显式配置时,JavaConfig 是更好的方案,因为它更为强大、类型安全并且对重构友好。因为它就是 Java 代码,就像应用程序中的其他Java 代码一样。同时,JavaConfig 与其他的 Java 代码又有所区别,在概念上,它与应用程序中的业务逻辑和领域代码是不同的。尽管它与其他的组件一样都使用相同的语言进行表述,但 JavaConfig 是配置代码。这意味着它不应该包含任何业务逻辑,JavaConfig 也不应该侵入到业务逻辑代码之中。尽管不是必须的,但通常会将 JavaConfig 放到单独的包中,使它与其他的应用程序逻辑分离开来,这样对于它的意图就不会产生困惑了。
接下来,让我们看一下如何通过JavaConfig显式配置Spring。
创建配置类
在本章前面的程序清单 2.3 中,我们第一次见识到 JavaConfig。让我们重温一下那个样例中的 CDPlayerConfig:
1 | package soundsystem; |
创建 JavaConfig 类的关键在于为其添加 @Configuration 注解,@Configuration 注解表明这个类是一个配置类,该类应该包含在 Spring 应用上下文中如何创建bean 的细节。
到此为止,我们都是依赖组件扫描来发现 Spring 应该创建的 bean。尽管我们可以同时使用组件扫描和显式配置,但是在本节中,我们更加关注于显式配置,因此我将 CDPlayerConfig 的 @ComponentScan 注解移除掉了。
移除了 @ComponentScan 注解,此时的 CDPlayerConfig 类就没有任何作用了。如果你现在运行 CDPlayerTest 的话,测试会失败,并且会出现 BeanCreationException 异常。测试期望被注入 CDPlayer 和 CompactDisc,但是这些 bean 根本就没有创建,因为组件扫描不会发现它们。
为了再次让测试通过,你可以将 @ComponentScan 注解添加回去,但是我们这一节关注显式配置,因此让我们看一下如何使用 JavaConfig 装配 CDPlayer 和 CompactDisc。
声明简单的 bean
要在 JavaConfig 中声明 bean,我们需要编写一个方法,这个方法会创建所需类型的实例,然后给这个方法添加 @Bean 注解。
1 |
|
@Bean 注解会告诉 Spring 这个方法将会返回一个对象,该对象要注册为 Spring 应用上下文中的 bean。方法体中包含了最终产生 bean 实例的逻辑。
默认情况下,bean 的 ID 与带有 @Bean 注解的方法名是一样的。如果你想为其设置成一个不同的名字的话,那么可以重命名该方法,也可以通过 name 属性指定一个不同的名字:
1 |
|
不管你采用什么方法来为 bean 命名,bean声明都是非常简单的。方法体返回了一个新的 SgtPeppers 实例。这里是使用 Java 来进行描述的,因此我们可以发挥Java 提供的所有功能,只要最终生成一个 CompactDisc 实例即可。
请稍微发挥一下你的想象力,我们可能希望做一点稍微疯狂的事情,比如说,在一组 CD 中随机选择一个 CompactDisc 来播放:
1 | CompactDisc randomBeatlesCD() { int choice = (int) Math.floor(Math.random() * 4); if (choice == 0) { return new SgtPeppers(); } else if (choice == 1) { return new WhiteAlbum(); } else if (choice == 2) { return new HardDaysNight(); } else { return new Revolver(); }} |
现在,你可以自己想象一下,借助 @Bean 注解方法的形式,我们该如何发挥出 Java 的全部威力来产生 bean。当你想完之后,我们要回过头来看一下在 JavaConfig 中,如何将 CompactDisc 注入到 CDPlayer 之中。
借助 JavaConfig 实现注入
我们前面所声明的 CompactDisc bean 是非常简单的,它自身没有其他的依赖。但现在,我们需要声明 CDPlayerbean,它依赖于 CompactDisc。在 JavaConfig 中,要如何将它们装配在一起呢?
在 JavaConfig 中装配 bean 的最简单方式就是引用创建 bean 的方法。
1 | CDPlayer cdPlayer() { return new CDPlayer(sgtPeppers());} |
cdPlayer() 方法像 sgtPeppers() 方法一样,同样使用了@Bean 注解,这表明这个方法会创建一个 bean 实例并将其注册到 Spring 应用上下文中。所创建的 bean ID为 cdPlayer,与方法的名字相同。
cdPlayer() 的方法体与 sgtPeppers() 稍微有些区别。在这里并没有使用默认的构造器构建实例,而是调用了需要传入 CompactDisc 对象的构造器来创建 CDPlayer 实例。
看起来,CompactDisc 是通过调用 sgtPeppers() 得到的,但情况并非完全如此。因为 sgtPeppers() 方法上添加了 @Bean 注解,Spring 将会拦截所有对它的调用,并确保直接返回该方法所创建的 bean,而不是每次都对其进行实际的调用。
比如说,假设你引入了一个其他的 CDPlayerbean,它和之前的那个 bean 完全一样:
1 |
|
假如对 sgtPeppers() 的调用就像其他的 Java 方法调用一样的话,那么每个 CDPlayer 实例都会有一个自己特有的 SgtPeppers 实例。如果我们讨论的是实际的 CD播放器和 CD 光盘的话,这么做是有意义的。如果你有两台 CD 播放器,在物理上并没有办法将同一张 CD 光盘放到两个 CD 播放器中。
但是,在软件领域中,我们完全可以将同一个 SgtPeppers 实例注入到任意数量的其他 bean 之中。默认情况下,Spring 中的 bean 都是单例的,我们并没有必要为第二个 CDPlayer bean 创建完全相同的 SgtPeppers 实例。所以,Spring 会拦截对 sgtPeppers()的调用并确保返回的是 Spring 所创建的 bean,也就是 Spring 本身在调用 sgtPeppers() 时所创建的 CompactDiscbean。因此,两个 CDPlayer bean 会得到相同的 SgtPeppers 实例。
可以看到,通过调用方法来引用 bean 的方式有点令人困惑。其实还有一种理解起来更为简单的方式:
1 | CDPlayer cdPlayer(CompactDisc compactDisc) { return new CDPlayer(compactDisc);} |
在这里,cdPlayer() 方法请求一个 CompactDisc 作为参数。当 Spring 调用 cdPlayer() 创建 CDPlayer bean 的时候,它会自动装配一个 CompactDisc 到配置方法之中。然后,方法体就可以按照合适的方式来使用它。借助这种技术,cdPlayer() 方法也能够将 CompactDisc 注入到 CDPlayer 的构造器中,而且不用明确引用CompactDisc 的 @Bean 方法。
通过这种方式引用其他的 bean 通常是最佳的选择,因为它不会要求将 CompactDisc 声明到同一个配置类之中。在这里甚至没有要求 CompactDisc 必须要在 JavaConfig 中声明,实际上它可以通过组件扫描功能自动发现或者通过 XML 来进行配置。你可以将配置分散到多个配置类、XML 文件以及自动扫描和装配 bean 之中,只要功能完整健全即可。不管 CompactDisc 是采用什么方式创建出来的,Spring 都会将其传入到配置方法中,并用来创建 CDPlayer bean。
另外,需要提醒的是,我们在这里使用 CDPlayer 的构造器实现了 DI 功能,但是我们完全可以采用其他风格的DI配置。比如说,如果你想通过 Setter 方法注入 CompactDisc 的话,那么代码看起来应该是这样的:
1 | CDPlayer cdPlayer(CompactDisc compactDisc) { CDPlayer cdPlayer = new CDPlayer(compactDisc); cdPlayer.setCompactDisc(compactDisc); retyrb cdPlayer;} |
再次强调一遍,带有 @Bean 注解的方法可以采用任何必要的 Java 功能来产生 bean 实例。构造器和 Setter 方法只是 @Bean 方法的两个简单样例。这里所存在的可能性仅仅受到 Java 语言的限制。
通过 XML 装配 bean
到此为止,我们已经看到了如何让 Spring 自动发现和装配bean,还看到了如何进行手动干预,即通过 JavaConfig 显式地装配 bean。但是,在装配 bean 的时候,还有一种可选方案,尽管这种方案可能不太合乎大家的心意,但是它在 Spring 中已经有很长的历史了。
在 Spring 刚刚出现的时候,XML 是描述配置的主要方式。在 Spring 的名义下,我们创建了无数行 XML 代码。在一定程度上,Spring 成为了 XML 配置的同义词。
尽管 Spring 长期以来确实与 XML 有着关联,但现在需要明确的是,XML 不再是配置 Spring 的唯一可选方案。Spring 现在有了强大的自动化配置和基于 Java 的配置,XML 不应该再是你的第一选择了。
不过,鉴于已经存在那么多基于 XML 的 Spring 配置,所以理解如何在 Spring 中使用 XML 还是很重要的。但是,我希望本节的内容只是用来帮助你维护已有的 XML 配置,在完成新的 Spring 工作时,希望你会使用自动化配置和 JavaConfig。
创建 XML 配置规范
在使用 XML 为 Spring 装配 bean 之前,你需要创建一个新的配置规范。在使用 JavaConfig 的时候,这意味着要创建一个带有 @Configuration 注解的类,而在 XML 配置中,这意味着要创建一个 XML 文件,并且要以 <beans> 元素为根。
最为简单的 Spring XML 配置如下所示:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:c="http://www.springframework.org/schema/c" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <!-- configuration details go here --></beans> |
很容易就能看出来,这个基本的 XML 配置已经比同等功能的 JavaConfig 类复杂得多了。作为起步,在 JavaConfig 中所需要的只是 @Configuration,但在使用 XML 时,需要在配置文件的顶部声明多个 XML 模式(XSD)文件,这些文件定义了配置 Spring 的 XML 元素。
借助 Spring Tool Suite
创建 XML 配置文件创建和管理 Spring XML 配置文件的一种简便方式是使用 Spring ToolSuite(https://spring.io/tools/sts)。在 Spring Tool Suite 的菜单中,选择 File>New>Spring Bean Configuration File,能够创建 Spring XML 配置文件,并且可以选择可用的配置命名空间。
用来装配 bean 的最基本的 XML 元素包含在 spring-beans 模式之中,在上面这个 XML 文件中,它被定义为根命名空间。<beans> 是该模式中的一个元素,它是所有 Spring 配置文件的根元素。
在 XML 中配置 Spring 时,还有一些其他的模式。尽管在本书中,我更加关注自动化以及基于 Java 的配置,但是在本书讲解的过程中,当出现其他模式的时候,我至少会提醒你。就这样,我们已经有了一个合法的 Spring XML 配置。不过,它也是一个没有任何用处的配置,因为它(还)没有声明任何 bean。为了给予它生命力,让我们重新创建一下 CD 样例,只不过我们这次使用 XML 配置,而不是使用 JavaConfig 和自动化装配。
声明一个简单的 <bean>
要在基于 XML 的 Spring 配置中声明一个 bean,我们要使用 spring beans 模式中的另外一个元素:<bean>。<bean> 元素类似于 JavaConfig 中的 @Bean 注解。我们可以按照如下的方式声明 CompactDiscbean:
1 | <bean class="soundsystem.SgtPeppers"/> |
这里声明了一个很简单的 bean,创建这个 bean 的类通过 class 属性来指定的,并且要使用全限定的类名。
因为没有明确给定 ID,所以这个 bean 将会根据全限定类名来进行命名。在本例中,bean 的 ID 将会是 “soundsystem.SgtPeppers#0”。其中,“#0” 是一个计数的形式,用来区分相同类型的其他 bean。如果你声明了另外一个 SgtPeppers,并且没有明确进行标识,那么它自动得到的 ID 将会是 “soundsystem.SgtPeppers#1”。
尽管自动化的 bean命 名方式非常方便,但如果你要稍后引用它的话,那自动产生的名字就没有多大的用处了。因此,通常来讲更好的办法是借助 id 属性,为每个bean 设置一个你自己选择的名字:
1 | <bean id="compactDisc" class="soundsystem.SgtPeppers"/> |
稍后将这个 bean 装配到 CDPlayer bean 之中的时候,你会用到这个具体的名字。
减少繁琐
为了减少 XML 中繁琐的配置,只对那些需要按名字引用的 bean(比如,你需要将对它的引用注入到另外一个 bean 中)进行明确地命名。
在进一步学习之前,让我们花点时间看一下这个简单 bean 声明的一些特征。
第一件需要注意的事情就是你不再需要直接负责创建 SgtPeppers 的实例,在基于 JavaConfig 的配置中,我们是需要这样做的。当 Spring 发现这个 <bean> 元素时,它将会调用 SgtPeppers 的默认构造器来创建 bean。在 XML 配置中,bean 的创建显得更加被动,不过,它并没有 JavaConfig 那样强大,在 JavaConfig 配置方式中,你可以通过任何可以想象到的方法来创建 bean 实例。
另外一个需要注意到的事情就是,在这个简单的 <bean> 声明中,我们将 bean 的类型以字符串的形式设置在了 class 属性中。谁能保证设置给 class 属性的值是真正的类呢?Spring 的 XML 配置并不能从编译期的类型检查中受益。即便它所引用的是实际的类型,如果你重命名了类,会发生什么呢?
借助 IDE 检查 XML 的合法性
使用能够感知 Spring 功能的 IDE,如 Spring Tool Suite,能够在很大程度上帮助你确保 Spring XML 配置的合法性。
以上介绍的只是 JavaConfig 要优于 XML 配置的部分原因。我建议在为你的应用选择配置风格时,要记住 XML 配置的这些缺点。接下来,我们继续 Spring XML 配置的学习进程,了解如何将 SgtPeppers bean 注入到 CDPlayer 中。
借助构造器注入初始化 bean
在 Spring XML 配置中,只有一种声明 bean 的方式:使用 <bean> 元素并指定 class 属性。Spring 会从这里获取必要的信息来创建 bean。
但是,在 XML 中声明 DI 时,会有多种可选的配置方案和风格。具体到构造器注入,有两种基本的配置方案可供选择:
<constructor-arg>元素- 使用 Spring 3.0 所引入的 c-命名空间
两者的区别在很大程度就是是否冗长烦琐。可以看到,<constructor-arg> 元素比使用 c-命名空间会更加冗长,从而导致 XML 更加难以读懂。另外,有些事情<constructor-arg> 可以做到,但是使用c-命名空间却无法实现。
在介绍 Spring XML 的构造器注入时,我们将会分别介绍这两种可选方案。首先,看一下它们各自如何注入 bean 引用。
构造器注入 bean 引用
按照现在的定义,CDPlayerbean 有一个接受 CompactDisc 类型的构造器。这样,我们就有了一个很好的场景来学习如何注入bean 的引用。
现在已经声明了 SgtPeppers bean,并且 SgtPeppers 类实现了 CompactDisc 接口,所以实际上我们已经有了一个可以注入到 CDPlayerbean 中的 bean。我们所需要做的就是在 XML 中声明 CDPlayer 并通过 ID 引用 SgtPeppers:
1 | <bean id="cdPlayer" class="soundsystem.CDPlayer"> <constructor-arg ref="compactDisc"/></bean> |
当 Spring 遇到这个 <bean> 元素时,它会创建一个 CDPlayer 实例。<constructor-arg> 元素会告知 Spring 要将一个 ID compactDisc 的 bean 引用传递到 CDPlayer 的构造器中。作为替代的方案,你也可以使用 Spring 的 c-命名空间。c-命名空间是在 Spring 3.0 中引入的,它是在 XML 中更为简洁地描述构造器参数的方式。要使用它的话,必须要在 XML 的顶部声明其模式,如下所示:
1 | <beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:c="http://www.springframework.org/schema/c" xmlns="http://www.springframework.org/schema/beans" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> </beans> |
在 c-命名空间和模式声明之后,我们就可以使用它来声明构造器参数了,如下所示:
1 | <bean id="cdPlayer" class="soundsystem.CDPlayer" c:cd-ref="compactDisc"/> |
在这里,我们使用了 c-命名空间来声明构造器参数,它作为 <bean> 元素的一个属性,不过这个属性的名字有点诡异。图2.1 描述了这个属性名是如何组合而成的。
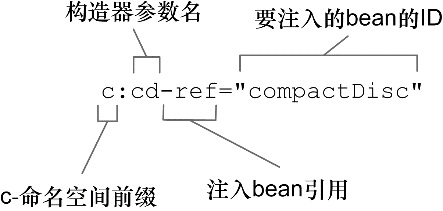
属性名以 “c:” 开头,也就是命名空间的前缀。接下来就是要装配的构造器参数名,在此之后是 “-ref”,这是一个命名的约定,它会告诉 Spring,正在装配的是一个 bean 的引用,这个 bean 的名字是 compactDisc,而不是字面量 “compactDisc”。
很显然,使用 c-命名空间属性要比使用 <constructor-arg> 元素简练得多。这是我很喜欢它的原因之一。除了更易读之外,当我在编写样例代码时,c-命名空间属性能够更加有助于使代码的长度保持在书的边框之内。
在编写前面的样例时,关于 c-命名空间,有一件让我感到困扰的事情就是它直接引用了构造器参数的名称。引用参数的名称看起来有些怪异,因为这需要在编译代码的时候,将调试标志(debug symbol)保存在类代码中。如果你优化构建过程,将调试标志移除掉,那么这种方式可能就无法正常执行了。
替代的方案是我们使用参数在整个参数列表中的位置信息:
1 | <bean id="cdPlayer" class="soundsystem.CDPlayer" c:_0-ref="compactDisc"/> |
这个 c-命名空间属性看起来似乎比上一种方法更加怪异。我将参数的名称替换成了 “0”,也就是参数的索引。因为在 XML 中不允许数字作为属性的第一个字符,因此必须要添加一个下画线作为前缀。
使用索引来识别构造器参数感觉比使用名字更好一些。即便在构建的时候移除掉了调试标志,参数却会依然保持相同的顺序。如果有多个构造器参数的话,这当然是很有用处的。在这里因为只有一个构造器参数,所以我们还有另外一个方案——根本不用去标示参数:
1 | <bean id="cdPlayer" class="soundsystem.CDPlayer" c:_-ref="compactDisc"/> |
到目前为止,这是最为奇特的一个 c-命名空间属性,这里没有参数索引或参数名。只有一个下画线,然后就是用“-ref”来表明正在装配的是一个引用。
我们已经将引用装配到了其他的 bean 之中,接下来看一下如何将字面量值(literal value)装配到构造器之中。
将字面量注入到构造器中
迄今为止,我们所做的 DI 通常指的都是类型的装配——也就是将对象的引用装配到依赖于它们的其他对象之中——而有时候,我们需要做的只是用一个字面量值来配置对象。为了阐述这一点,假设你要创建 CompactDisc 的一个新实现,如下所示:
1 | package soundsystem;public class BlankDisc implements CompactDisc { private String title; private String artist; public BlankDisc(String title, String artist) { this.title = title; this.artist = artist; } public void play() { System.out.println("playing " + title + " by " + artist); }} |
在 SgtPeppers 中,唱片名称和艺术家的名字都是硬编码的,但是这个 CompactDisc 实现与之不同,它更加灵活。像现实中的空磁盘一样,它可以设置成任意你想要的艺术家和唱片名。现在,我们可以将已有的 SgtPeppers 替换为这个类:
1 | <bean id="compactDisc" class="soundsystem.BlankDisc"> <constructor-arg value="Sgt. Pepper's Lonely Hearts Club Band"/> <constructor-arg value="The Battle"/></bean> |
我们再次使用 <constructor-arg> 元素进行构造器参数的注入。但是这一次我们没有使用 “ref” 属性来引用其他的 bean,而是使用了 value 属性,通过该属性表明给定的值要以字面量的形式注入到构造器之中。
如果要使用 c-命名空间的话,这个例子又该是什么样子呢?第一种方案是引用构造器参数的名字:
1 | <bean id="compactDisc" class="soundsystem.BlankDisc" c:title="Sgt. Pepper's Lonely Hearts Club Band" c:_artist="The Battle"/> |
可以看到,装配字面量与装配引用的区别在于属性名中去掉了 “-ref” 后缀。与之类似,我们也可以通过参数索引装配相同的字面量值,如下所示:
1 | <bean id="compactDisc" class="soundsystem.BlankDisc" c:_0="Sgt. Pepper's Lonely Hearts Club Band" c:_1="The Battle"/> |
XML 不允许某个元素的多个属性具有相同的名字。因此,如果有两个或更多的构造器参数的话,我们不能简单地使用下画线进行标示。但是如果只有一个构造器参数的话,我们就可以这样做了。为了完整地展现该功能,假设 BlankDisc 只有一个构造器参数,这个参数接受唱片的名称。在这种情况下,我们可以在 Spring 中这样声明它:
1 | <bean id="compactDisc" class="soundsystem.BlankDisc" c:_="Sgt. Pepper's Lonely hearts Club Band"/> |
在装配 bean 引用和字面量值方面,<constructor-arg> 和 c-命名空间的功能是相同的。但是有一种情况是 <constructor-arg> 能够实现,c-命名空间却无法做到的。
接下来,让我们看一下如何将集合装配到构造器参数中。
装配集合
到现在为止,我们假设 CompactDisc 在定义时只包含了唱片名称和艺术家的名字。如果现实世界中的 CD 也是这样的话,那么在技术上就不会任何的进展。CD 之所以值得购买是因为它上面所承载的音乐。大多数的 CD 都会包含十多个磁道,每个磁道上包含一首歌。
如果使用 CompactDisc 为真正的 CD 建模,那么它也应该有磁道列表的概念。请考虑下面这个新的 BlankDisc:
1 | package soundsystem.collectons;import java.util.List;import soundsystem.CompactDisc;public class BlankDisc implements CompactDisc { private String title; private String artist; private List<String> tracks; public BlanDisc(String title, String artist, List<String> tracks) { this.title = title; this.artist = artist; this.tracks = tracks; } public void play() { System.out.println("Playing " + title + " by " + artist); for (String track: tracks) { System.out.println("-Track: " + track); } }} |
这个变更会对 Spring 如何配置 bean 产生影响,在声明 bean 的时候,我们必须要提供一个磁道列表。最简单的办法是将列表设置为 null。因为它是一个构造器参数,所以必须要声明它,不过你可以采用如下的方式传递null给它:
1 | <bean id="compactDisc" class="soundsystem.BlankDisc"> <constructor-arg value="Sgt. Pepper's Lonely Hearts Club Band"/> <constructor-arg value="The Beatles"/> <constructor-arg><null/></constructor-arg></bean> |
<null/> 元素所做的事情与你的期望是一样的:将 null 传递给构造器。这并不是解决问题的好办法,但在注入期它能正常执行。当调用 play() 方法时,你会遇到NullPointerException 异常,因此这并不是理想的方案。更好的解决方法是提供一个磁道名称的列表。要达到这一点,我们可以有多个可选方案。首先,可以使用<list> 元素将其声明为一个列表:
1 | <bean id="compactDisc" class="soundsystem.BlankDisc"> <constructor-arg value="Sgt. Pepper's Lonely Hearts Club Band"/> <constructor-arg value="The Beatles"/> <constructor-arg> <list> <value>Sgt. Pepper's Lonely Hearts Club Band</value> <value>With a Little Help from My Friends</value> <value>Lucy in the Sky with Diamonds</value> </list> </constructor-arg></bean> |
其中,<list> 元素是 <constructor-arg> 的子元素,这表明一个包含值的列表将会传递到构造器中。其中,<value> 元素用来指定列表中的每个元素。
与之类似,我们也可以使用 <ref> 元素替代 <value>,实现 bean 引用列表的装配。例如,假设你有一个 Discography 类,它的构造器如下所示:
1 | public Discography(String artist, List<CompactDisc> cds) {} |
那么,你可以采取如下的方式配置 Discography bean:
1 | <bean id="compactDisc" class="soundsystem.BlankDisc"> <constructor-arg value="Sgt. Pepper's Lonely Hearts Club Band"/> <constructor-arg value="The Beatles"/> <constructor-arg> <list> <ref bean="sgtPeppers"/> <ref bean="WhiteAlbum"/> </list> </constructor-arg></bean> |
当构造器参数的类型是 java.util.List 时,使用 <list> 元素是合情合理的。尽管如此,我们也可以按照同样的方式使用 <set> 元素:
1 | <bean id="compactDisc" class="soundsystem.BlankDisc"> <constructor-arg value="Sgt. Pepper's Lonely Hearts Club Band"/> <constructor-arg value="The Beatles"/> <constructor-arg> <set> <value>Sgt. Pepper's Lonely Hearts Club Band</value> <value>With a Little Help from My Friends</value> <value>Lucy in the Sky with Diamonds</value> </set> </constructor-arg></bean> |
<set> 和 <list> 元素的区别不大,其中最重要的不同在于当 Spring 创建要装配的集合时,所创建的是 java.util.Set 还是 java.util.List。如果是 Set 的话,所有重复的值都会被忽略掉,存放顺序也不会得以保证。不过无论在哪种情况下,<set> 或 <list> 都可以用来装配 List、Set 甚至数组。
在装配集合方面,<constructor-arg> 比 c-命名空间的属性更有优势。目前,使用 c-命名空间的属性无法实现装配集合的功能。
使用 <constructor-arg> 和 c-命名空间实现构造器注入时,它们之间还有一些细微的差别。但是到目前为止,我们所涵盖的内容已经足够了,尤其是像我之前所建议的那样,要首选基于 Java 的配置而不是 XML。因此,与其不厌其烦地花费时间讲述如何使用 XML 进行构造器注入,还不如看一下如何使用 XML 来装配属性。
设置属性
到目前为止,CDPlayer 和 BlankDisc 类完全是通过构造器注入的,没有使用属性的 Setter 方法。接下来,我们就看一下如何使用 Spring XML 实现属性注入。假设属性注入的 CDPlayer 如下所示:
1 | package soundsystem;import org.springframework.beans.factory.annotation.Autowired;public class CDPlayer implements MediaPlayer { private CompactDisc cd; public void setCompactDisc(CompactDisc compactDisc) { this.compactDisc = compactDisc; } public void play() { cd.play(); }} |
该选择构造器注入还是属性注入呢?作为一个通用的规则,我倾向于对强依赖使用构造器注入,而对可选性的依赖使用属性注入。按照这个规则,我们可以说对于 BlankDisc 来讲,唱片名称、艺术家以及磁道列表是强依赖,因此构造器注入是正确的方案。不过,对于 CDPlayer 来讲,它对 CompactDisc 是强依赖还是可选性依赖可能会有些争议。虽然我不太认同,但你可能会觉得即便没有将 CompactDisc 装入进去,CDPlayer 依然还能具备一些有限的功能。
现在,CDPlayer 没有任何的构造器(除了隐含的默认构造器),它也没有任何的强依赖。因此,你可以采用如下的方式将其声明为 Spring bean:
1 | <bean id="cdPlayer" class="soundsystem.CDPlayer"/> |
Spring 在创建 bean 的时候不会有任何的问题,但是 CDPlayerTest 会因为出现 NullPointerException 而导致测试失败,因为我们并没有注入 CDPlayer 的 compactDisc 属性。不过,按照如下的方式修改 XML,就能解决该问题:
1 | <bean id="cdPlayer" class="soundsystem.CDPlayer"> <property name="compactDisc" ref="compactDisc" /></bean> |
<property> 元素为属性的 Setter 方法所提供的功能与 <constructor-arg> 元素为构造器所提供的功能是一样的。在本例中,它引用了 ID 为 compactDisc 的bean(通过ref属性),并将其注入到 compactDisc 属性中(通过 setCompactDisc() 方法)。如果你现在运行测试的话,它应该就能通过了。
我们已经知道,Spring 为 <constructor-arg> 元素提供了 c-命名空间作为替代方案,与之类似,Spring 提供了更加简洁的 p-命名空间,作为 <property> 元素的替代方案。为了启用 p-命名空间,必须要在XML文件中与其他的命名空间一起对其进行声明:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> ...</beans> |
我们可以使用 p-命名空间,按照以下的方式装配 compactDisc 属性:
1 | <bean id="cdPlayer" class="soundsystem.properties.CDPlayer" p:compactDisc-ref="compactDisc" /> |
p-命名空间中属性所遵循的命名约定与 c-命名空间中的属性类似。图 2.2 阐述了p-命名空间属性是如何组成的。
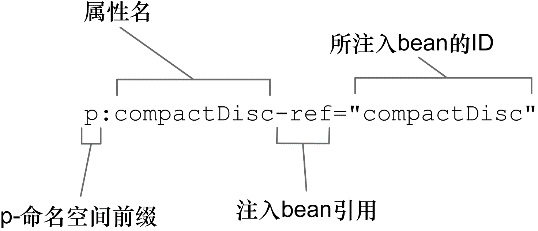
首先,属性的名字使用了 “p:” 前缀,表明我们所设置的是一个属性。接下来就是要注入的属性名。最后,属性的名称以 “-ref” 结尾,这会提示 Spring 要进行装配的是引用,而不是字面量。
将字面量注入到属性中
属性也可以注入字面量,这与构造器参数非常类似。作为示例,我们重新看一下 BlankDisc bean。不过,BlankDisc 这次完全通过属性注入进行配置,而不是构造器注入。新的 BlankDisc 类如下所示:
1 | package soundsystem;import java.util.List;import soundsystem.CompactDisc;public class BlankDisc implements CompactDisc { private String title; private String artist; private List<String> tracks; public BlankDisc(String title, String artist, List<String> tracks) { this.title = title; this.artist = artist; this.tracks = tracks; } public void play() { System.out.println("Playing " + title + " by " + artist); for (String track : tracks) { System.out.println("-Track: " + track); } }} |
现在,它不再强制要求我们装配任何的属性。你可以按照如下的方式创建一个 BlankDiscbean,它的所有属性全都是空的:
1 | <bean id="reallyBlankDisc" class="soundsysem.BlankDisc"/> |
当然,如果在装配 bean 的时候不设置这些属性,那么在运行期 CD 播放器将不能正常播放内容。play() 方法可能会遇到的输出内容是 “Playing null by null”,随之会抛出 NullPointerException 异常,这是因为我们没有指定任何的磁道。所以,我们需要装配这些属性,可以借助 <property> 元素的 value 属性实现该功能:
1 | <bean id="compactDisc" class="soundsystem.properties.BlankDisc"> <property name="title" value="Sgt. Pepper's Lonely Hearts Club Band" /> <property name="artist" value="The Beatles" /> <property name="tracks"> <list> <value>Sgt. Pepper's Lonely Hearts Club Band</value> <value>With a Little Help from My Friends</value> <value>Lucy in the Sky with Diamonds</value> <value>Getting Better</value> <value>Fixing a Hole</value> <value>She's Leaving Home</value> <value>Being for the Benefit of Mr. Kite!</value> <value>Within You Without You</value> <value>When I'm Sixty-Four</value> <value>Lovely Rita</value> <value>Good Morning Good Morning</value> <value>Sgt. Pepper's Lonely Hearts Club Band (Reprise)</value> <value>A Day in the Life</value> </list> </property></bean> |
在这里,除了使用 元素来设置 tracks属性,这与之前通过
另外一种可选方案就是使用 p-命名空间的属性来完成该功能:
1 | <bean id="compactDisc" class="soundsystem.properties.BlankDisc" p:title="Sgt. Pepper's Lonely Hearts Club Band" p:artist="The Beatles"> <property name="tracks"> <list> <value>Sgt. Pepper's Lonely Hearts Club Band</value> <value>With a Little Help from My Friends</value> <value>Lucy in the Sky with Diamonds</value> <value>Getting Better</value> <value>Fixing a Hole</value> <value>She's Leaving Home</value> <value>Being for the Benefit of Mr. Kite!</value> <value>Within You Without You</value> <value>When I'm Sixty-Four</value> <value>Lovely Rita</value> <value>Good Morning Good Morning</value> <value>Sgt. Pepper's Lonely Hearts Club Band (Reprise)</value> <value>A Day in the Life</value> </list> </property></bean> |
与 c-命名空间一样,装配 bean 引用与装配字面量的唯一区别在于是否带有 “-ref” 后缀。如果没有 “-ref” 后缀的话,所装配的就是字面量。
但需要注意的是,我们不能使用 p-命名空间来装配集合,没有便利的方式使用 p-命名空间来指定一个值(或 bean 引用)的列表。但是,我们可以使用 Spring util-命名空间中的一些功能来简化 BlankDiscbean。
首先,需要在 XML 中声明 util-命名空间及其模式:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:util="http://www.springframework.org/schema/util" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util.xsd"> ...</beans> |
util-命名空间所提供的功能之一就是 <util:list> 元素,它会创建一个列表的 bean。借助 <util:list>,我们可以将磁道列表转移到 BlankDisc bean之外,并将其声明到单独的 bean 之中,如下所示:
1 | <util:list id="trackList"> <value>Sgt. Pepper's Lonely Hearts Club Band</value> <value>With a Little Help from My Friends</value> <value>Lucy in the Sky with Diamonds</value> <value>Getting Better</value> <value>Fixing a Hole</value> <value>She's Leaving Home</value> <value>Being for the Benefit of Mr. Kite!</value> <value>Within You Without You</value> <value>When I'm Sixty-Four</value> <value>Lovely Rita</value> <value>Good Morning Good Morning</value> <value>Sgt. Pepper's Lonely Hearts Club Band (Reprise)</value> <value>A Day in the Life</value> </util:list> |
<util:list> 只是 util-命名空间中的多个元素之一。表 2.1 列出了 util-命名空间提供的所有元素。
在需要的时候,你可能会用到 util-命名空间中的部分成员。但现在,在结束本章前,我们看一下如何将自动化配置、 JavaConfig 以及 XML配置混合并匹配在一起。
| 元 素 | 描 述 |
|---|---|
<util:constant> |
引用某个类型的 public static 域,并将其暴露为 bean |
| util:list | 创建一个 java.util.List 类型的 bean,其中包含值或引用 |
| util:map | 创建一个 java.util.Map 类型的 bean,其中包含值或引用 |
| util:properties | 创建一个 java.util.Properties 类型的 bean |
| util:property-path | 引用一个 bean 的属性(或内嵌属性),并将其暴露为 bean |
| util:set | 创建一个 java.util.Set 类型的 bean,其中包含值或引用 |
导入和混合配置
在典型的 Spring 应用中,我们可能会同时使用自动化和显式配置。即便你更喜欢通过 JavaConfig 实现显式配置,但有的时候XML却是最佳的方案。
幸好在 Spring 中,这些配置方案都不是互斥的。你尽可以将 JavaConfig 的组件扫描和自动装配和 / 或 XML 配置混合在一起。实际上,就像在 2.2.1 小节中所看到的,我们至少需要有一点显式配置来启用组件扫描和自动装配。
关于混合配置,第一件需要了解的事情就是在自动装配时,它并不在意要装配的 bean 来自哪里。自动装配的时候会考虑到 Spring 容器中所有的 bean,不管它是在 JavaConfig 或 XML 中声明的还是通过组件扫描获取到的。
你可能会想在显式配置时,比如在 XML 配置和 Java 配置中该如何引用 bean 呢。让我们先看一下如何在 JavaConfig 中引用 XML 配置的 bean。
在 JavaConfig 中引用 XML 配置
现在,我们临时假设 CDPlayerConfig 已经变得有些笨重,我们想要将其进行拆分。当然,它目前只定义了两个 bean,远远称不上复杂的 Spring 配置。不过,我们假设两个 bean 就已经太多了。
我们所能实现的一种方案就是将 BlankDisc 从 CDPlayerConfig 拆分出来,定义到它自己的 CDConfig 类中,如下所示:
1 | package soundsystem;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration; class CDConfig { public CompactDisc compactDisc() { return new SgtPeppers(); }} |
compactDisc() 方法已经从 CDPlayerConfig 中移除掉了,我们需要有一种方式将这两个类组合在一起。一种方法就是在 CDPlayerConfig 中使用 @Import 注解导入 CDConfig:
1 | package soundsystem;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.Import;public class CDPlayerConfig { public CDPlayer cdPlayer(CompactDisc compactDisc) { return new CDPlayer(compactDisc); }} |
或者采用一个更好的办法,也就是不在 CDPlayerConfig 中使用 @Import,而是创建一个更高级别的 SoundSystemConfig,在这个类中使用 @Import 将两个配置类组合在一起:
1 | package soundsystem;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.Import;import org.springframework.context.annotation.ImportResource;public class SoundSystemConfig {} |
不管采用哪种方式,我们都将 CDPlayer 的配置与 BlankDisc 的配置分开了。现在,我们假设(基于某些原因)希望通过 XML 来配置 BlankDisc,如下所示:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:c="http://www.springframework.org/schema/c" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="compactDisc" class="soundsystem.BlankDisc" c:_0="Sgt. Pepper's Lonely Hearts Club Band" c:_1="The Beatles"> <constructor-arg> <list> <value>Sgt. Pepper's Lonely Hearts Club Band</value> <value>With a Little Help from My Friends</value> <value>Lucy in the Sky with Diamonds</value> <value>Getting Better</value> <value>Fixing a Hole</value> <!-- ...other tracks omitted for brevity... --> </list> </constructor-arg> </bean></beans> |
现在 BlankDisc 配置在了 XML 之中,我们该如何让 Spring 同时加载它和其他基于 Java 的配置呢?
答案是 @ImportResource 注解,假设 BlankDisc 定义在名为 cdconfig.xml 的文件中,该文件位于根类路径下,那么可以修改 SoundSystemConfig,让它使用@ImportResource注解,如下所示:
1 | public class SoundSystemConfig {} |
两个 bean——配置在 JavaConfig 中的 CDPlayer 以及配置在 XML 中 BlankDisc——都会被加载到 Spring 容器之中。因为 CDPlayer 中带有 @Bean 注解的方法接受一个 CompactDisc 作为参数,因此 BlankDisc 将会装配进来,此时与它是通过 XML 配置的没有任何关系。
让我们继续这个练习,但是这一次,我们需要在 XML 中引用 JavaConfig 声明的 bean。
在 XML 配置中引用 JavaConfig
假设你正在使用 Spring 基于 XML 的配置并且你已经意识到 XML 逐渐变得无法控制。像前面一样,我们正在处理的是两个 bean,但事情实际上会变得更加糟糕。在被无数的尖括号淹没之前,我们决定将 XML 配置文件进行拆分。
在 JavaConfig 配置中,我们已经展现了如何使用 @Import 和 @ImportResource 来拆分 JavaConfig 类。在 XML 中,我们可以使用 import 元素来拆分 XML 配置。
比如,假设希望将 BlankDisc bean 拆分到自己的配置文件中,该文件名为 cd-config.xml,这与我们之前使用@ImportResource 是一样的。我们可以在 XML 配置文件中使用 <import> 元素来引用该文件:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:c="http://www.springframework.org/schema/c" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="compactDisc" class="soundsystem.SgtPeppers" /> <bean id="cdPlayer" class="soundsystem.CDPlayer" c:cd-ref="compactDisc" /></beans> |
现在,我们假设不再将 BlankDisc 配置在 XML 之中,而是将其配置在 JavaConfig 中,CDPlayer 则继续配置在 XML 中。基于 XML 的配置该如何引用一个 JavaConfig 类呢?
事实上,答案并不那么直观。<import> 元素只能导入其他的 XML 配置文件,并没有 XML 元素能够导入 JavaConfig 类。
但是,有一个你已经熟知的元素能够用来将 Java 配置导入到 XML 配置中:<bean> 元素。为了将 JavaConfig 类导入到 XML 配置中,我们可以这样声明 bean:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:c="http://www.springframework.org/schema/c" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean class="soundsystem.CDConfig" /> <bean id="cdPlayer" class="soundsystem.CDPlayer" c:cd-ref="compactDisc" /></beans> |
采用这样的方式,两种配置——其中一个使用 XML 描述,另一个使用 Java 描述——被组合在了一起。类似地,你可能还希望创建一个更高层次的配置文件,这个文件不声明任何的 bean,只是负责将两个或更多的配置组合起来。例如,你可以将 CDConfig bean 从之前的 XML 文件中移除掉,而是使用第三个配置文件将这两个组合在一起:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:c="http://www.springframework.org/schema/c" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean class="soundsystem.CDConfig" /> <import resource="cdplayer-config.xml"/></beans> |
不管使用 JavaConfig 还是使用 XML 进行装配,我通常都会创建一个根配置(root configuration),也就是这里展现的这样,这个配置会将两个或更多的装配类和 / 或 XML 文件组合起来。我也会在根配置中启用组件扫描(通过<context:component-scan> 或 @ComponentScan)。你会在本书的很多例子中看到这种技术。
小结
Spring 框架的核心是 Spring 容器。容器负责管理应用中组件的生命周期,它会创建这些组件并保证它们的依赖能够得到满足,这样的话,组件才能完成预定的任务。
在本章中,我们看到了在 Spring 中装配 bean 的三种主要方式:自动化配置、基于 Java 的显式配置以及基于 XML 的显式配置。不管你采用什么方式,这些技术都描述了 Spring 应用中的组件以及这些组件之间的关系。
我同时建议尽可能使用自动化配置,以避免显式配置所带来的维护成本。但是,如果你确实需要显式配置 Spring 的话,应该优先选择基于 Java 的配置,它比基于 XML 的配置更加强大、类型安全并且易于重构。在本书中的例子中,当决定如何装配组件时,我都会遵循这样的指导意见。
因为依赖注入是 Spring 中非常重要的组成部分,所以本章中介绍的技术在本书中所有的地方都会用到。基于这些基础知识,下一章将会介绍一些更为高级的 bean 装配技术,这些技术能够让你更加充分地发挥 Spring 容器的威力。
高级装配
本章内容:
- Spring profile
- 条件化的 bean 声明
- 自动装配与歧义性
- bean 的作用域
- Spring 表达式语言
在上一章中,我们看到了一些最为核心的 bean 装配技术。你可能会发现上一章学到的知识有很大的用处。但是,bean 装配所涉及的领域并不仅仅局限于上一章所学习到的内容。Spring 提供了多种技巧,借助它们可以实现更为高级的 bean 装配功能。
在本章中,我们将会深入介绍一些这样的高级技术。本章中所介绍的技术也许你不会天天都用到,但这并不意味着它们的价值会因此而降低。
环境与 profile
在开发软件的时候,有一个很大的挑战就是将应用程序从一个环境迁移到另外一个环境。开发阶段中,某些环境相关做法可能并不适合迁移到生产环境中,甚至即便迁移过去也无法正常工作。数据库配置、加密算法以及与外部系统的集成是跨环境部署时会发生变化的几个典型例子。
比如,考虑一下数据库配置。在开发环境中,我们可能会使用嵌入式数据库,并预先加载测试数据。例如,在 Spring 配置类中,我们可能会在一个带有 @Bean 注解的方法上使用 EmbeddedDatabaseBuilder:
1 | public DataSource dataSource() { return new EmbeddedDatabaseBuilder() .addScript("classpath:schema.sql") .addScript("classpath:test-data.sql") .builder();} |
这会创建一个类型为 javax.sql.DataSource 的 bean,这个 bean 是如何创建出来的才是最有意思的。使用 EmbeddedDatabaseBuilder 会搭建一个嵌入式的 Hypersonic 数据库,它的模式(schema)定义在 schema.sql 中,测试数据则是通过 test-data.sql 加载的。
当你在开发环境中运行集成测试或者启动应用进行手动测试的时候,这个 DataSource 是很有用的。每次启动它的时候,都能让数据库处于一个给定的状态。
尽管 EmbeddedDatabaseBuilder 创建的 DataSource 非常适于开发环境,但是对于生产环境来说,这会是一个糟糕的选择。在生产环境的配置中,你可能会希望使用 JNDI 从容器中获取一个 DataSource。在这样场景中,如下的 @Bean 方法会更加合适:
1 | DataSource dataSource() { JndiObjectFactoryBean jndiObjectFactoryBean = new JndiObjectFactoryBean(); jndiObjectFactoryBean.setJndiName("jdbc/myDS"); jndiObjectFactoryBean.setResourceRef(true); jndiObjectFactoryBean.setProxyInterface(javax.sql.DataSource.class); return (DataSource) jndiObjectFactoryBean.getObject();} |
通过 JNDI 获取 DataSource 能够让容器决定该如何创建这个 DataSource,甚至包括切换为容器管理的连接池。即便如此,JNDI 管理的 DataSource 更加适合于生产环境,对于简单的集成和开发测试环境来说,这会带来不必要的复杂性。
同时,在 QA 环境中,你可以选择完全不同的 DataSource 配置,可以配置为 Commons DBCP 连接池,如下所示:
1 | public DataSource dataSource() { BasicDataSource dataSource = new BasicDataSource(); dataSource.setUrl("jdbc:h2:tcp://dbserver/~/test"); dataSource.setDriverClassName("org.h2.Driver"); dataSource.setUsername("sa"); dataSource.setPassword("password"); dataSource.setInitialSize(20); dataSource.setMaxActive(30); return dataSource;} |
显然,这里展现的三个版本的 dataSource() 方法互不相同。虽然它们都会生成一个类型为 javax.sql.DataSource 的 bean,但它们的相似点也仅限于此了。每个方法都使用了完全不同的策略来生成 DataSource bean。
再次强调的是,这里的讨论并不是如何配置 DataSource(我们将会在第 10 章更详细地讨论这个话题)。看起来很简单的 DataSource 实际上并不是那么简单。这是一个很好的例子,它表现了在不同的环境中某个 bean 会有所不同。我们必须要有一种方法来配置 DataSource,使其在每种环境下都会选择最为合适的配置。
其中一种方式就是在单独的配置类(或 XML 文件)中配置每个 bean,然后在构建阶段(可能会使用 Maven 的 profiles) 确定要将哪一个配置编译到可部署的应用中。这种方式的问题在于要为每种环境重新构建应用。当从开发阶段迁移到 QA 阶段时,重新构建也许算不上什么大问题。但是,从 QA 阶段迁移到生产阶段时,重新构建可能会引入 bug 并且会在 QA 团队的成员中带来不安的情绪。
值得庆幸的是,Spring 所提供的解决方案并不需要重新构建。
配置 profile bean
Spring 为环境相关的 bean 所提供的解决方案其实与构建时的方案没有太大的差别。当然,在这个过程中需要根据环境决定该创建哪个 bean 和不创建哪个 bean。不过 Spring 并不是在构建的时候做出这样的决策,而是等到运行时再来确定。这样的结果就是同一个部署单元(可能会是 WAR 文件)能够适用于所有的环境,没有必要进行重新构建。
在 3.1 版本中,Spring 引入了 bean profile 的功能。要使用 profile,你首先要将所有不同的 bean 定义整理到一个或多个 profile 之中,在将应用部署到每个环境时,要确保对应的 profile 处于激活(active)的状态。
在 Java 配置中,可以使用 @Profile注解指定某个 bean 属于哪一个 profile。例如,在配置类中,嵌入式数据库的 DataSource 可能会配置成如下所示:
1 | package com.myapp;import javax.sql.DataSource;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.Profile;import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseBuilder;import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseType;import org.springframework.jndi.JndiObjectFactoryBean;public class DataSourceConfig { public DataSource embeddedDataSource() { return new EmbeddedDatabaseBuilder() .setType(EmbeddedDatabaseType.H2) .addScript("classpath:schema.sql") .addScript("classpath:test-data.sql") .build(); }} |
我希望你能够注意的是 @Profile 注解应用在了类级别上。它会告诉 Spring 这个配置类中的 bean 只有在 dev profile 激活时才会创建。如果 dev profile 没有激活的话,那么带有 @Bean 注解的方法都会被忽略掉。
同时,你可能还需要有一个适用于生产环境的配置,如下所示:
1 | package com.myapp;import javax.sql.DataSource;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.Profile;import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseBuilder;import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseType;import org.springframework.jndi.JndiObjectFactoryBean;public class DataSourceConfig { public DataSource jndiDataSource() { JndiObjectFactoryBean jndiObjectFactoryBean = new JndiObjectFactoryBean(); jndiObjectFactoryBean.setJndiName("jdbc/myDS"); jndiObjectFactoryBean.setResourceRef(true); jndiObjectFactoryBean.setProxyInterface(javax.sql.DataSource.class); return (DataSource) jndiObjectFactoryBean.getObject(); }} |
在本例中,只有 prod profile 激活的时候,才会创建对应的 bean。
在 Spring 3.1 中,只能在类级别上使用 @Profile 注解。不过,从 Spring 3.2 开始,你也可以在方法级别上使用 @Profile 注解,与 @Bean 注解一同使用。这样的话,就能将这两个 bean 的声明放到同一个配置类之中,如下所示:
1 | package com.myapp;import javax.sql.DataSource;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.Profile;import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseBuilder;import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseType;import org.springframework.jndi.JndiObjectFactoryBean; class DataSourceConfig { public DataSource embeddedDataSource() { return new EmbeddedDatabaseBuilder() .setType(EmbeddedDatabaseType.H2) .addScript("classpath:schema.sql") .addScript("classpath:test-data.sql") .build(); } public DataSource jndiDataSource() { JndiObjectFactoryBean jndiObjectFactoryBean = new JndiObjectFactoryBean(); jndiObjectFactoryBean.setJndiName("jdbc/myDS"); jndiObjectFactoryBean.setResourceRef(true); jndiObjectFactoryBean.setProxyInterface(javax.sql.DataSource.class); return (DataSource) jndiObjectFactoryBean.getObject(); }} |
这里有个问题需要注意,尽管每个 DataSource bean 都被声明在一个 profile 中,并且只有当规定的 profile 激活时,相应的 bean 才会被创建,但是可能会有其他的 bean 并没有声明在一个给定的 profile 范围内。没有指定 profile 的 bean 始终都会被创建,与激活哪个 profile 没有关系。
在 XML 中配置 profile
我们也可以通过 <beans> 元素的 profile 属性,在 XML 中配置 profile bean。例如,为了在 XML 中定义适用于开发阶段的嵌入式数据库 DataSource bean,我们可以创建如下所示的 XML 文件:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:jdbc="http://www.springframework.org/schema/jdbc" xmlns:jee="http://www.springframework.org/schema/jee" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee.xsd http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd" profile="dev"> <jdbc:embedded-database id="dataSource" type="H2"> <jdbc:script location="classpath:schema.sql" /> <jdbc:script location="classpath:test-data.sql" /> </jdbc:embedded-database></beans> |
与之类似,我们也可以将 profile 设置为 prod,创建适用于生产环境的从 JNDI 获取 的DataSource bean。同样,可以创建基于连接池定义的 DataSource bean,将其放在另外一个 XML 文件中,并标注为 qaprofile。所有的配置文件都会放到部署单元之中(如WAR文件),但是只有 profile 属性与当前激活 profile 相匹配的配置文件才会被用到。
你还可以在根 <beans> 元素中嵌套定义 <beans> 元素,而不是为每个环境都创建一个 profile XML 文件。这能够将所有的 profile bean 定义放到同一个 XML 文件中,如下所示:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:jdbc="http://www.springframework.org/schema/jdbc" xmlns:jee="http://www.springframework.org/schema/jee" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee.xsd http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <beans profile="dev"> <jdbc:embedded-database id="dataSource" type="H2"> <jdbc:script location="classpath:schema.sql" /> <jdbc:script location="classpath:test-data.sql" /> </jdbc:embedded-database> </beans> <beans profile="qa"> <bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destory-method="close" p:url="jdbc:h2:tcp://dbserver/~/test" ... </beans> <beans profile="prod"> <jee:jndi-lookup id="dataSource" lazy-init="true" jndi-name="jdbc/myDatabase" resource-ref="true" proxy-interface="javax.sql.DataSource" /> </beans></beans> |
除了所有的 bean 定义到了同一个XML文件之中,这种配置方式与定义在单独的XML文件中的实际效果是一样的。这里有三个 bean,类型都是 javax.sql.DataSource,并且 ID 都是 dataSource。但是在运行时,只会创建一个 bean,这取决于处于激活状态的是哪个 profile。
那么问题来了:我们该怎样激活某个 profile 呢?
激活 profile
Spring 在确定哪个 profile 处于激活状态时,需要依赖两个独立的属性:spring.profiles.active 和 spring.profiles.default。如果设置了 spring.profiles.active 属性的话,那么它的值就会用来确定哪个 profile 是激活的。但如果没有设置 spring.profiles.active 属性的话,那 Spring 将会查找 spring.profiles.default 的值。如果 spring.profiles.active 和 spring.profiles.default 均没有设置的话,那就没有激活的profile,因此只会创建那些没有定义在 profile 中的 bean。
有多种方式来设置这两个属性:
- 作为 DispatcherServlet 的初始化参数;
- 作为 Web 应用的上下文参数;
- 作为 JNDI 条目;
- 作为环境变量;
- 作为 JVM 的系统属性;
- 在集成测试类上,使用 @ActiveProfiles 注解设置。
你尽可以选择 spring.profiles.active 和 spring.profiles.default 的最佳组合方式以满足需求,我将这样的自主权留给读者。
我所喜欢的一种方式是使用 DispatcherServlet 的参数将 spring.profiles.default 设置为开发环境的 profile,我会在 Servlet 上下文中进行设置(为了兼顾到 ContextLoaderListener)。例如,在 Web 应用中,设置 spring.profiles.default 的 web.xml 文件会如下所示:
1 | <web-app version="2.5" xmlns="http://java.sun.com/xml/ns/javeee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javeee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"> <context-param> <param-name>contextConfigLocation</param-name> <param-value>/WEB-INF/spring/root-context.xml</param-value> </context-param> <context-param> <!--为上下文设置默认的 profile--> <param-name>spring.profiles.default</param-name> <param-value>dev</param-value> </context-param> <listener> <listener-class> org.springramework.web.context.ContextLoaderListener </listener-class> </listener> <servlet> <servlet-name>appServlet</servlet-name> <servlet-class> org.springframework.web.servlet.DispatcherServlet </servlet-class> <init-param> <!--为 servlet 设置默认的 profile--> <param-name>spring.profiles.default</param-name> <param-value>dev</param-value> </init-param> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>appServlet</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping></web-app> |
按照这种方式设置 spring.profiles.default,所有的开发人员都能从版本控制软件中获得应用程序源码,并使用开发环境的设置(如嵌入式数据库)运行代码,而不需要任何额外的配置。
当应用程序部署到 QA、生产或其他环境之中时,负责部署的人根据情况使用系统属性、环境变量或 JNDI 设置 spring.profiles.active 即可。当设置 spring.profiles.active 以后,至于 spring.profiles.default 置成什么值就已经无所谓了;系统会优先使用 spring.profiles.active 中所设置的 profile。
你可能已经注意到了,在 spring.profiles.active 和 spring.profiles.default 中,profile 使用的都是复数形式。这意味着你可以同时激活多个 profile,这可以通过列出多个 profile 名称,并以逗号分隔来实现。当然,同时启用 dev 和 prod profile 可能也没有太大的意义,不过你可以同时设置多个彼此不相关的 profile。
使用 profile 进行测试
当运行集成测试时,通常会希望采用与生产环境(或者是生产环境的部分子集)相同的配置进行测试。但是,如果配置中的 bean 定义在了 profile 中,那么在运行测试时,我们就需要有一种方式来启用合适的 profile。
Spring 提供了 @ActiveProfiles 注解,我们可以使用它来指定运行测试时要激活哪个 profile。在集成测试时,通常想要激活的是开发环境的 profile。例如,下面的测试类片段展现了使用 @ActiveProfiles 激活 dev profile:
1 | public class PersistenceTest {} |
在条件化创建 bean 方面,Spring 的 profile 机制是一种很棒的方法,这里的条件要基于哪个 profile 处于激活状态来判断。Spring 4.0 中提供了一种更为通用的机制来实现条件化的 bean 定义,在这种机制之中,条件完全由你来确定。让我们看一下如何使用 Spring 4 和 @Conditional 注解定义条件化的 bean。
条件化的 bean
假设你希望一个或多个 bean 只有在应用的类路径下包含特定的库时才创建。或者我们希望某个 bean 只有当另外某个特定的 bean 也声明了之后才会创建。我们还可能要求只有某个特定的环境变量设置之后,才会创建某个 bean。
Spring 4 引入了一个新的 @Conditional 注解,它可以用到带有 @Bean 注解的方法上。如果给定的条件计算结果为 true,就会创建这个 bean,否则的话,这个 bean 会被忽略。
例如,假设有一个名为 MagicBean 的类,我们希望只有设置了 magic 环境属性的时候,Spring 才会实例化这个类。如果环境中没有这个属性,那么 MagicBean 将会被忽略。在程序清单 3.4 所展现的配置中,使用 @Conditional 注解条件化地配置了 MagicBean。
1 | public MagicBean magicBean() { return new MagicBean;} |
可以看到,@Conditional 中给定了一个 Class,它指明了条件 —— 在本例中,也就是 MagicExistsCondition。@Conditional 将会通过 Condition 接口进行条件对比:
1 | public interface Condition { boolean matches (ConditionContext ctxt, AnnotatedTypeMetadata metadata);} |
设置给 @Conditional 的类可以是任意实现了 Condition 接口的类型。可以看出来,这个接口实现起来很简单直接,只需提供 matches() 方法的实现即可。如果matches() 方法返回 true,那么就会创建带有 @Conditional 注解的 bean。如果 matches() 方法返回 false,将不会创建这些 bean。
在本例中,我们需要创建 Condition 的实现并根据环境中是否存在 magic 属性来做出决策。程序清单 3.5 展现了 MagicExistsCondition,这是完成该功能的Condition实现类:
1 | package com.habuma.restfun;import org.springframework.context.annotation.Condition;import org.springframework.context.annotation.ConditionContext;import org.springframework.core.env.Environment;import org.springframework.core.type.AnnotatedTypeMetadata;public class MagicExistsCondition implements Condition { public boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) { Environment env = context.getEnvironment(); return env.containsProperty("magic"); } } |
在上面的程序清单中,matches() 方法很简单但功能强大。它通过给定的 ConditionContext 对象进而得到 Environment 对象,并使用这个对象检查环境中是否存在名为 magic 的环境属性。在本例中,属性的值是什么无所谓,只要属性存在即可满足要求。如果满足这个条件的话,matches() 方法就会返回 true。所带来的结果就是条件能够得到满足,所有 @Conditional 注解上引用 MagicExistsCondition 的 bean 都会被创建。
话说回来,如果这个属性不存在的话,就无法满足条件,matches() 方法会返回 false,这些 bean 都不会被创建。
MagicExistsCondition 中只是使用了 ConditionContext 得到的 Environment,但 Condition 实现的考量因素可能会比这更多。matches() 方法会得到ConditionContext 和 AnnotatedTypeMetadata 对象用来做出决策。
ConditionContext 是一个接口,大致如下所示:
1 | public interface ConditionContext { BeanDefinitionRegistry getRegistry(); ConfigurableListableBeanFactory getBeanFactory(); Environment getEnvironment(); ResourceLoader getResourceLoader(); ClassLoader getClassLoader();} |
通过 ConditionContext,我们可以做到如下几点:
借助 getRegistry() 返回的 BeanDefinitionRegistry 检查 bean 定义;
借助 getBeanFactory() 返回的 ConfigurableListableBeanFactory 检查 bean 是否存在,甚至探查 bean 的属性;
借助 getEnvironment() 返回的 Environment 检查环境变量是否存在以及它的值是什么;
读取并探查 getResourceLoader() 返回的 ResourceLoader 所加载的资源;
借助 getClassLoader() 返回的 ClassLoader 加载并检查类是否存在。
AnnotatedTypeMetadata 则能够让我们检查带有 @Bean 注解的方法上还有什么其他的注解。像 ConditionContext 一样,AnnotatedTypeMetadata 也是一个接口。它如下所示:
1 | public interface AnnotatedTypeMetadata { default boolean isAnnotated(String annotationName); default Map<String, Object> getAnnotationAttributes(String annotationName); default Map<String, Object> getAnnotationAttributes(String annotationName, boolean classValuesAsString); default MultiValueMap<String, Object> getAllAnnotationAttributes(String annotationName); default MultiValueMap<String, Object> getAllAnnotationAttributes(String annotationName, boolean classValuesAsString);} |
借助 isAnnotated() 方法,我们能够判断带有 @Bean 注解的方法是不是还有其他特定的注解。借助其他的那些方法,我们能够检查 @Bean 注解的方法上其他注解的属性。
从 Spring 4 开始,@Profile 注解进行了重构,使其基于 @Conditional 和 Condition 实现。作为如何使用 @Conditional 和 Condition 的例子,我们来看一下在 Spring 4 中,@Profile 是如何实现的。
1 | public Profile { String[] value();} |
注意:@Profile 本身也使用了 @Conditional 注解,并且引用 ProfileCondition 作为 Condition 实现。如下所示, ProfileCondition 实现了 Condition 接口,并且在做出决策的过程中,考虑到了 ConditionContext 和 AnnotatedTypeMetadata 中的多个因素。
1 | class ProfileCondition implements Condition { public boolean matches(ConditonContext context, AnnotatedTypeMetadata metadata) { if (context.getEnvironment() != null) { MultiValueMap<String, object> attrs = metadata.getAllAnnotationAttributes(Profile.class.getname()); if (attrs != null) { for (Object value : attrs.get("value")) { if (context.getEnvironment().acceptsProfiles(((String[]) value))) { return true; } } return false; } } return true; }} |
我们可以看到,ProfileCondition 通过 AnnotatedTypeMetadata 得到了用于 @Profile 注解的所有属性。借助该信息,它会明确地检查 value 属性,该属性包含了 bean 的 profile 名称。然后,它根据通过 ConditionContext 得到的 Environment 来检查[借助 acceptsProfiles() 方法]该 profile 是否处于激活状态。
处理自动装配的歧义性
在第 2 章中,我们已经看到如何使用自动装配让 Spring 完全负责将 bean 引用注入到构造参数和属性中。自动装配能够提供很大的帮助,因为它会减少装配应用程序组件时所需要的显式配置的数量。
不过,仅有一个 bean 匹配所需的结果时,自动装配才是有效的。如果不仅有一个 bean 能够匹配结果的话,这种歧义性会阻碍 Spring 自动装配属性、构造器参数或方法参数。
为了阐述自动装配的歧义性,假设我们使用 @Autowired 注解标注了 setDessert() 方法:
1 | void setDessert(Dessert dessert) { this.dessert = dessert;} |
在本例中,Dessert 是一个接口,并且有三个类实现了这个接口,分别为 Cake、Cookies 和 IceCream:
1 | class Cake implements Dessert {} class Cookies implements Dessert {} class IceCream implements Dessert {} |
因为这三个实现均使用了 @Component 注解,在组件扫描的时候,能够发现它们并将其创建为 Spring 应用上下文里面的 bean。然后,当 Spring 试图自动装配 setDessert() 中的 Dessert 参数时,它并没有唯一、无歧义的可选值。在从多种甜点中做出选择时,尽管大多数人并不会有什么困难,但是 Spring 却无法做出选择。Spring此时别无他法,只好宣告失败并抛出异常。更精确地讲,Spring 会抛出 NoUniqueBeanDefinitionException:

当然,使用吃甜点的样例来阐述自动装配在遇到歧义性时所面临的问题多少有些牵强。在实际中,自动装配歧义性的问题其实比你想象中的更为罕见。就算这种歧义性确实是个问题,但更常见的情况是给定的类型只有一个实现类,因此自动装配能够很好地运行。
但是,当确实发生歧义性的时候,Spring 提供了多种可选方案来解决这样的问题。你可以将可选 bean中 的某一个设为首选(primary)的 bean,或者使用限定符(qualifier)来帮助 Spring 将可选的 bean 的范围缩小到只有一个 bean。
标示首选的 bean
在声明 bean 的时候,通过将其中一个可选的 bean 设置为首选(primary)bean 能够避免自动装配时的歧义性。当遇到歧义性的时候,Spring 将会使用首选的 bean,而不是其他可选的 bean。
在 Spring 中,可以通过 @Primary 来表达最喜欢的方案。@Primary 能够与 @Component 组合用在组件扫描的 bean 上,也可以与 @Bean 组合用在 Java 配置的 bean 声明中。
1 | class IceCream implements Dessert{} |
或者,如果你通过 Java 配置显式地声明 IceCream,那么 @Bean 方法应该如下所示:
1 | Dessert iceCream() { return new IceCream();} |
如果你使用 XML 配置 bean 的话,同样可以实现这样的功能。<bean> 元素有一个 primary 属性用来指定首选的 bean:
1 | <bean id="iceCream" class="com.dessertteater.IceCream" primary="true"/> |
但是,如果你标示了两个或更多的首选 bean,那么它就无法正常工作了。比如,假设 Cake 类如下所示:
1 | class Cake implements Dessert {} |
现在,有两个首选的 Dessert bean:Cake 和 IceCream。这带来了新的歧义性问题。就像 Spring 无法从多个可选的 bean 中做出选择一样,它也无法从多个首选的 bean 中做出选择。显然,如果不止一个 bean 被设置成了首选 bean,那实际上也就是没有首选 bean 了。
就解决歧义性问题而言,限定符是一种更为强大的机制,下面就将对其进行介绍。
限定自动装配的 bean
Spring 的限定符能够在所有可选的 bean 上进行缩小范围的操作,最终能够达到只有一个 bean 满足所规定的限制条件。如果将所有的限定符都用上后依然存在歧义性,那么你可以继续使用更多的限定符来缩小选择范围。
@Qualifier 注解是使用限定符的主要方式。它可以与 @Autowired 和 @Inject 协同使用,在注入的时候指定想要注入进去的是哪个 bean。例如,我们想要确保要将 IceCream 注入到 setDessert() 之中:
1 | public void setDessert(Dessert dessert) { this.dessert = dessert;} |
为 @Qualifier 注解所设置的参数就是想要注入的 bean 的 ID。所有使用 @Component 注解声明的类都会创建为 bean,并且 bean 的 ID 为首字母变为小写的类名。因此,@Qualifier(“iceCream”) 指向的是组件扫描时所创建的 bean,并且这个 bean 是 IceCream 类的实例。
实际上,还有一点需要补充一下。更准确地讲,@Qualifier(“iceCream”) 所引用的 bean 要具有 String 类型的 “iceCream” 作为限定符。如果没有指定其他的限定符的话,所有的 bean 都会给定一个默认的限定符,这个限定符与 bean 的 ID 相同。因此,框架会将具有 “iceCream” 限定符的 bean 注入到 setDessert() 方法中。这恰巧就是 ID 为 iceCream 的 bean,它是 IceCream 类在组件扫描的时候创建的。
基于默认的 bean ID 作为限定符是非常简单的,但这有可能会引入一些问题。如果你重构了 IceCream 类,将其重命名为 Gelato 的话,那此时会发生什么情况呢?如果这样的话,bean 的 ID 和默认的限定符会变为 gelato,这就无法匹配 setDessert() 方法中的限定符。自动装配会失败。
这里的问题在于 setDessert() 方法上所指定的限定符与要注入的bean的名称是紧耦合的。对类名称的任意改动都会导致限定符失效。
创建自定义的限定符
我们可以为 bean 设置自己的限定符,而不是依赖于将 bean ID 作为限定符。在这里所需要做的就是在 bean 声明上添加 @Qualifier 注解。例如,它可以与@Component 组合使用,如下所示:
1 | public class IceCream implements Dessert {} |
在这种情况下,cold 限定符分配给了 IceCream bean。因为它没有耦合类名,因此你可以随意重构 IceCream 的类名,而不必担心会破坏自动装配。在注入的地方,只要引用 cold 限定符就可以了:
1 | public void setDessert(Dessert dessert) { this.dessert = dessert;} |
值得一提的是,当通过 Java 配置显式定义 bean 的时候,@Qualifier 也可以与 @Bean 注解一起使用:
1 | public Dessert iceCream() { return new IceCream();} |
当使用自定义的 @Qualifier 值时,最佳实践是为 bean 选择特征性或描述性的术语,而不是使用随意的名字。在本例中,我将 IceCream bean 描述为 “cold” bean。在注入的时候,可以将这个需求理解为“给我一个凉的甜点”,这其实就是描述的 IceCream。类似地,我可以将 Cake 描述为 “soft”,将 Cookie 描述为 “crispy”。
使用自定义的限定符注解
面向特性的限定符要比基于 bean ID 的限定符更好一些。但是,如果多个 bean 都具备相同特性的话,这种做法也会出现问题。例如,如果引入了这个新的 Dessert bean,会发生什么情况呢:
1 | public class Popsicle implements Dessert {} |
不会吧?!现在我们有了两个带有 “cold” 限定符的甜点。在自动装配 Dessert bean 的时候,我们再次遇到了歧义性的问题,需要使用更多的限定符来将可选范围限定到只有一个 bean。
可能想到的解决方案就是在注入点和 bean 定义的地方同时再添加另外一个 @Qualifier 注解。IceCream 类大致就会如下所示:
1 | public class IceCream implements Dessert {} |
Popsicle 类同样也可能再添加另外一个 @Qualifier 注解:
1 | public class Popsicle implements Dessert {} |
在注入点中,我们可能会使用这样的方式来将范围缩小到 IceCream:
1 | public void setDessert(Dessert dessert) { this.dessert = dessert;} |
这里只有一个小问题:Java 不允许在同一个条目上重复出现相同类型的多个注解。如果你试图这样做的话,编译器会提示错误。在这里,使用 @Qualifier 注解并没有办法(至少没有直接的办法)将自动装配的可选 bean 缩小范围至仅有一个可选的 bean。
但是,我们可以创建自定义的限定符注解,借助这样的注解来表达 bean 所希望限定的特性。这里所需要做的就是创建一个注解,它本身要使用 @Qualifier 注解来标注。这样我们将不再使用 @Qualifier(“cold”),而是使用自定义的 @Cold 注解,该注解的定义如下所示:
1 | Cold {} |
同样,你可以创建一个新的 @Creamy 注解来代替 @Qualifier(“creamy”):
1 | Creamy {} |
当你不想用 @Qualifier 注解的时候,可以类似地创建 @Soft、@Crispy 和 @Fruity。通过在定义时添加 @Qualifier 注解,它们就具有了 @Qualifier 注解的特性。它们本身实际上就成为了限定符注解。
现在,我们可以重新看一下 IceCream,并为其添加 @Cold 和 @Creamy 注解,如下所示:
1 | class IceCream implements Dessert {} |
类似地,Popsicle 类可以添加 @Cold 和 @Fruity 注解:
1 | class Popsicle implements Dessert {} |
最终,在注入点,我们使用必要的限定符注解进行任意组合,从而将可选范围缩小到只有一个 bean 满足需求。为了得到 IceCream bean,setDessert() 方法可以这样使用注解:
1 | void setDessert(Dessert dessert) { this.dessert = dessert;} |
通过声明自定义的限定符注解,我们可以同时使用多个限定符,不会再有 Java 编译器的限制或错误。与此同时,相对于使用原始的 @Qualifier 并借助 String 类型来指定限定符,自定义的注解也更为类型安全。
让我们近距离观察一下 setDessert() 方法以及它的注解,这里并没有在任何地方明确指定要将 IceCream 自动装配到该方法中。相反,我们使用所需 bean 的特性来进行指定,即 @Cold 和 @Creamy。因此,setDessert() 方法依然能够与特定的 Dessert 实现保持解耦。任意满足这些特征的 bean 都是可以的。在当前选择 Dessert 实现时,恰好如此,IceCream 是唯一能够与之匹配的 bean。
在本节和前面的节中,我们讨论了几种通过自定义注解扩展 Spring 的方式。为了创建自定义的条件化注解,我们创建一个新的注解并在这个注解上添加了 @Conditional。为了创建自定义的限定符注解,我们创建一个新的注解并在这个注解上添加了 @Qualifier。这种技术可以用到很多的 Spring 注解中,从而能够将它们组合在一起形成特定目标的自定义注解。
现在我们来看一下如何在不同的作用域中声明 bean。
bean的作用域
在默认情况下,Spring 应用上下文中所有 bean 都是作为以单例(singleton)的形式创建的。也就是说,不管给定的一个 bean 被注入到其他 bean 多少次,每次所注入的都是同一个实例。
在大多数情况下,单例 bean 是很理想的方案。初始化和垃圾回收对象实例所带来的成本只留给一些小规模任务,在这些任务中,让对象保持无状态并且在应用中反复重用这些对象可能并不合理。
有时候,可能会发现,你所使用的类是易变的(mutable),它们会保持一些状态,因此重用是不安全的。在这种情况下,将 class 声明为单例的 bean 就不是什么好主意了,因为对象会被污染,稍后重用的时候会出现意想不到的问题。
Spring 定义了多种作用域,可以基于这些作用域创建 bean,包括:
- 单例(Singleton):在整个应用中,只创建bean的一个实例。
- 原型(Prototype):每次注入或者通过 Spring 应用上下文获取的时候,都会创建一个新的bean实例。
- 会话(Session):在 Web 应用中,为每个会话创建一个 bean 实例。
- 请求(Rquest):在 Web 应用中,为每个请求创建一个 bean 实例。
单例是默认的作用域,但是正如之前所述,对于易变的类型,这并不合适。如果选择其他的作用域,要使用 @Scope 注解,它可以与 @Component 或 @Bean 一起使用。
例如,如果你使用组件扫描来发现和声明 bean,那么你可以在 bean 的类上使用 @Scope 注解,将其声明为原型 bean:
1 | public class Notepad{} |
这里,使用 ConfigurableBeanFactory 类的 SCOPE_PROTOTYPE 常量设置了原型作用域。你当然也可以使用 @Scope(“prototype”),但是使用 SCOPE_PROTOTYPE 常量更加安全并且不易出错。
如果你想在 Java 配置中将 Notepad 声明为原型 bean,那么可以组合使用 @Scope 和 @Bean 来指定所需的作用域:
1 | public Notepad notepad() { return new Notepad();} |
同样,如果你使用 XML 来配置 bean 的话,可以使用 <bean> 元素的 scope 属性来设置作用域:
1 | <bean id="notepad" class="com.myapp.Notepad" scope="propertype"/> |
不管你使用哪种方式来声明原型作用域,每次注入或从 Spring 应用上下文中检索该 bean 的时候,都会创建新的实例。这样所导致的结果就是每次操作都能得到自己的 Notepad 实例。
使用会话和请求作用域
在 Web 应用中,如果能够实例化在会话和请求范围内共享的 bean,那将是非常有价值的事情。例如,在典型的电子商务应用中,可能会有一个 bean 代表用户的购物车。如果购物车是单例的话,那么将会导致所有的用户都会向同一个购物车中添加商品。另一方面,如果购物车是原型作用域的,那么在应用中某一个地方往购物车中添加商品,在应用的另外一个地方可能就不可用了,因为在这里注入的是另外一个原型作用域的购物车。
就购物车 bean 来说,会话作用域是最为合适的,因为它与给定的用户关联性最大。要指定会话作用域,我们可以使用 @Scope 注解,它的使用方式与指定原型作用域是相同的:
1 | public ShoppingCart ShoppingCart() {} |
这里,我们将 value 设置成了 WebApplicationContext 中的 SCOPE_SESSION 常量(它的值是 session)。这会告诉 Spring 为 Web 应用中的每个会话创建一个ShoppingCart。这会创建多个 ShoppingCart bean 的实例,但是对于给定的会话只会创建一个实例,在当前会话相关的操作中,这个 bean 实际上相当于单例的。
要注意的是,@Scope 同时还有一个 proxyMode 属性,它被设置成了 ScopedProxyMode.INTERFACES。这个属性解决了将会话或请求作用域的 bean 注入到单例 bean 中所遇到的问题。在描述 proxyMode 属性之前,我们先来看一下 proxyMode 所解决问题的场景。
假设我们要将 ShoppingCart bean 注入到单例 StoreService bean 的 Setter 方法中,如下所示:
1 | class StoreService { public void setShoppingCart(ShoppingCart shoppingCart) { this.shoppingCart = shoppingCart; }} |
因为 StoreService 是一个单例的 bean,会在 Spring 应用上下文加载的时候创建。当它创建的时候,Spring 会试图将 ShoppingCart bean 注入到 setShoppingCart() 方法中。但是 ShoppingCart bean 是会话作用域的,此时并不存在。直到某个用户进入系统,创建了会话之后,才会出现 ShoppingCart 实例。
另外,系统中将会有多个 ShoppingCart 实例:每个用户一个。我们并不想让 Spring 注入某个固定的 ShoppingCart 实例到 StoreService 中。我们希望的是当 StoreService 处理购物车功能时,它所使用的 ShoppingCart 实例恰好是当前会话所对应的那一个。
Spring 并不会将实际的 ShoppingCart bean 注入到 StoreService 中,Spring 会注入一个到 ShoppingCart bean 的代理。这个代理会暴露与 ShoppingCart 相同的方法,所以 StoreService 会认为它就是一个购物车。但是,当 StoreService 调用 ShoppingCart 的方法时,代理会对其进行懒解析并将调用委托给会话作用域内真正的 ShoppingCart bean。
现在,我们带着对这个作用域的理解,讨论一下 proxyMode 属性。
如配置所示,proxyMode 属性被设置成了 ScopedProxyMode.INTERFACES,这表明这个代理要实现 ShoppingCart 接口,并将调用委托给实现 bean。
如果 ShoppingCart 是接口而不是类的话,这是可以的(也是最为理想的代理模式)。但如果 ShoppingCart 是一个具体的类的话,Spring 就没有办法创建基于接口的代理了。此时,它必须使用 CGLib 来生成基于类的代理。所以,如果 bean 类型是具体类的话,我们必须要将 proxyMode 属性设置为 ScopedProxyMode.TARGET_CLASS,以此来表明要以生成目标类扩展的方式创建代理。
尽管我主要关注了会话作用域,但是请求作用域的 bean 会面临相同的装配问题。因此,请求作用域的 bean 应该也以作用域代理的方式进行注入。
在 XML 中声明作用域代理
如果你需要使用XML来声明会话或请求作用域的bean,那么就不能使用@Scope注解及其proxyMode属性了。<bean> 元素的 scope 属性能够设置 bean 的作用域,但是该怎样指定代理模式呢?
要设置代理模式,我们需要使用 Spring aop 命名空间的一个新元素:
1 | <bean id="cart" class="com.myapp.ShoppingCart" scope="session"> <aop:scoped-proxy/></bean> |
<aop:scoped-proxy> 是与 @Scope 注解的 proxyMode 属性功能相同的 Spring XML 配置元素。它会告诉 Spring 为 bean 创建一个作用域代理。默认情况下,它会使用 CGLib 创建目标类的代理。但是我们也可以将 proxy-target-class 属性设置为 false,进而要求它生成基于接口的代理:
1 | <bean id="cart" class="com.myapp.ShoppingCart" scope="session"> <aop:scoped-proxy proxy-target-class="false"/></bean> |
在第 4 章中,当我们使用 Spring 和面向切面编程的时候,会讨论 Spring aop 命名空间的更多知识。不过,在结束本章的内容之前,我们来看一下 Spring 高级配置的另外一个可选方案:Spring 表达式语言(Spring Expression Language)。
运行时值注入
当讨论依赖注入的时候,我们通常所讨论的是将一个 bean 引用注入到另一个 bean 的属性或构造器参数中。它通常来讲指的是将一个对象与另一个对象进行关联。
但是 bean 装配的另外一个方面指的是将一个值注入到 bean 的属性或者构造器参数中。我们在第 2 章中已经进行了很多值装配,如将专辑的名字装配到 BlankDisc bean 的构造器或 title 属性中。例如,我们可能按照这样的方式来组装 BlankDisc:
1 | CompactDisc sgtPeppers() { return new BlankDisc("Sgt. Pepper's Lonely Hearts Club Band", "The Battles");} |
尽管这实现了你的需求,也就是为 BlankDisc bean 设置 title 和 artist,但它在实现的时候是将值硬编码在配置类中的。与之类似,如果使用 XML 的话,那么值也会是硬编码的:
1 | <bean id="sgtPeppers" class="soundsystem.BlankDisc" c:_title="Sgt. Pepper's Lonely Hearts Club Band" c:_artist="The Battles" /> |
有时候硬编码是可以的,但有的时候,我们可能会希望避免硬编码值,而是想让这些值在运行时再确定。为了实现这些功能,Spring提供了两种在运行时求值的方式:
- 属性占位符(Property placeholder)。
- Spring表达式语言(SpEL)。
很快你就会发现这两种技术的用法是类似的,不过它们的目的和行为是有所差别的。让我们先看一下属性占位符,在这两者中它较为简单,然后再看一下更为强大的 SpEL。
注入外部的值
在 Spring 中,处理外部值的最简单方式就是声明属性源并通过 Spring 的 Environment 来检索属性。例如,程序清单3.7展现了一个基本的 Spring 配置类,它使用外部的属性来装配 BlankDisc bean。
1 | package com.soundsystem;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.PropertySource;import org.springframework.core.env.Environment; // 声明属性源public class ExpressiveConfig { @Autowired Environment env; @Bean public BlankDisc disc() { return new BlankDisc(env.getProperty("disc.title"), // 检索属性值 env.getProperrty("disc.artist")); }} |
在本例中,@PropertySource 引用了类路径中一个名为 app.properties 的文件。它大致会如下所示:
1 | =Sgt. Pepper's Lonely Hearts Club Banddisc.artist=The Battles |
这个属性文件会加载到 Spring 的 Environment 中,稍后可以从这里检索属性。同时,在 disc() 方法中,会创建一个新的 BlankDisc,它的构造器参数是从属性文件中获取的,而这是通过调用 getProperty() 实现的。
深入学习 Spring 的 Environment
当我们去了解 Environment 的时候会发现,程序清单 3.7 所示的 getProperty() 方法并不是获取属性值的唯一方法, getProperty() 方法有四个重载的变种形式:
- String getProperty(String key)
- String getProperty(String key, String defaultValue)
- T getProperty(String key, Class
type) - T getProperty(String key, Class
type, T defaultValue)
前两种形式的 getProperty()方法都会返回 String 类型的值。我们已经在程序清单 3.7 中看到了如何使用第一种 getProperty() 方法。但是,你可以稍微对@Bean方法进行一下修改,这样在指定属性不存在的时候,会使用一个默认值:
1 | BlankDisc disc() { return new Blank(env.getProperty("disc.title", "Rattle and Hum"), env.getProperty("disc.artist", "U2"));} |
剩下的两种 getProperty() 方法与前面的两种非常类似,但是它们不会将所有的值都视为 String 类型。例如,假设你想要获取的值所代表的含义是连接池中所维持的连接数量。如果我们从属性文件中得到的是一个 String 类型的值,那么在使用之前还需要将其转换为Integer 类型。但是,如果使用重载形式的 getProperty() 的话,就能非常便利地解决这个问题:
1 | int connectionCount = env.getProperty("db.connection.count", Integer.class, 30); |
Environment 还提供了几个与属性相关的方法,如果你在使用 getProperty() 方法的时候没有指定默认值,并且这个属性没有定义的话,获取到的值是 null。如果你希望这个属性必须要定义,那么可以使用 getRequiredProperty() 方法,如下所示:
1 | BlankDisc disc() { return new BlankDisc(env.getRequiredProperty("disc.title"), env.getRequiredProperty("disc.artist"));} |
在这里,如果 disc.title 或 disc.artist 属性没有定义的话,将会抛出 IllegalStateException 异常。
如果想检查一下某个属性是否存在的话,那么可以调用 Environment 的 containsProperty() 方法:
1 | boolean titleExists = env.containsProperty("disc.title"); |
最后,如果想将属性解析为类的话,可以使用 getPropertyAsClass() 方法:
1 | Class<CompactDisc> cdClass = env.getPropertyAsClass("disc.class", CompactDisc.class); |
除了属性相关的功能以外,Environment 还提供了一些方法来检查哪些 profile 处于激活状态:
- String[] getActiveProfiles():返回激活 profile 名称的数组;
- String[] getDefaultProfiles():返回默认 profile 名称的数组;
- boolean acceptsProfiles(String… profiles):如果 environment 支持给定 profile 的话,就返回 true。
在程序清单 3.6 中,我们已经看到了如何使用 acceptsProfiles()。在那个例子中,Environment 是从 ConditionContext 中获取到的,在 bean 创建之前,使用 acceptsProfiles() 方法来确保给定 bean 所需的 profile 处于激活状态。通常来讲,我们并不会频繁使用 Environment 相关的方法,但是知道有这些方法还是有好处的。
直接从 Environment 中检索属性是非常方便的,尤其是在 Java 配置中装配 bean 的时候。但是,Spring 也提供了通过占位符装配属性的方法,这些占位符的值会来源于一个属性源。
解析属性占位符
Spring 一直支持将属性定义到外部的属性的文件中,并使用占位符值将其插入到 Spring bean 中。在 Spring 装配中,占位符的形式为使用 “${… }” 包装的属性名称。作为样例,我们可以在 XML 中按照如下的方式解析 BlankDisc 构造器参数:
1 | <bean id="sgtPeppers" class="soundsystem.BlankDisc" c:_title=${disc.titile} c:_artist=${disc.artist} /> |
可以看到,title 构造器参数所给定的值是从一个属性中解析得到的,这个属性的名称为 disc.title。artist 参数装配的是名为 disc.artist 的属性值。按照这种方式, XML 配置没有使用任何硬编码的值,它的值是从配置文件以外的一个源中解析得到的。
如果我们依赖于组件扫描和自动装配来创建和初始化应用组件的话,那么就没有指定占位符的配置文件或类了。在这种情况下,我们可以使用 @Value 注解,它的使用方式与 @Autowired 注解非常相似。
1 | public BlankDisc( String title, String artist) { this.title = title; this.artist = artist;} |
为了使用占位符,我们必须要配置一个 PropertyPlaceholderConfigurer bean 或 PropertySourcesPlaceholderConfigurer bean。从 Spring 3.1开始,推荐使用 PropertySourcesPlaceholderConfigurer,因为它能够基于 Spring Environment 及其属性源来解析占位符。
如下的 @Bean 方法在 Java 中配置了 PropertySourcesPlaceholderConfigurer:
1 | static PropertySourcesPlaceholderConfigurer placeholderConfigurer() { return new PropertySourcesPlaceholderConfigurer();} |
如果你想使用 XML 配置的话,Spring context 命名空间中的 <context:propertyplaceholder> 元素将会为你生成 PropertySourcesPlaceholderConfigurer bean:
1 | <context:property-placeholder/> |
解析外部属性能够将值的处理推迟到运行时,但是它的关注点在于根据名称解析来自于 Spring Environment 和属性源的属性。而 Spring 表达式语言提供了一种更通用的方式在运行时计算所要注入的值。
使用 Spring 表达式语言进行装配
Spring 3 引入了 Spring 表达式语言(Spring Expression Language,SpEL),它能够以一种强大和简洁的方式将值装配到 bean 属性和构造器参数中,在这个过程中所使用的表达式会在运行时计算得到值。使用 SpEL,你可以实现超乎想象的装配效果,这是使用其他的装配技术难以做到的(甚至是不可能的)。
SpEL 拥有很多特性,包括:
- 使用 bean 的 ID 来引用 bean;
- 调用方法和访问对象的属性;
- 对值进行算术、关系和逻辑运算;
- 正则表达式匹配;
- 集合操作。
SpEL 能够用在依赖注入以外的其他地方。例如,Spring Security 支持使用 SpEL 表达式定义安全限制规则。另外,如果你在 Spring MVC 应用中使用 Thymeleaf 模板作为视图的话,那么这些模板可以使用 SpEL 表达式引用模型数据。
需要了解的第一件事情就是 SpEL 表达式要放到 “#{ … }” 之中,这与属性占位符有些类似,属性占位符需要放到 “${ … }” 之中。下面所展现的可能是最简单的SpEL表达式了:
1 | #{1} |
除去 “#{ … }” 标记之后,剩下的就是 SpEL 表达式体了,也就是一个数字常量。这个表达式的计算结果就是数字 1,这恐怕并不会让你感到丝毫惊讶。
当然,在实际的应用程序中,我们可能并不会使用这么简单的表达式。我们可能会使用更加有意思的表达式,如:
1 | #{T(System).currentTimeMillis()} |
它的最终结果是计算表达式的那一刻当前时间的毫秒数。T() 表达式会将 java.lang.System 视为 Java 中对应的类型,因此可以调用其 static 修饰的currentTimeMillis() 方法。
SpEL 表达式也可以引用其他的 bean 或其他 bean 的属性。例如,如下的表达式会计算得到 ID 为 sgtPeppers 的 bean 的 artist 属性:
1 | #{sgtPeppers.artist} |
我们还可以通过 systemProperties 对象引用系统属性:
1 | #{systemProperties['disc.title']} |
如果通过组件扫描创建 bean 的话,在注入属性和构造器参数时,我们可以使用 @Value 注解,这与之前看到的属性占位符非常类似。不过,在这里我们所使用的不是占位符表达式,而是 SpEL 表达式。例如,下面的样例展现了 BlankDisc,它会从系统属性中获取专辑名称和艺术家的名字:
1 | public BlankDisc( String title, String artist) { this.title = title; this.artist = artist;} |
在 XML 配置中,你可以将 SpEL 表达式传入 <property> 或 <constructor-arg> 的 value 属性中,或者将其作为 p-命名空间或 c-命名空间条目的值。例如,在如下 BlankDisc bean 的 XML 声明中,构造器参数就是通过 SpEL 表达式设置的:
1 | <bean id="sgtPeppers" class="soundsystem.BlankDisc" c:_title="#{systemProperties['disc.title']}" c:_artist="#{systemProperties['disc.artist']}" /> |
表示字面值
我们在前面已经看到了一个使用 SpEL 来表示整数字面量的样例。它实际上还可以用来表示浮点数、String 值以及Boolean 值。
下面的 SpEL 表达式样例所表示的就是浮点值:
1 | #{3.14159} |
数值还可以使用科学记数法的方式进行表示。如下面的表达式计算得到的值就是 98,700:
1 | #{9.87E4} |
SpEL 表达式也可以用来计算 String 类型的字面值,如:
1 | #{'Hello'} |
最后,字面值 true 和 false 的计算结果就是它们对应的 Boolean 类型的值。例如:
1 | #{false} |
在 SpEL 表达式中,只包含字面值情况并没有太大的用处。但需要记住的一点是,更有意思的 SpEL 表达式是由更简单的表达式组成的,因此了解在 SpEL 中如何使用字面量还是很有用处的。当组合更为复杂的表达式时,你迟早会用到它们。
引用 bean、属性和方法
SpEL 所能做的另外一件基础的事情就是通过 ID 引用其他的 bean。例如,你可以使用 SpEL 将一个 bean 装配到另外一个 bean 的属性中,此时要使用 bean ID 作为 SpEL 表达式(在本例中,也就是 sgtPeppers):
1 | #{sgtPeppers} |
现在,假设我们想在一个表达式中引用 sgtPeppers 的 artist 属性:
1 | #{sgtPeppers.artist} |
表达式主体的第一部分引用了一个 ID 为 sgtPeppers 的 bean,分割符之后是对 artist 属性的引用。
除了引用 bean 的属性,我们还可以调用 bean 上的方法。例如,假设有另外一个 bean,它的 ID 为 artistSelector,我们可以在 SpEL 表达式中按照如下的方式来调用 bean 的 selectArtist() 方法:
1 | #{sgtPeppers.selectAtist()} |
对于被调用方法的返回值来说,我们同样可以调用它的方法。例如,如果 selectArtist() 方法返回的是一个 String,那么可以调用 toUpperCase() 将整个艺术家的名字改为大写字母形式:
1 | #{sgtPeppers.selectAtist().toUpperCase()} |
如果 selectArtist() 的返回值不是 null 的话,这没有什么问题。为了避免出现 NullPointerException,我们可以使用类型安全的运算符:
1 | #{sgtPeppers.selectAtist()?.toUpperCase()} |
与之前只是使用点号(.)来访问 toUpperCase() 方法不同,现在我们使用了 “?.” 运算符。这个运算符能够在访问它右边的内容之前,确保它所对应的元素不是 null。所以,如果 selectArtist() 的返回值是 null 的话,那么 SpEL 将不会调用 toUpperCase() 方法。表达式的返回值会是 null。
在表达式中使用类型
如果要在 SpEL 中访问类作用域的方法和常量的话,要依赖 T() 这个关键的运算符。例如,为了在 SpEL 中表达 Java 的 Math 类,需要按照如下的方式使用 T() 运算符:
1 | T(java.lang.Math) |
这里所示的 T() 运算符的结果会是一个 Class 对象,代表了 java.lang.Math。如果需要的话,我们甚至可以将其装配到一个 Class 类型的 bean 属性中。但是 T() 运算符的真正价值在于它能够访问目标类型的静态方法和常量。
例如,假如你需要将 PI 值装配到 bean 属性中。如下的 SpEL 就能完成该任务:
1 | T(java.lang.Math).PI |
与之类似,我们可以调用 T() 运算符所得到类型的静态方法。我们已经看到了通过 T() 调用 System.currentTimeMillis()。如下的这个样例会计算得到一个0到1之间的随机数:
1 | T(java.lang.Math).random() |
SpEL运算符
SpEL提供了多个运算符,这些运算符可以用在SpEL表达式的值上。
| 运算符类型 | 运 算 符 |
|---|---|
| 算术运算 | +、-、 * 、/、%、^ |
| 比较运算 | <、 > 、 == 、 <= 、 >= 、 lt 、 gt 、 eq 、 le 、 ge |
| 逻辑运算 | and 、 or 、 not 、│ |
| 条件运算 | ?: (ternary) 、 ?: (Elvis) |
| 正则表达式 | matches |
作为使用上述运算符的一个简单样例,我们看一下下面这个 SpEL 表达式:
1 | #{2 * T(java.lang.Math).PI * circle.radius} |
这不仅是使用 SpEL 中乘法运算符(*)的绝佳样例,它也为你展现了如何将简单的表达式组合为更为复杂的表达式。在这里 PI 的值乘以 2,然后再乘以 radius 属性的值,这个属性来源于 ID 为 circle 的 bean。实际上,它计算了 circle bean 中所定义圆的周长。
类似地,你还可以在表达式中使用乘方运算符(^)来计算圆的面积:
1 | #{T(java.lang.Math).PI * circle.radius^2} |
“^” 是用于乘方计算的运算符。在本例中,我们使用它来计算圆半径的平方。
当使用 String 类型的值时,“+” 运算符执行的是连接操作,与在 Java 中是一样的:
1 | #{disc.title + 'by' + disc.artist} |
SpEL 同时还提供了比较运算符,用来在表达式中对值进行对比。比较运算符有两种形式:符号形式和文本形式。在大多数情况下,符号运算符与对应的文本运算符作用是相同的,使用哪一种形式均可以。
例如,要比较两个数字是不是相等,可以使用双等号运算符(==):
1 | #{counter.total == 100} |
或者,也可以使用文本型的 eq 运算符:
1 | #{counter.total eq 100} |
两种方式的结果都是一样的。表达式的计算结果是个 Boolean 值:如果 counter.total 等于 100 的话,为 true,否则为 false。
SpEL 还提供了三元运算符(ternary),它与 Java 中的三元运算符非常类似。例如,如下的表达式会判断如果 scoreboard.score>1000 的话,计算结果为 String类型的 “Winner!”,否则的话,结果为 Loser:
1 | #{scoreboard.score > 1000 ? "Winner" : "Loser"} |
三元运算符的一个常见场景就是检查 null 值,并用一个默认值来替代 null。例如,如下的表达式会判断 disc.title 的值是不是 null,如果是 null 的话,那么表达式的计算结果就会是 “Rattle and Hum”:
1 | #{disc.title ?: 'Rattle and Hum'} |
这种表达式通常称为 Elvis 运算符。这个奇怪名称的来历是,当使用符号来表示表情时,问号看起来很像是猫王(Elvis Presley)的头发。
计算正则表达式
当处理文本时,有时检查文本是否匹配某种模式是非常有用的。SpEL 通过 matches 运算符支持表达式中的模式匹配。matches 运算符对 String 类型的文本(作为左边参数)应用正则表达式(作为右边参数)。matches 的运算结果会返回一个 Boolean 类型的值:如果与正则表达式相匹配,则返回 true;否则返回 false。
为了进一步解释 matches 运算符,假设我们想判断一个字符串是否包含有效的邮件地址。在这个场景下,我们可以使用 matches 运算符,如下所示:
1 | #{admin.email mathes '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9._%+-]+\\.com'} |
计算集合
SpEL 中最令人惊奇的一些技巧是与集合和数组相关的。最简单的事情可能就是引用列表中的一个元素了:
1 | #{jukebox.songs[4].title} |
这个表达式会计算 songs 集合中第五个(基于零开始)元素的 title 属性,这个集合来源于 ID 为 jukebox bean。
为了让这个表达式更丰富一些,假设我们要从 jukebox 中随机选择一首歌:
1 | #{jukebox.songs[T(java.lang.Math).random() * jukebox.songs.size()].title} |
“[]” 运算符用来从集合或数组中按照索引获取元素,实际上,它还可以从 String 中获取一个字符。比如:
1 | #{'this is a test'[3]} |
这个表达式引用了 String 中的第 4 个(基于零开始)字符,也就是 “s”。
SpEL 还提供了查询运算符(.?[]),它会用来对集合进行过滤,得到集合的一个子集。作为阐述的样例,假设你希望得到 jukebox 中 artist 属性为 Aerosmith 的所有歌曲。如下的表达式就使用查询运算符得到了 Aerosmith 的所有歌曲:
1 | @{jukebox.songs.?[artist eq 'Aerosmith']} |
可以看到,选择运算符在它的方括号中接受另一个表达式。当 SpEL 迭代歌曲列表的时候,会对歌曲集合中的每一个条目计算这个表达式。如果表达式的计算结果为 true 的话,那么条目会放到新的集合中。否则的话,它就不会放到新集合中。在本例中,内部的表达式会检查歌曲的 artist 属性是不是等于 Aerosmith。
SpEL 还提供了另外两个查询运算符:“.^[]” 和 “.$[]”,它们分别用来在集合中查询第一个匹配项和最后一个匹配项。例如,考虑下面的表达式,它会查找列表中第一个 artist 属性为 Aerosmith 的歌曲:
1 | #{jukebox.songs.^[artist eq 'Aerosmith']} |
最后,SpEL 还提供了投影运算符(.![]),它会从集合的每个成员中选择特定的属性放到另外一个集合中。作为样例,假设我们不想要歌曲对象的集合,而是所有歌曲名称的集合。如下的表达式会将 title 属性投影到一个新的 String 类型的集合中:
1 | #{jukebox.songs.![title]} |
实际上,投影操作可以与其他任意的 SpEL 运算符一起使用。比如,我们可以使用如下的表达式获得 Aerosmith 所有歌曲的名称列表:
1 | #{jukebox.songs.?[artist eq 'Aerosmith'].![title]} |
我们所介绍的只是 SpEL 功能的一个皮毛。在本书中还有更多的机会继续介绍 SpEL,尤其是在定义安全规则的时候。
现在对 SpEL 的介绍要告一段落了,不过在此之前,我们有一个提示。在动态注入值到 Spring bean 时,SpEL 是一种很便利和强大的方式。我们有时会忍不住编写很复杂的表达式。但需要注意的是,不要让你的表达式太智能。你的表达式越智能,对它的测试就越重要。SpEL 毕竟只是 String 类型的值,可能测试起来很困难。鉴于这一点,我建议尽可能让表达式保持简洁,这样测试不会是什么大问题。
小结
我们在本章介绍了许多背景知识,在第 2 章所介绍的基本 bean 装配基础之上,又学习了一些强大的高级装配技巧。
首先,我们学习了 Spring profile,它解决了 Spring bean 要跨各种部署环境的通用问题。在运行时,通过将环境相关的 bean 与当前激活的 profile 进行匹配,Spring 能够让相同的部署单元跨多种环境运行,而不需要进行重新构建。
Profile bean 是在运行时条件化创建 bean 的一种方式,但是 Spring 4 提供了一种更为通用的方式,通过这种方式能够声明某些 bean 的创建与否要依赖于给定条件的输出结果。结合使用 @Conditional 注解和 Spring Condition 接口的实现,能够为开发人员提供一种强大和灵活的机制,实现条件化地创建 bean。
我们还看了两种解决自动装配歧义性的方法:首选 bean 以及限定符。
尽管将某个 bean 设置为首选 bean 是很简单的,但这种方式也有其局限性,所以我们讨论了如何将一组可选的自动装配 bean,借助限定符将其范围缩小到只有一个符合条件的 bean。除此之外,我们还看到了如何创建自定义的限定符注解,这些限定符描述了 bean 的特性。
尽管大多数的 Spring bean 都是以单例的方式创建的,但有的时候其他的创建策略更为合适。Spring 能够让 bean 以单例、原型、请求作用域或会话作用域的方式来创建。在声明请求作用域或会话作用域的 bean 的时候,我们还学习了如何创建作用域代理,它分为基于类的代理和基于接口的代理的两种方式。
最后,我们学习了 Spring 表达式语言,它能够在运行时计算要注入到 bean 属性中的值。
对于 bean 装配,我们已经掌握了扎实的基础知识,现在我们要将注意力转向面向切面编程(aspect-oriented programming ,AOP)了。依赖注入能够将组件及其协作的其他组件解耦,与之类似,AOP 有助于将应用组件与跨多个组件的任务进行解耦。在下一章,我们将会深入学习在 Spring 中如何创建和使用切面。
面向切面的 Spring
本章内容:
- 面向切面编程的基本原理
- 通过 POJO 创建切面
- 使用 @AspectJ 注解
- 为 AspectJ 切面注入依赖
在编写本章时,得克萨斯州(我所居住的地方)正值盛夏,这几天正在经历创历史记录的高温天气。这里真的非常热,在这种天气下,空调当然是必不可少的。但是空调的缺点是它会耗电,而电需要钱。为了享受凉爽和舒适,我们没有什么办法可以避免这种开销。这是因为每家每户都有一个电表来记录用电量,每个月都会有人来查电表,这样电力公司就知道应该收取多少费用了。
现在想象一下,如果没有电表,也没有人来查看用电量,假设现在由户主来联系电力公司并报告自己的用电量。虽然可能会有一些特别执着的户主会详细记录使用电灯、电视和空调的情况,但大多数人肯定不会这么做。基于信用的电力收费对于消费者可能非常不错,但对于电力公司来说结果可能就不那么美妙了。
监控用电量是一个很重要的功能,但并不是大多数家庭重点关注的问题。所有家庭实际上所关注的可能是修剪草坪、用吸尘器清理地毯、打扫浴室等事项。从家庭的角度来看,监控房屋的用电量是一个被动事件(其实修剪草坪也是一个被动事件——特别是在炎热的天气下)。
软件系统中的一些功能就像我们家里的电表一样。这些功能需要用到应用程序的多个地方,但是我们又不想在每个点都明确调用它们。日志、安全和事务管理的确都很重要,但它们是否为应用对象主动参与的行为呢?如果让应用对象只关注于自己所针对的业务领域问题,而其他方面的问题由其他应用对象来处理,这会不会更好呢?
在软件开发中,**分布于应用中多出的功能被称为横切关注点 (cross-cutting concerns)**。通常,这些横切关注点在概念上是与业务逻辑相分离的 (但是往往嵌入到应用的业务逻辑中)。将这些横切关注点和业务逻辑相分离正是面向切面编程 (AOP) 索要解决的。
在第 2 章,我们介绍了如何使用依赖注入(DI)管理和配置我们的应用对象。DI 有助于应用对象之间的解耦,而AOP可以实现横切关注点与它们所影响的对象之间的解耦。
日志是应用切面的常见范例,但它并不是切面适用的唯一场景。通览本书,我们还会看到切面所适用的多个场景,包括声明式事务、安全和缓存。
本章展示了 Spring 对切面的支持,包括如何把普通类声明为一个切面和如何使用注解创建切面。除此之外,我们还会看到 AspectJ——另一种流行的 AOP 实现——如何补充 Spring AOP 框架的功能。但是,我们先不管事务、安全和缓存,先看一下 Spring 是如何实现切面的,就从 AOP 的基础知识开始吧。
什么是面向切面编程
如前所述,切面能帮助我们模块化横切关注点。简而言之,横切关注点可以被描述为影响应用多处的功能。例如,安全就是一个横切关注点,应用中的许多方法都会涉及到安全规则。图 4.1 直观呈现了横切关注点的概念。
图 4.1 展现了一个被划分为模块的典型应用。每个模块的核心功能都是为特定业务领域提供服务,但是这些模块都需要类似的辅助功能,例如安全和事务管理。
如果要重用通用功能的话,最常见的面向对象技术是继承(inheritance)或委托(delegation)。但是,如果在整个应用中都使用相同的基类,继承往往会导致一个脆弱的对象体系;而使用委托可能需要对委托对象进行复杂的调用。
切面提供了取代继承和委托的另一种选择,而且在很多场景下更清晰简洁。在使用面向切面编程时,我们仍然在一个地方定义通用功能,但是我们可以通过声明的方式定义这个功能以何种方式在何处应用,而无需修改受影响的类。横切关注点可以被模块化特殊的类,这些类被称为切面。这样做有两个好处:首先,每个关注点现在都集中在一处,而不是分散到多处代码中;其次,服务模块更简洁,因为它们只包含主要关注点 (或核心功能) 的代码,而次要关注点的代码被转移到切面中了。
定义 AOP 术语
与大多数技术一样,AOP 已经形成了自己的术语。描述切面的常用术语有通知(advice)、切点(pointcut)和连接点(join point)。图4.2展示了这些概念是如何关联在一起的。
可以把切面的功能(通知)织入到程序的执行过程中
遗憾的是,大多数用于描述 AOP 功能的术语并不直观,尽管如此,它们现在已经是 AOP 行话的组成部分了,为了理解 AOP,我们必须了解这些术语。在我们进入某个领域之前,必须学会在这个领域该如何说话。
通知 (advice)
当抄表员出现在我们家门口时,他们要登记用电量并回去向电力公司报告。显然,他们必须有一份需要抄表的住户清单,他们所汇报的信息也很重要,但记录用电量才是抄表员的主要工作。
类似地,切面也有目标——它必须要完成的工作。在 AOP 术语中,切面的工作被称为通知。
通知定义了切面是什么以及何时使用。除了描述切面要完成的工作,通知还解决了何时执行这个工作的问题。
Spring 切面可以应用 5 种类型的通知。
- Before,在方法调用之前调用通知
- After,在方法调用之后调用通知,无论方法执行是否成功
- After-returning,在方法成功执行之后调用通知
- After-throwing,在方法抛出异常后调用通知
- Around,通知包裹了被通知的方法,在被通知的方法调用之前和调用之后执自定义的行为
连接点 (join point)
电力公司为多个住户提供服务,甚至可能是整个城市。每家都有一个电表,这些电表上的数字都需要读取,因此每家都是抄表员的潜在目标。抄表员也许能够读取各种类型的设备,但是为了完成他的工作,他的目标应该房屋内所安装的电表。
同样,我们的应用可能需要面对数以千计的时机应用通知。这些时机被称为连接点。连接点是在应用执行过程中能够插入切面的一个点。这个点可以是调用方法时、抛出异常时、甚至修改一个字段时。切面代码可以利用这些点插入到应用的正常流程之中,并添加新的行为。
切点 (pointcut)
如果让一位抄表员访问电力公司所服务的所有住户,那肯定是不现实的。实际上,电力公司为每一个抄表员都分别指定某一块区域的住户。类似地,一个切面并不需要通知应用的所有连接点。切点有助于缩小切面所通知的连接点的范围。
如果通知定义了切面的 “什么” 和 “何时”,那么切面就定义了 ”何处“。切点的定义会匹配通知所要织入的一 个或多个连接点。我们通常使用明确的类和方法名称来指定这些切点,或是利用正则表达式定义匹配的类和方法名称模式来指定这些切点。有些 AOP 框架允许我们创建动态的切点,可以根据运行时的决策 (比如方法的参数值) 来决定是否应用通知。
切面 (aspect)
当抄表员开始一天的工作时,他知道自己要做的事情(报告用电量)和从哪些房屋收集信息。因此,他知道要完成工作所需要的一切东西。
切面时通知和切点的结合。通知和切点共同定义了关于切面的全部内容,它是什么,在何时和何处完成其功能。
引入 (introduction)
引入允许我们向现有的类添加新方法和属性。例如,我们可以创建一个 Auditable 通知类,该类记录了对象最后一次修改时的状态。这很简单,只需一种方法,setLastModified(Date),和一个实例变量来保存这个状态。然后,这个新方法和实例变量就可以被引入到现有的类中。从而可以在无需修改这些现有的类的情况下,让它们具有新的行为和状态。
织入 (weaving)
织入是将切面应用到目标对象来创建新的代理对象的过程。切面在指定的连接点被织入到目标对象中。在目标对象的生命周期里有多个点可以进行织入。
- 编译期:切面在目标类编译时被织入。这种方式需要特殊的编译器。AspectJ 的织入编译器就是以这种方式织入切面的。
- 类加载期:切面在目标类加载到 JVM 时被织入。这种方式需要特殊的类加载器(ClassLoader),它可以在目标类被引入应用之前增强该目标类的字节码。AspectJ 5 的加载时织入(load-time weaving,LTW)就支持以这种方式织入切面。
- 运行期:切面在应用运行的某个时刻被织入。一般情况下,在织入切面时,AOP 容器会为目标对象动态地创建一个代理对象。Spring AOP 就是以这种方式织入切面的。
要掌握的新术语可真不少啊。再看一下图 4.1,现在我们已经了解了如下的知识,通知包含了需要用于多个应用对象的横切行为;连接点是程序执行过程中能够应用通知的所有点;切点定义了通知被应用的具体位置(在哪些连接点)。其中关键的概念是切点定义了哪些连接点会得到通知。
我们已经了解了一些基础的 AOP 术语,现在让我们再看看这些 AOP 的核心概念是如何在 Spring 中实现的。
Spring 对 AOP 的支持
并不是所有的 AOP 框架都是相同的,它们在连接点模型上可能有强弱之分。有些允许在字段修饰符级别应用通知,而另一些只支持与方法调用相关的连接点。它们织入切面的方式和时机也有所不同。但是无论如何,创建切点来定义切面所织入的连接点是 AOP 框架的基本功能。
因为这是一本介绍 Spring 的图书,所以我们会关注 Spring AOP。虽然如此,Spring 和 AspectJ 项目之间有大量的协作,而且 Spring 对 AOP 的支持在很多方面借鉴了 AspectJ 项目。
Spring 提供了 4 种各具特色的 AOP 支持:
- 基于代理的经典 AOP
- 纯 POJO 切面
- @AsoectJ 注解驱动的切面
- 注入式 Aspect J 切面 (适合 Spring 各版本)
前三种都是 Spring AOP 实现的变体,Spring AOP 构建在动态代理基础之上,因此,Spring 对 AOP 的支持局限于方法拦截。术语“经典”通常意味着是很好的东西。老爷车、经典高尔夫球赛、可口可乐精品都是好东西。但是 Spring 的经典 AOP 编程模型并不怎么样。当然,曾经它的确非常棒。但是现在 Spring 提供了更简洁和干净的面向切面编程方式。引入了简单的声明式 AOP 和基于注解的 AOP 之后,Spring 经典的 AOP 看起来就显得非常笨重和过于复杂,直接使用
ProxyFactory Bean 会让人感觉厌烦。所以在本书中我不会再介绍经典的 Spring AOP。
借助 Spring 的 aop 命名空间,我们可以将纯 POJO 转换为切面。实际上,这些 POJO 只是提供了满足切点条件时所要调用的方法。遗憾的是,这种技术需要 XML配置,但这的确是声明式地将对象转换为切面的简便方式。
Spring 借鉴了 AspectJ 的切面,以提供注解驱动的 AOP。本质上,它依然是 Spring 基于代理的 AOP,但是编程模型几乎与编写成熟的 AspectJ 注解切面完全一致。这种 AOP 风格的好处在于能够不使用 XML 来完成功能。
如果你的 AOP 需求超过了简单的方法调用(如构造器或属性拦截),那么你需要考虑使用 AspectJ 来实现切面。在这种情况下,上文所示的第四种类型能够帮助你将值注入到 AspectJ 驱动的切面中。
我们在将在本章展示更多的 Spring AOP 技术,但是在开始之前,我们必须要了解 Spring AOP 框架的一些关键知识。
Spring 通知是 Java 编写的
Spring 所创建的通知都是使用标准 Java 类编写的。这样的话,我们就可以使用与普通 Java 开发一样的集成开发环境(IDE)来开发切面。而且,定义通知所应用的切点通常会使用注解或在 Spring 配置文件里采用 XML 来编写,这两种语法对于 Java 开发者来说都是相当熟悉的。
AspectJ 与之相反。虽然 AspectJ 现在支持基于注解的切面,但 AspectJ 最初是以 Java 语言扩展的方式实现的。这种方式有优点也有缺点。通过特有的 AOP 语言,我们可以获得更强大和细粒度的控制,以及更丰富的 AOP 工具集,但是我们需要额外学习新的工具和语法。
Spring 在运行期通知对象
通过在代理类中包裹切面,Spring 在运行期把切面织入到 Spring 管理的 bean中。如图 4.3 所示,代理类封装了目标类,并拦截被通知方法的调用,再把调用转发给真正的目标 bean。当代理拦截到方法调用时,在调用目标 bean 方法之前,会执行切面逻辑。
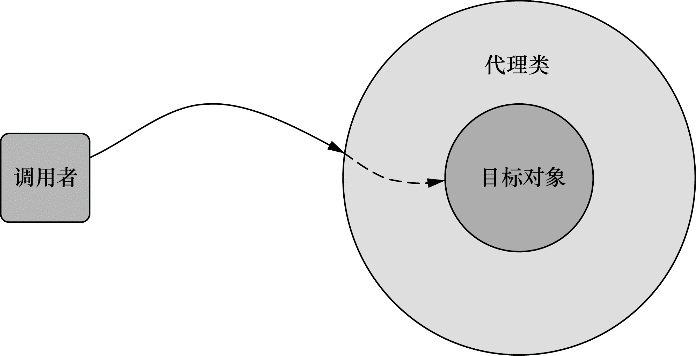
代理类处理方法的调用,执行额外的切面逻辑,并调用目标方法
直到应用需要被代理的 Bean 时,Spring 才创建代理对象。如果使用的是 ApplicationContext,在 ApplicationContext 从 BeanFactory 中加载所有的 Bean 时,Spring 创建被代理的对象。因为 Spring 运行时才创建代理对象,所以我们不需要特殊的编译器来织入 Spring AOP 的切面。
Spring 只支持方法级别的连接点
正如前面所探讨过的,通过使用各种 AOP 方案可以支持多种连接点模型。因为 Spring 基于动态代理,所以 Spring 只支持方法连接点。这与一些其他的 AOP 框架是不同的,例如 AspectJ 和 JBoss,除了方法切点,它们还提供了字段和构造器接入点。Spring 缺少对字段连接点的支持,无法让我们创建细粒度的通知,例如拦截对象字段的修改。而且它不支持构造器连接点,我们就无法在 bean 创建时应用通知。
但是方法拦截可以满足绝大部分的需求。如果需要方法拦截之外的连接点拦截功能,那么我们可以利用 Aspect 来补充 Spring AOP 的功能。
对于什么是AOP以及Spring如何支持AOP的,我们现在已经有了一个大致的了解。现在是时候学习如何在 Spring 中创建切面了,让我们先从 Spring 的声明式 AOP 模型开始。
使用切点选择连接点
正如之前所提过的,切点用于准确定位应该在什么地方应用切面的通知。通知和切点是切面的最基本元素。因此,了解如何编写切点非常重要。
在 Spring AOP 中,要使用 AspectJ 的切点表达式语言来定义切点。如果你已经很熟悉 AspectJ,那么在 Spring 中定义切点就感觉非常自然。但是如果你一点都不了解 AspectJ 的话,本小节我们将快速介绍一下如何编写 AspectJ 风格的切点。如果你想进一步了解 AspectJ 和 AspectJ 切点表达式语言,我强烈推荐 Ramniva Laddad 编写的《AspectJ in Action》第二版(Manning,2009,www.manning.com/laddad2/)。
关于 Spring AOP 的 AspectJ 切点,最重要的一点就是 Spring 仅支持 AspectJ 切点指示器(pointcut designator)的一个子集。让我们回顾下,Spring 是基于代理的,而某些切点表达式是与基于代理的 AOP 无关的。表 4.1 列出了 Spring AOP 所支持的 AspectJ 切点指示器。
| AspectJ 指示器 | 描 述 |
|---|---|
| arg() | 限制连接点匹配参数为指定类型的执行方法 |
| @args() | 限制连接点匹配参数由指定注解标注的执行方法 |
| execution() | 用于匹配是连接点的执行方法 |
| this() | 限制连接点匹配 AOP 代理的 bean 引用为指定类型的类 |
| target | 限制连接点匹配目标对象为指定类型的类 |
| @target() | 限制连接点匹配特定的执行对象,这些对象对应的类要具有指定类型的注解 |
| within() | 限制连接点匹配指定的类型 |
| @within() | 限制连接点匹配指定注解所标注的类型(当使用 Spring AOP 时,方法定义在由指定的注解所标注的类里) |
| @annotation | 限定匹配带有指定注解的连接点 |
在 Spring 中尝试使用 AspectJ 其他指示器时,将会抛出 IllegalArgument-Exception 异常。
当我们查看如上所展示的这些 Spring 支持的指示器时,注意只有 execution 指示器是实际执行匹配的,而其他的指示器都是用来限制匹配的。这说明 execution 指示器是我们在编写切点定义时最主要使用的指示器。在此基础上,我们使用其他指示器来限制所匹配的切点。
编写切点
为了阐述 Spring 中的切面,我们需要有个主题来定义切面的切点。为此,我们定义一个 Performance 接口:
1 | package concert;public interface Performance { public void perform();} |
Performance 可以代表任何类型的现场表演,如舞台剧、电影或音乐会。假设我们想编写 Performance 的 perform() 方法触发的通知。图 4.4 展现了一个切点表达式,这个表达式能够设置当 perform() 方法执行时触发通知的调用。

我们使用 execution() 指示器选择 Performance 的 perform() 方法。方法表达式以 “*” 号开始,表明了我们不关心方法返回值的类型。然后,我们指定了全限定类名和方法名。对于方法参数列表,我们使用两个点号(..)表明切点要选择任意的 perform() 方法,无论该方法的入参是什么。
现在假设我们需要配置的切点仅匹配 concert 包。在此场景下,可以使用 within() 指示器来限制匹配。

请注意我们使用了 “&&” 操作符把 execution() 和 within() 指示器连接在一起形成与(and)关系(切点必须匹配所有的指示器)。类似地,我们可以使用 “||” 操作符来标识或(or)关系,而使用 “!” 操作符来标识非(not)操作。
因为 “&” 在 XML 中有特殊含义,所以在 Spring 的 XML 配置里面描述切点时,我们可以使用and 来代替 “&&”。同样,or 和 not 可以分别用来代替 “||” 和 “!”。
在切点中选择bean
除了表 4.1 所列的指示器外,Spring 还引入了一个新的 bean() 指示器,它允许我们在切点表达式中使用 bean 的 ID 来标识 bean。bean() 使用 bean ID 或 bean 名称作为参数来限制切点只匹配特定的 bean。
例如,考虑如下的切点:
1 | execitopn(* concert.Performance.perform()) and bean('woodstack') |
在这里,我们希望在执行 Performance 的 perform() 方法时应用通知,但限定 bean 的 ID 为 woodstock。
在某些场景下,限定切点为指定的 bean 或许很有意义,但我们还可以使用非操作为除了特定 ID 以外的其他 bean 应用通知:
1 | execitopn(* concert.Performance.perform()) and bean('woodstack') |
在此场景下,切面的通知会被编织到所有 ID 不为 woodstock 的 bean 中。
现在,我们已经讲解了编写切点的基础知识,让我们再了解一下如何编写通知和使用这些切点声明切面。
使用注解创建切面
使用注解来创建切面是 AspectJ 5 所引入的关键特性。AspectJ 5之前,编写 AspectJ 切面需要学习一种 Java 语言的扩展,但是 AspectJ 面向注解的模型可以非常简便地通过少量注解把任意类转变为切面。
我们已经定义了 Performance 接口,它是切面中切点的目标对象。现在,让我们使用 AspecJ 注解来定义切面。
定义切面
如果一场演出没有观众的话,那不能称之为演出。对不对?从演出的角度来看,观众是非常重要的,但是对演出本身的功能来讲,它并不是核心,这是一个单独的关注点。因此,将观众定义为一个切面,并将其应用到演出上就是较为明智的做法。
程序清单 4.1 展现了 Audience 类,它定义了我们所需的一个切面。
1 | package concert;import org.aspectj.lang.annotation.AfterReturning;import org.aspectj.lang.annotation.AfterThrowing;import org.aspectj.lang.annotation.Aspect;import org.aspectj.lang.annotation.Before; class Audience { //表演之前 public void silienceCellPhones() { System.out.println("siliencing cellphones"); } @Before("execution(** concert.Performance.perform(..))") //表演之前 public void takekSeats() { System.out.println("the audience is taking their seats"); } @AfterReturning"execution(** concert.Performance.perform(..))") //表演之后 public void applaud() { System.out.println("clap clap clap clap clap"); } @AfterThrowing("execution(** concert.Performance.perform(..))") //表演失败之后 public void demandRefund() { System.out.println("Boo! we want our money back!"); }} |
Audience 类使用 @AspectJ 注解进行了标注。该注解表明 Audience 不仅仅是一个 POJO,还是一个切面。Audience 类中的方法都使用注解来定义切面的具体行为。
Audience 有四个方法,定义了一个观众在观看演出时可能会做的事情。在演出之前,观众要就坐(takeSeats())并将手机调至静音状态(silenceCellPhones())。如果演出很精彩的话,观众应该会鼓掌喝彩(applause())。不过,如果演出没有达到观众预期的话,观众会要求退款(demandRefund())。
可以看到,这些方法都使用了通知注解来表明它们应该在什么时候调用。AspectJ 提供了五个注解来定义通知,如表 4.2 所示。
| 注 解 | 通 知 |
|---|---|
| @After | 通知方法会在目标方法返回或抛出异常后调用 |
| @AfterReturning | 通知方法会在目标方法返回后调用 |
| @AfterThrowing | 通知方法会在目标方法抛出异常后调用 |
| @Around | 通知方法会将目标方法封装起来 |
| @Before | 通知方法会在目标方法调用之前执行 |
Audience 使用到了前面 5 个注解中的 3 个。takeSeats() 和 silenceCellPhones() 方法都用到了 @Before 注解,表明它们应该在演出开始之前调用。applause() 方法使用了 @AfterReturning 注解,它会在演出成功返回后调用。demandRefund() 方法上添加了 @AfterThrowing 注解,这表明它会在抛出异常以后执行。
你可能已经注意到了,所有的这些注解都给定了一个切点表达式作为它的值,同时,这四个方法的切点表达式都是相同的。其实,它们可以设置成不同的切点表达式,但是在这里,这个切点表达式就能满足所有通知方法的需求。让我们近距离看一下这个设置给通知注解的切点表达式,我们发现它会在 Performance 的perform() 方法执行时触发。
相同的切点表达式我们重复了四遍,这可真不是什么光彩的事情。这样的重复让人感觉有些不对劲。如果我们只定义这个切点一次,然后每次需要的时候引用它,那么这会是一个很好的方案。
幸好,我们完全可以这样做:@Pointcut 注解能够在一个 @AspectJ 切面内定义可重用的切点。接下来的程序清单 4.2 展现了新的 Audience,现在它使用了@Pointcut。
1 | package concert;import org.aspectj.lang.annotation.AfterReturning;import org.aspectj.lang.annotation.AfterThrowing;import org.aspectj.lang.annotation.Aspect;import org.aspectj.lang.annotation.Before; class Audience { //定义命名的切点 public void performance() {} @Before("performance()") //表演之前 public void silienceCellPhones() { System.out.println("siliencing cellphones"); } @Before("performance()") //表演之前 public void takekSeats() { System.out.println("the audience is taking their seats"); } @AfterReturning"performance()") //表演之后 public void applaud() { System.out.println("clap clap clap clap clap"); } @AfterThrowing("performance()") //表演失败之后 public void demandRefund() { System.out.println("Boo! we want our money back!"); }} |
在 Audience 中,performance() 方法使用了 @Pointcut 注解。为 @Pointcut 注解设置的值是一个切点表达式,就像之前在通知注解上所设置的那样。通过在 performance() 方法上添加 @Pointcut 注解,我们实际上扩展了切点表达式语言,这样就可以在任何的切点表达式中使用 performance() 了,如果不这样做的话,你需要在这些地方使用那个更长的切点表达式。我们现在把所有通知注解中的长表达式都替换成了 performance()。
performance() 方法的实际内容并不重要,在这里它实际上应该是空的。其实该方法本身只是一个标识,供 @Pointcut 注解依附。
需要注意的是,除了注解和没有实际操作的 performance() 方法,Audience 类依然是一个 POJO。我们能够像使用其他的 Java 类那样调用它的方法,它的方法也能够独立地进行单元测试,这与其他的 Java 类并没有什么区别。Audience 只是一个 Java 类,只不过它通过注解表明会作为切面使用而已。像其他的 Java 类一样,它可以装配为 Spring 中的 bean:
1 | Audience audience() { return new Audience();} |
如果你就此止步的话,Audience 只会是 Spring 容器中的一个 bean。即便使用了 AspectJ 注解,但它并不会被视为切面,这些注解不会解析,也不会创建将其转换为切面的代理。
如果你使用 JavaConfig 的话,可以在配置类的类级别上通过使用 EnableAspectJAutoProxy 注解启用自动代理功能。程序清单 4.3 展现了如何在 JavaConfig 中启用自动代理。
1 | package concert;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.ComponentScan;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.EnableAspectJAutoProxy; // 启用 AspectJ 自动代理@ComponentScanpublic class ConcertConfig { @Bean public Audience audience() { return new Audience(); }} |
假如你在 Spring 中要使用 XML 来装配 bean 的话,那么需要使用 Spring aop 命名空间中的 <aop:aspectj-autoproxy> 元素。下面的 XML 配置展现了如何完成该功能。
1 | <!-- 启用 AspectJ 自动代理 --><aop:aspectj-autoproxy/><!-- 声明 Audience bean --><bean class="concert.Audience"/> |
不管你是使用 JavaConfig 还是 XML,AspectJ 自动代理都会为使用 @Aspect 注解的 bean 创建一个代理,这个代理会围绕着所有该切面的切点所匹配的 bean。在这种情况下,将会为 Concert bean 创建一个代理,Audience 类中的通知方法将会在 perform() 调用前后执行。
我们需要记住的是,Spring 的 AspectJ 自动代理仅仅使用 @AspectJ 作为创建切面的指导,切面依然是基于代理的。在本质上,它依然是 Spring 基于代理的切面。这一点非常重要,因为这意味着尽管使用的是 @AspectJ 注解,但我们仍然限于代理方法的调用。如果想利用 AspectJ 的所有能力,我们必须在运行时使用 AspectJ 并且不依赖 Spring 来创建基于代理的切面。
到现在为止,我们的切面在定义时,使用了不同的通知方法来实现前置通知和后置通知。但是表 4.2 还提到了另外的一种通知:环绕通知(around advice)。环绕通知与其他类型的通知有所不同,因此值得花点时间来介绍如何进行编写。
创建环绕通知
环绕通知是最为强大的通知类型。它能够让你所编写的逻辑将被通知的目标方法完全包装起来。实际上就像在一个通知方法中同时编写前置通知和后置通知。
为了阐述环绕通知,我们重写 Audience 切面。这次,我们使用一个环绕通知来代替之前多个不同的前置通知和后置通知。
1 | package concert;import org.aspectj.lang.proceeingJoinPoint;import org.aspectj.lang.annotation.Around;import org.aspectj.lang.annotation.Aspect;import org.aspectj.lang.annotation/Pointcut; class Audience { // 定义命名的站点 public void performance(){} @Around("performance()") // 环绕通知方法 public void watchPerformance(ProceedingJointPoint jp) { try { System.out.println("Silencing cell phones"); System.out.println("Taking seats"); jp.proceed(); System.out.println("CLAP CLAP CLAP") } catch (Throwable e) { System.out.println("Deamanding a refund"); } }} |
在这里,@Around 注解表明 watchPerformance() 方法会作为 performance() 切点的环绕通知。在这个通知中,观众在演出之前会将手机调至静音并就坐,演出结束后会鼓掌喝彩。像前面一样,如果演出失败的话,观众会要求退款。
可以看到,这个通知所达到的效果与之前的前置通知和后置通知是一样的。但是,现在它们位于同一个方法中,不像之前那样分散在四个不同的通知方法里面。
关于这个新的通知方法,你首先注意到的可能是它接受 ProceedingJoinPoint 作为参数。这个对象是必须要有的,因为你要在通知中通过它来调用被通知的方法。通知方法中可以做任何的事情,当要将控制权交给被通知的方法时,它需要调用 ProceedingJoinPoint 的 proceed()方法。
需要注意的是,别忘记调用 proceed() 方法。如果不调这个方法的话,那么你的通知实际上会阻塞对被通知方法的调用。有可能这就是你想要的效果,但更多的情况是你希望在某个点上执行被通知的方法。
有意思的是,你可以不调用 proceed() 方法,从而阻塞对被通知方法的访问,与之类似,你也可以在通知中对它进行多次调用。要这样做的一个场景就是实现重试逻辑,也就是在被通知方法失败后,进行重复尝试。
处理通知中的参数
到目前为止,我们的切面都很简单,没有任何参数。唯一的例外是我们为环绕通知所编写的 watchPerformance() 示例方法中使用了 ProceedingJoinPoint 作为参数。除了环绕通知,我们编写的其他通知不需要关注传递给被通知方法的任意参数。这很正常,因为我们所通知的 perform() 方法本身没有任何参数。
但是,如果切面所通知的方法确实有参数该怎么办呢?切面能访问和使用传递给被通知方法的参数吗?为了阐述这个问题,让我们重新看一下 2.4.4 小节中的 BlankDisc 样例。play() 方法会循环所有的磁道并调用 playTrack() 方法。但是,我们也可以通过 playTrack() 方法直接播放某一个磁道中的歌曲。
假设你想记录每个磁道被播放的次数。一种方法就是修改 playTrack() 方法,直接在每次调用的时候记录这个数量。但是,记录磁道的播放次数与播放本身是不同的关注点,因此不应该属于 playTrack() 方法。看起来,这应该是切面要完成的任务。为了记录每个磁道所播放的次数,我们创建了 TrackCounter 类,它是通知 playTrack() 方法的一个切面。
1 | package systemsound;import java.util.HashM ap;import java.util.Map;import org.aspectj.lang.annotation.Before;import org.aspectj.lang.annotation.Aspect;import org.aspectj.lang.annotation/Pointcut; class TrackCount { private Map<Integer, Integer> trackCount = new HashMap<>(); public void trackPlayed(int trackNumber) {} public void countTrack(int tackNumber) { int currentCount = getPlayCount(trackNumber); trackCounts.put(trackNumber, currentCount + 1); } public int getPlayCount(int trackNumber) { return trackCounts.containsKey(trackNumber)? trackCounts.get(trackNumber) : 0; }} |
像之前所创建的切面一样,这个切面使用 @Pointcut 注解定义命名的切点,并使用 @Before 将一个方法声明为前置通知。但是,这里的不同点在于切点还声明了要提供给通知方法的参数。图 4.6 将切点表达式进行了分解,以展现参数是在什么地方指定的。

需要关注的是切点表达式中的 args(trackNumber) 限定符。它表明传递给 playTrack() 方法的int类型参数也会传递到通知中去。参数的名称 trackNumber 也与切点方法签名中的参数相匹配。
这个参数会传递到通知方法中,这个通知方法是通过 @Before 注解和命名切点 trackPlayed(trackNumber) 定义的。切点定义中的参数与切点方法中的参数名称是一样的,这样就完成了从命名切点到通知方法的参数转移。
现在,我们可以在 Spring 配置中将 BlankDisc 和 TrackCounter 定义为 bean,并启用 AspectJ 自动代理,如程序清单 4.7 所示。
1 | package concert;import java.util.ArrayList;import java.util.List;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.ComponentScan;import org.springframework.context.annotation.EnableAspectJAutoProxy; class ConcertConfig { public Compactisc sgtPepers() { BlankDisc cd = new BlankDisc(); cd.setTitle("Sgt. Pepper's Lonely Hearts Club Band"); cd setArtist("The Beatles"); List<String> tracks = new ArrayList<>(); tracks.add("Sgt. Pepper's Lonely Hearts Club Band"); track.add("With a Little help from My Friends"); track.add("Lucy in the Sky with Diamonds"); track.add("Getting Better"); track.add("Fixing a Hole"); // ...itger tracjs inutted fir brevity... cd.setTracks(tracks); return cd; } @Bean public TrackCounter trackCounter() { return new TrackCounter(); }} |
最后,为了证明它能正常工作,你可以编写如下的简单测试。它会播放几个磁道并通过 TrackCounter 断言播放的数量。
1 | import static org.junit.Assert.*;import org.junit.Assert;import org.junit.Rule;import org.junit.Test;import org.junit.contrib.java.lang.system.StandardOutputStreamLog;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.test.context.ContextConfiguration;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;public class TrackCounterTest { public final StandardOutputStreamLog log = new StandardOutputStreamLog(); private CompactDisc cd; public void testTrackCounter() { cd.playTrack(1); cd.playTrack(2); cd.playTrack(3); assertEqual(1, counter.getPlayhCount(1)); assertEqual(1, counter.getPlayhCount(2)); assertEqual(1, counter.getPlayhCount(3)); }} |
到目前为止,在我们所使用的切面中,所包装的都是被通知对象的已有方法。但是,方法包装仅仅是切面所能实现的功能之一。让我们看一下如何通过编写切面,为被通知的对象引入全新的功能。
通过注解引入新功能
一些编程语言,例如 Ruby 和 Groovy,有开放类的理念。它们可以不用直接修改对象或类的定义就能够为对象或类增加新的方法。不过,Java 并不是动态语言。一旦类编译完成了,我们就很难再为该类添加新的功能了。
但是如果仔细想想,我们在本章中不是一直在使用切面这样做吗?当然,我们还没有为对象增加任何新的方法,但是已经为对象拥有的方法添加了新功能。如果切面能够为现有的方法增加额外的功能,为什么不能为一个对象增加新的方法呢?
实际上,利用被称为引入的 AOP 概念,切面可以为 Spring bean 添加新方法。
回顾一下,在 Spring 中,切面只是实现了它们所包装 bean 相同接口的代理。如果除了实现这些接口,代理也能暴露新接口的话,会怎么样呢?那样的话,切面所通知的 bean 看起来像是实现了新的接口,即便底层实现类并没有实现这些接口也无所谓。
我们需要注意的是,当引入接口的方法被调用时,代理会把此调用委托给实现了新接口的某个其他对象。实际上,一个 bean 的实现被拆分到了多个类中。
为了验证该主意能行得通,我们为示例中的所有的 Performance 实现引入下面的 Encoreable 接口:
1 | package concert;public interface Encorable { void performEncore();} |
暂且先不管 Encoreable 是不是一个真正存在的单词,我们需要有一种方式将这个接口应用到 Performance 实现中。我们现在假设你能够访问 Performance 的所有实现,并对其进行修改,让它们都实现 Encoreable 接口。但是,从设计的角度来看,这并不是最好的做法,并不是所有的 Performance 都是具有 Encoreable 特性的。另外一方面,有可能无法修改所有的 Performance 实现,当使用第三方实现并且没有源码的时候更是如此。
值得庆幸的是,借助于 AOP 的引入功能,我们可以不必在设计上妥协或者侵入性地改变现有的实现。为了实现该功能,我们要创建一个新的切面:
1 | package concert;import org.aspectj.lang.annotation.Aspect;import org.aspectj.lang.annotation.DeclareParents; class EncoreableIntroducer { public static Encoreable encoreable;} |
可以看到,EncoreableIntroducer 是一个切面。但是,它与我们之前所创建的切面不同,它并没有提供前置、后置或环绕通知,而是通过@DeclareParents注解,将Encoreable接口引入到Performance bean中。
@DeclareParents 注解由三部分组成:
- value 属性指定了哪种类型的 bean 要引入该接口。在本例中,也就是所有实现 Performance 的类型。(标记符后面的加号表示是 Performance 的所有子类型,而不是 Performance 本身。)
- defaultImpl 属性指定了为引入功能提供实现的类。在这里,我们指定的是 DefaultEncoreable 提供实现。
- @DeclareParents 注解所标注的静态属性指明了要引入了接口。在这里,我们所引入的是 Encoreable 接口。
和其他的切面一样,我们需要在 Spring 应用中将 EncoreableIntroducer 声明为一个 bean:
1 | <bean class="concert.EncoreableIntroducer"/> |
Spring 的自动代理机制将会获取到它的声明,当 Spring 发现一个 bean 使用了 @Aspect 注解时,Spring 就会创建一个代理,然后将调用委托给被代理的 bean 或被引入的实现,这取决于调用的方法属于被代理的 bean 还是属于被引入的接口。
在 Spring 中,注解和自动代理提供了一种很便利的方式来创建切面。它非常简单,并且只涉及到最少的 Spring 配置。但是,面向注解的切面声明有一个明显的劣势:你必须能够为通知类添加注解。为了做到这一点,必须要有源码。
如果你没有源码的话,或者不想将 AspectJ 注解放到你的代码之中,Spring 为切面提供了另外一种可选方案。让我们看一下如何在 Spring XML 配置文件中声明切面。
在 XML 中声明切面
在本书前面的内容中,我曾经建立过这样一种原则,那就是基于注解的配置要优于基于 Java 的配置,基于 Java 的配置要优于基于 XML 的配置。但是,如果你需要声明切面,但是又不能为通知类添加注解的时候,那么就必须转向 XML 配置了。
在 Spring 的 AOP 配置命名空间中,提供了多个元素用来在XML中声明切面,如表4.3所示。
| AOP 配置元素 | 描述 |
|---|---|
<aop:advisor> |
定义 AOP 通知器 |
<aop:after> |
定义 AOP 后置通知(不管被通知的方法是否执行成功) |
<aop:afterreturning> |
定义 AOP 返回通知 |
<aop:afterthrowing> |
定义 AOP 异常通知 |
<aop:around> |
定义 AOP 环绕通知 |
<aop:aspect> |
定义一个切面 |
<aop:aspectjautoproxy> |
启用 @AspectJ 注解驱动的切面 |
<aop:before> |
定义一个 AOP 前置通知 |
<aop:config> |
顶层的 AOP 配置元素。大多数的 <aop:*> 元素必须包含在 <aop:config> 元素内 |
<aop:declareparents> |
以透明的方式为被通知的对象引入额外的接口 |
<aop:pointcut> |
定义一个切点 |
我们已经看过了 <aop:aspectj-autoproxy> 元素,它能够自动代理 AspectJ 注解的通知类。aop 命名空间的其他元素能够让我们直接在 Spring 配置中声明切面,而不需要使用注解。
例如,我们重新看一下 Audience 类,这一次我们将它所有的 AspectJ 注解全部移除掉:
1 | public class Audience { public void silienceCellPhones() { System.out.println("siliencing cellphones"); } public void takekSeats() { System.out.println("the audience is taking their seats"); } public void applaud() { System.out.println("clap clap clap clap clap"); } public void demandRefund() { System.out.println("Boo! we want our money back!"); }} |
正如你所看到的,Audience 类并没有任何特别之处,它就是有几个方法的简单 Java 类。我们可以像其他类一样把它注册为 Spring 应用上下文中的 bean。
尽管看起来并没有什么差别,但 Audience 已经具备了成为 AOP 通知的所有条件。我们再稍微帮助它一把,它就能够成为预期的通知了。
声明前置和后置通知
你可以再把那些 AspectJ 注解加回来,但这并不是本节的目的。相反,我们会使用 Spring aop 命名空间中的一些元素,将没有注解的 Audience 类转换为切面。下面的程序清单 4.9 展示了所需要的 XML。
1 | <aop:config> <aop:aspect ref="audience"> <aop:before method="taskSeats" pointcut="execution(** concert.Perforance.perform(..))"/> <aop:before method="silenceCellPhones" pointcut="execution(** concert.Perforance.perform(..))"/> <aop:after-returning method="applaud" pointcut="execution(** concert.Perforance.perform(..))"/> <aop:after-throwing method="demandRefund" pointcut="execution(** concert.Perforance.perform(..))"/> </aop:aspect></aop:config> |
关于 Spring AOP 配置元素,第一个需要注意的事项是大多数的 AOP 配置元素必须在 <aop:config> 元素的上下文内使用。这条规则有几种例外场景,但是把 bean 声明为一个切面时,我们总是从 <aop:config> 元素开始配置的。
在 <aop:config> 元素内,我们可以声明一个或多个通知器、切面或者切点。在程序清单 4.9 中,我们使用 <aop:aspect> 元素声明了一个简单的切面。ref 元素引用了一个 POJO bean,该 bean 实现了切面的功能——在这里就是 audience。ref 元素所引用的 bean 提供了在切面中通知所调用的方法。
该切面应用了四个不同的通知。两个 <aop:before> 元素定义了匹配切点的方法执行之前调用前置通知方法——也就是 Audience bean 的 takeSeats() 和 turnOffCellPhones() 方法(由 method 属性所声明)。<aop:after-returning> 元素定义了一个返回(after-returning)通知,在切点所匹配的方法调用之后再调用 applaud() 方法。同样,<aop:after-throwing>元素定义了异常(after-throwing)通知,如果所匹配的方法执行时抛出任何的异常,都将会调用 demandRefund() 方法。图 4.8 展示了通知逻辑如何织入到业务逻辑中。

在所有的通知元素中,pointcut 属性定义了通知所应用的切点,它的值是使用 AspectJ 切点表达式语法所定义的切点。
你或许注意到所有通知元素中的 pointcut 属性的值都是一样的,这是因为所有的通知都要应用到相同的切点上。
在基于 AspectJ 注解的通知中,当发现这种类型的重复时,我们使用 @Pointcut 注解消除了这些重复的内容。而在基于 XML 的切面声明中,我们需要使用 <aop:pointcut> 元素。如下的 XML 展现了如何将通用的切点表达式抽取到一个切点声明中,这样这个声明就能在所有的通知元素中使用了。
1 | <aop:config> <aop:aspect ref="audience"> <aop:pointcut id="performance" expression="execution(** concert.Perforance.perform(..))"/> <aop:before method="taskSeats" pointcut-ref="performance"/> <aop:before method="silenceCellPhones" pointcut-ref="performance"/> <aop:after-returning method="applaud" pointcut-ref="performance"/> <aop:after-throwing method="demandRefund" pointcut-ref="performance"/> </aop:aspect></aop:config> |
现在切点是在一个地方定义的,并且被多个通知元素所引用。<aop:pointcut> 元素定义了一个 id 为 performance 的切点。同时修改所有的通知元素,用 pointcut-ref 属性来引用这个命名切点。
正如程序清单 4.10 所展示的,<aop:pointcut> 元素所定义的切点可以被同一个 <aop:aspect> 元素之内的所有通知元素引用。如果想让定义的切点能够在多个切面使用,我们可以把 <aop:pointcut> 元素放在 <aop:config> 元素的范围内。
声明环绕通知
目前 Audience 的实现工作得非常棒,但是前置通知和后置通知有一些限制。具体来说,如果不使用成员变量存储信息的话,在前置通知和后置通知之间共享信息非常麻烦。
例如,假设除了进场关闭手机和表演结束后鼓掌,我们还希望观众确保一直关注演出,并报告每个参赛者表演了多长时间。使用前置通知和后置通知实现该功能的唯一方式是在前置通知中记录开始时间并在某个后置通知中报告表演耗费的时间。但这样的话我们必须在一个成员变量中保存开始时间。因为 Audience 是单例的,如果像这样保存状态的话,将会存在线程安全问题。
相对于前置通知和后置通知,环绕通知在这点上有明显的优势。使用环绕通知,我们可以完成前置通知和后置通知所实现的相同功能,而且只需要在一个方法中实现。因为整个通知逻辑是在一个方法内实现的,所以不需要使用成员变量保存状态。
例如,考虑程序清单 4.11 中新 Audience 类的 watchPerformance() 方法,它没有使用任何的注解。
1 | package concert;import org.aspectj.lang.ProceedingJoinPoint;public class Audience { public void wathcPerformance(ProceedingJoinPoint jp) { try { System.out.println("Silencing cell phone"); System.out.println("Taking seats"); jp.proceed(); System.out.println("Clap Clap Clap"); } catch(Throwable e) { System.out.println("Demanding a refund"); } }} |
在观众切面中,watchPerformance() 方法包含了之前四个通知方法的所有功能。不过,所有的功能都放在了这一个方法中,因此这个方法还要负责自身的异常处理。
声明环绕通知与声明其他类型的通知并没有太大区别。我们所需要做的仅仅是使用 <aop:around> 元素。
1 | <aop:config> <aop:aspect ref="audience"> <aop:pointcut id="performance" expression="execution(** concert.Perforance.perform(..))"/> <aop:around method="watchPerformance" pointcut="performance"/> </aop:aspect></aop:config> |
像其他通知的 XML 元素一样,<aop:around> 指定了一个切点和一个通知方法的名字。在这里,我们使用跟之前一样的切点,但是为该切点所设置的 method 属性值为 watchPerformance() 方法。
为通知传递参数
在 4.3.3 小节中,我们使用 @AspectJ 注解创建了一个切面,这个切面能够记录 CompactDisc 上每个磁道播放的次数。现在,我们使用 XML 来配置切面,那就看一下如何完成这一相同的任务。
首先,我们要移除掉 TrackCounter 上所有的 @AspectJ 注解。
1 | package systemsound;import java.util.HashMap;import java.util.Map;public class TrackCount { private Map<Integer, Integer> trackCount = new HashMap<>(); public void trackPlayed(int trackNumber) {} public void countTrack(int tackNumber) { int currentCount = getPlayCount(trackNumber); trackCounts.put(trackNumber, currentCount + 1); } public int getPlayCount(int trackNumber) { return trackCounts.containsKey(trackNumber)? trackCounts.get(trackNumber) : 0; }} |
去掉 @AspectJ 注解后,TrackCounter 显得有些单薄了。现在,除非显式调用 countTrack() 方法,否则 TrackCounter 不会记录磁道播放的数量。但是,借助一点 Spring XML 配置,我们能够让 TrackCounter 重新变为切面。
如下的程序清单展现了完整的 Spring 配置,在这个配置中声明了 TrackCounter bean 和 BlankDisc bean,并将 TrackCounter 转化为切面。
1 | <bean id="trackCounter" class="soundsystem.TrackCounter"/><bean id="cd" class="soundsystem.BlankDisc"> <property name="title" value="Sgt. Pepper's Lonely Hearts Club Band"/> <property name="artist" value="The Beatles"/> <property name="tracks"> <list> <value>Sgt. Pepper's Lonely Hearts Club Band</value> <value>With a Little Help from My Friends</value> <value>Lucy in the Sky with Diamonds</value> <!-- other tracks omitted for brevity...--> </list> </property></bean><aop:config> <aop:aspect ref="trackCounter"> <aop:pointcut id="trackPlayed" expression="execution(* soundsystem.Compactisc.playTrack(int)) and args(trackNumber)"/> <aop:before pointcut-ref="trackPlayed" method="countTrack"/> </aop:aspect></aop:config> |
可以看到,我们使用了和前面相同的 aop 命名空间 XML 元素,它们会将 POJO 声明为切面。唯一明显的差别在于切点表达式中包含了一个参数,这个参数会传递到通知方法中。如果你将这个表达式与程序清单 4.6 中的表达式进行对比会发现它们几乎是相同的。唯一的差别在于这里使用 and 关键字而不是 “&&”(因为在 XML 中,“&” 符号会被解析为实体的开始)。
我们通过练习已经使用 Spring 的 aop 命名空间声明了几个基本的切面,那么现在让我们看一下如何使用 aop 命名空间声明引入切面。
通过切面引入新功能
在前面的 4.3.4 小节中,我向你展现了如何借助 AspectJ 的 @DeclareParents 注解为被通知的方法神奇地引入新的方法。但是
AOP 引入并不是 AspectJ 特有的。使用 Spring aop 命名空间中的 <aop:declare-parents> 元素,我们可以实现相同的功能。
如下的 XML 代码片段与之前基于 AspectJ 的引入功能是相同:
1 | <aop:aspect> <aop:declare-parents types-matching="concert.Performance+" implent-interface="concert.Encoreable" default-impl="concort.DefaultEncoreable"/></aop:aspect> |
顾名思义,<aop:declare-parents> 声明了此切面所通知的 bean 要在它的对象层次结构中拥有新的父类型。具体到本例中,类型匹配 Performance 接口(由 types-matching 属性指定)的那些 bean 在父类结构中会增加 Encoreable 接口(由 implementinterface 属性指定)。最后要解决的问题是 Encoreable 接口中的方法实现要来自于何处。
这里有两种方式标识所引入接口的实现。在本例中,我们使用 default-impl 属性用全限定类名来显式指定 Encoreable 的实现。或者,我们还可以使用 delegate-ref 属性来标识。
1 | <aop:aspect> <aop:declare-parents types-matching="concert.Performance+" implent-interface="concert.Encoreable" delegate-ref="encoreableDelegate"/></aop:aspect> |
delegate-ref 属性引用了一个 Spring bean 作为引入的委托。这需要在 Spring 上下文中存在一个 ID 为 encoreableDelegate 的 bean。
1 | <bean id="encoreableDelegate" class="concert.DefaultEncoreable"/> |
使用 default-impl 来直接标识委托和间接使用 delegate-ref 的区别在于后者是 Spring bean,它本身可以被注入、通知或使用其他的 Spring 配置。
注入 AspectJ 切面
虽然 Spring AOP 能够满足许多应用的切面需求,但是与 AspectJ 相比,Spring AOP 是一个功能比较弱的 AOP 解决方案。 AspectJ 提供了Spring AOP 所不能支持的许多类型的切点。
例如,当我们需要在创建对象时应用通知,构造器切点就非常方便。不像某些其他面向对象语言中的构造器,Java 构造器不同于其他的正常方法。这使得 Spring 基于代理的 AOP 无法把通知应用于对象的创建过程。
对于大部分功能来讲,AspectJ 切面与 Spring 是相互独立的。虽然它们可以织入到任意的 Java 应用中,这也包括了 Spring 应用,但是在应用 AspectJ 切面时几乎不会涉及到 Spring。
但是精心设计且有意义的切面很可能依赖其他类来完成它们的工作。如果在执行通知时,切面依赖于一个或多个类,我们可以在切面内部实例化这些协作的对象。但更好的方式是,我们可以借助 Spring 的依赖注入把 bean 装配进 AspectJ 切面中。
为了演示,我们为上面的演出创建一个新切面。具体来讲,我们以切面的方式创建一个评论员的角色,他会观看演出并且会在演出之后提供一些批评意见。下面的 CriticAspect 就是一个这样的切面。
1 | package concert;public aspect CriticAspect { public CriticAspect(); pointcut performance() : execution(* perfor(..)); afterReturning() : performance() { System.out.println(criticismEngine.getCriticism()); } private CriticismEngine criticismEngine; public void setCriticismEngine(CriticismEngine criticismEngine) { this.criticismEngine = criticismEngine; }} |
CriticAspect 的主要职责是在表演结束后为表演发表评论。程序清单 4.15 中的 performance() 切点匹配 perform() 方法。当它与 afterReturning() 通知一起配合使用时,我们可以让该切面在表演结束时起作用。
程序清单 4.15 有趣的地方在于并不是评论员自己发表评论,实际上,CriticAspect 与一个 CriticismEngine 对象相协作,在表演结束时,调用该对象的 getCriticism() 方法来发表一个苛刻的评论。为了避免 CriticAspect 和 CriticismEngine 之间产生不必要的耦合,我们通过 Setter 依赖注入为 CriticAspect 设置 CriticismEngine。图 4.9 展示了此关系。
CriticismEngine 自身是声明了一个简单 getCriticism() 方法的接口。程序清单 4.16 为CriticismEngine 的实现。
1 | package com.springinaction.springidol;public class CriticismEngineImpl implements CriticismEngine { public CriticismEngineImpl() {} public String getCriticism() { int i = (int) (Math.random() * critismPool.length); return criticismPool[i]; } // injected private String[] criticismPool; public void setCriticismPool(String[] criticismPool) { this.criticismPool = criticismPool; }} |
CriticismEngineImpl 实现了CriticismEngine 接口,通过从注入的评论池中随机选择一个苛刻的评论。这个类可以使用如下的 XML 声明为一个 Spring bean。
1 | <bean id="criticismEngine" class="com.springinaction.springidol.CriticismEngineImpl"> <property name="criticisms"> <list> <value>Worst performance ever!</value> <value>I laughed, I cried, then I realized I was at the wrong show.</value> <value>a must see show.</value> </list> </property></bean> |
到目前为止,一切顺利。我们现在有了一个要赋予 CriticAspect 的 CriticismEngine 实现。剩下的就是为 CriticAspect 装
配 CriticismEngineImple。
在展示如何实现注入之前,我们必须清楚 AspectJ 切面根本不需要 Spring 就可以织入到我们的应用中。如果想使用 Spring 的依赖注入为 AspectJ 切面注入协作者,那我们就需要在 Spring 配置中把切面声明为一个 Spring 配置中的 <bean>。如下的 <bean> 声明会把 criticismEnginebean 注入到 CriticAspect 中:
1 | <bean class="com.springinaction.springidol.CriticAspect" factory-method="aspectOf"> <property name="criticismEngine" ref="criticismEngine"/></bean> |
很大程度上,<bean> 的声明与我们在 Spring 中所看到的其他 <bean> 配置并没有太多的区别,但是最大的不同在于使用了 factorymethod 属性。通常情况下,Spring bean 由 Spring 容器初始化,但是 AspectJ 切面是由 AspectJ 在运行期创建的。等到 Spring 有机会为 CriticAspect 注入 CriticismEngine 时,CriticAspect 已经被实例化了。
因为 Spring 不能负责创建 CriticAspect,那就不能在 Spring 中简单地把 CriticAspect 声明为一个 bean。相反,我们需要一种方式为 Spring 获得已经由 AspectJ 创建的 CriticAspect 实例的句柄,从而可以注入 CriticismEngine。幸好,所有的 AspectJ 切面都提供了一个静态的 aspectOf() 方法,该方法返回切面的一个单例。所以为了获得切面的实例,我们必须使用 factory-method 来调用 asepctOf() 方法而不是调用 CriticAspect 的构造器方法。
简而言之,Spring 不能像之前那样使用 <bean> 声明来创建一个 CriticAspect 实例——它已经在运行时由 AspectJ 创建完成了。Spring 需要通过 aspectOf() 工厂方法获得切面的引用,然后像 <bean> 元素规定的那样在该对象上执行依赖注入。
小结
AOP 是面向对象编程的一个强大补充。通过 AspectJ,我们现在可以把之前分散在应用各处的行为放入可重用的模块中。我们显示地声明在何处如何应用该行为。这有效减少了代码冗余,并让我们的类关注自身的主要功能。
Spring 提供了一个 AOP 框架,让我们把切面插入到方法执行的周围。现在我们已经学会如何把通知织入前置、后置和环绕方法的调用中,以及为处理异常增加自定义的行为。
关于在 Spring 应用中如何使用切面,我们可以有多种选择。通过使用 @AspectJ 注解和简化的配置命名空间,在 Spring 中装配通知和切点变得非常简单。
最后,当 Spring AOP 不能满足需求时,我们必须转向更为强大的 AspectJ。对于这些场景,我们了解了如何使用 Spring 为 AspectJ 切面注入依赖。
此时此刻,我们已经覆盖了 Spring 框架的基础知识,了解到如何配置 Spring 容器以及如何为 Spring 管理的对象应用切面。正如我们所看到的,这些核心技术为创建松散耦合的应用奠定了坚实的基础。
现在,我们越过这些基础的内容,看一下如何使用 Spring 构建真实的应用。从下一章开始,首先看到的是如何使用 Spring 构建 Web 应用。
Web 中的 Spring
Spring 通常用来开发Web应用。因此,在第 2 部分中,将会看到如何使用 Spring 的 MVC 框架为应用程序添加Web前端。
在第 5 章 “构建 Spring Web 应用” 中,你将会学习到 Spring MVC 的基本用法,它是构建在 Spring 理念之上的一个 Web 框架。我们将会看到如何编写处理 Web 请求的控制器以及如何透明地绑定请求参数和负载到业务对象上,同时它还提供了数据检验和错误处理的功能。
在第 6 章 “渲染 Web 视图” 中,将会基于第 5 章的内容继续讲解,展现了如何得到 Spring MVC 控制器所生成的模型数据,并将其渲染为用户浏览器中的 HTML。这一章的讨论包括 JavaServer Pages(JSP)、Apache Tiles 和 Thymeleaf 模板。
在第 7 章 “Spring MVC 的高级技术” 中,将会学习到构建 Web 应用时的一些高级技术,包括自定义 Spring MVC 配置、处理 multipart 文件上传、处理异常以及使用 flash 属性跨请求传递数据。
第 8 章,“使用 Spring Web Flow” 将会为你展示如何使用 Spring Web Flow来构建会话式、基于流程的 Web 应用程序。
鉴于安全是很多应用程序的重要关注点,因此第 9 章 “保护 Web 应用”将会为你介绍如何使用 Spring Security 来为 Web 应用程序提供安全性,保护应用中的信息。
构建 Spring Web 应用程序
本章内容:
- 映射请求到 Spring 控制器
- 透明地绑定表单参数
- 校验表单提交
作为企业级 Java 开发者,你可能开发过一些基于 Web 的应用程序。对于很多 Java 开发人员来说,基于 Web 的应用程序是他们主要的关注点。如果你有这方面经验的话,你会意识到这种系统所面临的挑战。具体来讲,状态管理、工作流以及验证都是需要解决的重要特性。HTTP 协议的无状态性决定了这些问题都不那么容易解决。
Spring 的 Web 框架就是为了帮你解决这些关注点而设计的。SpringMVC 基于模型-视图-控制器(Model-View-Controller,MVC)模式实现,它能够帮你构建像 Spring 框架那样灵活和松耦合的 Web 应用程序。
在本章中,我们将会介绍 Spring MVC Web 框架,并使用新的 SpringMVC 注解来构建处理各种 Web 请求、参数和表单输入的控制器。在深入介绍 Spring MVC 之前,让我们先总体上介绍一下 Spring MVC,并建立起 Spring MVC 运行的基本配置。
Spring MVC 起步
你见到过孩子们的捕鼠器游戏吗?这真是一个疯狂的游戏,它的目标是发送一个小钢球,让它经过一系列稀奇古怪的装置,最后触发捕鼠器。小钢球穿过各种复杂的配件,从一个斜坡上滚下来,被跷跷板弹起,绕过一个微型摩天轮,然后被橡胶靴从桶中踢出去。经过这些后,小钢球会对那只可怜又无辜的橡胶老鼠进行捕获。
乍看上去,你会认为 Spring MVC 框架与捕鼠器有些类似。Spring 将请求在调度 Servlet、处理器映射(handler mapping)、控制器以及视图解析器(view resolver)之间移动,而捕鼠器中的钢球则会在各种斜坡、跷跷板以及摩天轮之间滚动。但是,不要将 Spring MVC 与 Rube Goldberg-esque 捕鼠器游戏做过多比较。每一个 Spring MVC 中的组件都有特定的目的,并且它也没有那么复杂。
让我们看一下请求是如何从客户端发起,经过 Spring MVC 中的组件,最终再返回到客户端的。
跟踪 Spring MVC 的请求
每当用户在 Web 浏览器中点击链接或提交表单的时候,请求就开始工作了。对请求的工作描述就像是快递投送员。与邮局投递员或 FedEx 投送员一样,请求会将信息从一个地方带到另一个地方。
请求是一个十分繁忙的家伙。从离开浏览器开始到获取响应返回,它会经历好多站,在每站都会留下一些信息同时也会带上其他信息。图 5.1 展示了请求使用 Spring MVC 所经历的所有站点。
在请求离开浏览器时,会带有用户所请求内容的信息,至少会包含请求的 URL。但是还可能带有其他的信息,例如用户提交的表单信息。
请求旅程的第一站是 Spring 的 DispatcherServlet。与大多数基于 Java 的 Web 框架一样,Spring MVC 所有的请求都会通过一个前端控制器(front controller) Servlet。前端控制器是常用的 Web 应用程序模式,在这里一个单实例的 Servlet 将请求委托给应用程序的其他组件来执行实际的处理。在 Spring MVC 中,DispatcherServlet 就是前端控制器。
DispatcherServlet 的任务是将请求发送给 Spring MVC 控制器(controller)。控制器是一个用于处理请求的 Spring 组件。在典型的应用程序中可能会有多个控制器,DispatcherServlet 需要知道应该将请求发送给哪个控制器。所以 DispatcherServlet 以会查询一个或多个处理器映射(handler mapping) 来确定请求的下一站在哪里。处理器映射会根据请求所携带的 URL 信息来进行决策。
一旦选择了合适的控制器,DispatcherServlet 会将请求发送给选中的控制器。到了控制器,请求会卸下其负载(用户提交的信息)并耐心等待控制器处理这些信息。(实际上,设计良好的控制器本身只处理很少甚至不处理工作,而是将业务逻辑委托给一个或多个服务对象进行处理。)
控制器在完成逻辑处理后,通常会产生一些信息,这些信息需要返回给用户并在浏览器上显示。这些信息被称为模型(model)。不过仅仅给用户返回原始的信息是不够的——这些信息需要以用户友好的方式进行格式化,一般会是 HTML。所以,信息需要发送给一个视图(view),通常会是 JSP。
控制器所做的最后一件事就是将模型数据打包,并且标示出用于渲染输出的视图名。它接下来会将请求连同模型和视图名发送回 DispatcherServlet 。
这样,控制器就不会与特定的视图相耦合,传递给 DispatcherServlet 的视图名并不直接表示某个特定的 JSP。实际上,它甚至并不能确定视图就是 JSP。相反,它仅仅传递了一个逻辑名称,这个名字将会用来查找产生结果的真正视图。DispatcherServlet 将会使用视图解析器(view resolver)来将逻辑视图名匹配为一个特定的视图实现,它可能是也可能不是 JSP。
既然 DispatcherServlet 已经知道由哪个视图渲染结果,那请求的任务基本上也就完成了。它的最后一站是视图的实现(可能是 JSP) ,在这里它交付模型数据。请求的任务就完成了。视图将使用模型数据渲染输出,这个输出会通过响应对象传递给客户端(不会像听上去那样硬编码) 。
可以看到,请求要经过很多的步骤,最终才能形成返回给客户端的响应。大多数的步骤都是在 Spring 框架内部完成的,也就是图 5.1 所示的组件中。尽管本章的主要内容都关注于如何编写控制器,但在此之前我们首先看一下如何搭建 Spring MVC 的基础组件。
搭建 Spring MVC
基于图 5.1,看上去我们需要配置很多的组成部分。幸好,借助于最近几个 Spring 新版本的功能增强,开始使用 Spring MVC 变得非常简单了。现在,我们要使用最简单的方式来配置 Spring MVC:所要实现的功能仅限于运行我们所创建的控制器。在第 7 章中,我们会看一些其他的配置选项。
配置 DispatcherServlet
DispatcherServlet 是 Spring MVC 的核心。在这里请求会第一次接触到框架,它要负责将请求路由到其他的组件之中。
按照传统的方式,像 DispatcherServlet 这样的 Servlet 会配置在 web.xml 文件中,这个文件会放到应用的 WAR 包里面。当然,这是配置 DispatcherServlet 的方法之一。但是,借助于 Servlet 3 规范和 Spring 3.1 的功能增强,这种方式已经不是唯一的方案了,这也不是我们本章所使用的配置方法。
我们会使用 Java 将 DispatcherServlet 配置在 Servlet 容器中,而不会再使用 web.xml 文件。如下的程序清单展示了所需的 Java 类。
1 | package spittr.config;import org.springframework.web.servlet.support.AbstractAnnotationConfigDispatcherServletInitializer;import spittr.web.WebConfig;public class SpitterWebInitializer extends AbstractAnnotationConfigDispatcherServletInitializer { protected String[] getServletMappings() { return new String[] { "/" }; } protected Class<?>[] getRootConfigClasses() { return new Class<?>[] { RootConfig.class }; } protected Class<?>[] getServletConfigClasses() { return new Class<?>[] { WebConfig.class }; }} |
在我们深入介绍程序清单 5.1 之前,你可能想知道 spittr 到底是什么意思。这个类的名字是 SpittrWebAppInitializer,它位于名为 spittr.config 的包中。我稍后会对其进行介绍(在 5.1.3 小节中),但现在,你只需要知道我们所要创建的应用名为 Spittr。
要理解程序清单 5.1 是如何工作的,我们可能只需要知道扩展 AbstractAnnotationConfigDispatcherServletInitializer 的任意类都会自动地配置 DispatcherServlet和 Spring 应用上下文,Spring 的应用上下文会位于应用程序的 Servlet 上下文之中。
AbstractAnnotationConfigDispatcherServletInitializer 剖析
如果你坚持要了解更多细节的话,那就看这里吧。在 Servlet 3.0 环境中,容器会在类路径中查找实现 javax.servlet.ServletContainerInitializer 接口的类,如果能发现的话,就会用它来配置 Servlet 容器。
Spring 提供了这个接口的实现,名为 SpringServletContainerInitializer,这个类反过来又会查找实现 WebApplicationInitializer 的类并将配置的任务交给它们来完成。Spring 3.2 引入了一个便利的 WebApplicationInitializer 基础实现,也就是 AbstractAnnotationConfigDispatcherServletInitializer 。因为我们的 SpittrWebAppInitializer 扩展了 AbstractAnnotationConfigDispatcherServletInitializer(同时也就实现了 WebApplicationInitializer),因此当部署到 Servlet 3.0 容器中的时候,容器会自动发现它,并用它来配置 Servlet 上下文。
尽管它的名字很长,但是 AbstractAnnotationConfigDispatcherServletInitializer 使用起来很简便。在程序清单 5.1 中,SpittrWebAppInitializer 重写了三个方法。
第一个方法是 getServletMappings(),它会将一个或多个路径映射到 DispatcherServlet 上。在本例中,它映射的是 “/”,这表示它会是应用的默认 Servlet。它会处理进入应用的所有请求。
为了理解其他的两个方法,我们首先要理解 DispatcherServlet 和一个 Servlet 监听器(也就是 ContextLoaderListener)的关系。
两个应用上下文之间的故事
当 DispatcherServlet 启动的时候,它会创建 Spring 应用上下文,并加载配置文件或配置类中所声明的 bean。在程序清单 5.1 的 getServletConfigClasses() 方法中,我们要求 DispatcherServlet 加载应用上下文时,使用定义在 WebConfig 配置类(使用 Java 配置)中的 bean。
但是在Spring Web应用中,通常还会有另外一个应用上下文。另外的这个应用上下文是由 ContextLoaderListener 创建的。
我们希望 DispatcherServlet 加载包含 Web 组件的 bean,如控制器、视图解析器以及处理器映射,而 ContextLoaderListener 要加载应用中的其他 bean。这些 bean 通常是驱动应用后端的中间层和数据层组件。
实际上,AbstractAnnotationConfigDispatcherServletInitializer 会同时创建 DispatcherServlet 和 ContextLoaderListener。GetServletConfigClasses() 方法返回的带有 @Configuration 注解的类将会用来定义 DispatcherServlet 应用上下文中的 bean。getRootConfigClasses() 方法返回的带有 @Configuration 注解的类将会用来配置 ContextLoaderListener 创建的应用上下文中的 bean。
在本例中,根配置定义在 RootConfig 中,DispatcherServlet 的配置声明在 WebConfig 中。稍后我们将会看到这两个类的内容。
需要注意的是,通过 AbstractAnnotationConfigDispatcherServletInitializer 来配置 DispatcherServlet 是传统 web.xml 方式的替代方案。如果你愿意的话,可以同时包含 web.xml 和 AbstractAnnotationConfigDispatcherServletInitializer,但这其实并没有必要。
如果按照这种方式配置 DispatcherServlet,而不是使用 web.xml 的话,那唯一问题在于它只能部署到支持 Servlet 3.0 的服务器中才能正常工作,如 Tomcat 7 或更高版本。Servlet 3.0 规范在 2009 年 12 月份就发布了,因此很有可能你会将应用部署到支持 Servlet 3.0 的 Servlet 容器之中。
如果你还没有使用支持 Servlet 3.0 的服务器,那么在 AbstractAnnotationConfigDispatcherServletInitializer 子类中配置 DispatcherServlet 的方法就不适合你了。你别无选择,只能使用 web.xml 了。我们将会在第 7 章学习 web.xml 和其他配置选项。但现在,我们先看一下程序清单 5.1 中所引用的 WebConfig 和 RootConfig,了解一下如何启用 Spring MVC。
启用 Spring MVC
我们有多种方式来配置 DispatcherServlet,与之类似,启用 Spring MVC 组件的方法也不仅一种。以前,Spring 是使用 XML 进行配置的,你可以使用<mvc:annotation-driven> 启用注解驱动的 Spring MVC。
我们会在第 7 章讨论 Spring MVC 配置可选项的时候,再讨论 <mvc:annotation-driven>。不过,现在我们会让 Spring MVC 的搭建过程尽可能简单并基于 Java进行配置。
我们所能创建的最简单的 Spring MVC 配置就是一个带有 @EnableWebMvc 注解的类:
1 | package spittr.web;import org.springframework.context.annotation.Configuration;import org.springframework.web.servlet.config.annotation.EnableWebMvc; class WebConfig extends WebMvcConfigurerAdapter {} |
这可以运行起来,它的确能够启用 Spring MVC,但还有不少问题要解决:
- 没有配置视图解析器。如果这样的话,Spring 默认会使用
BeanNameViewResolver,这个视图解析器会查找 ID 与视图名称匹配的 bean,并且查找的 bean 要实现 View 接口,它以这样的方式来解析视图。 - 没有启用组件扫描。这样的结果就是,Spring 只能找到显式声明在配置类中的控制器。
- 这样配置的话,
DispatcherServlet会映射为应用的默认Servlet,所以它会处理所有的请求,包括对静态资源的请求,如图片和样式表(在大多数情况下,这可能并不是你想要的效果)。
因此,我们需要在 WebConfig 这个最小的 Spring MVC 配置上再加一些内容,从而让它变得真正有用。如下程序清单中的 WebConfig 解决了上面所述的问题。
1 | package spittr.web;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.ComponentScan;import org.springframework.context.annotation.Configuration;import org.springframework.web.servlet.ViewResolver;import org.springframework.web.servlet.config.annotation.DefaultServletHandlerConfigurer;import org.springframework.web.servlet.config.annotation.EnableWebMvc;import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;import org.springframework.web.servlet.config.annotation.WebMvcConfigurerAdapter;import org.springframework.web.servlet.view.InternalResourceViewResolver; // 启用 Spring mvc@ComponentScan("spittr.web") // 启用组件扫描public class WebConfig extends WebMvcConfigurerAdapter { // 配置 jsp 视图解析器 @Bean public ViewResolver viewResolver() { InternalResourceViewResolver resolver = new InternalResourceViewResolver(); resolver.setPrefix("/WEB-INF/views/"); resolver.setSuffix(".jsp"); return resolver; } // 配置静态资源的处理 @Override public void configureDefaultServletHandling(DefaultServletHandlerConfigurer configurer) { configurer.enable(); }} |
在程序清单 5.2 中第一件需要注意的事情是 WebConfig 现在添加了 @ComponentScan 注解,因此将会扫描 spitter.web 包来查找组件。稍后你就会看到,我们所编写的控制器将会带有 @Controller 注解,这会使其成为组件扫描时的候选 bean。因此,我们不需要在配置类中显式声明任何的控制器。
接下来,我们添加了一个 ViewResolver bean。更具体来讲,是 InternalResourceViewResolver。我们将会在第 6 章更为详细地讨论视图解析器。我们只需要知道它会查找 JSP 文件,在查找的时候,它会在视图名称上加一个特定的前缀和后缀(例如,名为 home 的视图将会解析为 /WEB-INF/views/home.jsp)。
最后,新的 WebConfig 类还扩展了 WebMvcConfigurerAdapter 并重写了其 configureDefaultServletHandling() 方法。通过调用DefaultServletHandlerConfigurer 的 enable() 方法,我们要求 DispatcherServlet 将对静态资源的请求转发到 Servlet 容器中默认的 Servlet 上,而不是使用 DispatcherServlet 本身来处理此类请求。
WebConfig 已经就绪,那 RootConfig 呢?因为本章聚焦于 Web 开发,而 Web 相关的配置通过 DispatcherServlet 创建的应用上下文都已经配置好了,因此现在的 RootConfig 相对很简单:
1 | package spittr.config;import java.util.regex.Pattern;import org.springframework.context.annotation.ComponentScan;import org.springframework.context.annotation.ComponentScan.Filter;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.FilterType;import org.springframework.context.annotation.Import;import org.springframework.core.type.filter.RegexPatternTypeFilter;import spittr.config.RootConfig.WebPackage;public class RootConfig { public static class WebPackage extends RegexPatternTypeFilter { public WebPackage() { super(Pattern.compile("spittr\\.web")); } }} |
唯一需要注意的是 RootConfig 使用了 @ComponentScan 注解。这样的话,在本书中,我们就有很多机会用非 Web 的组件来充实完善 RootConfig。
现在,我们基本上已经可以开始使用 Spring MVC 构建 Web 应用了。此时,最大的问题在于,我们要构建的应用到底是什么。
Spittr 应用简介
为了实现在线社交的功能,我们将要构建一个简单的微博(microblogging)应用。在很多方面,我们所构建的应用与最早的微博应用 Twitter 很类似。在这个过程中,我们会添加一些小的变化。当然,我们要使用 Spring 技术来构建这个应用。
因为从 Twitter 借鉴了灵感并且通过 Spring 来进行实现,所以它就有了一个名字:Spitter。再进一步,应用网站命名中流行的模式,如 Flickr,我们去掉字母 e,这样的话,我们就将这个应用称为 Spittr。这个名称也有助于区分应用名称和领域类型,因为我们将会创建一个名为 Spitter 的领域类。
Spittr 应用有两个基本的领域概念:Spitter(应用的用户)和 Spittle(用户发布的简短状态更新)。当我们在书中完善 Spittr 应用的功能时,将会介绍这两个领域概念。在本章中,我们会构建应用的 Web 层,创建展现 Spittle 的控制器以及处理用户注册成为 Spitter 的表单。
舞台已经搭建完成了。我们已经配置了 DispatcherServlet,启用了基本的 Spring MVC 组件并确定了目标应用。让我们进入本章的核心内容:使用 Spring MVC 控制器处理 Web 请求。
编写基本的控制器
在 Spring MVC 中,控制器只是方法上添加了 @RequestMapping 注解的类,这个注解声明了它们所要处理的请求。
开始的时候,我们尽可能简单,假设控制器类要处理对 “/” 的请求,并渲染应用的首页。程序清单 5.3 所示的 HomeController 可能是最简单的 Spring MVC 控制器类了。
1 | package spittr.web;import static org.springframework.web.bind.annotation.RequestMethod.*;import org.springframework.stereotype.Controller;import org.springframework.ui.Model;import org.springframework.web.bind.annotation.RequestMapping; class HomeController { public String home(Model model) { return "home"; }} |
你可能注意到的第一件事情就是 HomeController 带有 @Controller 注解。很显然这个注解是用来声明控制器的,但实际上这个注解对 Spring MVC 本身的影响并不大。
HomeController 是一个构造型(stereotype)的注解,它基于@Component 注解。在这里,它的目的就是辅助实现组件扫描。因为 HomeController 带有 @Controller 注解,因此组件扫描器会自动找到 HomeController,并将其声明为 Spring 应用上下文中的一个 bean。
其实,你也可以让 HomeController 带有 @Component 注解,它所实现的效果是一样的,但是在表意性上可能会差一些,无法确定 HomeController 是什么组件类型。
HomeController 唯一的一个方法,也就是 home() 方法,带有 @RequestMapping 注解。它的 value 属性指定了这个方法所要处理的请求路径,method 属性细化了它所处理的 HTTP 方法。在本例中,当收到对 “/” 的 HTTP GET 请求时,就会调用 home() 方法。
你可以看到,home() 方法其实并没有做太多的事情:它返回了一个 String 类型的 “home”。这个 String 将会被 Spring MVC 解读为要渲染的视图名称。DispatcherServlet 会要求视图解析器将这个逻辑名称解析为实际的视图。
鉴于我们配置 InternalResourceViewResolver 的方式,视图名 “home” 将会解析为 “/WEB-INF/views/home.jsp” 路径的 JSP。现在,我们会让 Spittr 应用的首页相当简单,如下所示。
1 | <%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %><%@ page session="false" %><html> <head> <title>Spitter</title> <link rel="stylesheet" type="text/css" href="<c:url value="/resources/style.css" />" > </head> <body> <h1>Welcome to Spitter</h1> <a href="<c:url value="/spittles" />">Spittles</a> | <a href="<c:url value="/spitter/register" />">Register</a> </body></html> |
这个 JSP 并没有太多需要注意的地方。它只是欢迎应用的用户,并提供了两个链接:一个是查看 Spittle 列表,另一个是在应用中进行注册。图 5.2 展现了此时的首页是什么样子的。
在本章完成之前,我们将会实现处理这些请求的控制器方法。但现在,让我们对这个控制器发起一些请求,看一下它是否能够正常工作。测试控制器最直接的办法可能就是构建并部署应用,然后通过浏览器对其进行访问,但是自动化测试可能会给你更快的反馈和更一致的独立结果。所以,让我们编写一个针对 HomeController 的测试。

测试控制器
让我们再审视一下 HomeController。如果你眼神不太好的话,你甚至可能注意不到这些注解,所看到的仅仅是一个简单的 POJO。我们都知道测试 POJO 是很容易的。因此,我们可以编写一个简单的类来测试 HomeController,如下所示:
1 | package spittr.web;import static org.springframework.test.web.servlet.request.MockMvcRequestBuilders.*;import static org.springframework.test.web.servlet.result.MockMvcResultMatchers.*;import static org.springframework.test.web.servlet.setup.MockMvcBuilders.*;import org.junit.Test;import org.springframework.test.web.servlet.MockMvc;import spittr.web.HomeController;public class HomeControllerTest { public void testHomePage() throws Exception { HomeController controller = new HomeController(); assertEquals("home", controller.home()) }} |
程序清单 5.5 中的测试很简单,但它只测试了 home() 方法中会发生什么。在测试中会直接调用 home() 方法,并断言返回包含 “home” 值的 String。它完全没有站在 Spring MVC 控制器的视角进行测试。这个测试没有断言当接收到针对 “/” 的 GET 请求时会调用 home() 方法。因为它返回的值就是 “home”,所以也没有真正判断 home 是视图的名称。
不过从 Spring 3.2 开始,我们可以按照控制器的方式来测试 Spring MVC 中的控制器了,而不仅仅是作为 POJO 进行测试。Spring 现在包含了一种 mock Spring MVC 并针对控制器执行 HTTP 请求的机制。这样的话,在测试控制器的时候,就没有必要再启动 Web 服务器和 Web 浏览器了。
为了阐述如何测试 Spring MVC 的控制器,我们重写 HomeControllerTest 并使用 Spring MVC 中新的测试特性。程序清单 5.6 展现了新的 HomeControllerTest。
1 | package spittr.web;import static org.springframework.test.web.servlet.request.MockMvcRequestBuilders.*;import static org.springframework.test.web.servlet.result.MockMvcResultMatchers.*;import static org.springframework.test.web.servlet.setup.MockMvcBuilders.*;import org.junit.Test;import org.springframework.test.web.servlet.MockMvc;import spittr.web.HomeController;public class HomeControllerTest { public void testHomePage() throws Exception { HomeController controller = new HomeController(); MockMvc mockMvc = standaloneSetup(controller).build(); //搭建 MocMvc mockMvc.perform(get("/")). // 对 "/" 执行 GET 请求 andExpect(view().name("home")); // 预期得到 home 视图 }} |
尽管新版本的测试只比之前版本多了几行代码,但是它更加完整地测试了 HomeController。这次我们不是直接调用 home() 方法并测试它的返回值,而是发起了对 “/” 的 GET 请求,并断言结果视图的名称为 home。它首先传递一个 HomeController 实例到 MockMvcBuilders.standaloneSetup() 并调用 build() 来构建 MockMvc 实例。然后它使用 MockMvc 实例来执行针对 “/” 的 GET 请求并设置期望得到的视图名称。
定义类级别的请求处理
现在,已经为 HomeController 编写了测试,那么我们可以做一些重构,并通过测试来保证不会对功能造成什么破坏。我们可以做的一件事就是拆分 @RequestMapping,并将其路径映射部分放到类级别上。程序清单 5.7 展示了这个过程。
1 | package spittr.web;import static org.springframework.web.bind.annotation.RequestMethod.*;import org.springframework.stereotype.Controller;import org.springframework.ui.Model;import org.springframework.web.bind.annotation.RequestMapping;public class HomeController { public String home(Model model) { return "home"; }} |
在这个新版本的 HomeController 中,路径现在被转移到类级别的 @RequestMapping 上,而 HTTP 方法依然映射在方法级别上。当控制器在类级别上添加 @RequestMapping 注解时,这个注解会应用到控制器的所有处理器方法上。处理器方法上的 @RequestMapping 注解会对类级别上的 @RequestMapping 的声明进行补充。
就 HomeController 而言,这里只有一个控制器方法。与类级别的 @RequestMapping 合并之后,这个方法的 @RequestMapping 表明 home() 将会处理对 “/” 路径的 GET 请求。
换言之,我们其实没有改变任何功能,只是将一些代码换了个地方,但是 HomeController 所做的事情和以前是一样的。因为我们现在有了测试,所以可以确保在这个过程中,没有对原有的功能造成破坏。
当我们在修改 @RequestMapping 时,还可以对 HomeController 做另外一个变更。@RequestMapping 的 value 属性能够接受一个 String 类型的数组。到目前为止,我们给它设置的都是一个 String 类型的 /。但是,我们还可以将它映射到对 /homepage 的请求,只需将类级别的 @RequestMapping 改为如下所示:
1 | public class HomeController{} |
现在,HomeController 的 home() 方法能够映射到对 / 和 /homepage 的 GET 请求。
传递模型数据到视图中
到现在为止,就编写超级简单的控制器来说,HomeController 已经是一个不错的样例了。但是大多数的控制器并不是这么简单。在 Spittr 应用中,我们需要有一个页面展现最近提交的 Spittle 列表。因此,我们需要一个新的方法来处理这个页面。
首先,需要定义一个数据访问的 Repository。为了实现解耦以及避免陷入数据库访问的细节之中,我们将 Repository 定义为一个接口,并在稍后实现它(第 10 章中)。此时,我们只需要一个能够获取 Spittle 列表的 Repository,如下所示的 SpittleRepository 功能已经足够了:
1 | package data;import java.util.List;import spittr.Spittle;public interface SpittleRepository { List<Spittle> findSpittles(long max, int count);} |
findSpittles() 方法接受两个参数。其中 max 参数代表所返回的 Spittle 中,Spittle ID 属性的最大值,而 count 参数表明要返回多少个 Spittle 对象。为了获得最新的 20 个 Spittle 对象,我们可以这样调用 findSpittles():
1 | List<Spittle> recent = spittlerepository.findSpittles(long.MAX_VALUE, 20); |
现在,我们让 Spittle 类尽可能的简单,如下面的程序清单 5.8 所示。它的属性包括消息内容、时间戳以及 Spittle 发布时对应的经纬度。
1 | package spittr;import java.util.Date;import org.apache.commons.lang3.builder.EqualsBuilder;import org.apache.commons.lang3.builder.HashCodeBuilder;public class Spittle { private final Long id; private final String message; private final Date time; private Double latitude; private Double longitude; public Spittle(String message, Date time) { this(null, message, time, null, null); } public Spittle(Long id, String message, Date time, Double longitude, Double latitude) { this.id = id; this.message = message; this.time = time; this.longitude = longitude; this.latitude = latitude; } public long getId() { return id; } public String getMessage() { return message; } public Date getTime() { return time; } public Double getLongitude() { return longitude; } public Double getLatitude() { return latitude; } public boolean equals(Object that) { return EqualsBuilder.reflectionEquals(this, that, "id", "time"); } public int hashCode() { return HashCodeBuilder.reflectionHashCode(this, "id", "time"); } } |
就大部分内容来看,Spittle 就是一个基本的 POJO 数据对象——没有什么复杂的。唯一要注意的是,我们使用 Apache Common Lang 包来实现 equals() 和 hashCode() 方法。这些方法除了常规的作用以外,当我们为控制器的处理器方法编写测试时,它们也是有用的。
既然我们说到了测试,那么我们继续讨论这个话题并为新的控制器方法编写测试。如下的程序清单使用 Spring 的 MockMvc 来断言新的处理器方法中你所期望的行为。
1 | void shouldShowRecentSpittles() throws Exception { List<Spittle> expectedSpittles = createSpittleList(20); SpittleRepository mockRepository = mock(SpittleRepository.class); when(mockRepository.findSpittles(Long.MAX_VALUE, 20)) .thenReturn(expectedSpittles); SpittleController controller = new SpittleController(mockRepository); MockMvc mockMvc = standaloneSetup(controller) .setSingleView(new InternalResourceView("/WEB-INF/views/spittles.jsp")) .build(); mockMvc.perform(get("/spittles")) .andExpect(view().name("spittles")) .andExpect(model().attributeExists("spittleList")) .andExpect(model().attribute("spittleList", hasItems(expectedSpittles.toArray())));} |
这个测试首先会创建 SpittleRepository 接口的mock实现,这个实现会从它的 findSpittles() 方法中返回 20 个 Spittle 对象。然后,它将这个 Repository 注入到一个新的 SpittleController 实例中,然后创建 MockMvc 并使用这个控制器。
需要注意的是,与 HomeController 不同,这个测试在 MockMvc 构造器上调用了 setSingleView()。这样的话,mock 框架就不用解析控制器中的视图名了。在很多场景中,其实没有必要这样做。但是对于这个控制器方法,视图名与请求路径是非常相似的,这样按照默认的视图解析规则时,MockMvc 就会发生失败,因为无法区分视图路径和控制器的路径。在这个测试中,构建 InternalResourceView 时所设置的实际路径是无关紧要的,但我们将其设置为与 InternalResourceViewResolver 配置一致。
这个测试对 “/spittles” 发起 GET 请求,然后断言视图的名称为 spittles 并且模型中包含名为 spittleList 的属性,在 spittleList 中包含预期的内容。
当然,如果此时运行测试的话,它将会失败。它不是运行失败,而是在编译的时候就会失败。这是因为我们还没有编写 SpittleController。现在,我们创建 SpittleController,让它满足程序清单 5.9 的预期。如下的 SpittleController 实现将会满足以上测试的要求。
1 | package spittr.web;import java.util.Date;import java.util.List;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Controller;import org.springframework.ui.Model;import org.springframework.web.bind.annotation.PathVariable;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.web.bind.annotation.RequestParam;import spittr.Spittle;import spittr.data.SpittleRepository;public class SpittleController { private SpittleRepository spittleRepository; public SpittleController(SpittleRepository spittleRepository) { this.spittleRepository = spittleRepository; } public String spittles(Model model) { model.addAttribute(spittleRepository.findSpittles(Long.MAX_VALUE, 20); return "spittles"; }} |
我们可以看到 SpittleController 有一个构造器,这个构造器使用了 @Autowired 注解,用来注入 SpittleRepository。这个 SpittleRepository 随后又用在 spittles() 方法中,用来获取最新的 spittle 列表。
需要注意的是,我们在 spittles() 方法中给定了一个 Model 作为参数。这样,spittles() 方法就能将 Repository 中获取到的 Spittle 列表填充到模型中。Model 实际上就是一个 Map(也就是 key-value 对的集合),它会传递给视图,这样数据就能渲染到客户端了。当调用 addAttribute() 方法并且不指定 key 的时候,那么key 会根据值的对象类型推断确定。在本例中,因为它是一个 List<Spittle>,因此,键将会推断为 spittleList。
spittles() 方法所做的最后一件事是返回 spittles 作为视图的名字,这个视图会渲染模型。
如果你希望显式声明模型的 key 的话,那也尽可以进行指定。例如,下面这个版本的 spittles() 方法与程序清单 5.10 中的方法作用是一样的:
1 | public String spittles(Model model) { model.addAttribute("spittleList", spittleRepository.findSpittles(Long.MAX_VALUE, 20)); return "spittles";} |
如果你希望使用非 Spring 类型的话,那么可以用 java.util.Map 来代替 Model。下面这个版本的 spittles() 方法与之前的版本在功能上是一样的:
1 | public String spittles(Map model) { model.put("spittleList", spittleRepository.findSpittles(Long.MAX_VALUE, 20)); return "spittles";} |
既然我们现在提到了各种可替代的方案,那下面还有另外一种方式来编写 spittles() 方法:
1 | public List<Spittle> spittles() { return spittleRepository.findSpittles(Long.MAX_VALUE, 20);} |
这个版本与其他的版本有些差别。它并没有返回视图名称,也没有显式地设定模型,这个方法返回的是 Spittle 列表。当处理器方法像这样返回对象或集合时,这个值会放到模型中,模型的 key 会根据其类型推断得出(在本例中,也就是 spittleList)。
而逻辑视图的名称将会根据请求路径推断得出。因为这个方法处理针对 “/spittles” 的 GET 请求,因此视图的名称将会是 spittles(去掉开头的斜线)。
不管你选择哪种方式来编写 spittles() 方法,所达成的结果都是相同的。模型中会存储一个 Spittle 列表,key 为 spittleList,然后这个列表会发送到名为 spittles 的视图中。按照我们配置 InternalResourceViewResolver的方式,视图的 JSP 将会是 “/WEB-INF/views/spittles.jsp”。
现在,数据已经放到了模型中,在 JSP 中该如何访问它呢?实际上,当视图是 JSP 的时候,模型数据会作为请求属性放到请求(request)之中。因此,在 spittles.jsp 文件中可以使用 JSTL(Java Server Pages Standard Tag Library)的 <c:forEach> 标签渲染 spittle 列表:
1 | <c:forEach items="${spittleList}" var="spittle" > <li id="spittle_<c:out value="spittle.id"/>"> <div class="spittleMessage"><c:out value="${spittle.message}" /></div> <div> <span class="spittleTime"><c:out value="${spittle.time}" /></span> <span class="spittleLocation">(<c:out value="${spittle.latitude}" />, <c:out value="${spittle.longitude}" />)</span> </div> </li></c:forEach> |
图 5.3 为显示效果,能够让你对它在 Web 浏览器中是什么样子有个可视化的印象。
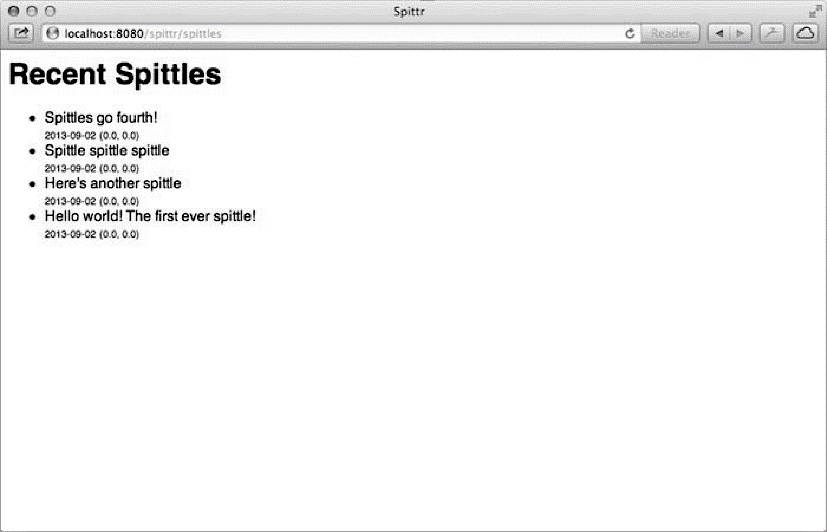
尽管 SpittleController 很简单,但是它依然比 HomeController 更进一步了。不过,SpittleController 和 HomeController 都没有处理任何形式的输入。现在,让我们扩展 SpittleController,让它从客户端接受一些输入。
接受请求的输入
有些 Web 应用是只读的。人们只能通过浏览器在站点上闲逛,阅读服务器发送到浏览器中的内容。不过,这并不是一成不变的。众多的 Web 应用允许用户参与进去,将数据发送回服务器。如果没有这项能力的话,那 Web 将完全是另一番景象。
Spring MVC 允许以多种方式将客户端中的数据传送到控制器的处理器方法中,包括:
- 查询参数(Query Parameter)。
- 表单参数(Form Parameter)。
- 路径变量(Path Variable)。
你将会看到如何编写控制器处理这些不同机制的输入。作为开始,我们先看一下如何处理带有查询参数的请求,这也是客户端往服务器端发送数据时,最简单和最直接的方式。
处理查询参数
在 Spittr 应用中,我们可能需要处理的一件事就是展现分页的 Spittle 列表。在现在的 SpittleController 中,它只能展现最新的 Spittle,并没有办法向前翻页查看以前编写的 Spittle 历史记录。如果你想让用户每次都能查看某一页的 Spittle 历史,那么就需要提供一种方式让用户传递参数进来,进而确定要展现哪些 Spittle 集合。
在确定该如何实现时,假设我们要查看某一页 Spittle 列表,这个列表会按照最新的 Spittle 在前的方式进行排序。因此,下一页中第一条的 ID 肯定会早于当前页最后一条的 ID。所以,为了显示下一页的 Spittle,我们需要将一个 Spittle 的 ID 传入进来,这个 ID 要恰好小于当前页最后一条 Spittle 的 ID。另外,你还可以传入一个参数来确定要展现的 Spittle 数量。
为了实现这个分页的功能,我们所编写的处理器方法要接受如下的参数:
- before 参数(表明结果中所有 Spittle 的ID 均应该在这个值之前)。
- count 参数(表明在结果中要包含的 Spittle 数量)。
为了实现这个功能,我们将程序清单 5.10 中的 spittles() 方法替换为使用 before 和 count 参数的新 spittles() 方法。我们首先添加一个测试,这个测试反映了新 spittles() 方法的功能。
1 | void shouldShowPagedSpittles() throws Exception { List<Spittle> expectedSpittles = createSpittleList(50); SpittleRepository mockRepository = mock(SpittleRepository.class); when(mockRepository.findSpittles(238900, 50)) // 预期的 max 和 count 参数 .thenReturn(expectedSpittles); SpittleController controller = new SpittleController(mockRepository); MockMvc mockMvc = standaloneSetup(controller) .setSingleView(new InternalResourceView("/WEB-INF/views/spittles.jsp")) .build(); mockMvc.perform(get("/spittles?max=238900&count=50")) // 传入 max 和 count 参数 .andExpect(view().name("spittles")) .andExpect(model().attributeExists("spittleList")) .andExpect(model().attribute("spittleList", hasItems(expectedSpittles.toArray())));} |
这个测试方法与程序清单 5.9 中的测试方法关键区别在于它针对 “/spittles” 发送 GET 请求,同时还传入了 max 和 count 参数。它测试了这些参数存在时的处理器方法,而另一个测试方法则测试了没有这些参数时的情景。这两个测试就绪后,我们就能确保不管控制器发生什么样的变化,它都能够处理这两种类型的请求:
1 | public List<Spittle> spittles( long max, int count) { return spittleRepository.findSpittles(max, count);} |
SpittleController 中的处理器方法要同时处理有参数和没有参数的场景,那我们需要对其进行修改,让它能接受参数,同时,如果这些参数在请求中不存在的话,就使用默认值 Long.MAX_VALUE 和 20。@RequestParam 注解的 defaultValue 属性可以完成这项任务:
1 | public List<Spittle> spittles( long max, int count) { return spittleRepository.findSpittles(max, count);} |
现在,如果 max 参数没有指定的话,它将会是 Long 类型的最大值。因为查询参数都是 String 类型的,因此 defaultValue 属性需要 String 类型的值。因此,使用 Long.MAX_VALUE 是不行的。我们可以将 Long.MAX_VALUE 转换为名为 MAX_LONG_AS_STRING 的 String 类型常量:
1 | private static final String MAX_LONG_AS_STRING = Long.toString(Long.MAX_VALUE); |
尽管 defaultValue 属性给定的是 String 类型的值,但是当绑定到方法的 max 参数时,它会转换为 Long 类型。
如果请求中没有 count 参数的话,count 参数的默认值将会设置为 20。
请求中的查询参数是往控制器中传递信息的常用手段。另外一种方式也很流行,尤其是在构建面向资源的控制器时,这种方式就是将传递参数作为请求路径的一部分。让我们看一下如何将路径变量作为请求路径的一部分,从而实现信息的输入。
通过路径参数接受输入
假设我们的应用程序需要根据给定的 ID 来展现某一个 Spittle 记录。其中一种方案就是编写处理器方法,通过使用 @RequestParam 注解,让它接受 ID 作为查询参数:
1 | public String spittle( long spittleId, Model model) { model.addAttribute(spittleRepository.findOne(spittleId)); return "spittle";} |
这个处理器方法将会处理形如 “/spittles/show?spittle_id=12345” 这样的请求。尽管这也可以正常工作,但是从面向资源的角度来看这并不理想。在理想情况下,要识别的资源(Spittle)应该通过 URL 路径进行标示,而不是通过查询参数。对 “/spittles/12345” 发起 GET 请求要优于对 “/spittles/show?spittle_id=12345” 发起请求。前者能够识别出要查询的资源,而后者描述的是带有参数的一个操作——本质上是通过 HTTP 发起的RPC。
既然已经以面向资源的控制器作为目标,那我们将这个需求转换为一个测试。程序清单 5.12 展现了一个新的测试方法,它会断言 SpittleController 中对面向资源请求的处理。
1 | void testSpittle() throws Exception { Spittle expectedSpittle = new Spittle("Hello", new Date()); SpittleRepository mockRepository = mock(SpittleRepository.class); when(mockRepository.findOne(12345)).thenReturn(expectedSpittle); SpittleController controller = new SpittleController(mockRepository); MockMvc mockMvc = standaloneSetup(controller).build(); mockMvc.perform(get("/spittles/12345")) .andExpect(view().name("spittle")) .andExpect(model().attributeExists("spittle")) .andExpect(model().attribute("spittle", expectedSpittle));} |
可以看到,这个测试构建了一个 mock Repository、一个控制器和 MockMvc,这与本章中我们所编写的其他测试很类似。这个测试中最重要的部分是最后几行,它对 “/spittles/12345” 发起 GET 请求,然后断言视图的名称是 spittle,并且预期的 Spittle 对象放到了模型之中。因为我们还没有为这种请求实现处理器方法,因此这个请求将会失败。但是,我们可以通过为 SpittleController 添加新的方法来修正这个失败的测试。
到目前为止,在我们编写的控制器中,所有的方法都映射到了(通过 @RequestMapping)静态定义好的路径上。但是,如果想让这个测试通过的话,我们编写的 @RequestMapping 要包含变量部分,这部分代表了 Spittle ID。
为了实现这种路径变量,Spring MVC 允许我们在 @RequestMapping 路径中添加占位符。占位符的名称要用大括号(“{” 和 “}”)括起来。路径中的其他部分要与所处理的请求完全匹配,但是占位符部分可以是任意的值。
下面的处理器方法使用了占位符,将 Spittle ID 作为路径的一部分:
1 | public String spittle( long spittleId, Model model) { model.addAttribute(spittleRepository.findOne(spittleId)); return "spittle";} |
例如,它就能够处理针对 “/spittles/12345” 的请求,也就是程序清单 5.12 中的路径我们可以看到,spittle() 方法的 spittleId 参数上添加了 @PathVariable("spittleId") 注解,这表明在请求路径中,不管占位符部分的值是什么都会传递到处理器方法的 spittleId 参数中。如果对 “/spittles/54321” 发送 GET 请求,那么将会把 “54321” 传递进来,作为 spittleId 的值。
需要注意的是:在样例中 spittleId 这个词出现了好几次:先是在 @RequestMapping 的路径中,然后作为 @PathVariable 属性的值,最后又作为方法的参数名称。因为方法的参数名碰巧与占位符的名称相同,因此我们可以去掉 @PathVariable 中的 value 属性:
1 | public String spittle( long spittleId, Model model) { model.addAttribute(spittleRepository.findOne(spittleId)); return "spittle";} |
如果 @PathVariable 中没有 value 属性的话,它会假设占位符的名称与方法的参数名相同。这能够让代码稍微简洁一些,因为不必重复写占位符的名称了。但需要注意的是,如果你想要重命名参数时,必须要同时修改占位符的名称,使其互相匹配。
spittle() 方法会将参数传递到 SpittleRepository 的 findOne() 方法中,用来获取某个 Spittle 对象,然后将 Spittle 对象添加到模型中。模型的 key 将会是 spittle,这是根据传递到 addAttribute() 方法中的类型推断得到的。
这样 Spittle 对象中的数据就可以渲染到视图中了,此时需要引用请求中 key 为 spittle 的属性(与模型的 key 一致)。如下为渲染 Spittle 的 JSP 视图片段:
1 | <div class="spittleView"> <div class="spittleMessage"><c:out value="${spittle.message}" /></div> <div> <span class="spittleTime"><c:out value="${spittle.time}" /></span> </div></div> |
这个视图并没有什么特别之处,它的屏幕截图如图 5.4 所示。
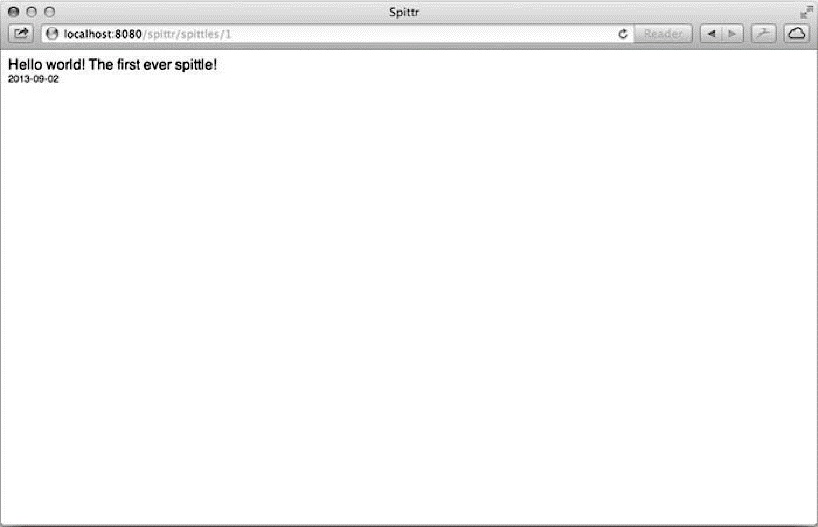
如果传递请求中少量的数据,那查询参数和路径变量是很合适的。但通常我们还需要传递很多的数据(也许是表单提交的数据),那查询参数显得有些笨拙和受限了。下面让我们来看一下如何编写控制器方法来处理表单提交。
处理表单
Web 应用的功能通常并不局限于为用户推送内容。大多数的应用允许用户填充表单并将数据提交回应用中,通过这种方式实现与用户的交互。像提供内容一样, Spring MVC 的控制器也为表单处理提供了良好的支持。
使用表单分为两个方面:展现表单以及处理用户通过表单提交的数据。在 Spittr 应用中,我们需要有个表单让新用户进行注册。SpitterController 是一个新的控制器,目前只有一个请求处理的方法来展现注册表单。
1 | package spittr.web;import static org.springframework.web.bind.annotation.RequestMethod.*;import javax.validation.Valid;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Controller;import org.springframework.ui.Model;import org.springframework.validation.Errors;import org.springframework.web.bind.annotation.PathVariable;import org.springframework.web.bind.annotation.RequestMapping;import spittr.Spitter;import spittr.data.SpitterRepository;public class SpitterController { public String showRegistrationForm() { return "registerForm"; }} |
showRegistrationForm() 方法的 @RequestMapping 注解以及类级别上的 @RequestMapping 注解组合起来,声明了这个方法要处理的是针对 “/spitter/register” 的 GET 请求。这是一个简单的方法,没有任何输入并且只是返回名为 registerForm 的逻辑视图。按照我们配置InternalResourceViewResolver的方式,这意味着将会使用 “/WEB-INF/ views/registerForm.jsp” 这个 JSP 来渲染注册表单。
尽管 showRegistrationForm() 方法非常简单,但测试依然需要覆盖到它。因为这个方法很简单,所以它的测试也比较简单。
1 | void shouldShowRegistration() throws Exception { SpitterRepository mockRepository = mock(SpitterRepository.class); SpitterController controller = new SpitterController(mockRepository); MockMvc mockMvc = standaloneSetup(controller).build(); mockMvc.perform(get("/spitter/register")) .andExpect(view().name("registerForm"));} |
这个测试方法与首页控制器的测试非常类似。它对 “/spitter/register” 发送GET请求,然后断言结果的视图名为 registerForm。
现在,让我们回到视图上。因为视图的名称为 registerForm,所以 JSP 的名称需要是 registerForm.jsp。这个 JSP 必须要包含一个 HTML <form> 标签,在这个标签中用户输入注册应用的信息。如下就是我们现在所要使用的 JSP。
1 | <%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %><%@ page session="false" %><html> <head> <title>Spitter</title> <link rel="stylesheet" type="text/css" href="<c:url value="/resources/style.css" />" > </head> <body> <h1>Register</h1> <form method="POST"> First Name: <input type="text" name="firstName" /><br/> Last Name: <input type="text" name="lastName" /><br/> Email: <input type="email" name="email" /><br/> Username: <input type="text" name="username" /><br/> Password: <input type="password" name="password" /><br/> <input type="submit" value="Register" /> </form> </body></html> |
可以看到,这个 JSP 非常基础。它的 HTML 表单域中记录用户的名字、姓氏、用户名以及密码,然后还包含一个提交表单的按钮。在浏览器渲染之后,它的样子大致如图 5.5 所示。
需要注意的是:这里的 <form> 标签中并没有设置 action 属性。在这种情况下,当表单提交时,它会提交到与展现时相同的 URL 路径上。也就是说,它会提交到 “/spitter/register” 上。
这就意味着需要在服务器端处理该 HTTP POST 请求。现在,我们在 Spitter-Controller 中再添加一个方法来处理这个表单提交。
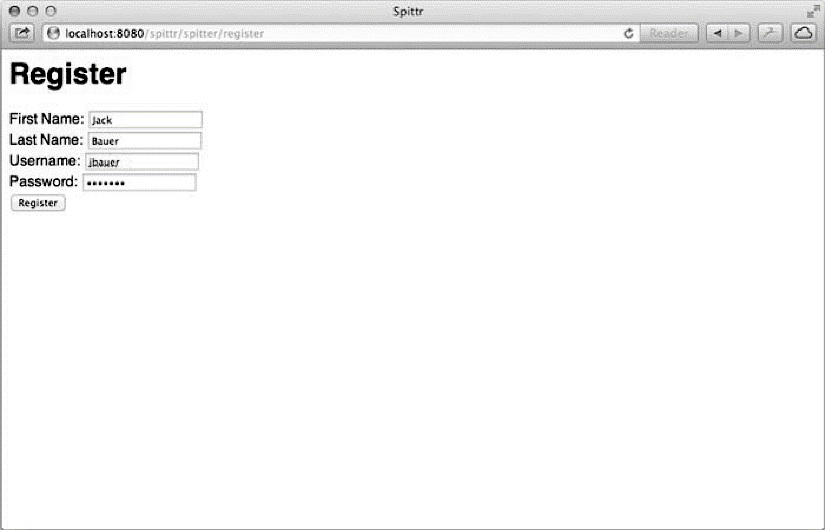
编写处理表单的控制器
当处理注册表单的 POST 请求时,控制器需要接受表单数据并将表单数据保存为 Spitter 对象。最后,为了防止重复提交(用户点击浏览器的刷新按钮有可能会发生这种情况),应该将浏览器重定向到新创建用户的基本信息页面。这些行为通过下面的 shouldProcessRegistration() 进行了测试。
1 | void shouldProcessRegistration() throws Exception { SpitterRepository mockRepository = mock(SpitterRepository.class); Spitter unsaved = new Spitter("jbauer", "24hours", "Jack", "Bauer", "jbauer@ctu.gov"); Spitter saved = new Spitter(24L, "jbauer", "24hours", "Jack", "Bauer", "jbauer@ctu.gov"); when(mockRepository.save(unsaved)).thenReturn(saved); SpitterController controller = new SpitterController(mockRepository); MockMvc mockMvc = standaloneSetup(controller).build(); mockMvc.perform(post("/spitter/register") .param("firstName", "Jack") .param("lastName", "Bauer") .param("username", "jbauer") .param("password", "24hours") .param("email", "jbauer@ctu.gov")) .andExpect(redirectedUrl("/spitter/jbauer")); verify(mockRepository, atLeastOnce()).save(unsaved);} |
显然,这个测试比展现注册表单的测试复杂得多。在构建完 SpitterRepository 的 mock 实现以及所要执行的控制器和 MockMvc 之后, shouldProcessRegistration() 对 “/spitter/register” 发起了一个POST请求。作为请求的一部分,用户信息以参数的形式放到 request 中,从而模拟提交的表单。
在处理 POST 类型的请求时,在请求处理完成后,最好进行一下重定向,这样浏览器的刷新就不会重复提交表单了。在这个测试中,预期请求会重定向到 “/spitter/jbauer”,也就是新建用户的基本信息页面。
最后,测试会校验 SpitterRepository 的 mock 实现最终会真正用来保存表单上传入的数据。
现在,我们来实现处理表单提交的控制器方法。通过 shouldProcess-Registration() 方法,我们可能认为要满足这个需求需要做很多的工作。但是,在如下的程序清单中,我们可以看到新的 SpitterController 并没有做太多的事情。
1 | package spittr.web;import static org.springframework.web.bind.annotation.RequestMethod.*;import javax.validation.Valid;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Controller;import org.springframework.ui.Model;import org.springframework.validation.Errors;import org.springframework.web.bind.annotation.PathVariable;import org.springframework.web.bind.annotation.RequestMapping;import spittr.Spitter;import spittr.data.SpitterRepository;public class SpitterController { private SpitterRepository spitterRepository; public SpitterController(SpitterRepository spitterRepository) { this.spitterRepository = spitterRepository; } public String showRegistrationForm() { return "registerForm"; } public String processRegistration(Spitter spitter) { spitterRepository.save(spitter); return "redirect:/spitter/" + spitter.getUsername(); }} |
我们之前创建的 showRegistrationForm() 方法依然还在,不过请注意新创建的 processRegistration() 方法,它接受一个 Spitter 对象作为参数。这个对象有 firstName、lastName、username 和 password 属性,这些属性将会使用请求中同名的参数进行填充。
当使用 Spitter 对象调用 processRegistration() 方法时,它会进而调用 SpitterRepository 的 save() 方法,SpitterRepository 是在 SpitterController 的构造器中注入进来的。
processRegistration() 方法做的最后一件事就是返回一个 String 类型,用来指定视图。但是这个视图格式和以前我们所看到的视图有所不同。这里不仅返回了视图的名称供视图解析器查找目标视图,而且返回的值还带有重定向的格式。
当 InternalResourceViewResolver 看到视图格式中的 “redirect:” 前缀时,它就知道要将其解析为重定向的规则,而不是视图的名称。在本例中,它将会重定向到用户基本信息的页面。例如,如果 Spitter.username 属性的值为 “jbauer”,那么视图将会重定向到 “/spitter/jbauer”。
需要注意的是,除了 “redirect:”,InternalResourceViewResolver 还能识别 “forward:” 前缀。当它发现视图格式中以 “forward:” 作为前缀时,请求将会前往(forward)指定的URL路径,而不再是重定向。
万事俱备!现在,程序清单 5.16 中的测试应该能够通过了。但是,我们的任务还没有完成,因为我们重定向到了用户基本信息页面,那么我们应该往 SpitterController 中添加一个处理器方法,用来处理对基本信息页面的请求。如下的 showSpitterProfile() 将会完成这项任务:
1 | public String showSpitterProfile( String username, Model model) { Spitter spitter = spitterRepository.findByUsername(username); model.addAttribute(spitter); return "profile";} |
SpitterRepository 通过用户名获取一个 Spitter 对象,showSpitterProfile() 得到这个对象并将其添加到模型中,然后返回 profile,也就是基本信息页面的逻辑视图名。像本章展现的其他视图一样,现在的基本信息视图非常简单:
1 | <h1>Your Profile</h1><c:out value="${spitter.username}" /><br/><c:out value="${spitter.firstName}" /> <c:out value="${spitter.lastName}" /><br/><c:out value="${spitter.email}" /> |
图 5.6 展现了在 Web 浏览器中渲染的基本信息页面。
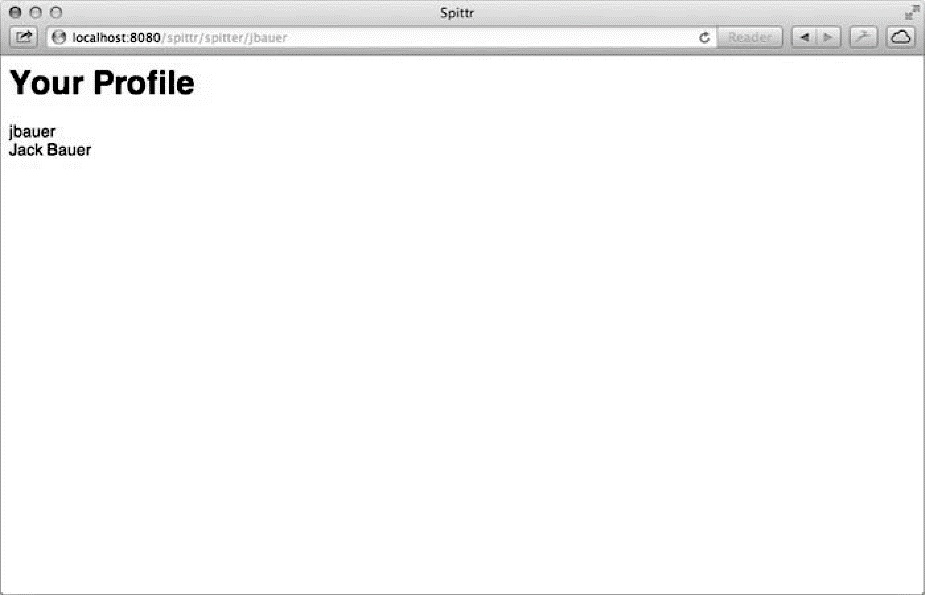
如果表单中没有发送 username 或 password 的话,会发生什么情况呢?或者说,如果 firstName 或 lastName 的值为空或太长的话,又会怎么样呢?接下来,让我们看一下如何为表单提交添加校验,从而避免数据呈现的不一致性。
校验表单
如果用户在提交表单的时候,username 或 password 文本域为空的话,那么将会导致在新建 Spitter 对象中,username 或 password 是空的 String。至少这是一种怪异的行为。如果这种现象不处理的话,这将会出现安全问题,因为不管是谁只要提交一个空的表单就能登录应用。
同时,我们还应该阻止用户提交空的 firstName 和 / 或 lastName,使应用仅在一定程度上保持匿名性。有个好的办法就是限制这些输入域值的长度,保持它们的值在一个合理的长度范围,避免这些输入域的误用。
有种处理校验的方式非常初级,那就是在 processRegistration() 方法中添加代码来检查值的合法性,如果值不合法的话,就将注册表单重新显示给用户。这是一个很简短的方法,因此,添加一些额外的 if 语句也不是什么大问题,对吧?
与其让校验逻辑弄乱我们的处理器方法,还不如使用 Spring 对 Java 校验 API(Java Validation API,又称 JSR-303)的支持。从 Spring 3.0 开始,在 Spring MVC 中提供了对 Java 校验 API 的支持。在 Spring MVC 中要使用 Java 校验 API 的话,并不需要什么额外的配置。只要保证在类路径下包含这个 Java API 的实现即可,比如 Hibernate Validator。
Java校验 API 定义了多个注解,这些注解可以放到属性上,从而限制这些属性的值。所有的注解都位于 javax.validation.constraints 包中。表 5.1 列出了这些校验注解。
| 注 解 | 描 述 |
|---|---|
| @AssertFalse | 所注解的元素必须是 Boolean 类型,并且值为 false |
| @AssertTrue | 所注解的元素必须是 Boolean 类型,并且值为 true |
| @DecimalMax | 所注解的元素必须是数字,并且它的值要小于或等于给定的 BigDecimalString 值 |
| @DecimalMin | 所注解的元素必须是数字,并且它的值要大于或等于给定的 BigDecimalString 值 |
| @Digits | 所注解的元素必须是数字,并且它的值必须有指定的位数 |
| @Future | 所注解的元素的值必须是一个将来的日期 |
| @Max | 所注解的元素必须是数字,并且它的值要小于或等于给定的值 |
| @Min | 所注解的元素必须是数字,并且它的值要大于或等于给定的值 |
| @NotNull | 所注解元素的值必须不能为 null |
| @Null | 所注解元素的值必须为 null |
| @Past | 所注解的元素的值必须是一个已过去的日期 |
| @Pattern | 所注解的元素的值必须匹配给定的正则表达式 |
| @Size | 所注解的元素的值必须是 String、集合或数组,并且它的长度要符合给定的范围 |
除了表 5.1 中的注解,Java 校验 API 的实现可能还会提供额外的校验注解。同时,也可以定义自己的限制条件。但就我们来讲,将会关注于上表中的两个核心限制条件。
请考虑要添加到 Spitter 域上的限制条件,似乎需要使用 @NotNull 和 @Size 注解。我们所要做的事情就是将这些注解添加到 Spitter 的属性上。如下的程序清单展现了 Spitter 类,它的属性已经添加了校验注解。
1 | package spittr;import javax.validation.constraints.NotNull;import javax.validation.constraints.Size;import org.apache.commons.lang3.builder.EqualsBuilder;import org.apache.commons.lang3.builder.HashCodeBuilder;import org.hibernate.validator.constraints.Email;public class Spitter { private Long id; private String username; private String password; private String firstName; private String lastName; private String email; ...} |
现在,Spitter 的所有属性都添加了 @NotNull 注解,以确保它们的值不为 null。类似地,属性上也添加了 @Size 注解以限制它们的长度在最大值和最小值之间。对 Spittr 应用来说,这意味着用户必须要填完注册表单,并且值的长度要在给定的范围内。
我们已经为 Spitter 添加了校验注解,接下来需要修改 processRegistration() 方法来应用校验功能。启用校验功能的 processRegistration() 如下所示:
1 | public String processRegistration( Spitter spitter, Errors errors) { if (errors.hasErrors()) { return "registerForm"; } spitterRepository.save(spitter); return "redirect:/spitter/" + spitter.getUsername(); } |
与程序清单 5.17 中最初的 processRegistration() 方法相比,这里有了很大的变化。Spitter 参数添加了 @Valid 注解,这会告知 Spring,需要确保这个对象满足校验限制。
在 Spitter 属性上添加校验限制并不能阻止表单提交。即便用户没有填写某个域或者某个域所给定的值超出了最大长度,processRegistration() 方法依然会被调用。这样,我们就需要处理校验的错误,就像在 processRegistration() 方法中所看到的那样。
如果有校验出现错误的话,那么这些错误可以通过 Errors 对象进行访问,现在这个对象已作为 processRegistration() 方法的参数。(很重要一点需要注意, Errors 参数要紧跟在带有 @Valid 注解的参数后面,@Valid 注解所标注的就是要检验的参数。)processRegistration() 方法所做的第一件事就是调用 Errors.hasErrors() 来检查是否有错误。
如果有错误的话,Errors.hasErrors() 将会返回到 registerForm,也就是注册表单的视图。这能够让用户的浏览器重新回到注册表单页面,所以他们能够修正错误,然后重新尝试提交。现在,会显示空的表单,但是在下一章中,我们将在表单中显示最初提交的值并将校验错误反馈给用户。
如果没有错误的话,Spitter 对象将会通过 Repository 进行保存,控制器会像之前那样重定向到基本信息页面。
小结
在本章中,我们为编写应用程序的 Web 部分开了一个好头。可以看到,Spring 有一个强大灵活的 Web 框架。借助于注解,Spring MVC 提供了近似于 POJO 的开发模式,这使得开发处理请求的控制器变得非常简单,同时也易于测试。
当编写控制器的处理器方法时,Spring MVC 极其灵活。概括来讲,如果你的处理器方法需要内容的话,只需将对应的对象作为参数,而它不需要的内容,则没有必要出现在参数列表中。这样,就为请求处理带来了无限的可能性,同时还能保持一种简单的编程模型。
尽管本章中的很多内容都是关于控制器的请求处理的,但是渲染响应同样也是很重要的。我们通过使用 JSP 的方式,简单了解了如何为控制器编写视图。但是就 Spring MVC 的视图来说,它并不限于本章所看到的简单 JSP。
在接下来的第 6 章中,我们将会更深入地学习 Spring 视图,包括如何在 JSP 中使用 Spring 标签库。我们还会学习如何借助 Apache Tiles 为视图添加一致的布局结构。同时,还会了解 Thymeleaf,这是一个很有意思的 JSP 替代方案,Spring 为其提供了内置的支持。
渲染Web视图
本章内容:
- 将模型数据渲染为 HTML
- 使用
JSP视图 - 通过 tiles 定义视图布局
- 使用 Thymeleaf 视图
上一章主要关注于如何编写处理 Web 请求的控制器。我们也创建了一些简单的视图,用来渲染控制器产生的模型数据,但我们并没有花太多时间讨论视图,也没有讨论控制器完成请求到结果渲染到用户的浏览器中的这段时间内到底发生了什么,而这正是本章的主要内容。
理解视图解析
在第 5 章中,我们所编写的控制器方法都没有直接产生浏览器中渲染所需的 HTML。这些方法只是将一些数据填充到模型中,然后将模型传递给一个用来渲染的视图。这些方法会返回一个 String 类型的值,这个值是视图的逻辑名称,不会直接引用具体的视图实现。尽管我们也编写了几个简单的 Java Server Page(JSP)视图,但是控制器并不关心这些。
将控制器中请求处理的逻辑和视图中的渲染实现解耦是 Spring MVC 的一个重要特性。如果控制器中的方法直接负责产生 HTML 的话,就很难在不影响请求处理逻辑的前提下,维护和更新视图。控制器方法和视图的实现会在模型内容上达成一致,这是两者的最大关联,除此之外,两者应该保持足够的距离。
但是,如果控制器只通过逻辑视图名来了解视图的话,那 Spring 该如何确定使用哪一个视图实现来渲染模型呢?这就是 Spring 视图解析器的任务了。
在第 5 章中,我们使用名为 InternalResourceViewResolver 的视图解析器。在它的配置中,为了得到视图的名字,会使用 “/WEB-INF/views/” 前缀和 “.jsp” 后缀,从而确定来渲染模型的 JSP 文件的物理位置。现在,我们回过头来看一下视图解析的基础知识以及 Spring 提供的其他视图解析器。
Spring MVC 定义了一个名为 ViewResolver 的接口,它大致如下所示:
1 | public interface ViewResolver { View resolveViewName(String viewName, Local local) throws Exception;} |
当给 resolveViewName() 方法传入一个视图名和 Locale 对象时,它会返回一个 View 实例。View 是另外一个接口,如下所示:
1 | public interface View { String getContentType(); void render(Map<String, ?> model, HttpServletRequest, request, HttpServletResponse response) throws Exception;} |
View 接口的任务就是接受模型以及 Servlet 的 request 和 response 对象,并将输出结果渲染到 response 中。
这看起来非常简单。我们所需要做的就是编写 ViewResolver 和 View 的实现,将要渲染的内容放到 response 中,进而展现到用户的浏览器中。对吧?
实际上,我们并不需要这么麻烦。尽管我们可以编写 ViewResolver 和 View 的实现,在有些特定的场景下,这样做也是有必要的,但是一般来讲,我们并不需要关心这些接口。我在这里提及这些接口只是为了让你对视图解析内部如何工作有所了解。Spring 提供了多个内置的实现,如表 6.1 所示,它们能够适应大多数的场景 。
| 视图解析器 | 描 述 |
|---|---|
BeanNameViewResolver |
将视图解析为 Spring 应用上下文中的 bean,其中 bean 的 ID 与视图的名字相同 |
ContentNegotiatingViewResolver |
通过考虑客户端需要的内容类型来解析视图,委托给另外一个能够产生对应内容类型的视图解析器 |
FreeMarkerViewResolver |
将视图解析为 FreeMarker 模板 |
InternalResourceViewResolver |
将视图解析为 Web 应用的内部资源(一般为 JSP) |
JasperReportsViewResolver |
将视图解析为 JasperReports 定义 |
ResourceBundleViewResolver |
将视图解析为资源 bundle(一般为属性文件) |
TilesViewResolver |
将视图解析为 Apache Tile 定义,其中tile ID与视图名称相同。注意有两个不同的 TilesViewResolver 实现,分别对应于Tiles 2.0 和 Tiles 3.0 |
UrlBasedViewResolver |
直接根据视图的名称解析视图,视图的名称会匹配一个物理视图的定义 |
VelocityLayoutViewResolver |
将视图解析为 Velocity 布局,从不同的Velocity模板中组合页面 |
VelocityViewResolver |
将视图解析为 Velocity 模板 |
XmlViewResolver |
将视图解析为特定 XML 文件中的 bean 定义。类似于 BeanNameViewResolver |
XsltViewResolver |
将视图解析为 XSLT 转换后的结果 |
Spring 4 和 Spring 3.2 支持表 6.1中 的所有视图解析器。Spring 3.1 支持除 Tiles 3 TilesViewResolver 之外的所有视图解析器。
我们没有足够的篇幅介绍 Spring 所提供的 13 种视图解析器。这其实也没什么,因为在大多数应用中,我们只会用到其中很少的一部分。
对于表 6.1 中的大部分视图解析器来讲,每一项都对应 Java Web 应用中特定的某种视图技术。InternalResourceViewResolver 一般会用于 JSP, TilesViewResolver 用于 Apache Tiles 视图,而 FreeMarkerViewResolver 和 VelocityViewResolver 分别对应 FreeMarker 和 Velocity 模板视图。
在本章中,我们将会关注与大多数 Java 开发人员最息息相关的视图技术。因为大多数 Java Web 应用都会用到 JSP,我们首先将会介绍 InternalResourceViewResolver,这个视图解析器一般会用来解析 JSP 视图。接下来,我们将会介绍 TilesViewResolver,控制 JSP 页面的布局。
在本章的最后,我们将会看一个没有列在表 6.1 中的视图解析器。Thymeleaf 是一种用来替代 JSP 的新兴技术,Spring 提供了与 Thymeleaf 的原生模板(natural template)协作的视图解析器,这种模板之所以得到这样的称呼是因为它更像是最终产生的 HTML,而不是驱动它们的 Java 代码。Thymeleaf 是一种非常令人兴奋的视图方案,所以你尽可以先往后翻几页,去 6.4 节看一下在 Spring 中是如何使用它的。
如果你依然停留在本页的话,那么你可能知道 JSP 曾经是,而且现在依然还是 Java 领域占主导地位的视图技术。在以前的项目中,也许你使用过 JSP,将来有可能还会继续使用这项技术,所以接下来让我们看一下如何在 Spring MVC中使用 JSP 视图。
创建 JSP 视图
不管你是否相信,Java Server Pages 作为 Java Web 应用程序的视图技术已经超过 15 年了。尽管开始的时候它很丑陋,只是类似模板技术(如 Microsoft 的 Active Server Pages)的 Java 版本,但 JSP 这些年在不断进化,包含了对表达式语言和自定义标签库的支持。
Spring 提供了两种支持 JSP 视图的方式:
InternalResourceViewResolver会将视图名解析为JSP文件。另外,如果在你的JSP页面中使用了JSP标准标签库(Java Server Pages Standard Tag Library,JSTL)的话,InternalResourceViewResolver能够将视图名解析为JstlView形式的JSP文件,从而将JSTL本地化和资源 bundle 变量暴露给JSTL的格式化 (formatting)和信息(message)标签。- Spring 提供了两个
JSP标签库,一个用于表单到模型的绑定,另一个提供了通用的工具类特性。
不管你使用 JSTL,还是准备使用 Spring 的 JSP 标签库,配置解析 JSP 的视图解析器都是非常重要的。尽管 Spring 还有其他的几个视图解析器都能将视图名映射为 JSP 文件,但就这项任务来讲,InternalResourceViewResolver 是最简单和最常用的视图解析器。
我们在第 5 章已经接触到了如何配置 InternalResourceViewResolver。但是在那里,我们只是匆忙体验了一下,以便于查看控制器在浏览器中的效果。接下来,我们将会更加仔细地了解 InternalResourceViewResolver,看看如何让它完全听命于我们。
配置适用于 JSP 的视图解析器
有一些视图解析器,如 ResourceBundleViewResolver 会直接将逻辑视图名映射为特定的 View 接口实现,而 InternalResourceViewResolver 所采取的方式并不那么直接。它遵循一种约定,会在视图名上添加前缀和后缀,进而确定一个 Web 应用中视图资源的物理路径。
作为样例,考虑一个简单的场景,假设逻辑视图名为 home。通用的实践是将 JSP 文件放到 Web 应用的 WEB-INF 目录下,防止对它的直接访问。如果我们将所有的 JSP 文件都放在 “/WEB-INF/views/” 目录下,并且 home 页的 JSP 名为 home.jsp,那么我们可以确定物理视图的路径就是逻辑视图名 home 再加上 “/WEB-INF/views/” 前缀和 “.jsp” 后缀。如图 6.1 所示。
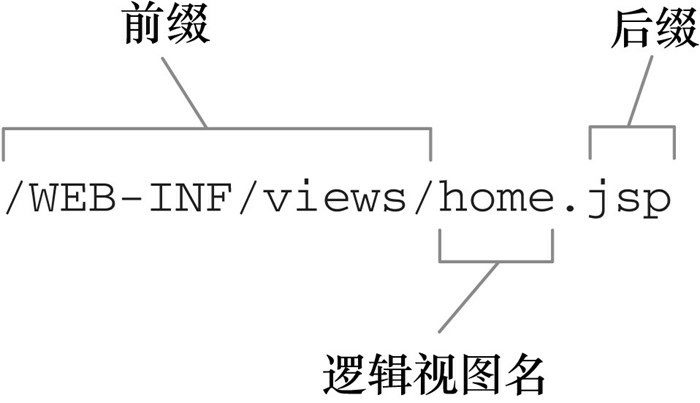
当使用 @Bean 注解的时候,我们可以按照如下的方式配置 InternalResourceViewResolver,使其在解析视图时,遵循上述的约定。
1 | ViewResolver viewResolver() { InternalResourceViewResolver resolver = new InternalResourceViewResolver(); resolver.setPrefix("WEB-INF/views"); resolver.setSuffix(".jsp"); return resolver;} |
作为替代方案,如果你更喜欢使用基于 XML 的 Spring 配置,那么可以按照如下的方式配置 InternalResourceViewResolver:
1 | <bean id="ViewResolver" class="org.springframework.web.servlet.view.InternalResourceViewResolver" P:prefix="WEB-INF/views" P:suffix=".jsp" |
InternalResourceViewResolver 配置就绪之后,它就会将逻辑视图名解析为 JSP 文件,如下所示:
home 将会解析为 “/WEB-INF/views/home.jsp”
productList 将会解析为 “/WEB-INF/views/productList.jsp”
books/detail 将会解析为 “/WEB-INF/views/books/detail.jsp”
让我们重点看一下最后一个样例。当逻辑视图名中包含斜线时,这个斜线也会带到资源的路径名中。因此,它会对应到 prefix属性所引用目录的子目录下的 JSP 文件。这样的话,我们就可以很方便地将视图模板组织为层级目录结构,而不是将它们都放到同一个目录之中。
解析 JSTL 视图
到目前为止,我们对 InternalResourceViewResolver 的配置都很基础和简单。它最终会将逻辑视图名解析为 InternalResourceView 实例,这个实例会引用 JSP文件。但是如果这些 JSP 使用 JSTL 标签来处理格式化和信息的话,那么我们会希望 InternalResourceViewResolver 将视图解析为 JstlView。
JSTL 的格式化标签需要一个 Locale 对象,以便于恰当地格式化地域相关的值,如日期和货币。信息标签可以借助 Spring 的信息资源和 Locale,从而选择适当的信息渲染到 HTML 之中。通过解析 JstlView,JSTL 能够获得 Locale 对象以及 Spring 中配置的信息资源。
如果想让 InternalResourceViewResolver 将视图解析为 JstlView,而不是 InternalResourceView 的话,那么我们只需设置它的 viewClass 属性即可
1 | ViewResolver viewResolver() { InternalResourceViewResolver resolver = new InternalResourceViewResolver(); resolver.setPrefix("WEB-INF/views/"); resolver.setSuffix(".jsp"); resolver.setViewClass(org.springframework.web.servlet.view.JstlView.class); return resovler;} |
同样,我们也可以使用XML完成这一任务:
1 | <bean id="viewResolver" class="org.springframework.web.servlewt.view.InternalResourceViewResolver" p:prefix="WEB-INF/view" p:suffix=".jsp" p:viewClass="org.springframework.web.servlet.view.JstlView"/> |
不管使用 Java 配置还是使用 XML,都能确保 JSTL 的格式化和信息标签能够获得 Locale 对象以及 Spring 中配置的信息资源。
使用 Spring 的 JSP 库
当为 JSP 添加功能时,标签库是一种很强大的方式,能够避免在脚本块中直接编写 Java 代码。Spring 提供了两个 JSP 标签库,用来帮助定义 Spring MVC Web 的视图。其中一个标签库会用来渲染 HTML 表单标签,这些标签可以绑定 model 中的某个属性。另外一个标签库包含了一些工具类标签,我们随时都可以非常便利地使用它们。
在这两个标签库中,你可能会发现表单绑定的标签库更加有用。所以,我们就从这个标签库开始学习 Spring 的 JSP 标签。我们将会看到如何将 Spittr 应用的注册表单绑定到模型上,这样表单就可以预先填充值,并且在表单提交失败后,能够展现校验错误。
将表单绑定到模型上
Spring的表单绑定 JSP 标签库包含了14个标签,它们中的大多数都用来渲染 HTML 中的表单标签。但是,它们与原生 HTML 标签的区别在于它们会绑定模型中的一个对象,能够根据模型中对象的属性填充值。标签库中还包含了一个为用户展现错误的标签,它会将错误信息渲染到最终的 HTML 之中。
为了使用表单绑定库,需要在 JSP 页面中对其进行声明:
1 | <%@ taglib url="http://www.springframework.org/tags/form" prefix="sf" %> |
需要注意,我将前缀指定为 “sf”,但通常也可能使用 “form” 前缀。你可以选择任意喜欢的前缀,我之所以选择 “sf” 是因为它很简洁、易于输入,并且还是 Spring form 的简写形式。在本书中,当使用表单绑定库的时候,我会一直使用“sf”前缀。
在声明完表单绑定标签库之后,你就可以使用 14 个相关的标签了。如表 6.2 所示。
| JSP 标签 | 描 述 |
|---|---|
<sf:checkbox> |
渲染成一个HTML <input> 标签,其中 type 属性设置为 checkbox |
<sf:checkboxes> |
渲染成多个HTML <input>标签,其中 type 属性设置为 checkbox |
<sf:errors> |
在一个HTML <span>中渲染输入域的错误 |
<sf:form> |
渲染成一个HTML <form>标签,并为其内部标签暴露绑定路径,用于数据绑定 |
<sf:hidden> |
渲染成一个HTML <input>标签,其中 type 属性设置为 hidden |
<sf:input> |
渲染成一个HTML <input>标签,其中 type 属性设置为 text |
<sf:label> |
渲染成一个HTML <label>标签 |
<sf:option> |
渲染成一个HTML <option>标签,其 selected 属性根据所绑定的值进行设置 |
<sf:options> |
按照绑定的集合、数组或Map,渲染成一个HTML <option>标签的列表 |
<sf:password> |
渲染成一个HTML <input>标签,其中 type 属性设置为 password |
<sf:radiobutton> |
渲染成一个HTML <input>标签,其中 type 属性设置为 radio |
<sf:radiobuttons> |
渲染成多个HTML <input>标签,其中 type 属性设置为 radio |
<sf:select> |
渲染为一个HTML <select>标签 |
<sf:textarea> |
渲染为一个HTML <textarea>标签 |
要在一个样例中介绍所有的这些标签是很困难的,如果一定要这样做的话,肯定也会非常牵强。就 Spittr 样例来说,我们只会用到适合于 Spittr 应用中注册表单的标签。具体来讲,也就是 <sf:form>、<sf:input> 和 <sf:password>。在注册 JSP 中使用这些标签后,所得到的程序如下所示:
1 | <sf:form method="POST" commandName="spitter"> First Name: <sf:input path="firstName" /><br/> Last Name: <sf:input path="lastName" /><br/> Email: <sf:input path="email" /><br/> Username: <sf:input path="username" /><br/> Password: <sf:password path="password" /><br/> <input type="submit" Value="Register" /></sf:form> |
<sf:form> 会渲染会一个 HTML <form> 标签,但它也会通过 commandName 属性构建针对某个模型对象的上下文信息。在其他的表单绑定标签中,会引用这个模型对象的属性。
在之前的代码中,我们将 commandName 属性设置为 spitter。因此,在模型中必须要有一个 key 为 spitter 的对象,否则的话,表单不能正常渲染(会出现 JSP 错误)。这意味着我们需要修改一下 SpitterController,以确保模型中存在以 spitter 为 key 的 Spitter 对象:
1 | public String showRegistrationForm(Model model) { model.addAttribute(new Spitter()); return "registerForm";} |
修改后的 showRegistrationForm() 方法中,新增了一个 Spitter 实例到模型中。模型中的 key 是根据对象类型推断得到的,也就是 spitter,与我们所需要的完全一致。
回到这个表单中,前四个输入域将 HTML <input>标签改成了<sf:input>。这个标签会渲染成一个 HTML <input>标签,并且 type 属性将会设置为 text。我们在这里设置了 path 属性,<input>标签的 value 属性值将会设置为模型对象中 path 属性所对应的值。例如,如果在模型中 Spitter 对象的 firstName 属性值为 Jack,那么 <sf:input path="firstName"/> 所渲染的 <input> 标签中,会存在 value=”Jack”。
对于 password 输入域,我们使用<sf:password>来代替 <sf:input>。<sf:password> 与 <sf:input> 类似,但是它所渲染的 HTML <input> 标签中,会将 type 属性设置为 password,这样当输入的时候,它的值不会直接明文显示。
为了帮助读者了解最终的 HTML 看起来是什么样子的,假设有个用户已经提交了表单,但值都是不合法的。校验失败后,用户会被重定向到注册表单,最终的HTML <form>元素如下所示:
1 | <form id="spitter" action="/spitter/spitter/register" method="POST"> First Name: <input id="firstName" name="firstName" type="text" value="J" /><br/> Last Name: <input id="lastName" name="lastName" type="text" value="B" /><br/> Email: <input id="email" name="email" type="text" value="jack" /><br/> Username: <input id="username" name="username" type="text" value="jack" /><br/> Password: <input id="password" name="password" type="password" value=""/><br/> <input type="submit" value="Register"/></form> |
值得注意的是,从 Spring 3.1 开始,<sf:input> 标签能够允许我们指定 type 属性,这样的话,除了其他可选的类型外,还能指定 HTML 5 特定类型的文本域,如 date、range 和 email。例如,我们可以按照如下的方式指定 email 域:
1 | Email: <sf:input path="email" type="email" /><br/> |
这样所渲染得到的 HTML 如下所示:
1 | Email: <input id="email" name="email" type="email" value="jack"/><br/> |
相对于标准的 HTML 标签,使用 Spring的表单绑定标签能够带来一定的功能提升,在校验失败后,表单中会预先填充之前输入的值。但是,这依然没有告诉用户错在什么地方。为了指导用户矫正错误,我们需要使用 <sf:errors>。
展现错误
如果存在校验错误的话,请求中会包含错误的详细信息,这些信息是与模型数据放到一起的。我们所需要做的就是到模型中将这些数据抽取出来,并展现给用户。<sf:errors> 能够让这项任务变得很简单。
例如,让我们看一下将 <sf:errors> 用到 registerForm.jsp 中的代码片段:
1 | <sf:form method="POST" commandName="spitter"> First Name: <sf:input path="firstName" /> <sf:errors path="firstName"/><br/> ...</sf:form> |
尽管我只展现了将 <sf:errors> 用到 First Name 输入域的场景,但是它可以按照同样简单的方式用到注册表单的其他输入域中。在这里,它的 path 属性设置成了 firstName,也就是指定了要显示 Spitter 模型对象中哪个属性的错误。如果 firstName 属性没有错误的话,那么 <sf:errors> 不会渲染任何内容。但如果有校验错误的话,那么它将会在一个 HTML <span> 标签中显示错误信息。
例如,如果用户提交字母 “J” 作为名字的话,那么如下的 HTML 片段就是针对 First Name 输入域所显示的内容:
1 | First Name:<input id="firstName" name="firstName" type="text" value="J"/><span id="firstName.errors">size must be between 2 and 30</span> |
现在,我们已经可以为用户展现错误信息,这样他们就能修正这些错误了。我们可以更进一步,修改错误的样式,使其更加突出显示。为了做到这一点,可以设置 cssClass 属性:
1 | <sf:form method="POST" commandName="spitter:"> First Name: <sf:input path="firstName" /> <sf:errors path="firstName" cssClass="error" /><br/> ...</sf:form> |
同样,简单起见,我只会展现如何为 firstName 输入域的 <sf:errors> 设置 cssClass 属性。你可以将其用到其他的输入域上。
现在 errors 的 <span> 会有一个值为 error 的 class 属性。剩下需要做的就是为这个类定义 CSS 样式。如下就是一个简单的 CSS 样式,它会将错误信息渲染为红色:图 6.2 展现了这个表单此时在浏览器中的显式效果。
1 | span.error { color: red;} |
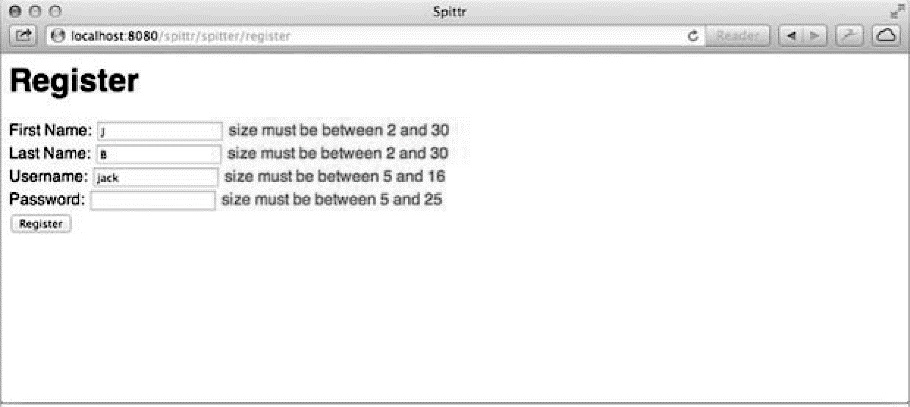
在输入域的旁边展现错误信息是一种很好的方式,这样能够引起用户的关注,提醒他们修正错误。但这样也会带来布局的问题。另外一种处理校验错误方式就是将所有的错误信息在同一个地方进行显示。为了做到这一点,我们可以移除每个输入域上的 <sf:errors> 元素,并将其放到表单的顶部,如下所示:
1 | <sf:form method="POST" commandName="spitter"> <sf:errors path="*" element="div" cssClass="errors" /> ...</sf:form> |
这个 <sf:errors> 与之前相比,值得注意的不同之处在于它的 path 被设置成了 “*”。这是一个通配符选择器,会告诉 <sf:errors> 展现所有属性的所有错误。
同样需要注意的是,我们将 element 属性设置成了 div。默认情况下,错误都会渲染在一个 HTML <span> 标签中,如果只显示一个错误的话,这是不错的选择。但是,如果要渲染所有输入域的错误的话,很可能要展现不止一个错误,这时候使用 <span> 标签(行内元素)就不合适了。像 <div> 这样的块级元素会更为合适。因此,我们可以将 element 属性设置为 div,这样的话,错误就会渲染在一个 <div> 标签中。
像之前一样,cssClass 属性被设置 errors,这样我们就能为 <div> 设置样式。如下为 <div> 的 CSS 样式,它具有红色的边框和浅红色的背景:
1 | div.errors { background-color: #ffcccc; border: 2px solid red;} |
现在,我们在表单的上方显示所有的错误,这样页面布局可能会更加容易一些。但是,我们还没有着重显示需要修正的输入域。通过为每个输入域设置 cssErrorClass 属性,这个问题很容易解决。我们也可以将每个 label 都替换为 <sf: label>,并设置它的 cssErrorClass 属性。如下就是做完必要修改后的 First Name 输入域:
1 | <sf:form method="POST" commandName="spitter"> <sf:label path="firstName" cssErrorClass="error">First Name</sf:label> <sf:input path="firstName" cssErrorClass="error"/><br/></sf:form> |
<sf: label> 标签像其他的表单绑定标签一样,使用 path 来指定它属于模型对象中的哪个属性。在本例中,我们将其设置为 firstName,因此它会绑定 Spitter 对象的 firstName 属性。假设没有校验错误的话,它将会渲染为如下的 HTML<label> 元素:
1 | <label for="firstName">First Name</label> |
就其自身来说,设置 <sf:label> 的 path 属性并没有完成太多的功能。但是,我们还同时设置了 cssErrorClass 属性。如果它所绑定的属性有任何错误的话,在渲染得到的 <label> 元素中,class 属性将会被设置为 error,如下所示:
1 | <label for="firstName" class="error">First Name</label> |
与之类似,<sf:input> 标签的 cssErrorClass 属性被设置为 error。如果有任何校验错误的话,在渲染得到的 <input> 标签中,class 属性将会被设置为 error。现在我们已经为文本标记和输入域设置了样式,这样当出现错误的时候,会将用户的注意力转移到此处。例如,如下的 CSS 会将文本标记渲染为红色,并将输入域设置为浅红色背景:
1 | label.error{ color: red;}input.error { background-color: #ffcccc;} |
现在,我们有了很好的方式为用户展现错误信息。不过,我们还可以做另外一件事情,能够让这些错误信息更加易读。重新看一下 Spitter 类,我们可以在校验注解上设置 message 属性,使其引用对用户更为友好的信息,而这些信息可以定义在属性文件中:
1 | private String username;private String password;private String firstName;private String lastName;private String email; |
对于上面每个域,我们都将其 @Size 注解的 message 设置为一个字符串,这个字符串是用大括号括起来的。如果没有大括号的话,message 中的值将会作为展现给用户的错误信息。但是使用了大括号之后,我们使用的就是属性文件中的某一个属性,该属性包含了实际的信息。
接下来需要做的就是创建一个名为 ValidationMessages.properties 的文件,并将其放在根类路径之下:
1 | =First name must be between {min} and {max} characters long.lastName.size=Last name must be between {min} and {max} characters long.username.size=Username must be between {min} and {max} characters long.password.size=Password must be between {min} and {max} characters long.email.valid=The email address must be valid. |
ValidationMessages.properties 文件中每条信息的 key 值对应于注解中 message 属性占位符的值。同时,最小和最大长度没有硬编码在
ValidationMessages.properties 文件中,在这个用户友好的信息中也有自己的占位符—— {min} 和 {max}——它们会引用 @Size 注解上所设置的 min 和 max 属性。
当用户提交的注册表单校验失败的话,他们在浏览器中应该可以看到图 6.3 所示的界面。
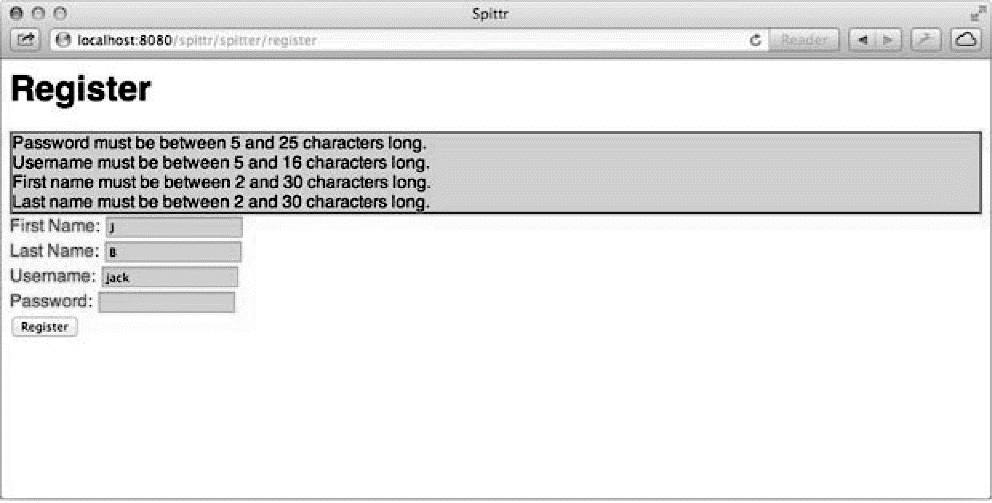
将这些错误信息抽取到属性文件中还会带来一个好处,那就是我们可以通过创建地域相关的属性文件,为用户展现特定语言和地域的信息。例如,如果用户的浏览器设置成了西班牙语,那么就应该用西班牙语展现错误信息,我们需要创建一个名为 ValidationErrors_es.properties 的文件,内容如下:
1 | =El nombre debe tener entre {min} y {max} caracteres largos.lastName.size=El apellido debe tener entre {min} y {max} caracteres largos.username.size=El nombre de usuario debe tener entre {min} y {max} caracteres.password.size=La contraseña debe tener entre {min} y {max} caracteres.email.valid=La dirección de correo electrónico debe ser válida. |
我们可以按需创建任意数量的 ValidationMessages.properties 文件,使其涵盖我们想支持的所有语言和地域。
Spring 通用的标签库
除了表单绑定标签库之外,Spring 还提供了更为通用的 JSP 标签库。实际上,这个标签库是 Spring 中最早的标签库。这么多年来,它有所变化,但是在最早版本的 Spring 中,它就已经存在了。
要使用 Spring 通用的标签库,我们必须要在页面上对其进行声明:
1 | <%@ taglib url="http://www.springframework.org/tags" prefix="s" %> |
与其他 JSP 标签库一样,prefix 可以是任意你所喜欢的值。在这里,通用的做法是将这个标签库的前缀设置为 spring。但是,我将其设置为 “s”,因为它更加简洁,更易于阅读和输入。
标签库声明之后,我们就可以使用表 6.3 中的十个 JSP 标签了。
JSP 标签 |
描 述 |
|---|---|
<s:bind> |
将绑定属性的状态导出到一个名为 status 的页面作用域属性中,与 <s:path> 组合使用获取绑定属性的值 |
<s:escapeBody> |
将标签体中的内容进行 HTML 和 / 或 JavaScript 转义 |
<s:hasBindErrors> |
根据指定模型对象(在请求属性中)是否有绑定错误,有条件地渲染内容 |
<s:htmlEscape> |
为当前页面设置默认的 HTML 转义值 |
<s:message> |
域或应用作用域的变量(通过使用 var 和 scope 属性实现) |
<s:nestedPath> |
设置嵌入式的 path,用于 <s:bind> 之中 |
<s:theme> |
根据给定的编码获取主题信息,然后要么进行渲染(默认行为),要么将其设置为页面作用域、请求作用域、会话作用域或应用作用域的变量(通过使用 var 和 scope 属性实现) |
<s:transform> |
使用命令对象的属性编辑器转换命令对象中不包含的属性 |
<s:url> |
创建相对于上下文的 URL,支持 URI 模板变量以及 HTML/XML/JavaScript 转义。可以渲染URL(默认行为),也可以将其设置为页面作用域、请求作用域、会话作用域或应用作用域的变量(通过使用 var 和 scope 属性实现) |
<s:eval> |
计算符合 Spring 表达式语言(Spring Expression Language,SpEL)语法的某个表达式的值,然后要么进行渲染(默认行为),要么将其设置为页面作用域、请求作用域、会话作用域或应用作用域的变量(通过使用 var 和 scope 属性实现) |
表 6.3 中的一些标签已经被 Spring 表单绑定标签库淘汰了。例如,<s:bind> 标签就是 Spring 最初所提供的表单绑定标签,它比我们在前面所介绍的标签复杂得多。
因为这些标签库的行为比表单绑定标签少得多,所以我不会详细介绍每个标签,而是快速介绍几个最为有用的标签,其余的留给读者自行去学习和探索。(即便你们会用到它们,很可能也不会那么频繁。)
展现国际化信息
到现在为止,我们的 JSP 模板包含了很多硬编码的文本。这其实也算不上什么大问题,但是如果你要修改这些文本的话,就不那么容易了。而且,没有办法根据用户的语言设置国际化这些文本。
例如,考虑首页中的欢迎信息:
1 | <h1> welcom to Spittr!</h1> |
修改这个信息的唯一办法是打开 home.jsp,然后对其进行变更。我觉得,这算不上什么大事。但是,应用中的文本散布到多个模板中,如果要大规模修改应用的信息时,你需要修改大量的 JSP 文件。
另外一个更为重要的问题在于,不管你选择什么样的欢迎信息,所有的用户都会看到同样的信息。Web 是全球性的网络,你所构建的应用很可能会有全球化用户。因此,最好能够使用用户的语言与其进行交流,而不是只使用某一种语言。
对于渲染文本来说,是很好的方案,文本能够位于一个或多个属性文件中。借助 <s:message>,我们可以将硬编码的欢迎信息替换为如下的形式:
1 | <h1> <s:message code="spittr.welcome"/></h1> |
按照这里的方式,<s:message> 将会根据 key 为 spittr.welcome 的信息源来渲染文本。因此,如果我们希望 <s:message> 能够正常完成任务的话,就需要配置一个这样的信息源。
Spring 有多个信息源的类,它们都实现了 MessageSource 接口。在这些类中,更为常见和有用的是 ResourceBundleMessageSource。它会从一个属性文件中加
载信息,这个属性文件的名称是根据基础名称(base name)衍生而来的。如下的 @Bean 方法配置了 ResourceBundleMessageSource:
1 | messageSource messageSource() { ResourceBundleMessageSource messageSource = new ResourceBundleMessageSource(); messageSource.setBasename("message"); return messageSource;} |
在这个 bean 声明中,核心在于设置 basename 属性。你可以将其设置为任意你喜欢的值,在这里,我将其设置为 message。将其设置为 message 后, ResourceBundleMessageSource 就会试图在根路径的属性文件中解析信息,这些属性文件的名称是根据这个基础名称衍生得到的。
另外的可选方案是使用 ReloadableResourceBundleMessageSource,它的工作方式与 ResourceBundleMessageSource 非常类似,但是它能够重新加载信息属性,而不必重新编译或重启应用。如下是配置 ReloadableResourceBundleMessageSource 的样例:
1 | MessageSource messageSource() { ReloadableResourceBundleMessageSource messageSource = new ReloadableResourceBundleMessageSource(); messageSource.setBasename("file:///etc/spittr/messages"); messageSource.setCacheSeconds(10); return messageSource;} |
这里的关键区别在于 basename 属性设置为在应用的外部查找(而不是像 ResourceBundleMessageSource 那样在类路径下查找)。basename 属性可以设置为在类路径下(以 “classpath:” 作为前缀)、文件系统中(以 “file:” 作为前缀)或 Web 应用的根路径下(没有前缀)查找属性。在这里,我将其配置为在服务器文件系统的 “/etc/spittr” 目录下的属性文件中查找信息,并且基础的文件名为 “message”。
现在,我们来创建这些属性文件。首先,创建默认的属性文件,名为 messages. properties。它要么位于根类路径下(如果使用 ResourceBundleMessageSource 的话),要么位于 pathname 属性指定的路径下(如果使用 ReloadableResourceBundleMessageSource 的话)。对 spittr.welcome 信息来讲,它需要如下的条目:
1 | =Welcome to Spittr! |
如果你不再创建其他信息文件的话,那么我们所做的事情就是将 JSP 中硬编码的信息抽取到了属性文件中,依然作为硬编码的信息。它能够让我们一站式地修改应用中的所有信息,但是它所完成的任务并不限于此。
我们已经具备了对信息进行国际化的重要组成部分。例如,如果你想要为语言设置为西班牙语的用户展现西班牙语的欢迎信息,那么需要创建另外一个名为 messages_es. properties 的属性文件,并包含如下的条目:
1 | =Bienvenidos a Spittr! |
现在,我们已经完成了一件了不起的事情。我们的应用目前只是多了几个 <s:message> 标签以及语言相关的属性文件,还没有完全实现国际化!我将应用其他部分的国际化留给读者去完成。
创建 URL
<s:url> 是一个很小的标签。它主要的任务就是创建 URL,然后将其赋值给一个变量或者渲染到响应中。它是 JSTL 中 <c:url> 标签的替代者,但是它具备几项特殊的技巧。
按照其最简单的形式,<s:url> 会接受一个相对于 Servlet 上下文的 URL,并在渲染的时候,预先添加上 Servlet 上下文路径。例如,考虑如下<s:url>的基本用法:
1 | <s:url href="/spitter/register/register" var="registerUrl" scope="request" /> |
如果希望在 URL 上添加参数的话,那么你可以使用<s:param>标签。比如,如下的<s:url>使用两个内嵌的<s:param>标签,来设置 “/spittles” 的 max 和 count 参数:
1 | <s:url href="/spittles" var="spittlesUrl"> <s:param name="max" value="60"/> <s:param name="count" value="20"/></s:url> |
到目前为止,我们还没有看到<s:url>能够实现,而 JSTL 的<c:url>无法实现的功能。但是,如果我们需要创建带有路径(path)参数的 URL 该怎么办呢?我们该如何设置 href 属性,使其具有路径变量的占位符呢?
例如,假设我们需要为特定用户的基本信息页面创建一个URL。那没有问题,<s:param>标签可以承担此任:
1 | <s:url href="/spitter/{username}" var="spitterUrl"> <s:param name="username" value="jbauer"/></s:url> |
当 href 属性中的占位符匹配 <s:param> 中所指定的参数时,这个参数将会插入到占位符的位置中。如果 <s:param> 参数无法匹配 href 中的任何占位符,那么这个参数将会作为查询参数。
<s:url> 标签还可以解决 URL 的转义需求。例如,如果你希望将渲染得到的 URL 内容展现在 Web 页面上(而不是作为超链接),那么你应该要求 <s:url> 进行 HTML 转义,这需要将 htmlEscape 属性设置为 true。例如,如下的 <s:url> 将会渲染 HTML 转义后的 URL:
1 | <s:url value="/spittles" htmlEscape="true"> <s:param name="max" value="60"/> <s:param name="count" value="20"/></s:url> |
所渲染的 URL 结果如下所示:
1 | /spitter/spittles?max=60&count=20 |
另一方面,如果你希望在 JavaScript 代码中使用 URL 的话,那么应该将 javaScriptEscape 属性设置为 true:
1 | <s:url value="/spittles" var="spittlesJSUrl" javaScriptEscape="true"> <s:param name="max" value="60"/> <s:param name="count" value="20"/></s:url><script> var spittlesUrl = "${spittlesJSUrl}"</script> |
这会渲染如下的结果到响应之中:
1 | <script> var spittlesUrl = "\/spitter\/spittles?max=60&count=20"</script> |
既然提到了转义,有一个标签专门用来转义内容,而不是转义标签。接下来,让我们看一下。
转义内容
<s:escapeBody> 标签是一个通用的转义标签。它会渲染标签体中内嵌的内容,并且在必要的时候进行转义。
例如,假设你希望在页面上展现一个 HTML 代码片段。为了正确显示,我们需要将 “<” 和 “>” 字符替换为 “<“ 和 “>”,否则的话,浏览器将会像解析页面上其他 HTML 那样解析这段 HTML 内容。
当然,没有人禁止我们手动将其转义为 “<“ 和 “>”,但是这很烦琐,并且代码难以阅读。我们可以使用 <s:escapeBody>,并让 Spring 完成这项任务:
1 | <s:escapeBody htmlEscape="true"> <h1> Hello </h1></s:escapeBody> |
它将会在响应体中渲染成如下的内容:
1 | <h1>Hello<> |
虽然转义后的格式看起来很难读,但浏览器会很乐意将其转换为未转义的HTML,也就是我们希望用户能够看到的样子。
通过设置 javaScriptEscape 属性,<s:escapeBody> 标签还支持 JavaScript 转义:
1 | <s:escapeBody javaScriptEscape="true"><h1>Hello</h1></s:escapeBody> |
<s:escapeBody> 只完成一件事,并且完成得非常好。与 <s:url> 不同,它只会渲染内容,并不能将内容设置为变量。
现在,我们已经看到了如何使用 JSP 来定义 Spring 视图,现在让我们考虑一下如何使其在审美上更加有吸引力。我们可以在页面上增加一些通用的元素,比如添加包含站点 Logo 的头部、使用样式并在底部展现版权信息。我们不会在 Spittr 应用中的每个 JSP 都进行这样的修改,而是借助 Apache Tiles 来为模板实现一些通用且可重用的布局。
使用 Apache Tiles 视图定义布局
到现在为止,我们很少关心应用中 Web 页面的布局问题。每个 JSP 完全负责定义自身的布局,在这方面其实这些 JSP 也没有做太多工作。
假设我们想为应用中的所有页面定义一个通用的头部和底部。最原始的方式就是查找每个 JSP 模板,并为其添加头部和底部的 HTML。但是这种方法的扩展性并不好,也难以维护。为每个页面添加这些元素会有一些初始成本,而后续的每次变更都会耗费类似的成本。
更好的方式是使用布局引擎,如 Apache Tiles,定义适用于所有页面的通用页面布局。Spring MVC 以视图解析器的形式为 Apache Tiles 提供了支持,这个视图解析器能够将逻辑视图名解析为 Tile 定义。
配置 Tiles 视图解析器
为了在 Spring 中使用 Tiles,需要配置几个 bean。我们需要一个 TilesConfigurer bean,它会负责定位和加载 Tile 定义并协调生成 Tiles。除此之外,还需要 TilesViewResolver bean 将逻辑视图名称解析为 Tile 定义。
这两个组件又有两种形式:针对 Apache Tiles 2 和 Apache Tiles 3 分别都有这么两个组件。这两组 Tiles 组件之间最为明显的区别在于包名。针对 Apache Tiles 2 的 TilesConfigurer/TilesViewResolver 位于 org.springframework.web.servlet.view.tiles2 包中,而针对 Tiles 3 的组件位于 org.springframework.web.servlet.view.tiles3 包中。对于该例子来讲,假设我们使用的是 Tiles 3。
首先,配置 TilesConfigurer 来解析 Tile 定义。
1 | TilesConfigurer tilesConfigurer() { TilesConfigurer tiles = new TilesConfigurer(); tiles.setDefinitions(new String[] {"/WEB-INF/layout/tiles.xml"}); tiles.setCheckRefresh(true); return tiles;} |
当配置 TilesConfigurer 的时候,所要设置的最重要的属性就是 definitions。这个属性接受一个 String 类型的数组,其中每个条目都指定一个 Tile 定义的 XML 文件。对于 Spittr 应用来讲,我们让它在 “/WEB-INF/layout/” 目录下查找 tiles.xml。
其实我们还可以指定多个 Tile 定义文件,甚至能够在路径位置上使用通配符,当然在上例中我们没有使用该功能。例如,我们要求 TilesConfigurer 加载 “/WEB-INF/” 目录下的所有名字为 tiles.xml 的文件,那么可以按照如下的方式设置 definitions 属性:
1 | titles.setDefinitions(new String[] {"WEB-INF/**/tiles.xml"}); |
在本例中,我们使用了 Ant 风格的通配符(**),所以 TilesConfigurer 会遍历 “WEB-INF/” 的所有子目录来查找 Tile 定义。
接下来,让我们来配置 TilesViewResolver,可以看到,这是一个很基本的 bean 定义,没有什么要设置的属性:
1 | ViewResolver viewResolver() { return new TilesViewResolver();} |
如果你更喜欢 XML 配置的话,那么可以按照如下的形式配置 TilesConfigurer 和 TilesViewResolver:
1 | <bean id="tilesConfigurer" class="org.springframework.web.servlet.view.tiles3.TilesConfigurer"> <property name="definitions"> <list> <value>/WEB-INF/layout/tiles.xml</value> <value>/WEB-INF/views/**/tiles.xml</value> </list> </property></bean><bean id="viewResolver" class="org.springframework.web.servlet.view.tiles3.TilesViewResolver"/> |
TilesConfigurer 会加载 Tile 定义并与 Apache Tiles 协作,而 TilesViewResolver 会将逻辑视图名称解析为引用 Tile 定义的视图。它是通过查找与逻辑视图名称相匹配的 Tile 定义实现该功能的。我们需要创建几个 Tile 定义以了解它是如何运转的。
定义 Tiles
Apache Tiles 提供了一个文档类型定义(document type definition,DTD),用来在 XML 文件中指定Tile的定义。每个定义中需要包含一个 <definition> 元素,这个元素会有一个或多个 <put-attribute> 元素。例如,如下的 XML 文档为 Spittr 应用定义了几个 Tiles。
1 | <tiles-definitions> <definition name="base" template="/WEB-INF/layout/page.jsp"> <put-attribute name="header" value="/WEB-INF/layout/header.jsp"/> <put-attribute name="footer" value="/WEB-INF/layout/footer.jsp"/> </definition> <definition name="home" extends="base"> <put-attribute name="body" value="/WEB-INF/views/home.jsp"/> </definition> <definition name="registerForm" extends="base"> <put-attribute name="body" value="/WEB-INF/views/registerForm.jsp"/> </definition> <definition name="profile" extends="base"> <put-attribute name="body" value="/WEB-INF/views/profile.jsp"/> </definition> <definition name="spittles" extends="base"> <put-attribute name="body" value="/WEB-INF/views/spittles.jsp"/> </definition> <definition name="spittle" extends="base"> <put-attribute name="body" value="/WEB-INF/view/spittle.jsp"/> </definition></tiles-definitions> |
每个 <definition> 元素都定义了一个 Tile,它最终引用的是一个 JSP 模板。在名为 base 的 Tile 中,模板引用的是 “/WEB-INF/layout/page.jsp”。某个 Tile 可能还会引用其他的 JSP 模板,使这些 JSP 模板嵌入到主模板中。对于 base Tile 来讲,它引用的是一个头部 JSP 模板和一个底部 JSP 模板。
base Tile 所引用的 page.jsp 模板如下面程序清单所示。
1 | <%@ taglib uri="http://www.springframework.org/tags" prefix="s" %><%@ taglib uri="http://tiles.apache.org/tags-tiles" prefix="t" %><%@ page session="false" %><html> <head> <titile>Spittr</titile> <link rel="stylesheet" type="text/css" href="<s:url value="/resource/style.css"/>"> </head> <body> <div id="header"> <t:insertAttribute name="header"/> </div> <div id="content"> <t:insertAttribute name="body"/> </div> <div id="footer"> <t:insertAttribute name="footer"/> </div> </body></html> |
<t:insertAttribute> JSP 标签来插入其他的模板。在这里,用它来插入名为 header、body 和 footer 的模板。最终,它会形成图 6.4 所示的布局。
在 base Tile 定义中,header 和 footer 属性分别被设置为引用 “/WEBINF/layout/ header. jsp” 和 “/WEB-INF/layout/footer.jsp”。但是 body 属性呢?它是在哪里设置的呢?
在这里,base Tile 不会期望单独使用。它会作为基础定义(这是其名字的来历),供其他的 Tile 定义扩展。在程序清单 6.2 的其余内容中,我们可以看到其他的 Tile 定义都是扩展自 base Tile。它意味着它们会继承其 header 和 footer 属性的设置(当然,Tile 定义中也可以覆盖掉这些属性),但是每一个都设置了 body 属性,用来指定每个 Tile 特有的 JSP 模板。
现在,我们关注一下 home Tile,它扩展了 base。因为它扩展了 base,因此它会继承 base 中的模板和所有的属性。尽管 home Tile 定义相对来说很简单,但是它实际上包含了如下的定义:
1 | <definition name="home" template="/WEB-INF/layout/page.jsp"> <put-attribute name="header" value="/WEB-INF/layout/header.jsp"/> <put-attribute name="footer" value="/WEB-INF/layout/footer.jsp"/> <put-attribute name="body" value="/WEB-INF/views/home.jsp"/></definition> |
属性所引用的每个模板是很简单的,如下是 header.jsp 模板:
1 | <%@ taglib uri="http://www.springframework.org/tags" prefix="s" %><a href="<s:url value="/"/>"><img src="<s:url value="/resources"/>/imgages/spittr_logo_50.png" border="0"/></a> |
footer.jsp 模板更为简单:
1 | Copyright © Craig Walls |
每个扩展自 base 的 Tile 都定义了自己的主体区模板,所以每个都会与其他的有所区别。但是为了完整地了解 home Tile,如下展现了 home.jsp:
1 | <%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %><%@ page session="false" %><h1> Welcome to Spittr</h1><a href="<c:url value="/spittles"/>">Spittles</a><a href="<c:url value="/spitter/register"/>">Register</a> |
这里的关键点在于通用的元素放到了 page.jsp、header.jsp 以及 footer.jsp 中,其他的 Tile 模板中不再包含这部分内容。这使得它们能够跨页面重用,这些元素的维护也得以简化。
要想看一下这些元素组合在一起的样子,那么可以看一下图 6.5。如图所示,它包含了一些样式和图像以增加应用的美观性。我们不是专门讨论使用 Tiles 实现页面布局的,因此在本节中不会涵盖所有的细节。但是,我们可以看到页面上的各种组件通过 Tile 定义组合在了一起,并且渲染出了 Spittr 应用的主页。
在 Java Web 应用领域,JSP 长期以来都是占据主导地位的方案。但是,在这个领域有了新的竞争者,也就是 Thymeleaf。接下来让我们看一下如何在 Spring MVC 应用中使用 Thymeleaf。
使用 Thymeleaf
尽管 JSP 已经存在了很长的时间,并且在 Java Web 服务器中无处不在,但是它却存在一些缺陷。JSP 最明显的问题在于它看起来像 HTML 或 XML,但它其实上并不是。大多数的 JSP 模板都是采用 HTML 的形式,但是又掺杂上了各种 JSP 标签库的标签,使其变得很混乱。
这些标签库能够以很便利的方式为 JSP 带来动态渲染的强大功能,但是它也摧毁了我们想维持一个格式良好的文档的可能性。作为一个极端的样例,如下的 JSP 标签甚至作为 HTML 参数的值:
1 | <input type="text" value="<c:out value="${thing.name}"/>"/> |
标签库和 JSP 缺乏良好格式的一个副作用就是它很少能够与其产生的 HTML 类似。所以,在 Web 浏览器或 HTML 编辑器中查看未经渲染的 JSP 模板是非常令人困惑的,而且得到的结果看上去也非常丑陋。这个结果是不完整的——在视觉上这简直就是一场灾难!因为 JSP 并不是真正的 HTML,很多浏览器和编辑器展现的效果都很难在审美上接近模板最终所渲染出来的效果。
同时,JSP 规范是与 Servlet 规范紧密耦合的。这意味着它只能用在基于 Servlet 的 Web 应用之中。JSP 模板不能作为通用的模板(如格式化 Email),也不能用于非 Servlet 的 Web 应用。
多年来,在 Java 应用中,有多个项目试图挑战 JSP 在视图领域的统治性地位。最新的挑战者是 Thymeleaf,它展现了一些切实的承诺,是一项很令人兴奋的可选方案。Thymeleaf 模板是原生的,不依赖于标签库。它能在接受原始 HTML 的地方进行编辑和渲染。因为它没有 与Servlet 规范耦合,因此 Thymeleaf 模板能够进入 JSP 所无法涉足的领域。现在,我们看一下如何在 Spring MVC 中使用 Thymeleaf。
配置 Thymeleaf 视图解析器
为了要在 Spring 中使用 Thymeleaf,我们需要配置三个启用 Thymeleaf 与 Spring 集成的 bean:
- ThymeleafViewResolver:将逻辑视图名称解析为 Thymeleaf 模板视图;
- SpringTemplateEngine:处理模板并渲染结果;
- TemplateResolver:加载Thymeleaf模板。
如下为声明这些 bean 的 Java 配置。
1 | ViewResolver viewResolver(SpringTemplateEngine templateEngine) { ThymeleafViewResolver viewResolver = new ThymeleafViewResolver(); // thymeleaf 视图解析器 viewResolver.setTemplateEngine(templateEngine); return viewResolver;}@Beanpublic SpringTemplateEngine templateEngine(TemplateResolver templateResolver) { SpringTemplateEngine templateEngine = new SpringTemplateEngine(); // 模板引擎 templateEngine.setTemplateResolver(templateResolver); return templateEngine;}@Beanpublic TemplateResolver templateResolver() { TemplateResolver templateResolver = new ServletContextTemplateResolver(); // 模板解析器 templateResolver.setPrefix("/WEB-INF/views/"); templateResolver.setSuffix(".html"); templateResolver.setTemplateMode("HTML5"); return templateResolver;} |
如果你更愿意使用 XML 来配置 bean,那么如下的声明能够完成该任务。
1 | <bean id="viewResolver" class="org.thymeleaf.spring3.view.ThymeleafViewResolver" p:templateEngine-ref="templateEngine" /><bean id="templateEngine" class="org.thymeleaf.spring3.SpringTemplateEngine" p:templateResolver-ref="templateResolver" /> <bean id="templateResolver" class="org.thymeleaf.templateResolver.ServletContextTemplateResolver" p:prefix="/WEB-INF/templates/" p:suffix=".html" p:templateMode="HTML5" /> |
不管使用哪种配置方式,Thymeleaf 都已经准备就绪了,它可以将响应中的模板渲染到 Spring MVC 控制器所处理的请求中。
ThymeleafViewResolver 是 Spring MVC 中 ViewResolver 的一个 实现类。像其他的视图解析器一样,它会接受一个逻辑视图名称,并将其解析为视图。不过在该场景下,视图会是一个 Thymeleaf 模板。
需要注意的是 ThymeleafViewResolver bean 中注入了一个对 SpringTemplateEngine bean 的引用。SpringTemplateEngine 会在 Spring 中启用 Thymeleaf 引擎,用来解析模板,并基于这些模板渲染结果。可以看到,我们为其注入了一个 TemplateResolver bean 的引用。
TemplateResolver 会最终定位和查找模板。与之前配置 InternalResourceViewResolver 类似,它使用了 prefix 和 suffix 属性。前缀和后缀将会与逻辑视图名组合使用,进而定位 Thymeleaf 引擎。它的 templateMode 属性被设置成了 HTML 5,这表明我们预期要解析的模板会渲染成 HTML 5 输出。
所有的 Thymeleaf bean 都已经配置完成了,那么接下来我们该创建几个视图了。
定义 Thymeleaf 模板
Thymeleaf 在很大程度上就是 HTML 文件,与 JSP不同,它没有什么特殊的标签或标签库。Thymeleaf 之所以能够发挥作用,是因为它通过自定义的命名空间,为标准的 HTML 标签集合添加 Thymeleaf 属性。如下的程序清单展现了 home.html,也就是使用 Thymeleaf 命名空间的首页模板。
1 | <html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org"> <head> <title>Spitter</title> <link rel="stylesheet" type="text/css" th:href="@{/resources/style.css}"></link> </head> <body> <div id="content"> <h1>Welcome to Spitter</h1> <a th:href="@{/spittles}">Spittles</a> | <a th:href="@{/spitter/register}">Register</a> </body></html> |
首页模板相对来讲很简单,只使用了 th:href 属性。这个属性与对应的原生 HTML 属性很类似,也就是 href 属性,并且可以按照相同的方式来使用。th:href 属性的特殊之处在于它的值中可以包含 Thymeleaf 表达式,用来计算动态的值。它会渲染成一个标准的 href 属性,其中会包含在渲染时动态创建得到的值。这是 Thymeleaf 命名空间中很多属性的运行方式:它们对应标准的 HTML 属性,并且具有相同的名称,但是会渲染一些计算后得到的值。在本例中,使用 th:href 属性的三个地方都用到了 @{} 表达式,用来计算相对于 URL 的路径(就像在 JSP 页面中,我们可能会使用的 JSTL <c:url> 标签或 Spring 标签类似)。
尽管 home.html 是一个相当简单的 Thymeleaf 模板,但是它依然很有价值,这在于它与纯 HTML 模板非常接近。唯一的区别之处在于 th:href 属性,否则的话,它就是基础且功能丰富的 HTML 文件。
这意味着 Thymeleaf 模板与 JSP 不同,它能够按照原始的方式进行编辑甚至渲染,而不必经过任何类型的处理器。当然,我们需要 Thymeleaf 来处理模板并渲染得到最终期望的输出。即便如此,如果没有任何特殊的处理,home.html 也能够加载到 Web 浏览器中,并且看上去与完整渲染的效果很类似。为了更加清晰地阐述这一点,图 6.6 对比了 home.jsp(上方)和 home.html(下方)在 Web 浏览器中的显示效果。
可以看到,在 Web 浏览器中,JSP 模板的渲染效果很糟糕。尽管我们可以看到一些熟悉的元素,但是 JSP 标签库的声明也显示了出来。在链接前出现了一些令人费解的未闭合标记,这是 Web 浏览器没有正常解析 <s:url> 标签的结果。
与之相反,Thymeleaf 模板的渲染效果基本上没有任何错误。稍微有点问题的是链接部分,Web 浏览器并不会像处理 href 属性那样处理 th:href,所以链接并没有渲染为链接的样子。除了这些细微的问题,模板的渲染效果与我们的预期完全符合。
像 home.jsp 这样的模板作为 Thymeleaf 入门是很合适的。但是 Spring 的 JSP 标签所擅长的是表单绑定。如果我们抛弃 JSP 的话,那是不是也要抛弃表单绑定呢?不必担心。Thymeleaf 提供了与之相匹敌的功能。
借助 Thymeleaf 实现表单绑定
表单绑定是 Spring MVC 的一项重要特性。它能够将表单提交的数据填充到命令对象中,并将其传递给控制器,而在展现表单的时候,表单中也会填充命令对象中的值。如果没有表单绑定功能的话,我们需要确保 HTML 表单域要映射后端命令对象中的属性,并且在校验失败后展现表单的时候,还要负责确保输入域中值要设置为命令对象的属性。
但是,如果有表单绑定的话,它就会负责这些事情了。为了复习一下表单绑定是如何运行的,下面展现了在 registration.jsp 中的 First Name 输入域:
1 | <sf:label path="firstName" cssErrorClass="error">First Name</sf:label><sf:input path="firstName" cassErrorClass="error" /><br/> |
在这里,调用了 Spring 表单绑定标签库的 <sf:input> 标签,它会渲染出一个 HTML input 标签,并且其 value 属性设置为后端对象 firstName 属性的值。它还使用了 Spring 的 <sf:label> 标签及其 cssErrorClass 属性,如果出现校验错误的话,会将文本标记渲染为红色。
但是,我们本节讨论的并不是 JSP,而是使用 Thymeleaf 替换 JSP。因此,我们不能使用 Spring 的 JSP 标签实现表单绑定,而是使用 Thymeleaf 的 Spring 方言。
作为阐述的样例,请参考如下的 Thymeleaf 模板片段,它会渲染 First Name 输入域:
1 | <label th:class="${#fields.hasErrors['firstName']}?'error'">First Name</label><input type="text" th:field="*{firstName}" th:class="${#fields.hasErrors['firstName']}?'error'" /><br/> |
在这里,我们不再使用 Spring JSP 标签中的 cssClassName 属性,而是在标准的 HTML 标签上使用 th:class 属性。th:class 属性会渲染为一个 class 属性,它的值是根据给定的表达式计算得到的。在上面的这两个 th:class 属性中,它会直接检查 firstName 域有没有校验错误。如果有的话,class 属性在渲染时的值为 error。如果这个域没有错误的话,将不会渲染 class 属性。
<input> 标签使用了 th:field 属性,用来引用后端对象的 firstName 域。这可能与你的预期有点差别。在 Thymeleaf 模板中, 我们在很多情况下所使用的属性都对应于标准的 HTML 属性,因此貌似使用 th:value 属性来设置标签的 value 属性才是合理的。
其实不然,因为我们是在将这个输入域绑定到后端对象的 firstName 属性上,因此使用 th:field 属性引用 firstName 域。通过使用 th:field,我们将 value 属性设置为 firstName 的值, 同时还会将 name 属性设置为 firstName。
为了阐述 Thymeleaf 是如何实际运行的,如下的程序清单展示了完整的注册表单模板。
1 | <form method="POST" th:object="${spitter}"> <div class="errors" th:if="${#fields.hasErrors('*')}"> <ul> <li th:each="err : ${#fields.errors('*')}" th:text="${err}">Input is incorrect </li> </ul> </div> <label th:class="${#fields.hasErrors('firstName')}? 'error'">First Name</label>: <input type="text" th:field="*{firstName}" th:class="${#fields.hasErrors('firstName')}? 'error'" /><br/> <label th:class="${#fields.hasErrors('lastName')}? 'error'">Last Name</label>: <input type="text" th:field="*{lastName}" th:class="${#fields.hasErrors('lastName')}? 'error'" /><br/> <label th:class="${#fields.hasErrors('email')}? 'error'">Email</label>: <input type="text" th:field="*{email}" th:class="${#fields.hasErrors('email')}? 'error'" /><br/> <label th:class="${#fields.hasErrors('username')}? 'error'">Username</label>: <input type="text" th:field="*{username}" th:class="${#fields.hasErrors('username')}? 'error'" /><br/> <label th:class="${#fields.hasErrors('password')}? 'error'">Password</label>: <input type="password" th:field="*{password}" th:class="${#fields.hasErrors('password')}? 'error'" /><br/> <input type="submit" value="Register" /></form> |
程序清单 6.7 使用了相同的 Thymeleaf 属性和 *{} 表达式,为所有的表单域绑定后端对象。这其实重复了我们在 First Name 域中所做的事情。
但是,需要注意我们在表单的顶部了也使用了 Thymeleaf,它会用来渲染所有的错误。元素使用 th:if 属性来检查是否有校验错误。如果有的话,会渲染,否则的话,它将不会渲染。
在 <div> 中,会使用一个无顺序的列表来展现每项错误。<li> 标签上的 th:each 属性将会通知 Thymeleaf 为每项错误都渲染一个 <li>,在每次迭代中会将当前错误设置到一个名为 err 的变量中。
<li> 标签还有一个 th:text 属性。这个命令会通知 Thymeleaf 计算某一个表达式(在本例中,也就是 err 变量)并将它的值渲染为 <li> 标签的内容体。实际上的效果就是每项错误对应一个 <li> 元素,并展现错误的文本。
你可能会想知道 ${} 和 *{} 括起来的表达式到底有什么区别。${} 表达式(如 ${spitter})是变量表达式(variable expression)。一般来讲,它们会是对象图导航语言(Object-Graph Navigation Language,OGNL)表达式 。但在使用 Spring 的时候,它们是 SpEL 表达式。在 ${spitter} 这个例子中,它会解析为 key 为 spitter 的 model 属性。
而对于 *{} 表达式,它们是选择表达式(selection expression)。变量表达式是基于整个 SpEL 上下文计算的,而选择表达式是基于某一个选中对象计算的。在本例的表单中,选中对象就是
小结
处理请求只是 Spring MVC 功能的一部分。如果控制器所产生的结果想要让人看到,那么它们产生的模型数据就要渲染到视图中,并展现到用户的 Web 浏览器中。Spring 的视图渲染是很灵活的,并提供了多个内置的可选方案,包括传统的 Java Server Pages 以及流行的 Apache Tiles 布局引擎。
在本章中,我们首先快速了解了一下 Spring 所提供的视图和视图解析可选方案。我们还深入学习了如何在 Spring MVC 中使用 JSP 和 Apache Tiles。
我们还看到了如何使用 Thymeleaf 作为 Spring MVC 应用的视图层,它被视为 JSP 的替代方案。Thymeleaf 是一项很有吸引力的技术,因为它能创建原始的模板,这些模板是纯 HTML,能像静态 HTML 那样以原始的方式编写和预览,并且能够在运行时渲染动态模型数据。除此之外,Thymeleaf 是与 Servlet 没有耦合关系的,这样它就能够用在 JSP 所不能使用的领域中。
Spittr 应用的视图定义完成之后,我们已经具有了一个虽然微小但是可部署且具有一定功能的 Spring MVC Web 应用。还有一些其他的特性需要更新进来,如数据持久化和安全性,我们会在合适的时候关注这些特性。但现在,这个应用开始变得有模有样了。
在深入学习应用的技术栈之前,在下一章我们将会继续讨论 Spring MVC,学习这个框架中一些更为有用和高级的功能。
Spring MVC 的高级技术
本章内容:
- Spring MVC 配置的替代方案
- 处理文件上传
- 在控制器中处理异常
- 使用 flash 属性
稍等,还没有结束!
如果你在电视购物节目上看过一些小发明或产品广告的话,你可能听过类似这样的话。在广告描述完产品并宣称它能够做什么之后,我们可能会听到“稍等,还没有结束!”,然后广告会继续告诉我们产品还有什么令人激动的特性。
在很多方面,Spring MVC(其实,整个 Spring 也是如此)也有“还没有 结束!”这样的感觉。就在我们觉得已经掌握了 Spring MVC 能够做什么之后,我们会发现它所能做的还不止如此。
在第 5 章中,我们学习了 Spring MVC 的基础知识,以及如何编写控制器来处理各种请求。基于这些知识,我们在第 6 章学习了如何创建 JSP 和 Thymeleaf 视图,这些视图会将模型数据展现给用户。你可能认为我们已经掌握了 Spring MVC 的全部知识。但是稍等!还没有结束!
在本章中,我们会继续 Spring MVC 的话题,本章所介绍的特性已经超出了第 5 章和第 6 章基础知识的范畴。我们将会看到如何编写控制器来处理文件上传、如何处理控制器所抛出的异常,以及如何在模型中传递数据,使其能够在重定向(redirect)之后依然存活。
但首先,我要兑现一个承诺。在第 5 章中,我快速展现了如何通过 AbstractAnnotationConfigDispatcherServletInitializer 搭建 Spring MVC,当时我承诺会为读者展现其他的配置方案。所以,在介绍文件上传和异常处理之前,我们先花一点时间探讨一下如何用其他的方式来搭建 DispatcherServlet 和 ContextLoaderListener。
Spring MVC 配置的替代方案
在第 5 章中,我们通过扩展 AbstractAnnotationConfigDispatcherServletInitializer 快速搭建了 Spring MVC 环境。在这个便利的基础类中,假设我们需要基本的 DispatcherServlet 和 ContextLoaderListener 环境,并且 Spring 配置是使用 Java 的,而不是 XML。
尽管对很多 Spring 应用来说,这是一种安全的假设,但是并不一定总能满足我们的要求。除了 DispatcherServlet 以外,我们可能还需要额外的 Servlet 和 Filter;我们可能还需要对 DispatcherServlet 本身做一些额外的配置;或者,如果我们需要将应用部署到 Servlet 3.0 之前的容器中,那么还需要将 DispatcherServlet 配置到传统的 web.xml 中。
自定义 DispatcherServlet 配置
虽然从程序清单 7.1 的外观上不一定能够看得出来,但是 AbstractAnnotationConfigDispatcherServletInitializer 所完成的事情其实比看上去要多。在 SpittrWebAppInitializer 中我们所编写的三个方法仅仅是必须要重载的 abstract 方法。但实际上还有更多的方法可以进行重载,从而实现额外的配置。
此类的方法之一就是 customizeRegistration()。在 AbstractAnnotationConfigDispatcherServletInitializer 将 DispatcherServlet 注册到 Servlet 容器中之后,就会调用 customizeRegistration(),并将 Servlet 注册后得到的 Registration.Dynamic 传递进来。通过重载 customizeRegistration() 方法,我们可以对 DispatcherServlet 进行额外的配置。
例如,在本章稍后的内容中(7.2 节),我们将会看到如何在 Spring MVC 中处理 multipart 请求和文件上传。如果计划使用 Servlet 3.0 对 multipart 配置的支持,那么需要使用 DispatcherServlet 的 registration 来启用 multipart 请求。我们可以重载 customizeRegistration() 方法来设置 MultipartConfigElement,如下所示:
1 | void customizeRegistration(Dynamic registration) { registration.setMultipartConfig( new MultipartConfigElement("/tmp/spittr/uploads"); );} |
借助 customizeRegistration() 方法中的 ServletRegistration.Dynamic,我们能够完成多项任务,包括通过调用 setLoadOnStartup() 设置 load-on-startup 优先级,通过 setInitParameter() 设置初始化参数,通过调用 setMultipartConfig() 配置 Servlet 3.0 对 multipart 的支持。在前面的样例中,我们设置了对 multipart 的支持,将上传文件的临时存储目录设置在 /tmp/spittr/uploads 中。
添加其他的 Servlet 和 Filter
按照 AbstractAnnotationConfigDispatcherServletInitializer 的定义,它会创建 DispatcherServlet 和 ContextLoaderListener。但是,如果你想注册其他的 Servlet、 Filter 或 Listener 的话,那该怎么办呢?
基于 Java 的初始化器(initializer)的一个好处就在于我们可以定义任意数量的初始化器类。因此,如果我们想往 Web 容器中注册其他组件的话,只需创建一个新的初始化器就可以了。最简单的方式就是实现 Spring 的 WebApplicationInitializer 接口。
例如,如下的程序清单展现了如何创建 WebApplicationInitializer 实现并注册一个 Servlet。
1 | package com.myapp.config;import javax.servlet.ServletContext;import javax.servlet.ServletException;import javax.servlet.ServletRegistration.Dynamic;import org.springframework.web.WebApplicationInitializer;import com.myapp.MyServlet;public class MyServletInitializer extends WebApplicationInitializer { public void onStartup(ServletContext servletContext) throws ServletException { Dynamic myServlet = servlectContext.addServlet("myServlet", MyServlet.class); myServlect.addMapping("/custom/**"); }} |
程序清单 7.1 是相当基础的 Servlet 注册初始化器类。它注册了一个 Servlet 并将其映射到一个路径上。我们也可以通过这种方式来手动注册 DispatcherServlet。(但这并没有必要,因为 AbstractAnnotationConfigDispatcherServletInitializer 没用太多代码就将这项任务完成得很漂亮。)
类似地,我们还可以创建新的 WebApplicationInitializer 实现来注册 Listener 和 Filter。例如,如下的程序清单展现了如何注册 Filter。
1 | void onStartup(ServlectContext servletContext) throws ServletException { javax.servlet.FilterRegistration.Dynamic filter = servletContext.addFilter("myFilter", MyFilter.class); filter.addMappingForUrlPatterns(null, false, "/custom/**");} |
如果要将应用部署到支持 Servlet 3.0 的容器中,那么 WebApplicationInitializer 提供了一种通用的方式,实现在 Java 中注册 Servlet、Filter 和 Listener。不过,如果你只是注册 Filter, 并且该 Filter 只会映射到 DispatcherServlet 上的话,那么在 AbstractAnnotationConfigDispatcherServletInitializer 中还有一种快捷方式。
为了注册 Filter 并将其映射到 DispatcherServlet,所需要做的仅仅是重载 AbstractAnnotationConfigDispatcherServletInitializer 的 getServletFilters() 方法。例如,在如下的代码中,重载了 AbstractAnnotationConfigDispatcherServletInitializer 的 getServletFilters() 方法以注册 Filter:
1 | Filter() getServletFilters() { return new Filter[] { new MyFilter() };} |
如果要将应用部署到 Servlet 3.0 容器中,那么 Spring 提供了多种方式来注册 Servlet(包括 DispatcherServlet)、Filter 和 Listener,而不必创建 web.xml 文件。但是,如果你不想采取以上所述方案的话,也是可以的。假设你需要将应用部署到不支持 Servlet 3.0 的容器中(或者你只是希望使用 web.xml 文件),那么我们完全可以按照传统的方式,通过 web.xml 配置 Spring MVC。让我们看一下该怎么做。
在 web.xml 中声明 DispatcherServlet
在典型的 Spring MVC 应用中,我们会需要 DispatcherServlet 和 ContextLoaderListener。AbstractAnnotationConfigDispatcherServletInitializer 会自动注册它们,但是如果需要在 web.xml 中注册的话,那就需要我们自己来完成这项任务了。 如下是一个基本的 web.xml 文件,它按照传统的方式搭建了 DispatcherServlet 和 ContextLoaderListener。
1 | <web-app version="2.5" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" > <context-param> <param-name>contextConfigLocation</param-name> <param-value>/WEB-INF/spring/root-context.xml</param-value> </context-param> <listener> <listener-class> org.springframework.web.context.ContextLoaderListener </listener-class> </listener> <servlet> <servlet-name>appServlet</servlet-name> <servlet-class> org.springframework.web.servlet.DispatcherServlet </servlet-class> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>appServlet</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping></web-app> |
就像我在第 5 章曾经介绍过的,ContextLoaderListener 和 DispatcherServlet 各自都会加载一个 Spring 应用上下文。上下文参数 contextConfigLocation 指定了一个 XML 文件的地址,这个文件定义了根应用上下文,它会被 ContextLoaderListener 加载。如程序清单 7.3 所示,根上下文会从 /WEB-INF/spring/root-context.xml 中加载 bean 定义。
DispatcherServlet 会根据 Servlet 的名字找到一个文件,并基于该文件加载应用上下文。在程序清单 7.3 中,Servlet 的名字是 appServlet,因此 DispatcherServlet 会从 /WEB-INF/appServlet-context.xml 文件中加载其应用上下文。
如果你希望指定 DispatcherServlet 配置文件的位置的话,那么可以在 Servlet 上指定一个 contextConfigLocation 初始化参数。例如,如下的配置中,DispatcherServlet 会从 /WEB-INF/spring/appServlet/servlet-context.xml 加载它的 bean:
1 | <servlet> <servlet-name>appServlet</servlet-name> <servlet-class> org.springframework.web.servlet.DispatcherServlet </servlet-class> <init-param> <param-name>contextConfigLocation</param-name> <param-value> /WEB-INF/spring/appServlet/servlet-context.xml </param-value> </init-parma> <load-on-startup>1</load-on-startup></servlet> |
当然,上面阐述的都是如何让 DispatcherServlet 和 ContextLoaderListener 从 XML 中加载各自的应用上下文。但是,在本书中的大部分内容中,我们都更倾向于使用 Java 配置而不是 XML 配置。因此,我们需要让 Spring MVC 在启动的时候,从带有 @Configuration 注解的类上加载配置。
要在 Spring MVC 中使用基于 Java 的配置,我们需要告诉 DispatcherServlet 和 ContextLoaderListener 使用 AnnotationConfigWebApplicationContext,这是一 个 WebApplicationContext 的实现类,它会加载 Java 配置类,而不是使用 XML。要实现这种配置,我们可以设置 contextClass 上下文参数以及 DispatcherServlet 的初始化参数。如下的程序清单展现 了一个新的 web.xml,在这个文件中,它所搭建的 Spring MVC 使用基于 Java 的 Spring 配置:
1 | <web-app version="2.5" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" > <context-param> <param-name>contextClass</param-name> <param-value> org.springframework.web.context.support.AnnotationConfigWebApplicationContext </param-value> </context-param> <context-param> <param-name>contextConfigLocation</param-name> <param-value> com.habuma.spitter.config.RootConfig </param-value> </context-param> <listener> <listener-class> org.springframework.web.context.ContextLoaderListener </listener-class> </listener> <servlet> <servlet-name>appServlet</servlet-name> <servlet-class> org.springframework.web.servlet.DispatcherServlet </servlet-class> <init-param> <param-name>contextClass</param-name> <param-value> org.springframework.web.context.support.AnnotationConfigWebApplicationContext </param-value> </init-param> <context-param> <param-name>contextConfigLocation</param-name> <param-value> com.habuma.spitter.config.WebConfigConfig </param-value> </context-param> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>appServlet</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping></web-app> |
现在我们已经看到了如何以多种不同的方式来搭建 Spring MVC,那么接下来我们会看一下如何使用 Spring MVC 来处理文件上传。
处理 multipart 形式的数据
在 Web 应用中,允许用户上传内容是很常见的需求。在 Facebook 和 Flickr 这样的网站中,用户通常会上传照片和视频,并与家人和朋友分享。还有一些服务允许用户上传照片,然后按照传统方式将其打印在纸上,或者用在 T 恤衫和咖啡杯上。
Spittr 应用在两个地方需要文件上传。当新用户注册应用的时候,我们希望他们能够上传一张图片,从而与他们的个人信息相关联。当用户提交新的 Spittle 时,除了文本消息以外,他们可能还会上传一 张照片。
一般表单提交所形成的请求结果是很简单的,就是以 & 符分割的多个 name-value 对。例如,当在 Spittr 应用中提交注册表单时,请求会如下所示
1 | firstName=Charless&lastName=Xavier&email=professor%40xmen.org&username=professorx&password=letmein01 |
尽管这种编码形式很简单,并且对于典型的基于文本的表单提交也足够满足要求,但是对于传送二进制数据,如上传图片,就显得力不从心了。与之不同的是,multipart 格式的数据会将一个表单拆分为多个部分(part),每个部分对应一个输入域。在一般的表单输入域中,它所对应的部分中会放置文本型数据,但是如果上传文件的话,它所对应的部分可以是二进制,下面展现了 multipart 的请求体:
1 | -----------WebKitFormBoundaryqgkaBn8lHJCuNmiWContent-Disposition: form-data; name="firstName"Charles-----------WebKitFormBoundaryqgkaBn8lHJCuNmiWContent-Disposition: form-data; name="lastName"Xavier-----------WebKitFormBoundaryqgkaBn8lHJCuNmiWContent-Disposition: form-data; name="email"charles@xmen.com-----------WebKitFormBoundaryqgkaBn8lHJCuNmiW"Content-Disposition: form-data; name="username"professorx-----------WebKitFormBoundaryqgkaBn8lHJCuNmiWContent-Disposition: form-data; name="password"letmeinO1-----------WebKitFormBoundaryqgkaBn8lHJCuNmiWContent-Disposition: form-data; name="profilePicture"; filename="me.jpg"Content-Type: image/jpeg [[ Binary image data goes here ]]-----------WebKitFormBoundaryqgkaBn8lHJCuNmiW-- |
在这个 multipart 的请求中,我们可以看到 profilePicture 部分与其他部分明显不同。除了其他内容以外,它还有自己的 Content-Type 头,表明它是一个 JPEG 图片。尽管不一定那么明显,但 profilePicture 部分的请求体是二进制数据,而不是简单的文本。
尽管 multipart 请求看起来很复杂,但在 Spring MVC 中处理它们却很容易。在编写控制器方法处理文件上传之前,我们必须要配置一个 multipart 解析器,通过它来告诉 DispatcherServlet 该如何读取 multipart 请求。
配置 multipart 解析器
DispatcherServlet 并没有实现任何解析 multipart 请求数据的功能。它将该任务委托给了 Spring 中 MultipartResolver 策略接口的实现,通过这个实现类来解析 multipart 请求中的内容。从 Spring 3.1 开 始,Spring 内置了两个 MultipartResolver 的实现供我们选择:
CommonsMultipartResolver:使用 Jakarta Commons FileUpload 解析 multipart 请求;StandardServletMultipartResolver:依赖于 Servlet 3.0 对 multipart 请求的支持(始于 Spring 3.1)。
一般来讲,在这两者之 间,StandardServletMultipartResolver 可能会是优选的方案。它使用 Servlet 所提供的功能支持,并不需要依赖任何其他的项目。如果我们需要将应用部署到 Servlet 3.0 之前的容器中,或者还没有使用 Spring 3.1 或更高版本,那么可能就需要 CommonsMultipartResolver 了。
使用 Servlet 3.0 解析 multipart 请求
兼容 Servlet 3.0 的 StandardServletMultipartResolver 没有构造器参数,也没有要设置的属性。这样,在 Spring 应用上下文中,将其声明为 bean 就会非常简单,如下所示:
1 | MultipartResolver multipartResolver() throws IOException { return new StandardServletMultipartResolver();} |
既然这个 @Bean 方法如此简单,你可能就会怀疑我们到底该如何限制 StandardServletMultipartResolver 的工作方式呢。如果我们想要限制用户上传文件的大小,该怎么实现?如果我们想要指定文件在上传时,临时写入目录在什么位置的话,该如何实现?因为没有属性和构造器参数,StandardServletMultipartResolver 的功能看起来似乎有些受限。
其实并不是这样,我们是有办法配置 StandardServletMultipartResolver 的限制条件的。只不过不是在 Spring 中配置 StandardServletMultipartResolver, 而是要在 Servlet 中指定 multipart 的配置。至少,我们必须要指定在文件上传的过程中,所写入的临时文件路径。如果不设定这个最基本配置的话,StandardServletMultipartResolver 就无法正常工作。具体来讲,我们必须要在 web.xml 或 Servlet 初始化类中,将 multipart 的具体细节作为 DispatcherServlet 配置的一部分。
如果我们采用 Servlet 初始化类的方式来配置 DispatcherServlet 的话,这个初始化类应该已经实现了 WebApplicationInitializer,那我们可以在 Servlet registration 上调用 setMultipartConfig() 方法,传入一个 MultipartConfigElement 实例。如下是最基本的 DispatcherServlet multipart 配置,它将临时路径设置为 /tmp/spittr/uploads:
1 | DispatcherServlet ds = new DispatchServlet();Dynamic registration = context.addServlet("appServlet", ds);registration.addMapping("/");registration.setMultipartConfig(new MultipartConfigElement("/tmp/spittr/uploads")); |
如果我们配置 DispatcherServlet 的 Servlet 初始化类继承了 AbstractAnnotationConfigDispatcherServletInitializer 或 AbstractDispatcherServletInitializer 的话,那么我们不会直接创建 DispatcherServlet 实例并将其注册到 Servlet 上下文中。这样的话,将不会有对 Dynamic Servlet registration 的引用供我们使用了。但是,我们可以通过重载 customizeRegistration() 方法(它会得到一个 Dynamic 作为参数)来配置 multipart 的具体细节:
1 | void customizeRegistration(Dynamic registration) { registration.setMultipartConfig( new MultipartConfigElement("/tmp/spittr/uploads"); );} |
到目前为止,我们所使用是只有一个参数的 MultipartConfigElement 构造器,这个参数指定的是文件系统中的一个绝对目录,上传文件将会临时写入该目录中。但是,我们还可以通过其他的构造器来限制上传文件的大小。除了临时路径的位 置,其他的构造器所能接受的参数如下:
- 上传文件的最大容量(以字节为单位)。默认是没有限制的。
- 整个 multipart 请求的最大容量(以字节为单位),不会关心有多少个 part 以及每个 part 的大小。默认是没有限制的。
- 在上传的过程中,如果文件大小达到了一个指定最大容量(以字节为单位),将会写入到临时文件路径中。默认值为 0,也就是所有上传的文件都会写入到磁盘上。
例如,假设我们想限制文件的大小不超过 2MB,整个请求不超过 4MB,而且所有的文件都要写到磁盘中。下面的代码使用 MultipartConfigElement 设置了这些临界值:
1 | void customizeRegistration(Dynamic registration) { registration.setMultipartConfig( new MultipartConfigElement("/tmp/spittr/uploads", 2097152, 4194304, 0); );} |
如果我们使用更为传统的 web.xml 来配置 MultipartConfigElement 的话,那么可以使用 <servlet> 中的 <multipart-config> 元素,如下所示:
1 | <servlet> <servlet-name>appServlet</servlet-name> <servlet-class> org.springframework.web.servlet.DispatchServlet </servlet-class> <load-on-startup>1</load-on-startup> <multipart-config> <location>/tmp/spittr/upload</location> <max-file-size>2097152</max-file-size> <max-request-size>4194304</max-request-size> </multipart-config></servlet> |
<multipart-config> 的默认值与 MultipartConfigElement 相同。与 MultipartConfigElement 一样,必须要配置的是 <location>。
配置 Jakarta Commons FileUpload multipart 解析器
通常来讲,StandardServletMultipartResolver 会是最佳的选择,但是如果我们需要将应用部署到非 Servlet 3.0 的容器中,那么就得需要替代的方案。如果喜欢的话,我们可以编写自己的 MultipartResolver 实现。不过,除非想要在处理 multipart 请求的时候执行特定的逻辑,否则的话,没有必要这样做。Spring 内置了 CommonsMultipartResolver,可以作为 StandardServletMultipartResolver 的替代方案。
将 CommonsMultipartResolver 声明为 Spring bean 的最简单方式如下:
1 | MultipartResolver multipartResolver() { return new MultipartResolver();} |
与 StandardServletMultipartResolver 有所不同,CommonsMultipartResolver 不会强制要求设置临时文件路径。默认情况下,这个路径就是 Servlet 容器的临时目录。不过,通过设置 uploadTempDir 属性,我们可以将其指定为一个不同的位置:
1 | MultipartResolver multipartResolver() throws IOException { CommonsMultipartResolver multipartResolver = new CommonsMultipartResolver(); multipartResolver.setUploadTempDir( new FileSystemResource("/tmp/spittr/uploads"); ); return multipartResolver;} |
实际上,我们可以按照相同的方式指定其他的 multipart 上传细节,也就是设置 CommonsMultipartResolver 的属性。例如,如下的配置就等价于我们在前文通过 MultipartConfigElement 所配置的 StandardServletMultipartResolver:
1 | MultipartResolver multipartResolver() throws IOException { CommonsMultipartResolver multipartResolver = new CommonsMultipartResolver(); multipartResolver.setUploadTempDir( new FileSystemResource("/tmp/spittr/uploads")); multipartResolver.setMaxUploadSize(2097152); multipartResolver.setMaxInMemorySize(0); return multipartResolver;} |
在这里,我们将最大的文件容量设置为 2 MB,最大的内存大小设置为 0 字节。这两个属性直接对应于 MultipartConfigElement 的第二个和第四个构造器参数,表明不能上传超过 2 MB 的文件,并且不管文件的大小如何,所有的文件都会写到磁盘中。但是与 MultipartConfigElement 有所不同,我们无法设定 multipart 请求整体的最大容量。
处理 multipart 请求
现在已经在 Spring 中(或 Servlet 容器中)配置好了对 mutipart 请求的处理,那么接下来我们就可以编写控制器方法来接收上传的文件。要实现这一点,最常见的方式就是在某个控制器方法参数上添加 @RequestPart 注解。
假设我们允许用户在注册 Spittr 应用的时候上传一张图片,那么我们需要修改表单,以允许用户选择要上传的图片,同时还需要修改 SpitterController 中的 processRegistration() 方法来接收上传的图片。如下的代码片段来源于 Thymeleaf 注册表单视图(registrationForm.html),着重强调了表单所需的修改:
1 | <form method="POST" th:object="${spitter}" enctype="multipart/form-data"> ... <label>Profile Picture</label>: <input type="file" name="profilePicture" accept="image/jpeg,image/png,image/gif" /><br/> ... </form> |
<form> 标签现在将 enctype 属性设置为 multipart/form-data,这会告诉浏览器以 multipart 数据的形式提交表单,而不是以表单数据的形式进行提交。在 multipart 中,每个输入域都会对应一个 part。
除了注册表单中已有的输入域,我们还添加了一个新的域,其 type 为 file。这能够让用户选择要上传的图片文件。accept 属性用来将文件类型限制为 JPEG、PNG 以及 GIF 图片。根据其 name 属性,图片数据将会发送到 multipart 请求中的 profilePicture part 之中。
现在,我们需要修改 processRegistration() 方法,使其能够接受上传的图片。其中一种方式是添加 byte 数组参数,并为其添加 @RequestPart 注解。如下为示例:
1 | public String processRegistration( byte[] profilePicture, Spittr spittr, Errors errors) { ...} |
当注册表单提交的时候,profilePicture 属性将会给定一个 byte 数组,这个数组中包含了请求中对应 part 的数据(通过 @RequestPart 指定)。如果用户提交表单的时候没有选择文件,那么这个数组会是空(而不是 null)。获取到图片数据后,processRegistration() 方法剩下的任务就是将文件保存到某个位置。
我们将会稍后讨论如何保存文件。但首先,想一下,对于提交的图片数据我们都了解哪些信息呢。或者,更为重要的是,我们还不知道些什么呢?尽管我们已经得到了 byte 数组形式的图片数据,并且根据它能够得到图片的大小,但是对于其他内容我们就一无所知了。我们不知道文件的类型是什么,甚至不知道原始的文件名是什么。你需要判断如何将 byte 数组转换为可存储的文件。
接受 MultipartFile
使用上传文件的原始 byte 比较简单但是功能有限。因此,Spring 还提供了 MultipartFile 接口,它为处理 multipart 数据提供了内容更为丰富的对象。如下的程序清单展现了 MultipartFile 接口的概况。
1 | package org.springframework.web.multipartimport java.io.File;import java.io.IOException;import java.io.InputStream;public interface MultipartFile { String getName(); String getOriginalFilename(); String getContentType(); boolean isEmpty(); long getSize(); byte[] getBytes() throws IOException; InputStream getInputStream() throws IOException; void transferTo(File dest) throws IOException;} |
我们可以看到,MultipartFile 提供了获取上传文件 byte 的方式,但是它所提供的功能并不仅限于此,还能获得原始的文件名、大小以及内容类型。它还提供了一个 InputStream,用来将文件数据以流的方式进行读取。
除此之外,MultipartFile 还提供了一个便利的 transferTo() 方 法,它能够帮助我们将上传的文件写入到文件系统中。作为样例,我们可以在 processRegistration() 方法中添加如下的几行代码,从而将上传的图片文件写入到文件系统中:
1 | profilePicture.tranferTo(new File("/data/spittr/" + profilePicture.getOriginalFilename())); |
将文件保存到本地文件系统中是非常简单的,但是这需要我们对这些文件进行管理。我们需要确保有足够的空间,确保当出现硬件故障时,文件进行了备份,还需要在集群的多个服务器之间处理这些图片文件的同步。
将文件保存到 Amazon S3 中
另外一种方案就是让别人来负责处理这些事情。多加几行代码,我们就能将图片保存到云端。例如,如下的程序清单所展现的 saveImage() 方法能够将上传的文件保存到 Amazon S3 中,我们在 processRegistration() 中可以调用该方法。
1 | private void saveImage(MultipartFile image) throws ImageUploadException { try { AWSCredentials awsCredentials = new AWSCredentials(s3AccessKey, s2SecretKey); S3Service s3 = new ResetS3Service(awsCredentials); S3Bucket bucket = s3.getBucket("spittrImages"); S3Object imageObject = new S3Object(image.getOriginalFilename); imageObject.setDataInputStream(image.getInputStream()); imageObject.setContentLength(image.getSize()); imageObject.setContentType(image.getContentType()); AccessControlList acl = new AccessControlList(); acl.setOwner(bucket.getOwner()); acl.grantPermission(GroupGrants.ALL_USERS, Permission.PERMISSION_READ); imageObject.setAcl(acl); s3.putObject(bucket, imageObject); } catch (Exception e) { throw new ImageUploadException("Unable to save image", e); }} |
程序清单 7.6 将 MultipartFile 保存到 Amazon S3 中 saveImage() 方法所做的第一件事就是构建 Amazon Web Service(AWS)凭证。为了完成这一点,你需要有一个 S3 Access Key 和 S3 Secret Access Key。当注册 S3 服务的时候,Amazon 会将其提供给你。它们会通过值注入的方式提供给 SpitterController。
AWS 凭证准备好后,saveImage() 方法创建了一个 JetS3t 的 RestS3Service 实例,可以通过它来操作 S3 文件系统。它获取 spitterImages bucket 的引用并创建用来包含图片的 S3Object 对象,接下来将图片数据填充到 S3Object。
在调用 putObject() 方法将图片数据写到 S3 之前,saveImage() 方法设置了 S3Object 的权限,从而允许所有的用户查看它。这是很重要的 —— 如果没有它的话,这些图片对我们应用程序的用户就是不可见的。最后,如果出现任何问题的话,将会抛出 ImageUploadException 异常。
以 Part 的形式接受上传的文件
如果你需要将应用部署到 Servlet 3.0 的容器中,那么会有 MultipartFile 的一个替代方案。Spring MVC 也能接受 javax.servlet.http.Part 作为控制器方法的参数。如果使用 Part 来替换 MultipartFile 的话,那么 processRegistration() 的方法签名将会变成如下的形式:
1 | public String processRegistration( Part profilePicture, Spittr spittr, Errors errors) { ...} |
就主体来言(不开玩笑地说),Part 接口与 MultipartFile 并没有太大的差别。在如下的程序清单中,我们可以看到 Part 接口的有一些方法其实是与 MultipartFile 相对应的。
1 | package javax.servlet.http;import java.io.*;import java.util.*;public interface Part { InputStream getInputStream() throws IOException; String getContentType(); String getName(); String getSubmittedFileName(); long getSize(); void write(String fileName) throws IOException; void delete() throws IOException; String getHeader(String name); Collection<String> getHeaders(String name); Collection<String> getHeaderNames();} |
在很多情况下,Part 方法的名称与 MultipartFile 方法的名称是完全相同的。有一些比较类似,但是稍有差异,比如 getSubmittedFileName() 对应于 getOriginalFilename()。类似地,write() 对应于 transferTo(),借助该方法我们能够将上传的文件写入文件系统中:
1 | profilePicture.write("/data/spittr/" + profilePicture.getOriginalFilename()); |
值得一提的是,如果在编写控制器方法的时候,通过 Part 参数的形式接受文件上传,那么就没有必要配置 MultipartResolver 了。只有使用 MultipartFile 的时候,我们才需要 MultipartResolver。
处理异常
到现在为止,在 Spittr 应用中,我们假设所有的功能都正常运行。但是如果某个地方出错的话,该怎么办呢?当处理请求的时候,抛出异常该怎么处理呢?如果发生了这样的情况,该给客户端什么响应呢?
不管发生什么事情,不管是好的还是坏的,Servlet 请求的输出都是一个 Servlet 响应。如果在请求处理的时候,出现了异常,那它的输出依然会是 Servlet 响应。异常必须要以某种方式转换为响应。
Spring 提供了多种方式将异常转换为响应:
- 特定的 Spring 异常将会自动映射为指定的 HTTP 状态码;
- 异常上可以添加
@ResponseStatus注解,从而将其映射为某一个 HTTP 状态码; - 在方法上可以添加
@ExceptionHandler注解,使其用来处理异常。
处理异常的最简单方式就是将其映射到 HTTP 状态码上,进而放到响应之中。接下来,我们看一下如何将异常映射为某一个 HTTP 状态码。
将异常映射为 HTTP 状态码
在默认情况下,Spring 会将自身的一些异常自动转换为合适的状态码。表 7.1 列出了这些映射关系。
| Spring 异常 | HTTP 状态码 |
|---|---|
| BindException | 400 - Bad Request |
| ConversionNotSupportedException | 500 - Internal Server Error |
| HttpMediaTypeNotAcceptableException | 406 - Not Acceptable |
| HttpMediaTypeNotSupportedException | 415 - Unsupported Media Type |
| HttpMessageNotReadableException | 400 - Bad Request |
| HttpMessageNotWritableException | 500 - Internal Server Error |
| HttpRequestMethodNotSupportedException | 405 - Method Not Allowed |
| MethodArgumentNotValidException | 400 - Bad Request |
| MissingServletRequestParameterException | 400 - Bad Request |
| MissingServletRequestPartException | 400 - Bad Request |
| NoSuchRequestHandlingMethodException | 404 - Not Found |
| TypeMismatchException | 400 - Bad Request |
表 7.1 中的异常一般会由 Spring 自身抛出,作为 DispatcherServlet 处理过程中或执行校验时出现问题的结果。例如,如果 DispatcherServlet 无法找到适合处理请求的控制器方法,那么将会抛出 NoSuchRequestHandlingMethod-Exception 异常,最终的结果就是产生 404 状态码的响应(Not Found)。
尽管这些内置的映射是很有用的,但是对于应用所抛出的异常它们就无能为力了。幸好,Spring 提供了一种机制,能够通过 @ResponseStatus 注解将异常映射为 HTTP 状态码。
为了阐述这项功能,请参考 SpittleController 中如下的请求处理方法,它可能会产生 HTTP 404 状态(但目前还没有实现):
1 | public String spittle( long spittleId, Model model) { Spittle spittle = spittleRepository.findOne(spittleId); if (spittle == null) { throw new SpittleNotFoundException(); } model.addAttribute(spittle); return "spittle";} |
在这里,会从 SpittleRepository 中,通过 ID 检索 Spittle 对象。如果 findOne() 方法能够返回 Spittle 对象的话,那么会将 Spittle 放到模型中,然后名为 spittle 的视图会负责将其渲染到响应之中。但是如果 findOne() 方法返回 null 的话,那么将会抛出 SpittleNotFoundException 异常。现在 SpittleNotFoundException 就是一个简单的非检查型异常,如下所示:
1 | package spittr.web;public class SpittleNotFoundException extends RuntimeException {} |
如果调用 spittle() 方法来处理请求,并且给定 ID 获取到的结果为空,那么 SpittleNotFoundException(默认)将会产生 500 状态码(Internal Server Error)的响应。实际上,如果出现任何没有映射的异常,响应都会带有 500 状态码,但是,我们可以通过映射 SpittleNotFoundException 对这种默认行为进行变更。
当抛出 SpittleNotFoundException 异常时,这是一种请求资源没有找到的场景。如果资源没有找到的话,HTTP 状态码 404 是最为精确的响应状态码。所以,我们要使用 @ResponseStatus 注解将 SpittleNotFoundException 映射为 HTTP 状态码 404。
1 | package spittr.web;import org.springframework.http.HttpStatus;import org.springframework.web.bind.annotation.ResponseStatus;public class SpittleNotFoundException extends RuntimeException {} |
在引入 @ResponseStatus 注解之后,如果控制器方法抛出 SpittleNotFoundException 异常的话,响应将会具有 404 状态码,这是因为 Spittle Not Found。
编写异常处理的方法
在很多的场景下,将异常映射为状态码是很简单的方案,并且就功能来说也足够了。但是如果我们想在响应中不仅要包括状态码,还要包含所产生的错误,那该怎么办呢?此时的话,我们就不能将异常视为 HTTP 错误了,而是要按照处理请求的方式来处理异常了。
作为样例,假设用户试图创建的 Spittle 与已创建的 Spittle 文本完全相同,那么 SpittleRepository 的 save() 方法将会抛出 DuplicateSpittle Exception 异常。这意味着 SpittleController 的 saveSpittle() 方法可能需要处理这个异常。如下面的程序清单所示,saveSpittle() 方法可以直接处理这个异常。
1 | public String saveSpittle(SpittleForm form, Model model) { try { spittleRepository.save(new Spittle(null, form.getMessage(), new Date(), form.getLongitude(), form.getLatitude())); return "redirect:/spittles"; } catch (DuplicateSpittleException e) { return "error/duplicate"; }} |
程序清单 7.9 中并没有特别之处,它只是在 Java 中处理异常的基本样例,除此之外,也就没什么了。
它运行起来没什么问题,但是这个方法有些复杂。该方法可以有两个路径,每个路径会有不同的输出。如果能让 saveSpittle() 方法只关注正确的路径,而让其他方法处理异常的话,那么它就能简单一些。
首先,让我们首先将 saveSpittle() 方法中的异常处理方法剥离掉:
1 | public String saveSpittle(SpittleForm form, Model model) { spittleRepository.save(new Spittle(null, form.getMessage(), new Date(), form.getLongitude(), form.getLatitude())); return "redirect:/spittles";} |
可以看到,saveSpittle() 方法简单了许多。因为它只关注成功保存 Spittle 的情况,所以只有一个执行路径,很容易理解(和测试)。
现在,我们为 SpittleController 添加一个新的方法,它会处理抛出 DuplicateSpittleException 的情况:
1 | public String handleDuplicateSpittle() { return "error/duplicate";} |
handleDuplicateSpittle() 方法上添加了 @ExceptionHandler 注解,当抛出 DuplicateSpittleException 异常的时候,将会委托该方法来处理。它返回的是一个 String,这与处理请求的方法是一致的,指定了要渲染的逻辑视图名,它能够告诉用户他们正在试图创建一条重复的条目。
对于 @ExceptionHandler 注解标注的方法来说,比较有意思的一点在于它能处理同一个控制器中所有处理器方法所抛出的异常。所以,尽管我们从saveSpittle() 中抽取代码创建了 handleDuplicateSpittle() 方法,但是它能够处理 SpittleController 中所有方法所抛出的 DuplicateSpittleException 异常。我们不用在每一个可能抛出 DuplicateSpittleException 的方法中添加异常处理代码,这一个方法就涵盖了所有的功能。
既然 @ExceptionHandler 注解所标注的方法能够处理同一个控制器类中所有处理器方法的异常,那么你可能会问有没有一种方法能够处理所有控制器中处理器方法所抛出的异常呢。从 Spring 3.2 开始,这肯定是能够实现的,我们只需将其定义到控制器通知类中即可。
什么是控制器通知方法?很高兴你会问这样的问题,因为这就是我们下面要讲的内容。
为控制器添加通知
如果控制器类的特定切面能够运用到整个应用程序的所有控制器中,那么这将会便利很多。举例来说,如果要在多个控制器中处理异常,那 @ExceptionHandler 注解所标注的方法是很有用的。不过,如果多个控制器类中都会抛出某个特定的异常,那么你可能会发现要在所有的控制器方法中重复相同的 @Exception-Handler 方法。或者,为了避免重复,我们会创建一个基础的控制器类,所有控制器类要扩展这个类,从而继承通用的 @ExceptionHandler 方法。
Spring 3.2 为这类问题引入了一个新的解决方案:控制器通知。控制器通知(controller advice)是任意带有 @ControllerAdvice 注解的类,这个类会包含一个或多个如下类型的方法:
- @ExceptionHandler 注解标注的方法;
- @InitBinder 注解标注的方法;
- @ModelAttribute 注解标注的方法。
在带有 @ControllerAdvice 注解的类中,以上所述的这些方法会运用到整个应用程序所有控制器中带有 @RequestMapping 注解的方法上。
@ControllerAdvice 注解本身已经使用了 @Component,因此@ControllerAdvice 注解所标注的类将会自动被组件扫描获取到,就像带有 @Component 注解的类一样。
@ControllerAdvice 最为实用的一个场景就是将所有的 @ExceptionHandler 方法收集到一个类中,这样所有控制器的异常就能在一个地方进行一致的处理。例如,我们想将 DuplicateSpittleException 的处理方法用到整个应用程序的所有控制器上。如下的程序清单展现的 AppWideExceptionHandler 就能完成这一任务,这是一个带有 @ControllerAdvice 注解的类。
1 | package spittr.web;import org.springframework.web.bind.annotation.ControllerAdvice;import org.springframework.web.bind.annotation.ExceptionHandler; class AppWideExceptionHandler { public String handleNotFound() { return "error/duplicate"; }} |
现在,如果任意的控制器方法抛出了 DuplicateSpittleException,不管这个方法位于哪个控制器中,都会调用这个 duplicateSpittleHandler() 方法来处理异常。我们可以像编写 @RequestMapping 注解的方法那样来编写 @Exception-Handler 注解的方法。如程序清单 7.10 所示,它返回 error/duplicate 作为逻辑视图名,因此将会为用户展现一个友好的出错页面。
跨重定向请求传递数据
在 5.4.1 小节中,在处理完 POST 请求后,通常来讲一个最佳实践就是执行一下重定向。除了其他的一些因素外,这样做能够防止用户点击浏览器的刷新按钮或后退箭头时,客户端重新执行危险的 POST 请求。
在第 5 章,在控制器方法返回的视图名称中,我们借助 了 redirect: 前缀的力量。当控制器方法返回的 String 值 以 redirect: 开头的话,那么这个 String 不是用来查找视图的,而是用来指导浏览器进行重定向的路径。我们可以回头看一下程序清单 5.17,可以看到 processRegistration() 方法返回的 redirect:String 如下所示:
1 | return "redirect:/spitter/" + spitter.getUsername(); |
redirect: 前缀能够让重定向功能变得非常简单。你可能会想 Spring 很难再让重定向功能变得更简单了。但是,请稍等:Spring 为重定向功能还提供了一些其他的辅助功能。
具体来讲,正在发起重定向功能的方法该如何发送数据给重定向的目标方法呢?一般来讲,当一个处理器方法完成之后,该方法所指定的模型数据将会复制到请求中,并作为请求中的属性,请求会转发(forward)到视图上进行渲染。因为控制器方法和视图所处理的是同一个请求,所以在转发的过程中,请求属性能够得以保存。
但是,如图 7.1 所示,当控制器的结果是重定向的话,原始的请求就结束了,并且会发起一个新的 GET 请求。原始请求中所带有的模型数据也就随着请求一起消亡了。在新的请求属性中,没有任何的模型数据,这个请求必须要自己计算数据。
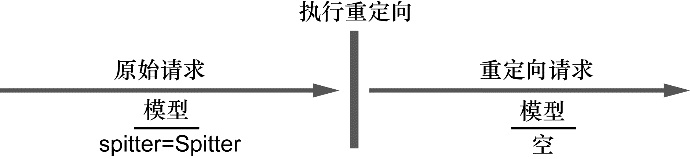
显然,对于重定向来说,模型并不能用来传递数据。但是我们也有一些其他方案,能够从发起重定向的方法传递数据给处理重定向方法中:
- 使用 URL 模板以路径变量和/或查询参数的形式传递数据;
- 通过 flash 属性发送数据。
首先,我们看一下 Spring 如何帮助我们通过路径变量和 / 或查询参数的形式传递数据。
通过 URL 模板进行重定向
通过路径变量和查询参数传递数据看起来非常简单。例如,在程序清单 5.19 中,我们以路径变量的形式传递了新创建 Spitter 的 username。但是按照现在的写法,username 的值是直接连接到重定向 String 上的。这能够正常运行,但是还远远不能说没有问题。当构建 URL 或 SQL 查询语句的时候,使用 String 连接是很危险的。
1 | return "redirect:/spitter/{username}"; |
除了连接 String 的方式来构建重定向 URL,Spring 还提供了使用模板的方式来定义重定向 URL。例如,在程序清单 5.19 中,processRegistration() 方法的最后一行可以改写为如下的形式:
1 | ;public String processRegistration( Spitter spitter, Model model) { spitterRepository.save(spitter); model.addAttribute("username", spitter.getUsername()); return "redirect:/spitter/{username}";} |
现在,username 作为占位符填充到了 URL 模板中,而不是直接连接到重定向 String 中,所以 username 中所有的不安全字符都会进行转义。这样会更加安全,这里允许用户输入任何想要的内容作为 username,并会将其附加到路径上。
除此之外,模型中所有其他的原始类型值都可以添加到 URL 中作为查询参数。作为样例,假设除了 username 以外,模型中还要包含新创建 Spitter 对象的 id 属性,那 processRegistration() 方法可以改写为如下的形式:
1 | public String processRegistration( Spitter spitter, Model model) { spitterRepository.save(spitter); model.addAttribute("username", spitter.getUsername()); model.addAttribute("spitterId", spitter.getId()); return "redirect:/spitter/{username}";} |
所返回的重定向 String 并没有太大的变化。但是,因为模型中的 spitterId 属性没有匹配重定向 URL 中的任何占位符,所以它会自动以查询参数的形式附加到重定向 URL 上。
如果 username 属性的值是 habuma 并且 spitterId 属性的值是 42,那么结果得到的重定向 URL 路径将会是 /spitter/habuma?spitterId=42。
通过路径变量和查询参数的形式跨重定向传递数据是很简单直接的方式,但它也有一定的限制。它只能用来发送简单的值,如 String 和数字的值。在 URL 中,并没有办法发送更为复杂的值,但这正是 flash 属性能够提供帮助的领域。
使用 flash 属性
假设我们不想在重定向中发送 username 或 ID 了,而是要发送实际的 Spitter 对象。如果我们只发送 ID 的话,那么处理重定向的方法还需要从数据库中查找才能得到 Spitter 对象。但是,在重定向之前,我们其实已经得到了 Spitter 对象。为什么不将其发送给处理重定向的方法,并将其展现出来呢?
Spitter 对象要比 String 和 int 更为复杂。因此,我们不能像路径变量或查询参数那么容易地发送 Spitter 对象。它只能设置为模型中的属性。
但是,正如我们前面所讨论的那样,模型数据最终是以请求参数的形式复制到请求中的,当重定向发生的时候,这些数据就会丢失。因此,我们需要将 Spitter 对象放到一个位置,使其能够在重定向的过程中存活下来。
有个方案是将 Spitter 放到会话中。会话能够长期存在,并且能够跨多个请求。所以我们可以在重定向发生之前将 Spitter 放到会话中,并在重定向后,从会话中将其取出。当然,我们还要负责在重定向后在会话中将其清理掉。
实际上,Spring 也认为将跨重定向存活的数据放到会话中是一个很不错的方式。但是,Spring 认为我们并不需要管理这些数据,相反,Spring 提供了将数据发送为 flash 属性(flash attribute)的功能。 按照定义,flash 属性会一直携带这些数据直到下一次请求,然后才会消失。
Spring 提供了通过 RedirectAttributes 设置 flash 属性的方法,这是 Spring 3.1 引入的 Model 的一个子接口。RedirectAttributes 提供了 Model 的所有功能,除此之外,还有几个方法是用来设置 flash 属性的。 具体来讲,Redirect-Attributes 提供了一组 addFlashAttribute() 方法来添加 flash 属性。重新看一 下 processRegistration() 方法,我们可以使用 addFlashAttribute() 将 Spitter 对象添加到模型中:
1 | public String processRegistration( Spitter spitter, RedirectAttribute model) { spitterRespository.save(spitter); model.addAttribute("username", spitter.getUsername()); model.addFlashAttribute("spitter", spitter); return "redirect:/spitter/{username}";} |
因为我们传递了一个 Spitter 对象给 addFlashAttribute() 方法,所以推断得到的 key 将会是 spitter。
在重定向执行之前,所有的 flash 属性都会复制到会话中。在重定向后,存在会话中的 flash 属性会被取出,并从会话转移到模型之中。处理重定向的方法就能从模型中访问 Spitter 对象了,就像获取其他的模型对象一样。图 7.2 阐述了它是如何运行的。

为了完成 flash 属性的流程,如下展现了更新版本的 showSpitterProfile() 方法,在从数据库中查找之前,它会首先从模型中检查 Spitter 对象:
1 | public String showSpitterProfile( String username, Model model) { if (!model.containsAttribute("spitter")) { model.addAttribute(spitterRepository.findByUsername(username)); } return "profile";} |
可以看到,showSpitterProfile() 方法所做的第一件事就是检查是否存有 key 为 spitter 的 model 属性。如果模型中包含 spitter 属性,那就什么都不用做了。这里面包含的 Spitter 对象将会传递到视图中进行渲染。但是如果模型中不包含 spitter 属性的话,那么 showSpitterProfile() 将会从 Repository 中查找 Spitter,并将其存放到模型中。
小结
在 Spring 中,总是会有 “还没有结束” 的感觉:更多的特性、更多的选择以及实现开发目标的更多方式。Spring MVC 有很多功能和技巧。
当然,Spring MVC 的环境搭建是有多种可选方案的一个领域。在本章中,我们首先看了一下搭建 Spring MVC 中 DispatcherServlet 和 ContextLoaderListener 的多种方式。我们还看到了如何调整 DispatcherServlet 的注册功能以及如何注册自定义的 Servlet 和 Filter。如果你需要将应用部署到更老的应用服务器上,我们还快速了解了如何使用 web.xml 声明 DispatcherServlet 和 ContextLoaderListener。
然后,我们了解了如何处理 Spring MVC 控制器所抛出的异常。尽管带有 @RequestMapping 注解的方法可以在自身的代码中处理异常,但是如果我们将异常处理的代码抽取到单独的方法中,那么控制器的代码会整洁得多。
为了采用一致的方式处理通用的任务,包括在应用的所有控制器中处理异常,Spring 3.2 引入了 @ControllerAdvice,它所创建的类能够将控制器的通用行为抽取到同一个地方。
最后,我们看了一下如何跨重定向传递数据,包括 Spring 对 flash 属性的支持:类似于模型的属性,但是能在重定向后存活下来。这样的话,就能采用非常恰当的方式为 POST 请求执行一个重定向回应,而且能够将处理 POST 请求时的模型数据传递过来,然后在重定向后使用或展现这些模型数据。
如果你还有疑惑的话,那么可以告诉你,这就是我所说的“更多的功能”!其实,我们并没有讨论到 Spring MVC 的每个方面。我们将会在第 16 章中重新讨论 Spring MVC,到时你会看到如何使用它来创建 REST API。
但现在,我们将会暂时放下 Spring MVC,看一下 Spring Web Flow,这是一个构建在 Spring MVC 之上的流程框架,它能够引导用户执行一系列向导步骤。
使用Spring Web Flow
本章内容:
创建会话式的 Web 应用程序
定义流程状态和行为
保护 Web 流程
关于互联网,很奇妙的一件事就是它很容易让你迷失。有如此之多的内容可以查看和阅读,而超链接是互联网强大魔力的核心。无怪乎将其称为网,正如蜘蛛织出的网,它会将经过的任何东西困住。我必须承认:之所以在编写此书时花费了如此多的时间,其中的一个原因就是我曾经迷失在维基百科无休无止的链接之中。
有时候,Web应用程序需要控制网络冲浪者的方向,引导他们一步步地访问应用。比较典型的例子就是电子商务站点的结账流程,从购物车开始,应用程序会引导你依次经过派送详情、账单信息以及最终的订单确认流程。
Spring Web Flow 是一个 Web 框架,它适用于元素按规定流程运行的程序。在本章中,我们将会探索 Spring Web Flow 并了解它如何应用于 Spring Web 框架平台。
其实我们可以使用任何 Web 框架编写流程化的应用程序。我曾经看到过一个应用程序,在 Struts 中构建了特定的流程。但是这样就没有办法将流程与实现分开了,你会发现流程的定义分散在组成流程的各个元素中。没有地方能够完整地描述整个流程。
Spring Web Flow 是 Spring MVC 的扩展,它支持开发基于流程的应用程序。它将流程的定义与实现流程行为的类和视图分离开来。
在介绍 Spring Web Flow 的时候,我们将暂时放下 Spittr 样例并使用生成披萨订单的新 Web 应用程序。我们会使用 Spring Web Flow 来定义订单流程。
使用 Spring Web Flow 的第一步是在项目中安装它。让我们从这里开始吧。
在 Spring 中配置 Web Flow
Spring Web Flow 是构建于 Spring MVC 基础之上的。这意味着所有的流程请求都需要首先经过 Spring MVC 的 DispatcherServlet。我们需要在 Spring 应用上下文中配置一些 bean 来处理流程请求并执行流程。
现在,还不支持在 Java 中配置 Spring Web Flow,所以我们别无选择,只能在 XML 中对其进行配置。有一些 bean 会使用 Spring Web Flow 的 Spring 配置文件命名空间来进行声明。因此,我们需要在上下文定义XML文件中添加这个命名空间声明:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:flow="http://www.springframework.org/schema/webflow-config" xsi:schemaLocation="http://www.springframework.org/schema/webflow-config http://www.springframework.org/schema/webflow-config/spring-webflow-config-2.3.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd"></beans> |
在声明了命名空间之后,我们就为装配 Web Flow 的 bean 做好了准备,让我们从流程执行器(flow executor)开始吧。
装配流程执行器
正如其名字所示,流程执行器(flow executor)驱动流程的执行。当用户进入一个流程时,流程执行器会为用户创建并启动一个流程执行实例。当流程暂停的时候(如为用户展示视图时),流程执行器会在用户执行操作后恢复流程。
在 Spring 中,<flow:flow-executor>元素会创建一个流程执行器:
1 | <flow:flow-executor id="flowExecutor" /> |
尽管流程执行器负责创建和执行流程,但它并不负责加载流程定义。这个责任落在了流程注册表(flow registry)身上,接下来我们会创建它。
配置流程注册表
流程注册表(flow registry)的工作是加载流程定义并让流程执行器能够使用它们。我们可以在 Spring 中使用 <flow:flow-registry> 配置流程注册表,如下所示:
1 | <flow:flow-registry id="flowRegistry" base-path="/WEB-INF/flows"> <flow:flow-location-pattern value="*-flow.xml" /></flow:flow-registry> |
在这里的声明中,流程注册表会在 /WEB-INF/flows 目录下查找流程定义,这是通过 base-path 属性指明的。依据 <flow:flow-location-pattern> 元素的值,任何文件名以 -flow.xml 结尾的 XML 文件都将视为流程定义。
所有的流程都是通过其 ID 来进行引用的。这里我们使用了 <flow:flow-location-pattern> 元素,流程的 ID 就是相对于 base-path 的路径 —— 或者双星号所代表的路径。图 8.1 展示了示例中的流程 ID 是如何计算的。

作为另一种方式,我们可以去除 base-path 属性,而显式声明流程定义文件的位置:
1 | <flow:flow-registry id="flowRegistry"> <flow:flow-location path="/WEB-INF/flows/springpizza.xml" /></flow:flow-registry> |
在这里,使用了 <flow:flow-location> 而不是 <flow:flow-location-pattern/>,path 属性直接指明了 /WEB-INF/flows/springpizza.xml 作为流程定义。当我们这样配置的话,流程的 ID 是从流程定义文件的文件名中获得的,在这里就是 springpizza。
如果你希望更显式地指定流程 ID,那你可以通过元素的 id 属性来进行设置。例如,要将 pizza 作为流程 ID,可以像这样配置:
1 | <flow:flow-registry id="flowRegistry"> <flow:flow-location id="pizza" path="/WEB-INF/flows/springpizza.xml" /></flow:flow-registry> |
处理流程请求
我们在前一章曾经看到,DispatcherServlet 一般将请求分发给控制器。但是对于流程而言,我们需要一个 FlowHandlerMapping 来帮助 DispatcherServlet 将流程请求发送给 Spring Web Flow。
在 Spring 应用上下文中,FlowHandlerMapping 的配置如下:
1 | <bean class="org.springframework.webflow.mvc.servlet.FlowHandlerMapping"> <property name="flowRegistry" ref="flowRegistry" /></bean> |
你可以看到,FlowHandlerMapping 装配了流程注册表的引用,这样它就能知道如何将请求的 URL 匹配到流程上。例如,如果我们有一个 ID 为 pizza 的流程, FlowHandlerMapping 就会知道如果请求的 URL 模式(相对于应用程序的上下文路径)是 “/pizza” 的话,就要将其匹配到这个流程上。
然而,FlowHandlerMapping 的工作仅仅是将流程请求定向到 Spring Web Flow 上,响应请求的是 FlowHandlerAdapter。FlowHandlerAdapter 等同于 Spring MVC 的控制器,它会响应发送的流程请求并对其进行处理。FlowHandlerAdapter 可以像下面这样装配成一个 Spring bean,如下所示:
1 | <bean class="org.springframework.webflow.mvc.servlet.FlowHandlerAdapter"> <property name="flowExecutor" ref="flowExecutor" /></bean> |
这个处理适配器是 DispatcherServlet 和 Spring Web Flow 之间的桥梁。它会处理流程请求并管理基于这些请求的流程。在这里,它装配了流程执行器的引用,而后者是为所处理的请求执行流程的。
我们已经配置了 Spring Web Flow 所需的 bean 和组件。剩下就是真正定义流程了。我们随后将会进行这项工作。但首先,让我们先了解一下组成流程的元素。
流程的组件
在 Spring Web Flow 中,流程是由三个主要元素定义的:状态、转移和流程数据。状态(State)是流程中事件发生的地点。如果你将流程想象成公路旅行,那状态就是路途上的城镇、路边饭店以及风景点。流程中的状态是业务逻辑执行、做出决策或将页面展现给用户的地方,而不是在公路旅行中买 Doritos 薯片和健怡可乐的所在。
如果流程状态就像公路旅行中停下来的地点,那转移(transition)就是连接这些点的公路。在流程中,你通过转移的方式从一个状态到另一个状态。
当你在城镇之间旅行的时候,你可能要买一些纪念品,留下一些记忆并在路上取一些空的零食袋。类似地,在流程处理中,它要收集一些数据:流程的当前状况。我很想将其称为流程的状态,但是在我们讨论流程的时候状态(state)已经有了另外的含义。
让我们仔细看一下在 Spring Web Flow 中这三个元素是如何定义的。
状态
Spring Web Flow 定义了五种不同类型的状态,如表 8.1 所示。通过选择 Spring Web Flow 的状态几乎可以把任意的安排功能构造成会话式的 Web 应用。尽管并不是所有的流程都需要表 8.1 所描述的状态,但最终你可能会经常使用它们中的大多数。
| 状 态 类 型 | 它是用来做什么的 |
|---|---|
| 行为(Action) | 行为状态是流程逻辑发生的地方 |
| 决策(Decision) | 决策状态将流程分成两个方向,它会基于流程数据的评估结果确定流程方向 |
| 结束(End) | 结束状态是流程的最后一站。一旦进入End状态,流程就会终止 |
| 子流程(Subflow) | 子流程状态会在当前正在运行的流程上下文中启动一个新的流程 |
| 视图(View) | 视图状态会暂停流程并邀请用户参与流程 |
稍后我们将会看到如何将这些不同类型的状态组合起来形成一个完整的流程。但首先,让我们了解一下这些流程元素在 Spring Web Flow 定义中是如何表现的。
视图状态
视图状态用于为用户展现信息并使用户在流程中发挥作用。实际的视图实现可以是 Spring 支持的任意视图类型,但通常是用 JSP 来实现的。
在流程定义的 XML 文件中,<view-state> 用于定义视图状态:
1 | <view-state id="welcome" /> |
在这个简单的示例中,id 属性有两个含义。它在流程内标示这个状态。除此以外,因为在这里没有在其他地方指定视图,所以它也指定了流程到达这个状态时要展现的逻辑视图名为 welcome。
如果你愿意显式指定另外一个视图名,那可以使用 view 属性做到这一点:
1 | <view-state id="welcome" view="greeting"/> |
如果流程为用户展现了一个表单,你可能希望指明表单所绑定的对象。为了做到这一点,可以设置 model 属性:
1 | <view-state id="takepayment" model="flowScope.paymentDetails"/> |
这里我们指定 takePayment 视图中的表单将绑定流程作用域内的 paymentDetails 对象。(稍后,我们将会更详细地介绍流程作用域和数据。)
行为状态
视图状态会涉及到流程应用程序的用户,而行为状态则是应用程序自身在执行任务。行为状态一般会触发 Spring 所管理 bean 的一些方法并根据方法调用的执行结果转移到另一个状态。
在流程定义 XML 中,行为状态使用 <action-state> 元素来声明。这里是一个例子:
1 | <action-state id="saveOrder"> <evaluate expression="pizzaFlowActions.saveOrder(order)" /> <transition to="thankYou" /></action-state> |
尽管不是严格需要的,但是 <action-state> 元素一般都会有一个 <evaluate> 作为子元素。<evaluate> 元素给出了行为状态要做的事情。expression 属性指定了进入这个状态时要评估的表达式。在本示例中,给出的 expression 是 SpEL 表达式,它表明将会找到 ID 为 pizzaFlowActions 的 bean 并调用其 saveOrder() 方法。
Spring Web Flow 与表达式语言
在这几年以来,Spring Web Flow 在选择的表达式语言方面,经过了一些变化。在 1.0 版本的时候,Spring Web Flow 使用的是对象图导航语言(Object-Graph Navigation Language ,OGNL)。随后的 2.0 版本又换成了统一表达式语言(Unified Expression Language ,Unified EL)。在 2.1 版本中,Spring Web Flow 使用的是 SpEL。
尽管可以使用上述的任意表达式语言来配置 Spring Web Flow,但 SpEL 是默认和推荐使用的表达式语言。因此,当定义流程的时候,我们会选择使用 SpEL,忽略掉其他的可选方案。
决策状态
有可能流程会完全按照线性执行,从一个状态进入另一个状态,没有其他的替代路线。但是更常见的情况是流程在某一个点根据流程的当前情况进入不同的分支。
决策状态能够在流程执行时产生两个分支。决策状态将评估一个 Boolean 类型的表达式,然后在两个状态转移中选择一个,这要取决于表达式会计算出 true 还是 false。在 XML 流程定义中,决策状态通过 <decision-state> 元素进行定义。典型的决策状态示例如下所示:
1 | <decision-state id="checkDeliveryArea"> <if test="pizzaFlowActions.checkDeliveryArea(customer.zipCode)" then="addCustomer" else="deliveryWarning" /></decision-state> |
你可以看到,<decision-state> 并不是独立完成工作的。<if> 元素是决策状态的核心。这是表达式进行评估的地方,如果表达式结果为 true,流程将转移到 then 属性指定的状态中,如果结果为 false,流程将会转移到 else 属性指定的状态中。
子流程状态
你可能不会将应用程序的所有逻辑写在一个方法中,而是将其分散到多个类、方法以及其他结构中。
同样,将流程分成独立的部分是个不错的主意。<subflow-state> 允许在一个正在执行的流程中调用另一个流程。这类似于在一个方法中调用另一个方法。
<subflow-state> 可以这样声明:
1 | <subflow-state id="order" subflow="pizza/order"> <input name="order" value="order" /> <transition on="orderCreated" to="payment" /></subflow-state> |
在这里,<input> 元素用于传递订单对象作为子流程的输入。如果子流程结束的 <end-state> 状态 ID 为 orderCreated,那么流程将会转移到名为 payment 的状态。
在这里,我有点超出进度了,我们还没有讨论到 <end-state> 元素和转移。我们很快就会在 8.2.2 小节介绍转移。对于结束状态,这正是接下来要介绍的。
结束状态
最后,所有的流程都要结束。这就是当流程转移到结束状态时所做的。<end-state> 元素指定了流程的结束,它一般会是这样声明的:
1 | <end-state id="customerReady" /> |
当到达 <end-state> 状态,流程会结束。接下来会发生什么取决于几个因素:
- 如果结束的流程是一个子流程,那调用它的流程将会从
<subflow-state>处继续执行。<end-state>的 ID 将会用作事件触发从<subflow-state>开始的转移。 - 如果
<end-state>设置了 view 属性,指定的视图将会被渲染。视图可以是相对于流程路径的视图模板,如果添加 “externalRedirect:” 前缀的话,将会重定向到流程外部的页面,如果添加 “flowRedirect:” 将重定向到另一个流程中。 - 如果结束的流程不是子流程,也没有指定 view 属性,那这个流程只是会结束而已。浏览器最后将会加载流程的基本URL地址,当前已没有活动的流程,所以会开始一个新的流程实例。
需要意识到流程可能会有不止一个结束状态。子流程的结束状态 ID 确定了激活的事件,所以你可能会希望通过多种结束状态来结束子流程,从而能够在调用流程中触发不同的事件。即使不是在子流程中,也有可能在结束流程后,根据流程的执行情况有多个显示页面供选择。
现在,已经看完了流程中的各个状态,我们应当看一下流程是如何在状态间迁移的。让我们看看如何在流程中通过定义转移来完成道路铺设的。
转移
正如我在前面所提到的,转移连接了流程中的状态。流程中除结束状态之外的每个状态,至少都需要一个转移,这样就能够知道一旦这个状态完成时流程要去向哪里。状态可以有多个转移,分别对应于当前状态结束时可以执行的不同的路径。
转移使用 <transition> 元素来进行定义,它会作为各种状态元素(<action-state>、<view-state>、<subflow-state>)的子元素。最简单的形式就是 <transition> 元素在流程中指定下一个状态:
1 | <transition to="customerReady" /> |
属性 to 用于指定流程的下一个状态。如果 <transition> 只使用了 to 属性,那这个转移就会是当前状态的默认转移选项,如果没有其他可用转移的话,就会使用它。
更常见的转移定义是基于事件的触发来进行的。在视图状态,事件通常会是用户采取的动作。在行为状态,事件是评估表达式得到的结果。而在子流程状态,事件取决于子流程结束状态的 ID。在任意的事 件中(这里没有任何歧义),你可以使用 on 属性来指定触发转移的事件:
1 | <transition on="phoneEntered" to="lookupCustomer" /> |
在本例中,如果触发了 phoneEntered 事件,流程将会进入 lookupCustomer 状态。
在抛出异常时,流程也可以进入另一个状态。例如,如果顾客的记录没有找到,你可能希望流程转移到一个展现注册表单的视图状态。以下的代码片段显示了这种类型的转移:
1 | <transition on-exception="com.springinaction.pizza.service.CustomerNotFoundException" to="registraction" /> |
属性 on-exception 类似于on属性,只不过它指定了要发生转移的异常而不是一个事件。在本示例中,CustomerNotFoundException 异常将导致流程转移到 registrationForm 状态。
全局转移
在创建完流程之后,你可能会发现有一些状态使用了一些通用的转移。例如,如果在整个流程中到处都有如下的 <transition> 话, 我一点也不感觉意外:
1 | <transition on="cancel" to="endState" /> |
与其在多个状态中都重复通用的转移,我们可以将 <transition> 元素作为的子元素,把它们定义为全局转移。例如:
1 | <global-transitions> <transition on="cancel" to="endState" /></global-transitions> |
定义完这个全局转移后,流程中的所有状态都会默认拥有这个cancel转移。
我们已经讨论过了状态和转移。在我们开始编写流程之前,让我们看一下流程数据,这是Web流程三元素中的另一个成员。
流程数据
如果你曾经玩过那种老式的基于文字的冒险游戏的话,那么当从一个地方转移到另一个地方时,你会偶尔发现散布在周围的一些东西,你可以把它们捡起来并带上。有时候,你会马上需要一件东西。其他的时候,你会在整个游戏过程中带着这些东西而不知道它们是做什么用的——直到你到达游戏结束的时候才会发现它是真正有用的。
在很多方面,流程与这些冒险游戏是很类似的。当流程从一个状态进行到另一个状态时,它会带走一些数据。有时候,这些数据只需要很短的时间(可能只要展现页面给用户)。有时候,这些数据会在整个流程中传递并在流程结束的时候使用。
声明变量
流程数据保存在变量中,而变量可以在流程的各个地方进行引用。它能够以多种方式创建。在流程中创建变量的最简单形式是使用 <var> 元素:
1 | <var name="customer" class="com.springinaction.pizza.domain.Customer" /> |
这里,创建了一个新的 Customer 实例并将其放在名为customer 的变量中。这个变量可以在流程的任意状态进行访问。
作为行为状态的一部分或者作为视图状态的入口,你有可能会使用 <evaluate> 元素来创建变量。例如:
1 | <evaluate result="viewScope.topppingsList" expression="T(com.springinaction.pizza.domain.Topping).asList()" /> |
在本例中,<evaluate> 元素计算了一个表达式(SpEL 表达式)并将结果放到了名为 toppingsList 的变量中,这个变量是视图作用域的(我们将会在稍后介绍关于作用域的更多概念)。
类似地,<set> 元素也可以设置变量的值:
1 | <set name="flowScope.pizza" value="new com.springinaction.pizza.domain.Pizza()" /> |
<set> 元素与 <evaluate> 元素很类似,都是将变量设置为表达式计算的结果。这里,我们设置了一个流程作用域内的 pizza 变量,它的值是 Pizza 对象的新实例。
当我们在 8.3 小节开始构建真实工作的 Web 流程时,你会看到这些元素是如何具体应用在实际流程中的。但首先,让我们看一下变量的流程作用域、视图作用域以及其他的一些作用域是什么意思。
定义流程数据的作用域
流程中携带的数据会拥有不同的生命作用域和可见性,这取决于保存数据的变量本身的作用域。Spring Web Flow 定义了五种不同作用域,如表 8.2 所示。
| 范 围 | 生命作用域和可见性 |
|---|---|
| Conversation | 最高层级的流程开始时创建,在最高层级的流程结束时销毁。被最高层级的流程和其所有的子流程所共享 |
| Flow | 当流程开始时创建,在流程结束时销毁。只有在创建它的流程中是可见的 |
| Request | 当一个请求进入流程时创建,在流程返回时销毁 |
| Flash | 当流程开始时创建,在流程结束时销毁。在视图状态渲染后,它也会被清除 |
| View | 当进入视图状态时创建,当这个状态退出时销毁。只在视图状态内是可见的 |
当使用 <var> 元素声明变量时,变量始终是流程作用域的,也就是在定义变量的流程内有效。当使用 <set> 或 <evaluate> 的时候,作用域通过 name 或 result 属性的前缀指定。例如,将一个值赋给流程作用域的 theAnswer 变量:
1 | <set name="flowScope.theAnswer" value="42" /> |
到目前为止,我们已经看到了 Web 流程的所有原材料。是时候将其组装起来形成一个成熟且完整功能的 Web 流程了。当我们这样做的时候,请睁大你的眼睛观察,比如我是如何将数据存储在各作用域的变量中的。
组合起来:披萨流程
正如我在本章前面所提到的,我们将暂时不用 Spittr 应用程序。取而代之,我们被要求做一个在线的披萨订购应用,饥饿的 Web 访问者可以在这里订购他们所喜欢的意大利派。
实际上,订购披萨的过程可以很好地定义在一个流程中。我们首先从构建一个高层次的流程开始,它定义了订购披萨的整体过程。接下来,我们会将这个流程拆分成子流程,这些子流程在较低的层次定义了细节。
定义基本流程
一个新的披萨连锁店 Spizza 决定允许用户在线订购以减轻店面电话的压力。当顾客访问 Spizza 站点时,他们需要进行用户识别,选择一个或更多披萨添加到订单中,提供支付信息然后提交订单并等待热乎又新鲜的披萨送过来。图 8.2 阐述了这个流程。
图中的方框代表了状态而箭头代表了转移。你可以看到,订购披萨的整个流程很简单且是线性的。在 Spring Web Flow 中,表示这个流程是很容易的。使这个过程变得更有意思的就是前三个流程会比图中的简单方框更复杂。
以下的程序清单 8.1 展示了如何使用 Spring Web Flow 的 XML 流程定义来实现披萨订单的整体流程。
1 | <flow xmlns="http://www.springframework.org/schema/webflow" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/webflow http://www.springframework.org/schema/webflow/spring-webflow-2.3.xsd"> <var name="order" class="com.springinaction.pizza.domain.Order"/> <subflow-state id="identifyCustomer" subflow="pizza/customer"> <output name="customer" value="order.customer"/> <transition on="customerReady" to="buildOrder" /> </subflow-state> <subflow-state id="buildOrder" subflow="pizza/order"> <input name="order" value="order"/> <transition on="orderCreated" to="takePayment" /> </subflow-state> <subflow-state id="takePayment" subflow="pizza/payment"> <input name="order" value="order"/> <transition on="paymentTaken" to="saveOrder"/> </subflow-state> <action-state id="saveOrder"> <evaluate expression="pizzaFlowActions.saveOrder(order)" /> <transition to="thankCustomer" /> </action-state> <view-state id="thankCustomer"> <transition to="endState" /> </view-state> <end-state id="endState" /> <global-transitions> <transition on="cancel" to="endState" /> </global-transitions></flow> |
在流程定义中,我们看到的第一件事就是 order 变量的声明。每次流程开始的时候,都会创建一个 Order 实例。Order 类会带有关于订单的所有信息,包含顾客信息、订购的披萨列表以及支付详情,如下面所示。
1 | package com.springinaction.pizza.domain;import java.io.Serializable;import java.util.ArrayList;import java.util.List;import org.springframework.beans.factory.annotation.Configurable;public class Order implements Serializable { private static final long serialVersionUID = 1L; private Customer customer; private List<Pizza> pizzas; private Payment payment; public Order() { pizzas = new ArrayList<Pizza>(); customer = new Customer(); } public Customer getCustomer() { return customer; } public void setCustomer(Customer customer) { this.customer = customer; } public List<Pizza> getPizzas() { return pizzas; } public void setPizzas(List<Pizza> pizzas) { this.pizzas = pizzas; } public void addPizza(Pizza pizza) { pizzas.add(pizza); } public float getTotal() { return 0.0f;//pricingEngine.calculateOrderTotal(this); } public Payment getPayment() { return payment; } public void setPayment(Payment payment) { this.payment = payment; }} |
流程定义的主要组成部分是流程的状态。默认情况下,流程定义文件中的第一个状态也会是流程访问中的第一个状态。在本例中,也就是 identifyCustomer 状态(一个子流程)。但是如果你愿意的话,你可以通过 <flow> 元素的 start-state 属性将任意状态指定为开始状态。
1 | <flow xmlns="http://www.springframework.org/schema/webflow" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/webflow http://www.springframework.org/schema/webflow/spring-webflow-2.3.xsd" start-state="identifyCustomer">...</flow> |
识别顾客、构造披萨订单以及支付这样的活动太复杂了,并不适合将其强行塞入一个状态。这是我们为何在后面将其单独定义为流程的原因。但是为了更好地整体了解披萨流程,这些活动都是以 <subflow-state> 元素来进行展现的。
流程变量 order 将在前三个状态中进行填充并在第四个状态中进行保存。identifyCustomer 子流程状态使用了 <output> 元素来填充 order 的 customer 属性,将其设置为顾客子流程收到的输出。buildOrder 和 takePayment 状态使用了不同的方式,它们使用 <input> 将 order 流程变量作为输入,这些子流程就能在其内部填充 order 对象。
在订单得到顾客、一些披萨以及支付细节后,就可以对其进行保存了。saveOrder 是处理这个任务的行为状态。它使用 <evaluate> 来调用 ID 为 pizzaFlowActions 的 bean 的 saveOrder() 方法,并将保存的订单对象传递进来。订单完成保存后,它会转移到 thankCustomer。
thankCustomer 状态是一个简单的视图状态,后台使用了 “/WEBINF/flows/pizza/ thankCustomer.jsp” 这个 JSP 文件,如下所示:
1 | <html xmlns:jsp="http://java.sun.com/JSP/Page"> <jsp:output omit-xml-declaration="yes" /> <jsp:directive.page contentType="text/html;charset=UTF-8" /> <head><title>Spizza</title></head> <body> <h2>Thank you for your order!</h2> <![CDATA[ <a href="${flowExecutionUrl}&_eventId=finished">Finish</a> ]]> </body></html> |
在“感谢”页面中,会感谢顾客的订购并为其提供一个完成流程的链接。这个链接是整个页面中最有意思的事情,因为它展示了用户与流程交互的唯一办法。
Spring Web Flow 为视图的用户提供了一个 flowExecutionUrl 变量,它包含了流程的 URL。结束链接将一个 “_eventId” 参数关联到 URL 上,以便回到 Web 流程时触发 finished 事件。这个事件将会让流程到达结束状态。
流程将会在结束状态完成。鉴于在流程结束后没有下一步做什么的具体信息,流程将会重新从 identifyCustomer 状态开始,以准备接受另一个披萨订单。
这涵盖了订购披萨的整体流程。但是这个流程并不仅仅是我们在代码清单 8.1 中所看到的这些。我们还需要定义 identifyCustomer、buildOrder、takePayment 这些状态的子流程。让我们从识别用户开始构建这些流程。
收集顾客信息
如果你曾经订购过披萨,你可能会知道流程。他们首先会询问你的电话号码。电话号码除了能够让送货司机在找不到你家的时候打电话给你,还可以作为你在这个披萨店的标识。如果你是回头客,他们可以使用这个电话号码来查找你的地址,这样他们就知道将你的订单派送到什么地方了。
对于一个新的顾客来讲,查询电话号码不会有什么结果。所以接下来,他们将询问你的地址。这样,披萨店的人就会知道你是谁以及将披萨送到哪里。但是在问你要哪种披萨之前,他们要确认你的地址在他们的配送范围之内。如果不在的话,你需要自己到店里并取走披萨。
在每个披萨订单开始前的提问和回答阶段可以用图 8.3 的流程图来表示。
这个流程比整体的披萨流程更有意思。这个流程不是线性的而是在好几个地方根据不同的条件有了分支。例如,在查找顾客后,流程可能结束(如果找到了顾客),也有可能转移到注册表单(如果没有找到顾客)。同样,在 checkDeliveryArea 状态,顾客有可能会被警告也有可能不被警告他们的地址在配送范围之外。
以下的程序清单展示了识别顾客的流程定义。
1 | <flow xmlns="http://www.springframework.org/schema/webflow" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/webflow http://www.springframework.org/schema/webflow/spring-webflow-2.0.xsd"> <input name="order" required="true"/> <!-- Customer --> <view-state id="welcome"> <transition on="phoneEntered" to="lookupCustomer"/> <transition on="cancel" to="cancel"/> </view-state> <action-state id="lookupCustomer"> <evaluate result="order.customer" expression= "pizzaFlowActions.lookupCustomer(requestParameters.phoneNumber)" /> <transition to="registrationForm" on-exception= "com.springinaction.pizza.service.CustomerNotFoundException" /> <transition to="customerReady" /> </action-state> <view-state id="registrationForm" model="order" popup="true" > <on-entry> <evaluate expression= "order.customer.phoneNumber = requestParameters.phoneNumber" /> </on-entry> <transition on="submit" to="checkDeliveryArea" /> <transition on="cancel" to="cancel" /> </view-state> <decision-state id="checkDeliveryArea"> <if test="pizzaFlowActions.checkDeliveryArea(order.customer.zipCode)" then="addCustomer" else="deliveryWarning"/> </decision-state> <view-state id="deliveryWarning"> <transition on="accept" to="addCustomer" /> <transition on="cancel" to="cancel" /> </view-state> <action-state id="addCustomer"> <evaluate expression="pizzaFlowActions.addCustomer(order.customer)" /> <transition to="customerReady" /> </action-state> <!-- End state --> <end-state id="cancel" /> <end-state id="customerReady"> <output name="customer" /> </end-state> <global-transitions> <transition on="cancel" to="cancel" /> </global-transitions></flow> |
这个流程包含了几个新的技巧,包括我们首次使用的 <decisionstate> 元素。因为它是 pizza 流程的子流程,所以它也可以接受 Order 对象作为输入。
与前面一样,我们还是将这个流程的定义分解成一个个的状态,让我们从 welcome 状态开始。
询问电话号码
welcome 状态是一个很简单的视图状态,它欢迎访问 Spizza 站点的顾客并要求他们输入电话号码。这个状态并没有什么特殊的。它有两个转移:如果从视图触发 phoneEntered 事件的话,转移会将流程定向到 lookupCustomer,另外一个就是在全局转移中定义的用来响应 cancel 事件的 cancel 转移。
welcome 状态的有趣之处在于视图本身。视图 welcome 定义在 “/WEBINF/flows/ pizza/customer/welcome.jspx” 中,如下所示。
1 | <%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %><%@ taglib prefix="form" uri="http://www.springframework.org/tags/form" %><html> <head><title>Spring Pizza</title></head> <body> <h2>Welcome to Spring Pizza!!!</h2> <form:form> <input type="hidden" name="_flowExecutionKey" value="${flowExecutionKey}"/> <input type="text" name="phoneNumber"/><br/> <input type="submit" name="_eventId_phoneEntered" value="Lookup Customer" /> </form:form> </body></html> |
这个简单的表单提示用户输入其电话号码。但是表单中有两个特殊的部分来驱动流程继续。
首先要注意的是隐藏的 _flowExecutionKey 输入域。当进入视图状态时,流程暂停并等待用户采取一些行为。赋予视图的流程执行 key(flow execution key)就是一种返回流程的“回程票”(claimticket)。当用户提交表单时,流程执行key会在 _flowExecutionKey 输入域中返回并在流程暂停的位置进行恢复。
还要注意的是提交按钮的名字。按钮名字的 eventId` 部分是提供给 Spring Web Flow 的一个线索,它表明了接下来要触发事件。当点击这个按钮提交表单时,会触发 phoneEntered 事件进而转移到 lookupCustomer。
查找顾客
当欢迎表单提交后,顾客的电话号码将包含在请求参数中并准备用于查询顾客。lookupCustomer 状态的 <evaluate> 元素是查找发生的地方。它将电话号码从请求参数中抽取出来并传递到 pizzaFlowActions bean 的 lookupCustomer() 方法中。
目前,lookupCustomer() 的实现并不重要。只需知道它要么返回 Customer 对象,要么抛出 CustomerNotFoundException 异常。
在前一种情况下,Customer 对象将会设置到 customer 变量中(通过result属性)并且默认的转移将把流程带到 customerReady 状态。但是如果不能找到顾客的话,将抛出 CustomerNotFoundException 并且流程被转移到 registrationForm 状态。
注册新顾客
registrationForm 状态是要求用户填写配送地址的。就像我们之前看到的其他视图状态,它将被渲染成 JSP。JSP 文件如下所示。
1 | <%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %><%@ taglib prefix="form" uri="http://www.springframework.org/tags/form" %><html> <head><title>Spring Pizza</title></head> <body> <h2>Customer Registration</h2> <form:form commandName="order"> <input type="hidden" name="_flowExecutionKey" value="${flowExecutionKey}"/> <b>Phone number: </b><form:input path="customer.phoneNumber"/><br/> <b>Name: </b><form:input path="customer.name"/><br/> <b>Address: </b><form:input path="customer.address"/><br/> <b>City: </b><form:input path="customer.city"/><br/> <b>State: </b><form:input path="customer.state"/><br/> <b>Zip Code: </b><form:input path="customer.zipCode"/><br/> <input type="submit" name="_eventId_submit" value="Submit" /> <input type="submit" name="_eventId_cancel" value="Cancel" /> </form:form> </body></html> |
这并非我们在流程中看到的第一个表单。welcome 视图状态也为顾客展现了一个表单,那个表单很简单,并且只有一个输入域,从请求参数中获得输入域的值也很简单。但是注册表单就比较复杂了。
在这里不是通过请求参数一个个地处理输入域,而是以更好的方式将表单绑定到 Customer 对象上——让框架来做所有繁杂的工作。
检查配送区域
在顾客提供其地址后,我们需要确认他的住址在配送范围之内。如果 Spizza 不能派送给他们,那么我们要让顾客知道并建议他们自己到店面里取走披萨。
为了做出这个判断,我们使用了决策状态。决策状态 checkDeliveryArea 有一个 <if> 元素,它将顾客的邮政编码传递到 pizzaFlowActions bean 的 checkDeliveryArea() 方法中。
这个方法将会返回一个 Boolean 值:如果顾客在配送区域内则为 true,否则为 false。
如果顾客在配送区域内的话,那流程转移到 addCustomer 状态。否则,顾客被带入到 deliveryWarning 视图状态。deliveryWarning 背后的视图就是 “/WEBINF/
flows/pizza/customer/deliveryWarning.jspx”,如下所示:
1 | <%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %><html> <head><title>Spring Pizza</title></head> <body> <h2>Delivery Unavailable</h2> <p>The address is outside of our delivery area. The order may still be taken for carry-out.</p> <a href="${flowExecutionUrl}&_eventId=accept">Accept</a> | <a href="${flowExecutionUrl}&_eventId=cancel">Cancel</a> </body></html> |
在 deliveryWarning.jspx 中与流程相关的两个关键点就是那两个链接,它们允许用户继续订单或者将其取消。通过使用与 welcome 状态相同的 flowExecurtionUrl 变量,这些链接分别触发流程中的 accept 或 cancel 事件。如果发送的是 accept 事件,那么流程会转移到 addCustomer 状态。否则,接下来会是全局的取消转移,子流程将会转移到 cancel 结束状态。
稍后我们将介绍结束状态。让我们先来看看 addCustomer 状态。
存储顾客数据
当流程抵达addCustomer 状态时,用户已经输入了他们的地址。为了将来使用,这个地址需要以某种方式存储起来(可能会存储在数据库中)。addCustomer 状态有一个 <evaluate> 元素,它会调用 pizzaFlowActions bean 的 addCustomer() 方法,并将 customer 流程参数传递进去。
一旦这个过程完成,会执行默认的转移,流程将会转移到 ID 为 customerReady 的结束状态。
结束流程
一般来讲,流程的结束状态并不会那么有意思。但是这个流程中,它不仅仅只有一个结束状态,而是两个。当子流程完成时,它会触发一个与结束状态 ID 相同的流程事件。如果流程只有一个结束状态的话,那么它始终会触发相同的事件。但是如果有两个或更多的结束状态,流程能够影响到调用状态的执行方向。
当 customer 流程走完所有正常的路径后,它最终会到达 ID 为 customerReady 的结束状态。当调用它的披萨流程恢复时,它会接收到一个 customerReady 事件,这个事件将使得流程转移到 buildOrder 状态。
要注意的是 customerReady 结束状态包含了一个 <output> 元素。在流程中这个元素等同于 Java 中的 return 语句。它从子流程中传递一些数据到调用流程。在本示例中,<output> 元素返回 customer 流程变量,这样在披萨流程中,就能够将 identifyCustomer 子流程的状态指定给订单。另一方面,如果在识别顾客流程的任意地方触发了 cancel 事件,将会通过 ID 为 cancel 的结束状态退出流程,这也会在披萨流程中触发 cancel 事件并导致转移(通过全局转移)到披萨流程的结束状态。
构建订单
在识别完顾客之后,主流程的下一件事情就是确定他们想要什么类型的披萨。订单子流程就是用于提示用户创建披萨并将其放入订单中的,如图 8.4 所示。
你可以看到,showOrder 状态位于订单子流程的中心位置。这是用户进入这个流程时看到的第一个状态,它也是用户在添加披萨到订单后要转移到的状态。它展现了订单的当前状态并允许用户添加其他的披萨到订单中。
要添加披萨到订单时,流程会转移到 createPizza 状态。这是另外一个视图状态,允许用户选择披萨的尺寸和面饼上面的配料。在这里,用户可以添加或取消披萨,两种事件都会使流程转移回 showOrder 状态。
从 showOrder 状态,用户可能提交订单也可能取消订单。两种选择都会结束订单子流程,但是主流程会根据选择不同进入不同的执行路径。
如下显示了如何将图中所阐述的内容转变成 Spring Web Flow 定义。
1 | <flow xmlns="http://www.springframework.org/schema/webflow" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/webflow http://www.springframework.org/schema/webflow/spring-webflow-2.0.xsd"> <input name="order" required="true" /> <!-- Order --> <view-state id="showOrder"> <transition on="createPizza" to="createPizza" /> <transition on="checkout" to="orderCreated" /> <transition on="cancel" to="cancel" /> </view-state> <view-state id="createPizza" model="flowScope.pizza"> <on-entry> <set name="flowScope.pizza" value="new com.springinaction.pizza.domain.Pizza()" /> <evaluate result="viewScope.toppingsList" expression="T(com.springinaction.pizza.domain.Topping).asList()" /> </on-entry> <transition on="addPizza" to="showOrder"> <evaluate expression="order.addPizza(flowScope.pizza)" /> </transition> <transition on="cancel" to="showOrder" /> </view-state> <!-- End state --> <end-state id="cancel" /> <end-state id="orderCreated" /></flow> |
这个子流程实际上会操作主流程创建的 Order 对象。因此,我们需要以某种方式将 Order 从主流程传到子流程。你可能还记得在程序清单 8.1 中我们使用了 <input> 元素来将 Order 传递进流程。在这里,我们使用它来接收 Order 对象。如果你觉得这个流程与Java中的方法有 些类似地话,那这里使用的 <input> 元素实际上就定义了这个子流程的签名。这个流程需要一个名为 order 的参数。
接下来,我们会看到 showOrder 状态,它是一个基本的视图状态并具有三个不同的转移,分别用于创建披萨、提交订单以及取消订单。
createPizza 状态更有意思一些。它的视图是一个表单,这个表单可以添加新的 Pizza 对象到订单中。元素添加了一个新的 Pizza 对象到流程作用域内,当表单提交时,表单的内容会填充到该对象中。需要注意的是,这个视图状态引用的 model 是流程作用域内的同一个 Pizza 对象。Pizza 对象将绑定到创建披萨的表单中,如下所示。
1 | <%@ taglib prefix="form" uri="http://www.springframework.org/tags/form" %><div> <h2>Create Pizza</h2> <form:form commandName="pizza"> <input type="hidden" name="_flowExecutionKey" value="${flowExecutionKey}"/> <b>Size: </b><br/> <form:radiobutton path="size" label="Small (12-inch)" value="SMALL"/><br/> <form:radiobutton path="size" label="Medium (14-inch)" value="MEDIUM"/><br/> <form:radiobutton path="size" label="Large (16-inch)" value="LARGE"/><br/> <form:radiobutton path="size" label="Ginormous (20-inch)" value="GINORMOUS"/><br/> <br/> <b>Toppings: </b><br/> <form:checkboxes path="toppings" items="${toppingsList}" delimiter="<br/>"/><br/> <br/> <input type="submit" class="button" name="_eventId_addPizza" value="Continue"/> <input type="submit" class="button" name="_eventId_cancel" value="Cancel"/> </form:form></div> |
当通过 Continue 按钮提交订单时,尺寸和配料选择将会绑定到 Pizza 对象中并且触发 addPizza 转移。与这个转移关联的 <evaluate> 元素表明在转移到 showOrder 状态之前,流程作用域内的 Pizza 对象将会传递给订单的 addPizza() 方法中。
有两种方法来结束这个流程。用户可以点击 showOrder 视图中的 Cancel 按钮或者 Checkout 按钮。这两种操作都会使流程转移到一个 <end-state>。但是选择的结束状态 id 决定了退出这个流程时触发事件,进而最终确定了主流程的下一步行为。主流程要么基于 cancel 事件要么基于 orderCreated 事件进行状态转移。在前者情况下,外边的主流程会结束;在后者情况下,它将转移 到 takePayment 子流程,这也是接下来我们要看的。
支付
吃免费披萨这事儿并不常见。如果 Spizza 披萨店让他们的顾客不提供支付信息就订购披萨的话,估计他们也维持不了多久。在披萨流程要结束的时候,最后的子流程提示用户输入他们的支付信息。这个简单的流程如图 8.5 所示。
流程让用户进行支付像订单子流程一样,支付子流程也使用 <input> 元素接收一个Order对象作为输入。
你可以看到,进入支付子流程的时候,用户会到达 takePayment 状态。这是一个视图状态,在这里用户可以选择使用信用卡、支票或现金进行支付。提交支付信息后,将进入 verifyPayment 状态。这是一个行为状态,它将校验支付信息是否可以接受。
使用 XML 定义的支付流程如下所示:
1 | <flow xmlns="http://www.springframework.org/schema/webflow" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/webflow http://www.springframework.org/schema/webflow/spring-webflow-2.0.xsd"> <input name="order" required="true"/> <view-state id="takePayment" model="flowScope.paymentDetails"> <on-entry> <set name="flowScope.paymentDetails" value="new com.springinaction.pizza.domain.PaymentDetails()" /> <evaluate result="viewScope.paymentTypeList" expression="T(com.springinaction.pizza.domain.PaymentType).asList()" /> </on-entry> <transition on="paymentSubmitted" to="verifyPayment" /> <transition on="cancel" to="cancel" /> </view-state> <action-state id="verifyPayment"> <evaluate result="order.payment" expression= "pizzaFlowActions.verifyPayment(flowScope.paymentDetails)" /> <transition to="paymentTaken" /> </action-state> <!-- End state --> <end-state id="cancel" /> <end-state id="paymentTaken" /></flow> |
在流程进入 takePayment 视图时,元素将构建一个支付表单并使用 SpEL 表达式在流程作用域内创建一个 PaymentDetails 实例,这是支撑表单的对象。它也会创建视图作用域的 paymentTypeList 变量,这个变量是一个列表包含了 PaymentType 枚举(如程序清单 8.11 所示)的值。在这里,SpEL 的 T() 操作用于获得 PaymentType 类,这样就可以调用静态的 asList() 方法。
1 | package com.springinaction.pizza.domain;import java.util.Arrays;import java.util.List;import org.apache.commons.lang3.text.WordUtils;public enum PaymentType { CASH, CHECK, CREDIT_CARD; public static List<PaymentType> asList() { PaymentType[] all = PaymentType.values(); return Arrays.asList(all); } public String toString() { return WordUtils.capitalizeFully(name().replace('_', ' ')); }} |
在面对支付表单的时候,用户可能提交支付也可能会取消。根据做出的选择,支付子流程将以名为 paymentTaken 或 cancel 的 <end-state> 结束。就像其他的子流程一样,不论哪种 <end-state> 都会结束子流程并将控制交给主流程。但是所采用 <end-state> 的 id 将决定主流程中接下来的转移。
现在,我们已经依次介绍了披萨流程及其子流程,并看到了 Spring Web Flow的很多功能。在我们结束 Spring Web Flow 话题之前,让我们快速了解一下如何对流程及其状态的访问增加安全保护。
在下一章中,我们将会看到如何使用 Spring Security 来保护 Spring 应用程序。但现在我们讨论的是 Spring Web Flow,让我们快速地看一下 Spring Web Flow 是如何结合 Spring Security 支持流程级别的安全性的。
Spring Web Flow 中的状态、转移甚至整个流程都可以借助 <secured> 元素实现安全性,该元素会作为这些元素的子元素。例如,为了保护对一个视图状态的访问,你可以这样使用 <secured>:
1 | <view-state id="restricted"> <secured attribute="ROLE_ADMIN" match="all" /></view-state> |
按照这里的配置,只有授予 ROLE_ADMIN 访问权限(借助 attributes 属性)的用户才能访问这个视图状态。attributes 属性使用逗号分隔的权限列表来表明用户要访问指定状态、转移或流程所需要的权限。match 属性可以设置为 any 或 all。如果设置为 any,那么用户必须至少具有一个 attributes 属性所列的权限。 如果设置为 all,那么用户必须具有所有的权限。你可能想知道用户如何具备 <secured> 元素所检验的权限,甚至最开始的时候用户是如何进行登录的?这些问题的答案将在第 9 章给出。
小结
并不是所有的 Web 应用程序都是自由访问的。有时候,必须对用户进行指引、询问适当的问题并基于他们的响应将其引导到特定页面。在这些情况下,应用程序不太像一个菜单选项而更像应用程序与用户之间的对话。
在本章中,我们介绍了 Spring Web Flow,它是能够构建会话式应用程序的 Web 框架。在介绍的同时,我们构建了一个基于流程的披萨订单应用。我们先定义了应用程序的整体流程,从收集顾客信息开始到保存订单到系统中结束。
流程由多个状态和转移组成,它们定义了会话如何从一个状态到另一个状态。状态本身分为好多种:行为状态执行业务逻辑,视图状态涉及到流程中的用户,决策状态动态地引导流程执行,结束状态表明流程的结束,除此之外,还有子流程状态,它们自身是通过流程来定义 的。
最后,我们看到如何限制具有特定权限的用户才能访问流程、状态或转移。但是,我们还没有介绍应用程序对用户的认证以及如何授予用户权限。这就是 Spring Security 能够发挥作用的地方了,而 Spring Security 就是我们第 9 章将要介绍的内容。
保护 Web 应用
本章内容:
- Spring Security 介绍
- 使用 Servlet 规范中的 Filter 保护 Web 应用
- 基于数据库和 LDAP 进行认证
有一点不知道你是否在意过,那就是在电视剧中大多数人从不锁门?这是司空见惯的现象。在《Seinfeld》中,Kramer 经常到 Jerry 的房间里并从他的冰箱里拿东西吃。在《Friends》中,很多剧中的角色经常不敲门就不假思索地进入别人的房间。有一次在伦敦,Ross 甚至闯入 Chandler 的旅馆房间,差一点就撞见 Chandler 和 Ross 妹妹的私情。
在《Leave it to Beaver》热播的时代,人们不锁门这事儿并不值得大惊小怪。但是在这个隐私和安全被看得极其重要的年代,看到电视剧中的角色允许别人大摇大摆地进入自己的寓所或家中,实在让人难以置信。
现在,信息可能是我们最有价值的东西,一些不怀好意的人想尽办法试图偷偷进入不安全的应用程序来窃取我们的数据和身份信息。作为软件开发人员,我们必须采取措施来保护应用程序中的信息。无论你是通过用户名/密码来保护电子邮件账号,还是基于交易 PIN 来保护经纪账户,安全性都是绝大多数应用系统中的一个重要切面 (aspect)。
我有意选择了“切面”这个词来描述应用系统的安全性。安全性是超越应用程序功能的一个关注点。应用系统的绝大部分内容都不应该参与到与自己相关的安全性处理中。尽管我们可以直接在应用程序中编写安全性功能相关的代码(这种情况并不少见),但更好的方式还是将安全性相关的关注点与应用程序本身的关注点进行分离。
如果你觉得安全性听上去好像是使用面向切面技术实现的,那你猜对了。在本章中,我们将使用切面技术来探索保护应用程序的方式。不过我们不必自己开发这些切面 —— 我们将介绍 Spring Security,这是一种基于 Spring AOP 和 Servlet 规范中的 Filter 实现的安全框架。
Spring Security简介
Spring Security 是为基于 Spring 的应用程序提供声明式安全保护的安全性框架。Spring Security 提供了完整的安全性解决方案,它能够在 Web 请求级别和方法调用级别处理身份认证和授权。因为基于 Spring 框架,所以 Spring Security 充分利用了依赖注入(dependency injection,DI)和面向切面的技术。
最初,Spring Security 被称为 Acegi Security。Acegi 是一个强大的安全框架,但是它存在一个严重的问题:那就是需要大量的 XML 配置。我不会向你介绍这种复杂配置的细节。总之一句话,典型的 Acegi 配置有几百行 XML 是很常见的。
到了 2.0 版本,Acegi Security 更名为 Spring Security。但是 2.0 发布版本所带来的不仅仅是表面上名字的变化。为了在 Spring 中配置安全性,Spring Security 引入了一个全新的、与安全性相关的 XML 命名空间。这个新的命名空间连同注解和一些合理的默认设置,将典型的安全性配置从几百行 XML 减少到十几行。 Spring Security 3.0 融入了SpEL,这进一步简化了安全性的配置。
它的最新版本为 3.2,Spring Security 从两个角度来解决安全性问题。它使用 Servlet 规范中的 Filter 保护 Web 请求并限制 URL 级别的访问。Spring Security 还能够使用 Spring AOP 保护方法调用——借助于对象代理和使用通知,能够确保只有具备适当权限的用户才能访问安全保护的方法。
在本章中,我们将会关注如何将 Spring Security 用于 Web 层的安全性之中。在稍后的第 14 章中,我们会重新学习 Spring Security,了解它如何保护方法的调用。
理解 Spring Security 的模块
不管你想使用 Spring Security 保护哪种类型的应用程序,第一件需要做的事就是将 Spring Security 模块添加到应用程序的类路径下。SpringSecurity 3.2 分为 11 个模块,如表 9.1 所示。
| 模 块 | 描 述 |
|---|---|
| ACL | 支持通过访问控制列表(access control list,ACL)为域对象提供安全性 |
| 切面(Aspects) | 一个很小的模块,当使用 Spring Security 注解时,会使用基于 AspectJ 的切面,而不是使用标准的 Spring AOP |
| CAS 客户端(CAS Client) | 提供与 Jasig 的中心认证服务(Central Authentication Service,CAS)进行集成的功能 |
| 配置(Configuration) | 包含通过 XML 和 Java 配置 Spring Security 的功能支持 |
| 核心(Core) | 提供 Spring Security 基本库 |
| 加密(Cryptography) | 提供了加密和密码编码的功能 |
| LDAP | 支持基于 LDAP 进行认证 |
| OpenID | 支持使用 OpenID 进行集中式认证 |
| Remoting | 提供了对 Spring Remoting 的支持 |
| 标签库(TagLibrary) | Spring Security 的 JSP 标签库 |
| Web | 提供了 Spring Security 基于 Filter 的 Web 安全性支持 |
应用程序的类路径下至少要包含 Core 和 Configuration 这两个模块。
Spring Security 经常被用于保护 Web 应用,这显然也是 Spittr 应用的场景,所以我们还需要添加 Web 模块。同时我们还会用到 Spring Security 的 JSP 标签库,所以我们需要将这个模块也添加进来。
现在,我们已经为在 Spring Security 中进行安全性配置做好了准备。让我们看看如何使用 Spring Security 的 XML 命名空间。
过滤 Web 请求
Spring Security 借助一系列 Servlet Filter 来提供各种安全性功能。你可能会想,这是否意味着我们需要在 web.xml 或 WebApplicationInitializer中 配置多个 Filter 呢?实际上,借助于 Spring 的小技巧,我们只需配置一个 Filter 就可以了。
DelegatingFilterProxy 是一个特殊的 Servlet Filter,它本身所做的工作并不多。只是将工作委托给一个 javax.servlet.Filter 实现类,这个实现类作为一个 <bean> 注册在 Spring 应用的上下文中,如图 9.1 所示。

如果你喜欢在传统的 web.xml 中配置 Servlet 和 Filter 的话,可以使用 <filter> 元素,如下所示:
1 | <filter> <filter-name>springSecurityFilterChain</filter-name> <filter-class> org.springframework.web.filter.DelegatingFilteProxy </filter-class></filter> |
在这里,最重要的是 <filter-name> 设置成了 springSecurityFilterChain。这是因为我们马上就会将 SpringSecurity 配置在Web安全性之中,这里会有一个名
为 springSecurityFilterChain 的 Filterbean,DelegatingFilterProxy 会将过滤逻辑委托给它。
如果你希望借助 WebApplicationInitializer 以 Java 的方式来配置 DelegatingFilterProxy 的话,那么我们所需要做的就是创建一个扩展的新类:
1 | package spitter.config;import org.springframwork.security.web.context.AbstractSecurityWebApplicationInitializer;public class SecurityWebInitializer extends AbstractSecurityWebApplicationInitializer{} |
AbstractSecurityWebApplicationInitializer 实现了 WebApplication-Initializer,因此 Spring 会发现它,并用它在 Web 容器中注册 DelegatingFilterProxy。尽管我们可以重载它的 appendFilters() 或 insertFilters() 方法来注册自己选择的 Filter,但是要注册 DelegatingFilterProxy 的话,我们并不需要重载任何方法。
不管我们通过 web.xml 还是通过 AbstractSecurityWebApplicationInitializer 的子类来配置 DelegatingFilterProxy,它都会拦截发往应用中的请求,并将请求委托给 ID 为 springSecurityFilterChain bean。
springSecurityFilterChain 本身是另一个特殊的 Filter,它也被称为 FilterChainProxy。它可以链接任意一个或多个其他的 Filter。Spring Security 依赖一系列 Servlet Filter 来提供不同的安全特性。但是,你几乎不需要知道这些细节,因为你不需要显式声明 springSecurityFilterChain 以及它所链接在一起的其他 Filter。当我们启用 Web 安全性的时候,会自动创建这些 Filter。
为了让 Web 安全性运行起来,我们创建一个最简单的安全性配置。
编写简单的安全性配置
在 Spring Security 的早期版本中(在其还被称为 Acegi Security 之时),为了在 Web 应用中启用简单的安全功能,我们需要编写上百行的 XML 配置。Spring Security 2.0 提供了安全性相关的 XML 配置命名空间,让情况有了一些好转。
Spring 3.2 引入了新的 Java 配置方案,完全不再需要通过 XML 来配置安全性功能了。如下的程序清单展现了 Spring Security 最简单的 Java 配置。
1 | package spitter.config;import org.springframwork.security.web.context.AbstractSecurityWebApplicationInitializer;public class SecurityWebInitializer extends AbstractSecurityWebApplicationInitializer{} |
顾名思义,@EnableWebSecurity 注解将会启用 Web 安全功能。但它本身并没有什么用处,Spring Security 必须配置在一个实现了 WebSecurityConfigurer 的bean中,或者(简单起见)扩展WebSecurityConfigurerAdapter。在 Spring 应用上下文中,任何实现了 WebSecurityConfigurer 的 bean 都可以用来配置 Spring Security,但是最为简单的方式还是像程序清单 9.1 那样扩展 WebSecurityConfigurer Adapter 类。
@EnableWebSecurity 可以启用任意 Web 应用的安全性功能,不过,如果你的应用碰巧是使用 Spring MVC 开发的,那么就应该考虑使用 @EnableWebMvcSecurity 替代它,如程序清单 9.2 所示。
1 | package spitter.config;import org.springframework.context.annotation.Configuration;import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;import org.springframework.security.config.annotation.web.servlet.configuration.EnableWebMvcSecurity; class SecurityConfig extends WebSecurityConfigurerAdapter {} |
除了其他的内容以外,@EnableWebMvcSecurity 注解还配置了一个 Spring MVC 参数解析解析器(argument resolver),这样的话处理器方法就能够通过带有 @AuthenticationPrincipal 注解的参数获得认证用户的 principal(或 username)。它同时还配置了一个 bean,在使用 Spring 表单绑定标签库来定义表单时,这个 bean 会自动添加一个隐藏的跨站请求伪造(cross-site request forgery,CSRF)token 输入域。
看起来似乎并没有做太多的事情,但程序清单 9.1 和 9.2 中的配置类会给应用产生很大的影响。其中任何一种配置都会将应用严格锁定,导致没有人能够进入该系统了!
尽管不是严格要求的,但我们可能希望指定 Web 安全的细节,这要通过重载 WebSecurityConfigurerAdapter 中的一个或多个方法来实现。我们可以通过重载 WebSecurityConfigurerAdapter 的三个 configure() 方法来配置 Web 安全性,这个过程中会使用传递进来的参数设置行为。表 9.2 描述了这三个方法。
| 方 法 | 描 述 |
|---|---|
| configure(WebSecurity) | 通过重载,配置Spring Security的Filter链 |
| configure(HttpSecurity) | 通过重载,配置如何通过拦截器保护请求 |
| configure(AuthenticationManagerBuilder) | 通过重载,配置user-detail服务 |
让我们重新看一下程序清单 9.2,可以看到它没有重写上述三个 configure() 方法中的任何一个,这就说明了为什么应用现在是被锁定的。尽管对于我们的需求来讲默认的 Filter 链是不错的,但是默认的 configure(HttpSecurity) 实际上等同于如下所示:
1 | protected void configure(HttpSecurity http) throws Exception { http .authorizeRequests() .anyRequest().authorized() .and() .formLogin() .and() .httpBasic();} |
这个简单的默认配置指定了该如何保护 HTTP 请求,以及客户端认证用户的方案。通过调用 authorizeRequests() 和 anyRequest().authenticated() 就会要求所有进入应用的 HTTP 请求都要进行认证。它也配置 Spring Security 支持基于表单的登录以及 HTTP Basic 方式的认证。
同时,因为我们没有重载 configure(AuthenticationManagerBuilder) 方法,所以没有用户存储支撑认证过程。没有用户存储,实际上就等于没有用户。所以,在这里所有的请求都需要认证,但是没有人能够登录成功。
为了让 Spring Security 满足我们应用的需求,还需要再添加一点配置。具体来讲,我们需要:
- 配置用户存储;
- 指定哪些请求需要认证,哪些请求不需要认证,以及所需要的权限;
- 提供一个自定义的登录页面,替代原来简单的默认登录页。
除了 Spring Security 的这些功能,我们可能还希望基于安全限制,有选择性地在 Web 视图上显示特定的内容。
但首先,我们看一下如何在认证的过程中配置访问用户数据的服务。
选择查询用户详细信息的服务
假如你计划去一个独家经营的饭店享受一顿晚餐,当然,你会提前几周预订,保证到时候能有一个位置。当到达饭店的时候,你会告诉服务员你的名字。但令人遗憾的是,里面并没有你的预订记录。美好的夜晚眼看就要泡汤了。但是没有人会如此轻易地放弃,你会要求服务员再次确认预订名单。此时,事情变得有些怪异了。
服务员说没有预订名单。你的名字不在名单上——名单上没有任何人——因为根本就不存在这么个名单。这就解释了为什么位置是空的,但我们却进不去。几周后,我们也就明白这家饭店为何最终会关门大吉,被一家墨西哥美食店所代替。
这也是此时我们应用程序的现状。我们没有办法进入应用,即便用户认为他们应该能够登录进去,但实际上却没有允许他们访问应用的数据记录。因为缺少用户存储,现在的应用程序太封闭了,变得不可用。
我们所需要的是用户存储,也就是用户名、密码以及其他信息存储的地方,在进行认证决策的时候,会对其进行检索。
好消息是,Spring Security 非常灵活,能够基于各种数据存储来认证用户。它内置了多种常见的用户存储场景,如内存、关系型数据库以及 LDAP。但我们也可以编写并插入自定义的用户存储实现。
借助 Spring Security 的 Java 配置,我们能够很容易地配置一个或多个数据存储方案。那我们就从最简单的开始:在内存中维护用户存储。
使用基于内存的用户存储
因为我们的安全配置类扩展了 WebSecurityConfigurerAdapter,因此配置用户存储的最简单方式就是重载 configure() 方法,并以 AuthenticationManagerBuilder 作为传入参数。AuthenticationManagerBuilder 有多个方法可以用来配置 Spring Security 对认证的支持。通过 inMemoryAuthentication() 方法,我们可以启用、配置并任意填充基于内存的用户存储。
例如,在如程序清单 9.3 中,SecurityConfig 重载了 configure() 方法,并使用两个用户来配置内存用户存储。
1 | package spittr.config;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.context.annotation.Configuration;import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder;import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;import org.springframework.security.config.annotation.web.servlet.configuration.EnableWebMvcSecurity; class SecurityConfig extends WebSecurityConfigurerAdapter { protected void configure(AuthenticationManagerBuilder auth) throws Exception { auth .inMemoryAuthentication() .withUser("user").password("password").roles("USER").and() .withUser("admin").password("password").roles("USER","ADMIN"); }} |
我们可以看到,configure() 方法中的 AuthenticationManagerBuilder 使用构造者风格的接口来构建认证配置。通过简单地调用 inMemoryAuthentication() 就能启用内存用户存储。但是我们还需要有一些用户,否则的话,这和没有用户并没有什么区别。因此,我们需要调用 withUser() 方法为内存用户存储添加新的用户,这个方法的参数是 username。withUser() 方法返回的是 UserDetailsManagerConfigurer.UserDetailsBuilder,这个对象提供了多个进一步配置用户的方法,包括设置用户密码的 password() 方法以及为给定用户授予一个或多个角色权限的 roles() 方法。
在程序清单 9.3 中,我们添加了两个用户,“user” 和 “admin”,密码均为 “password”。“user” 用户具有 USER 角色,而 “admin” 用户具有 ADMIN 和 USER 两个角色。我们可以看到,and() 方法能够将多个用户的配置连接起来。
除了 password()、roles() 和 and() 方法以外,还有其他的几个方法可以用来配置内存用户存储中的用户信息。表 9.3 描述了UserDetailsManagerConfigurer.UserDetailsBuilder 对象所有可用的方法。
需要注意的是,roles() 方法是 authorities() 方法的简写形式。roles() 方法所给定的值都会添加一个 “ROLE_” 前缀,并将其作为权限授予给用户。实际上,如下的用户配置与程序清单9.3是等价的
1 | auth .inMemoryAuthentication() .withUser("user").password("password").authorities("ROLE_USER") .and() .withUser("admin").password("password").authorities("ROLE_USER", "ROLE_ADMIN"); |
| 方 法 | 描 述 |
|---|---|
| accountExpired(boolean) | 定义账号是否已经过期 |
| accountLocked(boolean) | 定义账号是否已经锁定 |
| and() | 用来连接配置 |
| authorities(GrantedAuthority…) | 授予某个用户一项或多项权限 |
| authorities(List<? extends GrantedAuthority>) | 授予某个用户一项或多项权限 |
| authorities(String…) | 授予某个用户一项或多项权限 |
| credentialsExpired(boolean) | 定义凭证是否已经过期 |
| disabled(boolean) | 定义账号是否已被禁用 |
| password(String) | 定义用户的密码 |
| roles(String…) | 授予某个用户一项或多项角色 |
对于调试和开发人员测试来讲,基于内存的用户存储是很有用的,但是对于生产级别的应用来讲,这就不是最理想的可选方案了。为了用于生产环境,通常最好将用户数据保存在某种类型的数据库之中。
基于数据库表进行认证
用户数据通常会存储在关系型数据库中,并通过 JDBC 进行访问。为了配置 Spring Security 使用以 JDBC 为支撑的用户存储,我们可以使用 jdbcAuthentication() 方法,所需的最少配置如下所示:
1 | dataSource; void configure(AuthenticationManagerBuilder auth) throws Exception { auth .jdbcAuthentication() .dataSource(dataSource);} |
我们必须要配置的只是一个 DataSource,这样的话,就能访问关系型数据库了。在这里,DataSource 是通过自动装配的技巧得到的。
重写默认的用户查询功能
尽管默认的最少配置能够让一切运转起来,但是它对我们的数据库模式有一些要求。它预期存在某些存储用户数据的表。更具体来说,下面的代码片段来源于 Spring Security 内部,这块代码展现了当查找用户信息时所执行的 SQL 查询语句:
1 | public static final String DEF_USERS_BY_USERNAME_QUERY = "select username, password, enabled " + "from users " + "where username = ?";public static final String DEF_AUTHORITIES_BY_USERNAME_QUERY = "select username, authority " + "from authorities " + "where username = ?";public static final String DEF_GROUP_AUTHORITIES_BY_USERNAME_QUERY = "select g.id, g.group_name, ga.authority " + "from groups g, group_members gm, group_authorities ga " + "where gm.username = ? " + "and g.id = ga.group_id " + "and g.id = gm.group_id"; |
在第一个查询中,我们获取了用户的用户名、密码以及是否启用的信息,这些信息会用来进行用户认证。接下来的查询查找了用户所授予的权限,用来进行鉴权,最后一个查询中,查找了用户作为群组的成员所授予的权限。
如果你能够在数据库中定义和填充满足这些查询的表,那么基本上就不需要你再做什么额外的事情了。但是,也有可能你的数据库与上面所述并不一致,那么你就会希望在查询上有更多的控制权。如果是这样的话,我们可以按照如下的方式配置自己的查询:
1 | void configure(AuthenticationManagerBuilder auth) throws Exception { auth .jdbcAuthentication() .dataSource(dataSource) .usersByUsernameQuery( "select username, password, true " + "from Spitter where username=?") .authoritiesByUsernameQuery( "select username, 'ROLE_USER' from Spitter where username=?");} |
在本例中,我们只重写了认证和基本权限的查询语句,但是通过调用 group-AuthoritiesByUsername() 方法,我们也能够将群组权限重写为自定义的查询语句。
将默认的 SQL 查询替换为自定义的设计时,很重要的一点就是要遵循查询的基本协议。所有查询都将用户名作为唯一的参数。认证查询会选取用户名、密码以及启用状态信息。权限查询会选取零行或多行包含该用户名及其权限信息的数据。群组权限查询会选取零行或多行数据,每行数据中都会包含群组 ID、群组名称以及权限。
使用转码后的密码
看一下上面的认证查询,它会预期用户密码存储在了数据库之中。这里唯一的问题在于如果密码明文存储的话,会很容易受到黑客的窃取。但是,如果数据库中的密码进行了转码的话,那么认证就会失败,因为它与用户提交的明文密码并不匹配。
为了解决这个问题,我们需要借助 passwordEncoder() 方法指定一个密码转码器(encoder):
1 | void configure(AuthenticationManagerBuilder auth) throws Exception { auth .jdbcAuthentication() .dataSource(dataSource) .usersByUsernameQuery( "select username, password, true " + "from Spitter where username=?") .authoritiesByUsernameQuery( "select username, 'ROLE_USER' from Spitter where username=?") .passwordEncoder(new StandardPasswordEnconder("53cr3t"));} |
passwordEncoder() 方法可以接受 Spring Security 中 PasswordEncoder 接口的任意实现。Spring Security 的加密模块包括了三个这样的实现:BCryptPasswordEncoder、NoOpPasswordEncoder 和 StandardPasswordEncoder。
上述的代码中使用了 StandardPasswordEncoder,但是如果内置的实现无法满足需求时,你可以提供自定义的实现。PasswordEncoder 接口非常简单:
1 | public interface PasswordEncoder { String encode(CharSequence rawPassword); boolean matched(CharSequence rawPassword, String encodedPassword);} |
不管你使用哪一个密码转码器,都需要理解的一点是,数据库中的密码是永远不会解码的。所采取的策略与之相反,用户在登录时输入的密码会按照相同的算法进行转码,然后再与数据库中已经转码过的密码进行对比。这个对比是在 PasswordEncoder 的 matches() 方法中进行的。
基于 LDAP 进行认证
为了让 Spring Security 使用基于 LDAP 的认证,我们可以使用 ldapAuthentication() 方法。这个方法在功能上类似于 jdbcAuthentication(),只不过是 LDAP 版本。如下的 configure() 方法展现了 LDAP 认证的简单配置:
1 | void configure(AuthenticationManagerBuilder auth) throws Exception { auth .ldapAuthentication() .userSearchFilter("{uid={0}}") .groupSearchFilter("member={0}");} |
方法 userSearchFilter() 和 groupSearchFilter() 用来为基础 LDAP 查询提供过滤条件,它们分别用于搜索用户和组。默认情况下,对于用户和组的基础查询都是空的,也就是表明搜索会在 LDAP 层级结构的根开始。但是我们可以通过指定查询基础来改变这个默认行为:
1 | void configure(AuthenticationManagerBuilder auth) throws Exception { auth .ldapAuthentication() .userSearchBase("ou=people"); .userSearchFilter("{uid={0}}") .groupSearchBase("ou=groups"); .groupSearchFilter("member={0}");} |
userSearchBase() 属性为查找用户提供了基础查询。同样,groupSearchBase() 为查找组指定了基础查询。我们声明用户应该在名为 people 的组织单元下搜索而不是从根开始。而组应该在名为 groups 的组织单元下搜索。
配置密码比对
基于 LDAP 进行认证的默认策略是进行绑定操作,直接通过 LDAP 服务器认证用户。另一种可选的方式是进行比对操作。这涉及将输入的密码发送到 LDAP 目录上,并要求服务器将这个密码和用户的密码进行比对。因为比对是在 LDAP 服务器内完成的,实际的密码能保持私密。
如果你希望通过密码比对进行认证,可以通过声明 passwordCompare() 方法来实现:
1 | void configure(AuthenticationManagerBuilder auth) throws Exception { auth .ldapAuthentication() .userSearchBase("ou=people"); .userSearchFilter("{uid={0}}") .groupSearchBase("ou=groups"); .groupSearchFilter("member={0}") .passwordCompare();} |
默认情况下,在登录表单中提供的密码将会与用户的 LDAP 条目中的 userPassword 属性进行比对。如果密码被保存在不同的属性中,可以通过 passwordAttribute() 方法来声明密码属性的名称:
1 | void configure(AuthenticationManagerBuilder auth) throws Exception { auth .ldapAuthentication() .userSearchBase("ou=people"); .userSearchFilter("{uid={0}}") .groupSearchBase("ou=groups"); .groupSearchFilter("member={0}") .passwordCompare() .passwordEncoder(new Md5PasswordEncoder()) .passwordAttribute("passcode");} |
在本例中,我们指定了要与给定密码进行比对的是 “passcode” 属性。另外,我们还可以指定密码转码器。在进行服务器端密码比对时,有一点非常好,那就是实际的密码在服务器端是私密的。但是进行尝试的密码还是需要通过线路传输到 LDAP 服务器上,这可能会被黑客所拦截。为了避免这一点,我们可以通过调用 passwordEncoder() 方法指定加密策略。
在本示例中,密码会进行 MD5 加密。这需要 LDAP 服务器上密码也使用 MD5 进行加密。
引用远程的 LDAP 服务器
到目前为止,我们忽略的一件事就是 LDAP 和实际的数据在哪里。我们很开心地配置 Spring 使用 LDAP 服务器进行认证,但是服务器在哪里呢?
默认情况下,Spring Security 的 LDAP 认证假设 LDAP 服务器监听本机的 33389 端口。但是,如果你的 LDAP 服务器在另一台机器上,那么可以使用 contextSource() 方法来配置这个地址:
1 | void configure(AuthenticationManagerBuilder auth) throws Exception { auth .ldapAuthentication() .userSearchBase("ou=people"); .userSearchFilter("{uid={0}}") .groupSearchBase("ou=groups"); .groupSearchFilter("member={0}") .contextSource() .url("ldap://habuma.com:389/dc=habuma,dc=com");} |
contextSource() 方法会返回一个 ContextSourceBuilder 对象,这个对象除了其他功能以外,还提供了 url() 方法用来指定 LDAP 服务器的地址。
配置嵌入式的 LDAP 服务器
如果你没有现成的 LDAP 服务器供认证使用,Spring Security 还为我们提供了嵌入式的 LDAP 服务器。我们不再需要设置远程 LDAP 服务器的 URL,只需通过 root() 方法指定嵌入式服务器的根前缀就可以了:
1 | void configure(AuthenticationManagerBuilder auth) throws Exception { auth .ldapAuthentication() .userSearchBase("ou=people"); .userSearchFilter("{uid={0}}") .groupSearchBase("ou=groups"); .groupSearchFilter("member={0}") .contextSource() .root("dc=habuma,dc=com");} |
当 LDAP 服务器启动时,它会尝试在类路径下寻找LDIF 文件来加载数据。LDIF(LDAP Data Interchange Format,LDAP数据交换格式)是以文本文件展现 LDAP 数据的标准方式。每条记录可以有一行或多行,每项包含一个名值对。记录之间通过空行进行分割。
如果你不想让 Spring 从整个根路径下搜索 LDIF 文件的话,那么可以通过调用 ldif() 方法来明确指定加载哪个 LDIF 文件:
1 | void configure(AuthenticationManagerBuilder auth) throws Exception { auth .ldapAuthentication() .userSearchBase("ou=people"); .userSearchFilter("{uid={0}}") .groupSearchBase("ou=groups"); .groupSearchFilter("member={0}") .contextSource() .root("dc=habuma,dc=com") .ldif("classpath:users.ldif");} |
在这里,我们明确要求 LDAP 服务器从类路径根目录下的users.ldif文件中加载内容。如果你比较好奇的话,如下就是一个包含用户数据 LDIF 文件,我们可以使用它来加载嵌入式 LDAP 服务器:
1 | dn: ou=groups,dc=habuma,dc=com objectclass: top objectclass: organizationalUnit ou: groupsdn: ou=people,dc=habuma,dc=com objectclass: top objectclass: organizationalUnit ou: peopledn: uid=habuma, ou=people, dc=hab\oma, dc=comobjectclass: topobjectclass: personobjectclass: organizationalPersonobjectclass: inetOrgPersoncn: Craig Wallssn: Wallsuid: habumauserPassword: passworddn: uid=jsmith,ou=people,dc=habuma,dc=comobjectclass: topobjectclass: personobjectclass: organizationalPersonobjectclass: inetOrgPersoncn: John Smithsn: Smithuid: jsmithuserPassword: passworddn: cn=spittr,outgroups,dc=habuma,dc=comobjectclass: topobjectclass: groupOfNamescn: spittrmember: uid=habuma,ou=people,dc=habuma,dc=com |
Spring Security 内置的用户存储非常便利,并且涵盖了最为常用的用户场景。但是,如果你的认证需求不是那么通用的话,那么就需要创建并配置自定义的用户详细信息服务了。
配置自定义的用户服务
假设我们需要认证的用户存储在非关系型数据库中,如 Mongo 或 Neo4j,在这种情况下,我们需要提供一个自定义的 UserDetailsService 接口实现。
UserDetailsService 接口非常简单:
1 | public interface UserDetailsService { UserDetails loadUserByUsername(String username) throws UsernameNotFoundException;} |
我们所需要做的就是实现 loadUserByUsername() 方法,根据给定的用户名来查找用户。loadUserByUsername() 方法会返回代表给定用户的 UserDetails 对象。如下的程序清单展现了一个 UserDetailsService 的实现,它会从给定的 SpitterRepository 实现中查找用户。
1 | package spittr.security;import org.springframework.security.core.GrantedAuthority;import org.springframework.security.core.authority.SimpleGrantAuthority;import org.springframework.security.core.userdetails.User;import org.springframework.security.core.userdetails.UserDetails;import org.springframework.security.core.userdetails.UserDetailsService;import org.springframework.security.core.userdetails.UsernameNotFoundException;import spittr.Spitter;import spittr.data.SpitterRepository;public class SpitterUserService(SpitterRepository spitterRepository) { private final SpitterRepository spitterRepository; public SpitterUserService(SpitterRepository spitterRepository){ this.spitterRepository = spitterRepository; } public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException { Spitter spitter = spitterRepository.findByUsername(username); if (spitter != null) { List<GrantedAuthority> authorities = new ArrayList<>(); authorities.add(new SimpleGrantedAuthority("ROLE_SPITTER")); } return new User( spitter.getUsername(), spitter.getPassword(), authorities); } throw new UsernameNotFoundException( "User '" + username + "' not found.");} |
SpitterUserService 有意思的地方在于它并不知道用户数据存储在什么地方。设置进来的 SpitterRepository 能够从关系型数据库、文档数据库或图数据中查找Spitter 对象,甚至可以伪造一个。SpitterUserService 不知道也不会关心底层所使用的数据存储。它只是获得 Spitter 对象,并使用它来创建 User 对象。(User
是 UserDetails 的具体实现。)
为了使用 SpitterUserService 来认证用户,我们可以通过 userDetailsService() 方法将其设置到安全配置中:
1 | spitterRepository; void configure(AuthenticationManagerBuilder auth) throws Exception { auth .userDetailsService(new SpitterUserService(spitterRepository));} |
userDetailsService() 方法(类似于 jdbcAuthentication()、ldapAuthentication 以及 inMemoryAuthentication())会配置一个用户存储。不过,这里所使用的不是 Spring 所提供的用户存储,而是使用 UserDetailsService 的实现。
另外一种值得考虑的方案就是修改 Spitter,让其实现 UserDetails。这样的话,loadUserByUsername() 就能直接返回 Spitter 对象了,而不必再将它的值复制到 User 对象中。
拦截请求
在前面的 9.1.3 小节中,我们看到一个特别简单的 Spring Security 配置,在这个默认的配置中,会要求所有请求都要经过认证。有些人可能会说,过多的安全性总比安全性太少要好。但也有一种说法就是要适量地应用安全性。
在任何应用中,并不是所有的请求都需要同等程度地保护。有些请求需要认证,而另一些可能并不需要。有些请求可能只有具备特定权限的用户才能访问,没有这些权限的用户会无法访问。
例如,考虑 Spittr 应用的请求。首页当然是公开的,不需要进行保护。类似地,因为所有的 Spittle 都是公开的,所以展现 Spittle 的页面不需要安全性。但是,创建 Spittle 的请求只有认证用户才能执行。同样,尽管用户基本信息页面是公开的,不需要认证,但是,如果要处理 “/spitters/me” 请求,并展现当前用户的基本信息时,那么就需要进行认证,从而确定要展现谁的信息。
对每个请求进行细粒度安全性控制的关键在于重载 configure(HttpSecurity) 方法。如下的代码片段展现了重载的 configure(HttpSecurity) 方法,它为不同的 URL 路径有选择地应用安全性:
1 | void configure(HttpSecurity http) throws Exception { http .authorizeRequests() .antMatchers("/spitters/me").authenticated() .antMatchers(HttpMethod.POST, "/spittles").authenticated() .anyRequest().permitAll();} |
configure() 方法中得到的 HttpSecurity 对象可以在多个方面配置 HTTP 的安全性。在这里,我们首先调用 authorizeRequests(),然后调用该方法所返回的对象的方法来配置请求级别的安全性细节。其中,第一次调用 antMatchers() 指定了对 “/spitters/me” 路径的请求需要进行认证。第二次调用 antMatchers() 更为具体,说明对 “/spittles” 路径的 HTTP POST 请求必须要经过认证。最后对 anyRequests() 的调用中,说明其他所有的请求都是允许的,不需要认证和任何的权限。
antMatchers() 方法中设定的路径支持 Ant 风格的通配符。在这里我们并没有这样使用,但是也可以使用通配符来指定路径,如下所示:
1 | .antMatchers("/spitter/**").authenticated(); |
我们也可以在一个对 antMatchers() 方法的调用中指定多个路径:
1 | .antMatchers("/spitter/**", "/spittles/mine").authenticated(); |
antMatchers() 方法所使用的路径可能会包括 Ant 风格的通配符,而 regexMatchers() 方法则能够接受正则表达式来定义请求路径。例如,如下代码片段所使用的正则表达式与 “/spitters/**”(Ant风格)功能是相同的:
1 | .regexMatchers("/spitter/.*").authenticated(); |
除了路径选择,我们还通过 authenticated() 和 permitAll() 来定义该如何保护路径。authenticated() 要求在执行该请求时,必须已经登录了应用。如果用户没有认证的话,Spring Security 的 Filter 将会捕获该请求,并将用户重定向到应用的登录页面。同时,permitAll() 方法允许请求没有任何的安全限制。
除了 authenticated() 和 permitAll() 以外,还有其他的一些方法能够用来定义该如何保护请求。表 9.4 描述了所有可用的方案。
| 方 法 | 能够做什么 |
|---|---|
| access(String) | 如果给定的 SpEL 表达式计算结果为 true,就允许访问 |
| anonymous() | 允许匿名用户访问 |
| authenticated() | 允许认证过的用户访问 |
| denyAll() | 无条件拒绝所有访问 |
| fullyAuthenticated() | 如果用户是完整认证的话(不是通过 Remember-me 功能认证的),就允许访问 |
| hasAnyAuthority(String…) | 如果用户具备给定权限中的某一个的话,就允许访问 |
| hasAnyRole(String…) | 如果用户具备给定角色中的某一个的话,就允许访问 |
| hasAuthority(String) | 如果用户具备给定权限的话,就允许访问 |
| hasIpAddress(String) | 如果请求来自给定 IP 地址的话,就允许访问 |
| hasRole(String) | 如果用户具备给定角色的话,就允许访问 |
| not() | 对其他访问方法的结果求反 |
| permitAll() | 无条件允许访问 |
| rememberMe() | 如果用户是通过 Remember-me 功能认证的,就允许访问 |
通过使用表 9.4 中的方法,我们所配置的安全性能够不仅仅限于认证用户。例如,我们可以修改之前的 configure() 方法,要求用户不仅需要认证,还要具备ROLE_SPITTER 权限:
1 | void configure(HttpSecurity http) throws Exception { http .authorizeRequests() .antMatchers("/spitters/me").hasAuthority("ROLE_SPITTER") .antMatchers(HttpMethoed.POST, "/spitters").hasAuthority("ROLE_SPITTER") .anyRequest().permitAll();} |
作为替代方案,我们还可以使用hasRole()方法,它会自动使用 ROLE_ 前缀:
1 | void configure(HttpSecurity http) throws Exception { http .authorizeRequests() .antMatchers("/spitters/me").hasRole("SPITTER") .antMatchers(HttpMethoed.POST, "/spitters").hasRole("SPITTER") .anyRequest().permitAll();} |
我们可以将任意数量的 antMatchers()、regexMatchers() 和 anyRequest() 连接起来,以满足 Web 应用安全规则的需要。但是,我们需要知道,这些规则会按照给定的顺序发挥作用。所以,很重要的一点就是将最为具体的请求路径放在前面,而最不具体的路径(如 anyRequest())放在最后面。如果不这样做的话,那不具体的路径配置将会覆盖掉更为具体的路径配置。
使用Spring表达式进行安全保护
表 9.4 中的大多数方法都是一维的,也就是说我们可以使用 hasRole() 限制某个特定的角色,但是我们不能在相同的路径上同时通过 hasIpAddress() 限制特定的 IP 地址。
另外,除了表 9.4 定义的方法以外,我们没有办法使用其他的条件。如果我们希望限制某个角色只能在星期二进行访问的话,该怎么办呢?
在第 3 章中,我们看到了如何使用 Spring 表达式语言(Spring Expression Language,SpEL),将其作为装配 bean 属性的高级技术。
借助 access() 方法,我们也可以将 SpEL 作为声明访问限制的一种方式。例如,如下就是使用 SpEL 表达式来声明具有 “ROLE_SPITTER” 角色才能访“/spitter/me”URL:
1 | .antMatchers("/spitter/me").access("hasRole('ROLE_SPITTER')"); |
这个对 “/spitter/me” 的安全限制与开始时的效果是等价的,只不过这里使用了 SpEL 来描述安全规则。如果当前用户被授予了给定角色的话,那 hasRole() 表达式的计算结果就为 true。
让 SpEL 更强大的原因在于,hasRole() 仅是 Spring 支持的安全相关表达式中的一种,表 9.5 列出了 Spring Security 支持的所有 SpEL 表达式。
| 安全表达式 | 计 算 结 果 |
|---|---|
| authentication | 用户的认证对象 |
| denyAll | 结果始终为 false |
| hasAnyRole(list of roles) | 如果用户被授予了列表中任意的指定角色,结果为 true |
| hasRole(role) | 如果用户被授予了指定的角色,结果为 true |
| hasIpAddress(IP Address) | 如果请求来自指定 IP 的话,结果为 true |
| isAnonymous() | 如果当前用户为匿名用户,结果为 true |
| isAuthenticated() | 如果当前用户进行了认证的话,结果为 true |
| isFullyAuthenticated() | 如果当前用户进行了完整认证的话(不是通过 Remember-me 功能进行的认证),结果为 true |
| isRememberMe() | 如果当前用户是通过 Remember-me 自动认证的,结果为 true |
| permitAll | 结果始终为 true |
| principal | 用户的 principal 对象 |
在掌握了 Spring Security 的 SpEL 表达式后,我们就能够不再局限于基于用户的权限进行访问限制了。例如,如果你想限制 “/spitter/me” URL 的访问,不仅需要 ROLE_SPITTER,还需要来自指定的 IP 地址,那么我们可以按照如下的方式调用 access() 方法:
1 | .antMatchers("/spitter/me").access("hasRole('ROLE_SPITTER') and hasIpAddress('192.168.1.2')"); |
我们可以使用 SpEL 实现各种各样的安全性限制。我敢打赌,你已经在想象基于 SpEL 所能实现的那些有趣的安全性限制了。但现在,让我们看一下 Spring Security 拦截请求的另外一种方式:强制通道的安全性。
强制通道的安全性
使用 HTTP 提交数据是一件具有风险的事情。如果使用 HTTP 发送无关紧要的信息,这可能不是什么大问题。但是如果你通过 HTTP 发送诸如密码和信用卡号这样的敏感信息的话,那你就是在找麻烦了。通过 HTTP 发送的数据没有经过加密,黑客就有机会拦截请求并且能够看到他们想看的数据。这就是为什么敏感信息要通过 HTTPS 来加密发送的原因。
使用 HTTPS 似乎很简单。你要做的事情只是在 URL 中的 HTTP 后加上一个字母 “s” 就可以了。是这样吗?
这是真的,但这是把使用 HTTPS 通道的责任放在了错误的地方。通过添加 “s” 我们就能很容易地实现页面的安全性,但是忘记添加 “s” 同样也是很容易出现的。如果我们的应用中有多个链接需要 HTTPS,估计在其中的一两个上忘记添加 “s” 的概率还是很高的。
另一方面,你可能还会在原本并不需要 HTTPS 的地方,误用 HTTPS。
传递到 configure() 方法中的 HttpSecurity 对象,除了具有 authorizeRequests() 方法以外,还有一个 requiresChannel() 方法,借助这个方法能够为各种 URL 模式声明所要求的通道。
作为示例,可以参考 Spittr 应用的注册表单。尽管Spittr应用不需要信用卡号、社会保障号或其他特别敏感的信息,但用户有可能仍然希望信息是私密的。为了保证注册表单的数据通过 HTTPS 传送,我们可以在配置中添加 requiresChannel() 方法,如下所示:
1 | void configure(HttpSecurity http) throws Exception { http .authorizeRequests() .antMatchers("/spitter/me").hasRole("SPITTER") .antMatchers(HttpMethod.POST, "/spittles").hasRole("SPITTER") .anyRequest().permitAll() .and() .requeresChannel() .antMatchers("/spitter/form").requiresSecure();} |
不论何时,只要是对“/spitter/form”的请求,Spring Security都视为需要安全通道(通过调用requiresChannel()确定的)并自动将请求重定向到HTTPS上。
与之相反,有些页面并不需要通过 HTTPS 传送。例如,首页不包含任何敏感信息,因此并不需要通过 HTTPS 传送。我们可以使用 requiresInsecure() 代替requiresSecure() 方法,将首页声明为始终通过 HTTP 传送:
1 | .antMatchers("/").requiresInecure(); |
如果通过 HTTPS 发送了对 “/” 的请求,Spring Security 将会把请求重定向到不安全的 HTTP 通道上。
在强制要求通道时,路径的选取方案与 authorizeRequests() 是相同的。在程序清单 9.5 中,使用了 antMatches(),但我们也可以使用 regexMatchers() 方法,通过正则表达式选取路径模式。
防止跨站请求伪造
我们可以回忆一下,当一个 POST 请求提交到 “/spittles” 上时,SpittleController 将会为用户创建一个新的 Spittle 对象。但是,如果这个 POST 请求来源于其他站点的话,会怎么样呢?如果在其他站点提交如下表单,这个 POST 请求会造成什么样的结果呢?
1 | <form method="POST" action="http://www.spittr.com/spittles"> <input type="hidden" name="message" value="I'm stupid!" /> <input type="submit" value="Click here to win a new car!" /></form> |
假设你禁不住获得一辆新汽车的诱惑,点击了按钮——那么你将会提交表单到如下地址 http://www.spittr.com/spittles。如果你已经登录到了 spittr.com,那么这就会广播一条消息,让每个人都知道你做了一件蠢事。
这是跨站请求伪造(cross-site request forgery,CSRF)的一个简单样例。简单来讲,如果一个站点欺骗用户提交请求到其他服务器的话,就会发生 CSRF 攻击,这可能会带来消极的后果。尽管提交 “I’m stupid!” 这样的信息到微博站点算不上什么 CSRF 攻击的最糟糕场景,但是你可以很容易想到更为严重的攻击情景,它可能会对你的银行账号执行难以预期的操作。
从 Spring Security 3.2 开始,默认就会启用 CSRF 防护。实际上,除非你采取行为处理CSRF防护或者将这个功能禁用,否则的话,在应用中提交表单时,你可能会遇到问题。
Spring Security 通过一个同步 token 的方式来实现 CSRF 防护的功能。它将会拦截状态变化的请求(例如,非 GET、HEAD、OPTIONS 和 TRACE 的请求)并检查CSRF token。如果请求中不包含 CSRF token 的话,或者 token 不能与服务器端的 token 相匹配,请求将会失败,并抛出 CsrfException 异常。
这意味着在你的应用中,所有的表单必须在一个 _csrf 域中提交token,而且这个token必须要与服务器端计算并存储的token一致,这样的话当表单提交的时候,才能进行匹配。
好消息是,Spring Security 已经简化了将 token 放到请求的属性中这一任务。如果你使用 Thymeleaf 作为页面模板的话,只要 <form> 标签的 action 属性添加了 Thymeleaf 命名空间前缀,那么就会自动生成一个_csrf 隐藏域:
1 | <form method="POST" th:action="@{/spittles}"> ...</form> |
如果使用 JSP 作为页面模板的话,我们要做的事情非常类似:
1 | <input type="hidden" name="${_csrf.parameterName}" value="${_csrf.token}" /> |
更好的功能是,如果使用 Spring 的表单绑定标签的话,<sf:form> 标签会自动为我们添加隐藏的 CSRF token 标签。
处理 CSRF 的另外一种方式就是根本不去处理它。我们可以在配置中通过调用 csrf().disable() 禁用 Spring Security 的 CSRF 防护功能,如下所示:
1 | void configure(HttpSecurity http) throws Exception { http ... .csrf() .disable();} |
需要提醒的是,禁用 CSRF 防护功能通常来讲并不是一个好主意。如果这样做的话,那么应用就会面临 CSRF 攻击的风险。只有在深思熟虑之后,才能使用程序清单 9.6 中的配置。
我们已经配置好了用户存储,也配置好了使用 Spring Security 来拦截请求,那么接下来就该提示用户输入凭证了。
认证用户
如果你使用程序清单 9.1 中最简单的 Spring Security 配置的话,那么就能无偿地得到一个登录页。实际上,在重写 configure(HttpSecurity) 之前,我们都能使用一个简单却功能完备的登录页。但是,一旦重写了 configure(HttpSecurity) 方法,就失去了这个简单的登录页面。
不过,把这个功能找回来也很容易。我们所需要做的就是在 configure(HttpSecurity) 方法中,调用 formLogin(),如下面的程序清单所示。
请注意,和前面一样,这里调用 add() 方法来将不同的配置指令连接在一起。如果我们访问应用的 “/login” 链接或者导航到需要认证的页面,那么将会在浏览器中展现登录页面。如图 9.2 所示,在审美上它没有什么令人兴奋的,但是它却能实现所需的功能。
1 | void configure(HttpSecurity http) throws Exception { http .formLogin() .and() .authorizeRequests() .antMatchers("/spitter/me").hasRole("SPITTER") .antMatchers(HttpMethod.POST, "/spittles").hasRole("SPITTER") .anyRequest().permitAll() .and() .requeresChannel() .antMatchers("/spitter/form").requiresSecure();} |
我敢打赌,你肯定希望在自己的应用程序中能有一个比默认登录页更漂亮的登录页面。如果这个普通的登录页面破坏了我们原本精心设计的漂亮站点,那真的是件很令人遗憾的事情。没问题!接下来,我们就看一下如何为应用添加自定义的登录页面。
添加自定义的登录页
创建自定义登录页的第一步就是了解登录表单中都需要些什么。只需看一下默认登录页面的HTML源码,我们就能了解需要些什么:
1 | <html> <head><title>Login Page</title></head> <body onload='document.f.username.focus();'> <h3>Login with Username and Password</h3> <form name='f' th:action='/spittr/login' method='POST'> <table> <tr><td>User:</td><td> <input type='text' name='username' value='' /></td></tr> <tr><td>Password:</td> <td><input type='password' name='password'/></td></tr> <tr><td colspan='2'> <input name="submit" type="submit" value="Login"/></td></tr> <input name="_csrf" type="hidden" value="5sdf4-dfsd45s-4579-sdhf564fds45" /> </table> </form> </body></html> |
需要注意的一个关键点是 <form> 提交到了什么地方。同时还需要注意 username 和 password 输入域,在你的登录页中,需要同样的输入域。最后,假设没有禁用 CSRF 的话,还需要保证包含了值为 CSRFtoken 的 _csrf 输入域。
如下程序清单所展现的 Thymeleaf 模板提供了一个与 Spittr 应用风格一致的登录页。
1 | <html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org"> <head> <title>Spitter</title> <link rel="stylesheet" type="text/css" th:href="@{/resources/style.css}"></link> </head> <body onload='document.f.username.focus();'> <div id="header" th:include="page :: header"></div> <div id="content"> <a th:href="@{/spitter/register}">Register</a> <form name='f' th:action='@{/login}' method='POST'> <table> <tr><td>User:</td><td> <input type='text' name='username' value='' /></td></tr> <tr><td>Password:</td> <td><input type='password' name='password'/></td></tr> <tr><td colspan='2'> <input id="remember_me" name="remember-me" type="checkbox"/> <label for="remember_me" class="inline">Remember me</label></td></tr> <tr><td colspan='2'> <input name="submit" type="submit" value="Login"/></td></tr> </table> </form> </div> <div id="footer" th:include="page :: copy"></div> </body></html> |
需要注意的是,在 Thymeleaf 模板中,包含了 username 和 password 输入域,就像默认的登录页一样,它也提交到了相对于上下文的 “/login” 页面上。因为这是一个 Thymeleaf 模板,因此隐藏的 _csrf 域将会自动添加到表单中。
启用HTTP Basic认证
对于应用程序的人类用户来说,基于表单的认证是比较理想的。但是在第 16 章中,将会看到如何将我们 Web 应用的页面转化为 RESTful API。当应用程序的使用者是另外一个应用程序的话,使用表单来提示登录的方式就不太适合了。
HTTP Basic 认证(HTTP Basic Authentication)会直接通过 HTTP 请求本身,对要访问应用程序的用户进行认证。你可能在以前见过 HTTP Basic 认证。当在 Web 浏览器中使用时,它将向用户弹出一个简单的模态对话框。
但这只是 Web 浏览器的显示方式。本质上,这是一个 HTTP 401 响应,表明必须要在请求中包含一个用户名和密码。在 REST 客户端向它使用的服务进行认证的场景中,这种方式比较适合。
如果要启用 HTTP Basic 认证的话,只需在 configure() 方法所传入的 HttpSecurity 对象上调用 httpBasic() 即可。另外,还可以通过调用 realmName() 方法指定域。如下是在 Spring Security 中启用 HTTP Basic 认证的典型配置:
1 | void configure(HttpSecurity http) throws Exception { http .formLogin() .loginPage("/login"); .and() .httpBasic() .realmName("Spittr") .and() ...} |
注意,和前面一样,在 configure() 方法中,通过调用 add() 方法来将不同的配置指令连接在一起。在 httpBasic() 方法中,并没有太多的可配置项,甚至不需要什么额外配置。HTTP Basic 认证要么开启要么关闭。所以,与其进一步研究这个话题,还不如看看如何通过 Remember-me 功能实现用户的自动认证。
启用Remember-me功能
对于应用程序来讲,能够对用户进行认证是非常重要的。但是站在用户的角度来讲,如果应用程序不用每次都提示他们登录是更好的。这就是为什么许多站点提供了 Remember-me 功能,你只要登录过一次,应用就会记住你,当再次回到应用的时候你就不需要登录了。
Spring Security 使得为应用添加 Remember-me 功能变得非常容易。为了启用这项功能,只需在 configure() 方法所传入的 HttpSecurity 对象上调用 rememberMe() 即可。
1 | void configure(HttpSecurity http) throws Exception { http .formLogin() .loginPage("/login"); .and() .rememberMe() .tokenValiditySeconds(2419200) .key("spittrKey") ...} |
在这里,我们通过一点特殊的配置就可以启用 Remember-me 功能。默认情况下,这个功能是通过在 cookie 中存储一个 token 完成的,这个 token 最多两周内有效。但是,在这里,我们指定这个 token 最多四周内有效(2,419,200 秒)。
存储在 cookie 中的 token 包含用户名、密码、过期时间和一个私钥——在写入 cookie 前都进行了 MD5 哈希。默认情况下,私钥的名为 SpringSecured,但在这里我们将其设置为 spitterKey,使它专门用于 Spittr 应用。
如此简单。既然 Remember-me 功能已经启用,我们需要有一种方式来让用户表明他们希望应用程序能够记住他们。为了实现这一点,登录请求必须包含一个名为 remember-me 的参数。在登录表单中,增加一个简单复选框就可以完成这件事情:
1 | <input id="remember_me" name="remember-me" type="checkbox" /><label for="remember_me" class="inline">Remember me</label> |
在应用中,与登录同等重要的功能就是退出。如果你启用 Rememberme 功能的话,更是如此,否则的话,用户将永远登录在这个系统中。我们下面将看一下如何添加退出功能。
退出
其实,按照我们的配置,退出功能已经启用了,不需要再做其他的配置了。我们需要的只是一个使用该功能的链接。
退出功能是通过 Servlet 容器中的 Filter 实现的(默认情况下),这个 Filter 会拦截针对 “/logout” 的请求。因此,为应用添加退出功能只需添加如下的链接即可(如下以 Thymeleaf 代码片段的形式进行了展现):
1 | <a th:href="@{/logout}">Logout</a> |
当用户点击这个链接的时候,会发起对 “/logout” 的请求,这个请求会被 Spring Security 的 LogoutFilter 所处理。用户会退出应用,所有的 Remember-me token 都会被清除掉。在退出完成后,用户浏览器将会重定向到 “/login?logout”,从而允许用户进行再次登录。
如果你希望用户被重定向到其他的页面,如应用的首页,那么可以在 configure() 中进行如下的配置:
1 | void configure(HttpSecurity http) throws Exception { http .formLogin() .loginPage("/login"); .and() .logout() .logoutSuccessUrl("/") ...} |
在这里,和前面一样,通过add()连接起了对 logout() 的调用。logout() 提供了配置退出行为的方法。在本例中,调用 logoutSuccessUrl() 表明在退出成功之后,浏览器需要重定向到 “/”。
除了 logoutSuccessUrl() 方法以外,你可能还希望重写默认的 LogoutFilter 拦截路径。我们可以通过调用 logoutUrl() 方法实现这一功能:
1 | .logout().logoutSuccessUrl("/").logoutUrl("/signout"); |
到目前为止,我们已经看到了如何在发起请求的时候保护 Web 应用。这假设安全性主要涉及阻止用户访问没有权限的 URL。但是,如果我们能够不给用户显示其无权访问的连接,那么这也是一个很好的思路。接下来,我们将会看一下如何添加视图级别的安全性。
保护视图
当为浏览器渲染 HTML 内容时,你可能希望视图中能够反映安全限制和相关的信息。一个简单的样例就是渲染用户的基本信息(比如显示“您已经以……身份登录”)。或者你想根据用户被授予了什么权限,有条件地渲染特定的视图元素。
在第 6 章,我们看到了在 Spring MVC 应用中渲染视图的两个最重要的可选方案:JSP 和 Thymeleaf。不管你使用哪种方案,都有办法在视图上实现安全性。 Spring Security 本身提供了一个 JSP 标签库,而 Thymeleaf 通过特定的方言实现了与 Spring Security 的集成。
让我们看一下如何将 Spring Security 用到视图中,就从 Spring Security 的 JSP 标签库开始吧。
使用 Spring Security 的 JSP 标签库
Spring Security 的 JSP 标签库很小,只包含三个标签,如表 9.6 所示。
| JSP标签 | 作 用 |
|---|---|
<security:accesscontrollist> |
如果用户通过访问控制列表授予了指定的权限,那么渲染该标签体中的内容 |
<security:authentication> |
渲染当前用户认证对象的详细信息 |
<security:authorize> |
如果用户被授予了特定的权限或者 SpEL 表达式的计算结果为 true,那么渲染该标签体中的内容 |
为了使用 JSP 标签库,我们需要在对应的JSP中声明它:
1 | <%@ taglib prefix="security" uri="http://www.springframework.org/security/tags" %> |
只要标签库在 JSP 文件中进行了声明,我们就可以使用它了。让我们看看 Spring Security 提供的这三个标签是如何工作的。
访问认证信息的细节
借助 Spring Security JSP 标签库,所能做到的最简单的一件事情就是便利地访问用户的认证信息。例如,对于 Web 站点来讲,在页面顶部以用户名标示显示“欢迎”或“您好”信息是很常见的。这恰恰是 <security:authentication> 能为我们所做的事情。例如:
1 | Hello <security:authentication property="pricipal.username" />! |
其中,property 用来标示用户认证对象的一个属性。可用的属性取决于用户认证的方式。但是,我们可以依赖几个通用的属性,在不同的认证方式下,它们都是可用的,如表 9.7 所示。
| 认 证 属 性 | 描 述 |
|---|---|
| authorities | 一组用于表示用户所授予权限的 GrantedAuthority 对象 |
| Credentials | 用于核实用户的凭证(通常,这会是用户的密码) |
| details | 认证的附加信息(IP 地址、证件序列号、会话 ID 等) |
| principal | 用户的基本信息对象 |
在我们的示例中,实际上渲染的是 principal 属性中嵌套的 username 属性。当像前面示例那样使用时,<security:authentication> 将在视图中渲染属性的值。但是如果你愿意将其赋值给一个变量,那只需要在var属性中指明变量的名字即可。例如,如下展现了如何将其设置给名为 loginId 的属性:
1 | <security:authentication property="principal.username" var="loginId" /> |
这个变量默认是定义在页面作用域内的。但是如果你愿意在其他作用域内创建它,例如请求或会话作用域(或者是能够在 javax.servlet.jsp.PageContext 中获取的其他作用域),那么可以通过 scope 属性来声明。例如,要在请求作用域内创建这个变量,那可以使用 <security:authentication> 按照如下的方式来设置:
1 | <security:authentication property="principal.username" var="loginId" scope="request" /> |
<security:authentication> 标签非常有用,但这只是 Spring Security JSP 标签库功能的基础功能。让我们来看一下如何根据用户的权限来渲染内容。
条件性的渲染内容
有时候视图上的一部分内容需要根据用户被授予了什么权限来确定是否渲染。对于已经登录的用户显示登录表单,或者对还未登录的用户显示个性化的问候信息都是毫无意义的。
Spring Security 的 <security:authorize> JSP 标签能够根据用户被授予的权限有条件地渲染页面的部分内容。例如,在 Spittr 应用中,对于没有 ROLE_SPITTER 角色的用户,我们不会为其显示添加新 Spitter 记录的表单。程序清单 9.9 展现了如何使用 <security:authorize> 标签来为具有 ROLE_SPITTER 角色的用户显示 Spitter 表单。
1 | <sec:authorize access="hasRole('ROLE_SPITTER')"> <s:url value="/spittles" var="spittle_url" /> <sf:form modelAttribute="spittle" action="${spittle_url}"> <sf:label path="text"> <s:message code="label.spittle" text="Enter spittle:" /> </sf:label> <sf:textarea path="text" row="2" cols="40" /> <sf:errors path="text" /> <br/> <div class="spitItSubmit"> <input type="submit" value="Spit it !" class="status-btn round-btn disabled" /> </div> </sf:form></sec:authorize> |
access 属性被赋值为一个 SpEL 表达式,这个表达式的值将确定 <security: authorize> 标签主体内的内容是否渲染。这里我们使用了 hasRole(‘ROLE_SPITTER’) 表达式来确保用户具有 ROLE_SPITTER 角色。但是,当你设置 access 属性时,可以任意发挥 SpEL 的强大威力,包括表 9.5 所示的 Spring Security 所提供的表达式。
借助于这些可用的表达式,可以构造出非常有意思的安全性约束。例如,假设应用中有一些管理功能只能对用户名为 habuma 的用户可用。也许你会像这样使用 isAuthenticated() 和 principal 表达式:
1 | <security:authorize access="isAuthenticated and principal.username=='habuma'"> <a href="/admin">Administration</a></security:authorize> |
我相信你能设计出比这个更有意思的表达式,可以尽情发挥你的想象力来构造更多的安全性约束。借助于 SpEL,选择其实是无限的。
但是我构造的这个示例还有一件事让人很困惑。尽管我想限制管理功能只能给 habuma 用户,但使用 JSP 标签表达式并不见得理想。确实,它能在视图上阻止链接的渲染。但是没有什么可以阻止别人在浏览器的地址栏手动输入“/admin” 这个 URL。
根据我们在本章前面所学,这是一个很容易解决的问题。在安全配置中,添加一个对 antMatchers() 方法的调用将会严格限制对 “/admin” 这个 URL 的访问。
1 | .antMatchers("/admin").access("isAuthenticated and principal.username='habuma'"); |
现在,管理功能已经被锁定了。URL 地址得到了保护,并且到这个 URL 的链接在用户没有授权使用的情况下不会显示。但是为了做到这一点,我们需要在两个地方声明 SpEL 表达式——在安全配置中以及在 <security:authorize> 标签的 access 属性中。有没有办法消除这种重复性,并且还要确保只有规则条件满足的情况下才渲染管理功能的链接呢?
这是 <security:authorize> 的 url 属性所要做的事情。它不像 access 属性那样明确声明安全性限制,url 属性对一个给定的 URL 模式会间接引用其安全性约束。鉴于我们已经在 Spring Security 配置中为 “/admin” 声明了安全性约束,所以我们可以这样使用 url 属性:
1 | <security:authorize url="/admin"> <spring:url value="/admin" var="admin_url" /> <br/> <a href="${admin_url}">Admin</a></security:authorize> |
因为只有基本信息中用户名为 “habuma” 的已认证用户才能访问 “/admin” URL,所以只有满足以上条件,<security:authorize> 标签主体中的内容才会被渲染。我们只在一个地方配置了表达式(安全配置中),但是在两个地方进行了应用。
Spring Security 的 JSP 标签库非常便利,尤其是只给满足条件的用户渲染特定的视图元素时更是如此。如果我们选择 Thymeleaf 而不是 JSP 作为视图方案的话,我们其实还能延续这种好运气。我们已经看到 Thymeleaf 的 Spring 方言能够自动为表单添加隐藏的 CSRF token,现在我们看一下 Thymeleaf 如何支持 Spring Security。
使用 Thymeleaf 的 Spring Security 方言
与 Spring Security 的 JSP 标签库类似,Thymeleaf 的安全方言提供了条件化渲染和显示认证细节的能力。表 9.8 列出了安全方言所提供的属性。
表9.8 Thymeleaf的安全方言提供了与Spring Security标签库相对应的属性
| 属 性 | 作 用 |
|---|---|
| sec:authentication | 渲染认证对象的属性。类似于Spring Security的sec:authentication/JSP标签 |
| sec:authorize | 基于表达式的计算结果,条件性的渲染内容。类似于SpringSecurity的sec:authorize/JSP标签 |
| sec:authorize-acl | 基于表达式的计算结果,条件性的渲染内容。类似于SpringSecurity的sec:accesscontrollist/ JSP标签 |
| sec:authorize-expr | sec:authorize属性的别名 |
| sec:authorize-url | 基于给定URL路径相关的安全规则,条件性的渲染内容。类似于Spring Security的sec:authorize/ JSP标签使用url属性时的场景 |
为了使用安全方言,我们需要确保 Thymeleaf Extras Spring Security 已经位于应用的类路径下。然后,还需要在配置中使用 SpringTemplateEngine 来注册SpringSecurity Dialect。程序清单 9.10 所展现的 @Bean 方法声明了 SpringTemplateEngine bean,其中就包含了 SpringSecurityDialect。
1 | SpringTemplateEngine templateEngine(TemplateResolver templateResolver) { SpringTemplateEngine templateEngine = new SpringTemplateEngine(); templateEngine.setTemplateResolver(templateResolver); templateEngine.addDialect(new SpringSecurityDialect()); return templateEngine;} |
安全方言注册完成之后,我们就可以在 Thymeleaf 模板中使用它的属性了。首先,需要在使用这些属性的模板中声明安全命名空间:
1 | <html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org" xmlns:sec="http://www.thymeleaf.org/thymeleaf-extras-springsecurity3">...</html> |
在这里,标准的 Thymeleaf 方法依旧与之前一样,使用 th 前缀,安全方言则设置为使用 sec 前缀。
这样我们就能在任意合适的地方使用 Thymeleaf 属性了。比如,假设我们想要为认证用户渲染“Hello”文本。如下的 Thymeleaf 模板代码片段就能完成这项任务:
1 | <div sec:authorize="isAuthenticated"> Hello <span sec:authentication="name">someone</span></div> |
sec:authorize 属性会接受一个 SpEL 表达式。如果表达式的计算结果为 true,那么元素的主体内容就会渲染。在本例中,表达式为 isAuthenticated(),所以只有用户已经进行了认证,才会渲染 <div> 标签的主体内容。就这个标签的主体内容部分而言,它的功能是使用认证对象的 name 属性提示 “Hello” 文本。
你可能还记得,在 Spring Security 中,借助 <sec:authorize> JSP 标签的 url 属性能够基于给定 URL 的权限有条件地渲染内容。在 Thymeleaf 中,我们可以通过 sec:authorize-url 属性完成相同的功能。例如,如下 Thymeleaf 代码片段所实现的功能与之前 <sec:authorize> JSP标签和 url 属性所实现的功能是相同的:
1 | <span sec:authorize-url="/admin"> <br/> <a th:href="@{/admin}">Admin</></span> |
如果用户有权限访问 “/admin” 的话,那么到管理页面的链接就会渲染,否则的话,这个链接将不会渲染。
小结
对于许多应用而言,安全性都是非常重要的切面。Spring Security 提供了一种简单、灵活且强大的机制来保护我们的应用程序。
借助于一系列 Servlet Filter,Spring Security 能够控制对 Web 资源的访问,包括 Spring MVC 控制器。借助于 Spring Security 的 Java 配置模型,我们不必直接处理 Filter,能够非常简洁地声明 Web 安全性功能。
当认证用户时,Spring Security 提供了多种选项。我们探讨了如何基于内存用户库、关系型数据库和 LDAP 目录服务器来配置认证功能。如果这些可选方案无法满足认证需求的话,我们还学习了如何创建和配置自定义的用户服务。
在前面的几章中,我们看到了如何将Spring运用到应用程序的前端。在接下来的章中,我们将会继续深入这个技术栈,学习 Spring 如何在后端发挥作用,下一章将会首先从 Spring 的 JDBC 抽象开始。
后端中的 Spring
尽管用户看到的内容是由Web应用所提供的页面,但是在这背后,实际的工作是在后端服务器中发生的,在这里会处理和持久化数据。第3部分将会关注Spring如何帮助我们在后端处理数据。
多年以来,关系型数据库一直是企业级应用中的统治者。在第 10 章 “通过 Spring 和 JDBC 征服数据库” 中,我们将会看到如何使用 Spring 的 JDBC 抽象来查询关系型数据库,这要比原生的 JDBC 简单得多。
如果你不喜欢 JDBC 风格的话,在第 11 章 “通过对象-关系映射持久化数据” 中,将会展现如何与 ORM 框架进行集成,这些框架包括 Hibernate 以及其他的 Java 持久化 API(Java Persistence API,JPA)实现。除此之外,还将会看到如何发挥 Spring Data JPA 的魔力,在运行时自动生成 Repository 实现。
关系型数据库不一定是所有场景下的最佳选择,因此,第 12 章“使用 NoSQL 数据库”将会研究其他的 Spring Data 项目,它们能够持久化各种非关系型数据库中的数据,包括 MongoDB、Neo4j 和 Redis。
第 13 章“缓存数据”为上述的持久化章提供了一个缓存层,如果数据已经可用的话,它会避免数据库操作,从而提升应用的性能。
与前端类似,安全性在后端也是一个很重要的方面。在第 14 章“保护方法应用”中,将会把 Spring Security 应用于后端,它会拦截方法的调用并确保调用者被授予了适当的权限。
通过 Spring 和 JDBC 征服数据库
本章内容:
- 定义 Spring 对数据访问的支持
- 配置数据库资源
- 使用 Spring 的 JDBC 模版
在掌握了 Spring 容器的核心知识之后,是时候将它在实际应用中进行使用了。数据持久化是一个非常不错的起点,因为几乎所有的企业级应用程序中都存在这样的需求。我们可能都处理过数据库访问功能,在实际的工作中也发现数据访问有一些不足之处。我们必须初始化数据访问框架、打开连接、处理各种异常和关闭连接。如果上述操作出现任何问题,都有可能损坏或删除珍贵的企业数据。如果你还未曾经历过因未妥善处理数据访问而带来的严重后果,那我要提醒你这绝对不是什么好事情。
做事要追求尽善尽美,所以我们选择了 Spring。Spring 自带了一组数据访问框架,集成了多种数据访问技术。不管你是直接通过 JDBC 还是像 Hibernate 这样的对象关系映射(object-relational mapping,ORM)框架实现数据持久化,Spring 都能够帮你消除持久化代码中那些单调枯燥的数据访问逻辑。我们可以依赖 Spring 来处理底层的数据访问,这样就可以专注于应用程序中数据的管理了。
当开发 Spittr 应用的持久层的时候,会面临多种选择,我们可以使用 JDBC、Hibernate、Java 持久化 API(Java Persistence API,JPA)或者其他任意的持久化框架。你可能还会考虑使用最近很流行的 NoSQL 数据库(其实我更喜欢将其称为无模式数据库)。
幸好,不管你选择哪种持久化方式,Spring 都能够提供支持。在本章,我们主要关注于 Spring 对 JDBC 的支持。但首先,我们来熟悉一下 Spring 的持久化哲学,从而为后面打好基础。
Spring 的数据访问哲学
从前面的几章可以看出,Spring 的目标之一就是允许我们在开发应用程序时,能够遵循面向对象(OO)原则中的“针对接口编程”。Spring 对数据访问的支持也不例外。
像很多应用程序一样,Spittr 应用需要从某种类型的数据库中读取和写入数据。为了避免持久化的逻辑分散到应用的各个组件中,最好将数据访问的功能放到一个或多个专注于此项任务的组件中。这样的组件通常称为数据访问对象(data access object,DAO)或 Repository。
为了避免应用与特定的数据访问策略耦合在一起,编写良好的 Repository 应该以接口的方式暴露功能。图 10.1 展现了设计数据访问层的合理方式。

如图所示,服务对象通过接口来访问 Repository。这样做会有几个好处。第一,它使得服务对象易于测试,因为它们不再与特定的数据访问实现绑定在一起。实际上,你可以为这些数据访问接口创建 mock 实现,这样无需连接数据库就能测试服务对象,而且会显著提升单元测试的效率并排除因数据不一致所造成的测试失败。
此外,数据访问层是以持久化技术无关的方式来进行访问的。持久化方式的选择独立于 Repository,同时只有数据访问相关的方法才通过接口进行暴露。这可以实现灵活的设计,并且切换持久化框架对应用程序其他部分所带来的影响最小。如果将数据访问层的实现细节渗透到应用程序的其他部分中,那么整个应用程序将与数据访问层耦合在一起,从而导致僵化的设计。
接口与 Spring:如果在阅读了上面几段文字之后,你能感受到我倾向于将持久层隐藏在接口之后,那很高兴我的目的达到了。我相信接口是实现松耦合代码的关键,并且应将其用于应用程序的各个层,而不仅仅是持久化层。还要说明一点,尽管 Spring 鼓励使用接口,但这并不是强制的——你可以使用 Spring 将 bean (DAO或其他类型)直接装配到另一个 bean 的某个属性中,而不需要一定通过接口注入。
为了将数据访问层与应用程序的其他部分隔离开来,Spring采用的方式之一就是提供统一的异常体系,这个异常体系用在了它支持的所有持久化方案中。
了解 Spring 的数据访问异常体系
这里有一个关于跳伞运动员的经典笑话,这个运动员被风吹离正常路线后降落在树上并高高地挂在那里。后来,有人路过,跳伞运动员就问他自己在什么地方。过路人回答说:“你在离地大约 20 尺的空中。”跳伞运动员说:“你一定是个软件分析师。”过路人回应说“你说对了。你是怎么知道的呢?”“因为你跟我说的话百分百正确,但丝毫用处都没有。”
这个故事已经听过很多遍了,每次过路人的职业或国籍都会有所不同。但是这个故事使我想起了 JDBC 中的 SQLException。如果你曾经编写过 JDBC 代码(不使用 Spring),你肯定会意识到如果不强制捕获 SQLException 的话,几乎无法使用 JDBC 做任何事情。SQLException 表示在尝试访问数据库的时出现了问题,但是这个异常却没有告诉你哪里出错了以及如何进行处理。
可能导致抛出 SQLException 的常见问题包括:
应用程序无法连接数据库;
要执行的查询存在语法错误;
查询中所使用的表和/或列不存在;
试图插入或更新的数据违反了数据库约束。
SQLException 的问题在于捕获到它的时候该如何处理。事实上,能够触发 SQLException 的问题通常是不能在 catch 代码块中解决的。大多数抛出 SQLException 的情况表明发生了致命性错误。如果应用程序不能连接到数据库,这通常意味着应用不能继续使用了。类似地,如果查询时出现了错误,那在运行时基本上也是无能为力。
如果无法从 SQLException 中恢复,那为什么我们还要强制捕获它呢?
即使对某些 SQLException 有处理方案,我们还是要捕获 SQLException 并查看其属性才能获知问题根源的更多信息。这是因为 SQLException 被视为处理数据访问所有问题的通用异常。对于所有的数据访问问题都会抛出 SQLException,而不是对每种可能的问题都会有不同的异常类型。
一些持久化框架提供了相对丰富的异常体系。例如,Hibernate 提供了二十个左右的异常,分别对应于特定的数据访问问题。这样就可以针对想处理的异常编写catch 代码块。
即便如此,Hibernate 的异常是其本身所特有的。正如前面所言,我们想将特定的持久化机制独立于数据访问层。如果抛出了 Hibernate 所特有的异常,那我们对 Hibernate 的使用将会渗透到应用程序的其他部分。如果不这样做的话,我们就得捕获持久化平台的异常,然后将其作为平台无关的异常再次抛出。
一方面,JDBC 的异常体系过于简单了——实际上,它算不上一个体系。另一方面,Hibernate 的异常体系是其本身所独有的。我们需要的数据访问异常要具有描述性而且又与特定的持久化框架无关。
Spring 所提供的平台无关的持久化异常
Spring JDBC 提供的数据访问异常体系解决了以上的两个问题。不同于JDBC,Spring提供了多个数据访问异常,分别描述了它们抛出时所对应的问题。表 10.1 对比了 Spring 的部分数据访问异常以及 JDBC 所提供的异常。
从表中可以看出,Spring 为读取和写入数据库的几乎所有错误都提供了异常。Spring 的数据访问异常要比表 10.1 所列的还要多。(在此没有列出所有的异常,因为我不想让 JDBC 显得太寒酸。)
| JDBC的异常 | Spring的数据访问异常 |
|---|---|
| BatchUpdateException DataTruncation SQLException SQLWarning |
BadSqlGrammarException CannotAcquireLockException CannotSerializeTransactionException CannotGetJdbcConnectionException CleanupFailureDataAccessException ConcurrencyFailureException DataAccessException DataAccessResourceFailureException DataIntegrityViolationException DataRetrievalFailureException DataSourceLookupApiUsageException DeadlockLoserDataAccessException SQLWarning DuplicateKeyException EmptyResultDataAccessException IncorrectResultSizeDataAccessException IncorrectUpdateSemanticsDataAccessException InvalidDataAccessApiUsageException InvalidDataAccessResourceUsageException InvalidResultSetAccessException JdbcUpdateAffectedIncorrectNumberOfRowsException LbRetrievalFailureException |
| BatchUpdateException DataTruncation SQLException SQLWarning |
NonTransientDataAccessResourceException OptimisticLockingFailureException PermissionDeniedDataAccessException PessimisticLockingFailureException QueryTimeoutException RecoverableDataAccessException SQLWarningException SqlXmlFeatureNotImplementedException TransientDataAccessException TransientDataAccessResourceException TypeMismatchDataAccessException UncategorizedDataAccessException UncategorizedSQLException |
尽管 Spring 的异常体系比 JDBC 简单的 SQLException 丰富得多,但它并没有与特定的持久化方式相关联。这意味着我们可以使用 Spring 抛出一致的异常,而不用关心所选择的持久化方案。这有助于我们将所选择持久化机制与数据访问层隔离开来。
看!不用写 catch 代码块
表 10.1 中没有体现出来的一点就是这些异常都继承自 DataAccessException。DataAccessException 的特殊之处在于它是一个非检查型异常。换句话说,没有必要捕获 Spring 所抛出的数据访问异常(当然,如果你想捕获的话也是完全可以的)。
DataAccessException 只是 Sping 处理检查型异常和非检查型异常哲学的一个范例。Spring 认为触发异常的很多问题是不能在 catch 代码块中修复的。Spring 使用了非检查型异常,而不是强制开发人员编写 catch 代码块(里面经常是空的)。这把是否要捕获异常的权力留给了开发人员。
为了利用 Spring 的数据访问异常,我们必须使用 Spring 所支持的数据访问模板。让我们看一下 Spring 的模板是如何简化数据访问的。
数据访问模板化
如果以前有搭乘飞机旅行的经历,你肯定会觉得旅行中很重要的一件事就是将行李从一个地方搬运到另一个地方。这个过程包含多个步骤。当你到达机场时,第一站是到柜台办理行李托运。然后保安人员对其进行安检以确保安全。之后行李将通过行李车转送到飞机上。如果你需要中途转机,行李也要进行中转。当你到达目的地的时候,行李需要从飞机上取下来并放到传送带上。最后,你到行李认领区将其取回。
尽管在这个过程中包含多个步骤,但是涉及到旅客的只有几个。承运人负责推动整个流程。你只会在必要的时候进行参与,其余的过程不必关心。这反映了一个强大的设计模式:模板方法模式。
模板方法定义过程的主要框架。在我们的示例中,整个过程是将行李从出发地运送到目的地。过程本身是固定不变的。处理行李过程中的每个事件都会以同样的方式进行:托运检查、运送到飞机上等等。在这个过程中的某些步骤是固定的——这些步骤每次都是一样的。比如当飞机到达目的地后,所有的行李被取下来并通过传送带运到取行李处。
在某些特定的步骤上,处理过程会将其工作委派给子类来完成一些特定实现的细节。这是过程中变化的部分。例如,处理行李是从乘客在柜台托运行李开始的。这部分的处理往往是在最开始的时候进行,所以它在处理过程中的顺序是固定的。由于每位乘客的行李登记都不一样,所以这个过程的实现是由旅客决定的。按照软件方面的术语来讲,模板方法将过程中与特定实现相关的部分委托给接口,而这个接口的不同实现定义了过程中的具体行为。
这也是 Spring 在数据访问中所使用的模式。不管我们使用什么样的技术,都需要一些特定的数据访问步骤。例如,我们都需要获取一个到数据存储的连接并在处理完成后释放资源。这都是在数据访问处理过程中的固定步骤,但是每种数据访问方法又会有些不同,我们会查询不同的对象或以不同的方式更新数据,这都是数据访问过程中变化的部分。
Spring 将数据访问过程中固定的和可变的部分明确划分为两个不同的类:模板(template)和回调(callback)。模板管理过程中固定的部分,而回调处理自定义的数据访问代码。图 10.2 展现了这两个类的职责。

如图所示,Spring 的模板类处理数据访问的固定部分——事务控制、管理资源以及处理异常。同时,应用程序相关的数据访问——语句、绑定参数以及整理结果集——在回调的实现中处理。事实证明,这是一个优雅的架构,因为你只需关心自己的数据访问逻辑即可。
针对不同的持久化平台,Spring 提供了多个可选的模板。如果直接使用 JDBC,那你可以选择 JdbcTemplate。如果你希望使用对象关系映射框架,那HibernateTemplate 或 JpaTemplate 可能会更适合你。表 10.2 列出了 Spring 所提供的所有数据访问模板及其用途。
| 模板类(org.springframework.*) | 用 途 |
|---|---|
| jca.cci.core.CciTemplate | JCA CCI 连接 |
| jdbc.core.JdbcTemplate | JDBC连接 |
| jdbc.core.namedparam.NamedParameterJdbcTemplate | 支持命名参数的JDBC连接 |
| jdbc.core.simple.SimpleJdbcTemplate | 通过Java 5简化后的JDBC连接(Spring 3.1中已经废弃) |
| orm.hibernate3.HibernateTemplate | Hibernate 3.x以上的Session |
| orm.ibatis.SqlMapClientTemplate iBATIS | SqlMap客户端 |
| orm.jdo.JdoTemplate | Java数据对象(Java DataObject)实现 |
| orm.jpa.JpaTemplate | Java持久化API的实体管理器 |
Spring 为多种持久化框架提供了支持,这里没有那么多的篇幅在本章对其进行一一介绍。因此,我会关注于我认为最为实用的持久化方案,这也是读者最可能用到的。
在本章中,我们将会从基础的 JDBC 访问开始,因为这是从数据库中读取和写入数据的最基本方式。在第 11 章中,我们将会了解 Hibernate 和 JPA,这是最流行的基于 POJO 的 ORM 方案。我们会在第 12 章结束 Spring 持久化的话题,在这一章中,将会看到 Spring Data 项目是如何让 Spring 支持无模式数据的。
但首先要说明的是 Spring 所支持的大多数持久化功能都依赖于数据源。因此,在声明模板和 Repository 之前,我们需要在 Spring 中配置一个数据源用来连接数据库。
配置数据源
无论选择 Spring 的哪种数据访问方式,你都需要配置一个数据源的引用。Spring 提供了在 Spring 上下文中配置数据源 bean 的多种方式,包括:
- 通过 JDBC 驱动程序定义的数据源;
- 通过 JNDI 查找的数据源;
- 连接池的数据源。
对于即将发布到生产环境中的应用程序,我建议使用从连接池获取连接的数据源。如果可能的话,我倾向于通过应用服务器的JNDI来获取数据源。请记住这一点,让我们首先看一下如何配置 Spring 从 JNDI 中获取数据源。
使用 JNDI 数据源
Spring 应用程序经常部署在 Java EE 应用服务器中,如 WebSphere、JBoss 或甚至像 Tomcat 这样的Web容器中。这些服务器允许你配置通过 JNDI 获取数据源。这种配置的好处在于数据源完全可以在应用程序之外进行管理,这样应用程序只需在访问数据库的时候查找数据源就可以了。另外,在应用服务器中管理的数据源通常以池的方式组织,从而具备更好的性能,并且还支持系统管理员对其进行热切换。
利用 Spring,我们可以像使用 Spring bean 那样配置 JNDI 中数据源的引用并将其装配到需要的类中。位于 jee 命名空间下的<jee:jndilookup>元素可以用于检索 JNDI 中的任何对象(包括数据源)并将其作为 Spring 的 bean。例如,如果应用程序的数据源配置在 JNDI 中,我们可以使用<jee:jndi-lookup>元素将其装配到 Spring 中,如下所示:
1 | <jee:jndi-lookup id="dataSource" jndi-name="/jdbc/SpitterDS" resource-ref="true"/> |
其中 jndi-name 属性用于指定 JNDI 中资源的名称。如果只设置了 jndi-name 属性,那么就会根据指定的名称查找数据源。但是,如果应用程序运行在 Java 应用服务器中,你需要将 resource-ref 属性设置为 true,这样给定的 jndi-name 将会自动添加 “java:comp/env/” 前缀。
如果想使用 Java 配置的话,那我们可以借助 JndiObjectFactoryBean 从 JNDI 中查找 DataSource:
1 | JndiObjectFactoryBean dataSource() { JndiObjectFactoryBean jndiObjectFB = new JndiObjectFactoryBean(); jndiObjectFB.setJndiName("jdbc/SpitterDS"); jndiObjectFB.setResourceRef(true); jndiObjectFB.setProxyInterface(javax.sql.DataSource.class); return jndiObjectFB;} |
显然,通过 Java 配置获取 JNDI bean 要更为复杂。大多数情况下,Java 配置要比 XML 配置简单,但是这一次我们需要写更多的 Java 代码。但是,很容易就能够看出 Java 代码中与 XML 相对应的配置,Java 配置的内容其实也不算多。
使用数据源连接池
如果你不能从 JNDI 中查找数据源,那么下一个选择就是直接在 Spring 中配置数据源连接池。尽管 Spring 并没有提供数据源连接池实现,但是我们有多项可用的方案,包括如下开源的实现:
Apache Commons DBCP (http://jakarta.apache.org/commons/dbcp);
BoneCP (http://jolbox.com/) 。
这些连接池中的大多数都能配置为 Spring 的数据源,在一定程度上与 Spring 自带的 DriverManagerDataSource 或 SingleConnectionDataSource 很类似(我们稍后会对其进行介绍)。例如,如下就是配置 DBCP BasicDataSource 的方式:
1 | <bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" p:driverClassName="org.h2.Driver" p:url="jdbc:h2:tcp://localhost/~/spitter" p:username="sa" p:password="" p:initialSize="5" p:maxActive="10"/> |
如果你喜欢 Java 配置的话,连接池形式的 DataSource bean 可以声明如下:
1 | BasicDataSource dataSource() { BasicDataSource ds = new BasicDataSource(); ds.setDriveClassName("org.h2.Driver"); ds.setUrl("jdbc:h2:tcp://localhost/~/spitter"); ds.setUsername("sa"): ds.setPassword(""); ds.setInitialSize(5); ds.setMaxActive(10); return ds;} |
前四个属性是配置 BasicDataSource 所必需的。属性 driverClassName 指定了 JDBC 驱动类的全限定类名。在这里我们配置的是 H2 数据库的数据源。属性 url 用于设置数据库的 JDBC URL。最后,username 和 password 用于在连接数据库时进行认证。
以上四个基本属性定义了 BasicDataSource 的连接信息。除此以外,还有多个配置数据源连接池的属性。表 10.3 列出了 DBCP BasicDataSource 最有用的一些池配置属性:
| 池配置属性 | 所指定的内容 |
|---|---|
| initialSize | 池启动时创建的连接数量 |
| maxActive | 同一时间可从池中分配的最多连接数。如果设置为 0,表示无限制 |
| maxIdle | 池里不会被释放的最多空闲连接数。如果设置为 0,表示无限制 |
| maxOpenPreparedStatements | 在同一时间能够从语句池中分配的预处理语句(prepared statement)的最大数量。如果设置为 0,表示无限制 |
| maxWait | 在抛出异常之前,池等待连接回收的最大时间(当没有可用连接时)。如果设置为 -1,表示无限等待 |
| minEvictableIdleTimeMillis | 连接在池中保持空闲而不被回收的最大时间 |
| minIdle | 在不创建新连接的情况下,池中保持空闲的最小连接数 |
| poolPreparedStatements | 是否对预处理语句(prepared statement)进行池管理(布尔值) |
在我们的示例中,连接池启动时会创建 5 个连接;当需要的时候,允许 BasicDataSource 创建新的连接,但最大活跃连接数为 10。
基于 JDBC 驱动的数据源
在 Spring 中,通过 JDBC 驱动定义数据源是最简单的配置方式。Spring 提供了三个这样的数据源类(均位于 org.springframework.jdbc.datasource 包中)供选择:
- DriverManagerDataSource:在每个连接请求时都会返回一个新建的连接。与 DBCP 的 BasicDataSource 不同,由 DriverManagerDataSource 提供的连接并没有进行池化管理;
- SimpleDriverDataSource:与 DriverManagerDataSource 的工作方式类似,但是它直接使用 JDBC 驱动,来解决在特定环境下的类加载问题,这样的环境包括 OSGi 容器;
- SingleConnectionDataSource:在每个连接请求时都会返回同一个的连接。尽管 SingleConnectionDataSource 不是严格意义上的连接池数据源,但是你可以将其视为只有一个连接的池。
以上这些数据源的配置与 DBCPBasicDataSource 的配置类似。例如,如下就是配置 DriverManagerDataSource 的方法:
1 | DataSource dataSource() { DBCPBasicDataSource ds = new DBCPBasicDataSource(); ds.setDriveClassName("org.h2.Driver"); ds.setUrl("jdbc:h2:tcp://localhost/~/spitter"); ds.setUsername("sa"): ds.setPassword(""); return ds;} |
如果使用 XML 的话,DriverManagerDataSource 可以按照如下的方式配置:
1 | <bean id="dataSource" class="org.springframework.jdbc.DriverManagerDataSource" p:driverClassName="org.h2.Driver" p:url="jdbc:h2:tcp://localhost/~/spitter" p:username="sa" p:password=""/> |
与具备池功能的数据源相比,唯一的区别在于这些数据源 bean 都没有提供连接池功能,所以没有可配置的池相关的属性。
尽管这些数据源对于小应用或开发环境来说是不错的,但是要将其用于生产环境,你还是需要慎重考虑。因为 SingleConnectionDataSource 有且只有一个数据库连接,所以不适合用于多线程的应用程序,最好只在测试的时候使用。
而 DriverManagerDataSource 和 SimpleDriverDataSource 尽管支持多线程,但是在每次请求连接的时候都会创建新连接,这是以性能为代价的。鉴于以上的这些限制,我强烈建议应该使用数据源连接池。
使用嵌入式的数据源
除此之外,还有一个数据源是我想对读者介绍的:嵌入式数据库(embedded database)。嵌入式数据库作为应用的一部分运行,而不是应用连接的独立数据库服务器。尽管在生产环境的设置中,它并没有太大的用处,但是对于开发和测试来讲,嵌入式数据库都是很好的可选方案。这是因为每次重启应用或运行测试的时候,都能够重新填充测试数据。
Spring 的 jdbc 命名空间能够简化嵌入式数据库的配置。例如,如下的程序清单展现了如何使用 jdbc 命名空间来配置嵌入式的 H2 数据库,它会预先加载一组测试数据。
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:c="http://www.springframework.org/schema/c" xmlns:jdbc="http://www.springframework.org/schema/jdbc" xsi:schemaLocation="http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc-3.1.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <jdbc:embedded-database id="dataSource" type="H2"> <jdbc:script location="classpath:spittr/db/jdbc/schema.sql" /> <jdbc:script location="classpath:spittr/db/jdbc/test-data.sql" /> </jdbc:embedded-database> </beans> |
我们将 <jdbc:embedded-database> 的 type 属性设置为 H2,表明嵌入式数据库应该是 H2 数据库(要确保 H2 位于应用的类路径下)。另外,我们还可以将 type 设置为 DERBY,以使用嵌入式的 Apache Derby 数据库。
在 <jdbc:embedded-database> 中,我们可以不配置也可以配置多个 <jdbc:script> 元素来搭建数据库。程序清单 10.1 中包含了两个 <jdbc:script> 元素:第一个引用了 schema.sql,它包含了在数据库中创建表的 SQL;第二个引用了 test-data.sql,用来将测试数据填充到数据库中。
除了搭建嵌入式数据库以外,<jdbc:embedded-database> 元素还会暴露一个数据源,我们可以像使用其他的数据源那样来使用它。在这里,id 属性被设置成了dataSource,这也是所暴露数据源的 bean ID。因此,当我们需要 javax.sql.DataSource 的时候,就可以注入 dataSource bean。
如果使用 Java 来配置嵌入式数据库时,不会像 jdbc 命名空间那么简便,我们可以使用 EmbeddedDatabaseBuilder 来构建 DataSource:
1 | DataSource dataSource() { return new EmbeddedDatabaseBuilder() .setType(embeddedDatabaseType.H2) .addScript("classpath:schema.sql") .addScript("classpath:test-data.sql") .builder();} |
可以看到,setType() 方法等同于 <jdbc:embedded-database> 元素中的 type 属性,此外,我们这里用 addScript() 代替 jdbc:script 元素来指定初始化 SQL。
使用 profile 选择数据源
我们已经看到了多种在 Spring 中配置数据源的方法,我相信你已经找到了一两种适合你的应用程序的配置方式。实际上,我们很可能面临这样一种需求,那就是在某种环境下需要其中一种数据源,而在另外的环境中需要不同的数据源。
例如,对于开发期来说,<jdbc:embedded-database> 元素是很合适的,而在 QA 环境中,你可能希望使用 DBCP 的 BasicDataSource,在生产部署环境下,可能需要使用 <jee:jndi-lookup>。
我们在第 3 章所讨论的 Spring 的 bean profile 特性恰好用在这里,所需要做的就是将每个数据源配置在不同的 profile 中,如下所示:
1 | package com.habuma.spitter.config;import org.apache.commons.dbcp.BasicDataSOurce;import javax.sql.DataSource;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.Profile;import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseBuilder;import org.springframework.jdbc.jndi.JnidObjectFactoryBean; class DataSourceConfiguration { public DataSource embeddedDataSource() { return new EmbeddedDatabaseBuilder() .setType(EmbeddedDatabaseType.H2) .addScript("classpath:schema.sql") .addScript("classpath:test-data.sql") .builder(); } public DataSource data() { BasicDataSource ds = new BasicDataSource(); ds.setDriveClassName("org.h2.Driver"); ds.setUrl("jdbc:h2:tcp://localhost/~/spitter"); ds.setUsername("sa"): ds.setPassword(""); return ds; } public DataSource dataSource() { JndiObjectFactoryBean jndiObjectFB = new JndiObjectFactoryBean(); jndiObjectFB.setJndiName("jdbc/SpitterDS"); jndiObjectFB.setResourceRef(true); jndiObjectFB.setProxyInterface(javax.sql.DataSource.class); return (DataSource) jndiObjectFB.getObject(); }} |
通过使用 profile 功能,会在运行时选择数据源,这取决于哪一个 profile 处于激活状态。如程序清单 10.2 配置所示,当且仅当 development profile 处于激活状态时,会创建嵌入式数据库,当且仅当 qa profile 处于激活状态时,会创建 DBCPBasicDataSource,当且仅当 production profile 处于激活状态时,会从 JNDI 获取数据源。
为了内容的完整性,如下的程序清单展现了如何使用 Spring XML 代替 Java 配置,实现相同的 profile 配置。
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:c="http://www.springframework.org/schema/c" xmlns:jdbc="http://www.springframework.org/schema/jdbc" xsi:schemaLocation="http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc-3.1.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <beans profile="development" c;as> <jdbc:embedded-database id="dataSource" type="H2"> <jdbc:script location="classpath:spittr/db/jdbc/schema.sql" /> <jdbc:script location="classpath:spittr/db/jdbc/test-data.sql" /> </jdbc:embedded-database> </beans> <beans profile="qa"> <bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" p:driverClassName="org.h2.Driver" p:url="jdbc:h2:tcp://localhost/~/spitter" p:username="sa" p:password="" p:initialSize="5" p:maxActive="10"/> </beans> <beans profile="development"> <jee:jndi-lookup id="dataSource" jndi-name="/jdbc/SpitterDS" resource-ref="true"/> </beans> </beans> |
现在我们已经通过数据源建立了与数据库的连接,接下来要实际访问数据库了。就像我在前面所提到的,Spring 为我们提供了多种使用数据库的方式包括 JDBC、Hibernate 以及 Java 持久化 API(Java Persistence API,JPA)。在下一节,我们将会看到如何使用 Spring 对 JDBC 的支持为应用程序构建持久层。如果你喜欢使用 Hibernate 或 JPA,那可以直接跳到下一章。
在 Spring 中使用JDBC
持久化技术有很多种,而Hibernate、iBATIS和JPA只是其中的几种而已。尽管如此,还是有很多的应用程序使用最古老的方式将 Java 对象保存到数据库中:他们自食其力。不,等等,这是他们挣钱的途径。这种久经考验并证明行之有效的持久化方法就是古老的 JDBC。
为什么不采用它呢?JDBC 不要求我们掌握其他框架的查询语言。它是建立在 SQL 之上的,而 SQL 本身就是数据访问语言。此外,与其他的技术相比,使用 JDBC 能够更好地对数据访问的性能进行调优。JDBC 允许你使用数据库的所有特性,而这是其他框架不鼓励甚至禁止的。
再者,相对于持久层框架,JDBC 能够让我们在更低的层次上处理数据,我们可以完全控制应用程序如何读取和管理数据,包括访问和管理数据库中单独的列。这种细粒度的数据访问方式在很多应用程序中是很方便的。例如在报表应用中,如果将数据组织为对象,而接下来唯一要做的就是将其解包为原始数据,那就没有太大意义了。
但是 JDBC 也不是十全十美的。虽然 JDBC 具有强大、灵活和其他一些优点,但也有其不足之处。
应对失控的 JDBC 代码
如果使用 JDBC 所提供的直接操作数据库的 API,你需要负责处理与数据库访问相关的所有事情,其中包含管理数据库资源和处理异常。如果你曾经使用 JDBC 往数据库中插入数据,那如下代码对你应该并不陌生:
1 | private static final String SQL_INSERT_SPITTER = "insert into spitter (username, password, fullname) values (?, ?, ?)";private DataSource dataSource;public void addSpitter(Spitter spitter) { connection conn = null; PreparedStatement stmt = null; try { conn = datasource.getConnection(); stmt = conn.prepareStatement(SQL_INSERT_SPITTER); stmt.setString(1, spitter.getUsername()); stmt.setString(2, spitter.getPassword()); stmt.setString(3, spitter.getFullName()); stmt.execute(); } catch (SQLException e) { // do something ... not sure what, though } finally { try { if (stmt != null) { stmt.close(); } if (conn != null) { conn.close(); } } catch (SQLException e) { // I'm even less sure about what todo here } }} |
看看这些失控的代码!这个超过 20 行的代码仅仅是为了向数据库中插入一个简单的对象。对于 JDBC 操作来讲,这应该是最简单的了。但是为什么要用这么多行代码才能做如此简单的事情呢?实际上,并非如此,只有几行代码是真正用于进行插入数据的。但是 JDBC 要求你必须正确地管理连接和语句,并以某种方式处理可能抛出的 SQLException 异常。
再提一句这个 SQLException 异常:你不但不清楚如何处理它(因为并不知道哪里出错了),而且你还要捕捉它两次!你需要在插入记录出错时捕捉它,同时你还需要在关闭语句和连接出错的时候捕捉它。看起来我们要做很多的工作来处理可能出现的问题,而这些问题通常是难以通过编码来处理的。
再来看一下如下程序清单中的代码,我们使用传统的 JDBC 来更新数据库中 Spitter 表的一行。
1 | private static final String SQL_UPDATE_SPITTER = "update spitter set username = ?, password = ?, fullname = ?" + "where id = ?";public void saveSpitter(Spitter spitter) { Connection conn = null; PreparedStatement stmt = null; try { conn = dataSource.getConnection(); stmt = conn.prepareStatement(SQL_UPDATE_SPITTER); stmt.setString(1, spitter.getUsername()); stmt.setString(2, spitter.getPassword()); stmt.setString(3, spitter.getFullname()); stmt.setLong(4, spitter.getId()); stmt.execute(); } catch (SQLException e) { // Still not sure what I'm supposed to do here } finally { try { if (stmt != null) { stmt.close(); } if (conn != null) { conn.close(); } } catch (SQLException e) { // or here } }} |
乍看上去,程序清单 10.5 和 10.4 是相同的。实际上,除了 SQL 字符串和创建语句的那一行,它们是完全相同的。同样,这里也使用大量代码来完成一件简单的事情,而且有很多重复的代码。在理想情况下,我们只需要编写与特定任务相关的代码。毕竟,这才是程序清单 10.5 和 10.4 的不同之处,剩下的都是样板代码。
为了完成对 JDBC 的完整介绍,让我们看一下如何从数据库中获取数据。如下所示,它也不简单。
1 | private static final String SQL_SELECT_SPITTER = "select id, username, fullname from spitter where id = ?";public void findOne(Long id) { Connection conn = null; PreparedStatement stmt = null; ResultSet rs = null; try { conn = dataSource.getConnection(); stmt = conn.prepareStatement(SQL_SELECT_SPITTER); stmt.setLong(1, id); rs = stmt.executeQuery(); Spitter spitter = null; if (rs.next()) { spitter = new Spitter(); spitter.setId(rs.getLong("id")); spitter.setUsername(rs.getString("username")); spitter.setPassword(rs.getString("password")); spitter.setFullName(rs.getString("fullname")); } return spitter; } catch (SQLException e) { // Still not sure what I'm supposed to do here } finally { try { if (stmt != null) { stmt.close(); } if (conn != null) { conn.close(); } } catch (SQLException e) { // or here } }} |
这段代码与插入和更新的样例一样冗长,甚至更为复杂。这就好像 Pareto 法则被倒了过来:只有 20% 的代码是真正用于查询数据的,而 80% 代码都是样板代码。
现在你可以看出,大量的 JDBC 代码都是用于创建连接和语句以及异常处理的样板代码。既然已经得出了这个观点,我们将不再接受它的折磨,以后你再也不会看到这样令人厌恶的代码了。
但实际上,这些样板代码是非常重要的。清理资源和处理错误确保了数据访问的健壮性。如果没有它们的话,就不会发现错误而且资源也会处于打开的状态,这将会导致意外的代码和资源泄露。我们不仅需要这些代码,而且还要保证它是正确的。基于这样的原因,我们才需要框架来保证这些代码只写一次而且是正确的。
使用 JDBC 模板
Spring 的 JDBC 框架承担了资源管理和异常处理的工作,从而简化了 JDBC 代码,让我们只需编写从数据库读写数据的必需代码。
正如前面小节所介绍过的,Spring 将数据访问的样板代码抽象到模板类之中。Spring 为 JDBC 提供了三个模板类供选择:
- JdbcTemplate:最基本的 Spring JDBC 模板,这个模板支持简单的 JDBC 数据库访问功能以及基于索引参数的查询;
- NamedParameterJdbcTemplate:使用该模板类执行查询时可以将值以命名参数的形式绑定到 SQL 中,而不是使用简单的索引参数;
- SimpleJdbcTemplate:该模板类利用 Java 5 的一些特性如自动装箱、泛型以及可变参数列表来简化 JDBC 模板的使用。
以前,在选择哪一个 JDBC 模板的时候,我们需要仔细权衡。但是从 Spring 3.1 开始,做这个决定变得容易多了。SimpleJdbcTemplate 已经被废弃了,其 Java 5 的特性被转移到了 JdbcTemplate 中,并且只有在你需要使用命名参数的时候,才需要使用 NamedParameterJdbcTemplate。这样的话,对于大多数的 JDBC 任务来说,JdbcTemplate 就是最好的可选方案,这也是本小节中所关注的方案。
使用 JdbcTemplate 来插入数据
为了让 JdbcTemplate 正常工作,只需要为其设置 DataSource 就可以了,这使得在 Spring 中配置 JdbcTemplate 非常容易,如下面的 @Bean 方法所示:
1 | JdbcTemplate jdbcTemplate(DataSource dataSource) { return new JdbcTemplate(dataSource);} |
在这里,DataSource 是通过构造器参数注入进来的。这里所引用的 dataSource bean 可以是 javax.sql.DataSource 的任意实现,包括我们在 10.2 小节中所创建的。
现在,我们可以将 jdbcTemplate 装配到 Repository 中并使用它来访问数据库。例如,SpitterRepository 使用了 JdbcTemplate:
1 | class JdbcSpitterRepository implements SpitterRepository { private JdbcOperations jdbcOperations; public JdbcSpitterRepository(JdbcOperations jdbcOperations) { this.jdbcOperations = jdbcOperations; } ...} |
在这里,JdbcSpitterRepository 类上使用了 @Repository 注解,这表明它将会在组件扫描的时候自动创建。它的构造器上使用了 @Inject 注解,因此在创建的时候,会自动获得一个 JdbcOperations 对象。JdbcOperations 是一个接口,定义了 JdbcTemplate 所实现的操作。通过注入 JdbcOperations,而不是具体的 JdbcTemplate,能够保证 JdbcSpitterRepository 通过 JdbcOperations 接口达到与 JdbcTemplate 保持松耦合。
作为另外一种组件扫描和自动装配的方案,我们可以将 JdbcSpitterRepository 显式声明为 Spring 中的 bean,如下所示:
1 | SpitterRepository spitterRepository(JdbcTemplate jdbcTemplate) { return new JdbcSpitterRepository(jdbcTemplate);} |
在 Repository 中具备可用的 JdbcTemplate 后,我们可以极大地简化程序清单 10.4 中的 addSpitter() 方法。基于 JdbcTemplate 的 addSpitter() 方法如下:
1 | public void addSpitter(Spitter spitter) { jdbcOperations.update(INSERT_SPITTER, spitter.getUsername(), spitter.getPassword(), spitter.getFullName(), spitter.getEmail(), spitter.isUpdateByEmail());} |
这个版本的 addSpitter() 方法简单多了。这里没有了创建连接和语句的代码,也没有异常处理的代码,只剩下单纯的数据插入代码。
不能因为你看不到这些样板代码,就意味着它们不存在。样板代码被巧妙地隐藏到 JDBC 模板类中了。当 update() 方法被调用的时候 JdbcTemplate 将会获取连接、创建语句并执行插入 SQL。
在这里,你也看不到对 SQLException 处理的代码。在内部,JdbcTemplate 将会捕获所有可能抛出的 SQLException,并将通用的 SQLException 转换为表 10.1 所列的那些更明确的数据访问异常,然后将其重新抛出。因为Spring的数据访问异常都是运行时异常,所以我们不必在 addSpring() 方法中进行捕获。
使用 JdbcTemplate 来读取数据
JdbcTemplate 也简化了数据的读取操作。程序清单 10.8 展现了新版本的 findOne() 方法,它使用了 JdbcTemplate 的回调,实现根据 ID 查询 Spitter,并将结果集映射为 Spitter 对象。
1 | public Spitter findOne(long id) { return jdbcTemplate.queryForObject( SELECT_SPITTER_By_ID, new SpitterRowMapper(), id); }private static final class SpitterRowMapper implements RowMapper<Spitter> { public Spitter mapRow(ResultSet rs, int rowNum) throws SQLException { long id = rs.getLong("id"); String username = rs.getString("username"); String password = rs.getString("password"); String fullName = rs.getString("fullname"); String email = rs.getString("email"); boolean updateByEmail = rs.getBoolean("updateByEmail"); return new Spitter(id, username, password, fullName, email, updateByEmail); } } |
在这个 findOne() 方法中使用了 JdbcTemplate 的 queryForObject() 方法来从数据库查询 Spitter。queryForObject() 方法有三个参数:
String 对象,包含了要从数据库中查找数据的 SQL;
RowMapper 对象,用来从 ResultSet 中提取数据并构建域对象(本例中为 Spitter);
可变参数列表,列出了要绑定到查询上的索引参数值。
真正奇妙的事情发生在 SpitterRowMapper 对象中,它实现了 RowMapper 接口。对于查询返回的每一行数据,JdbcTemplate 将会调用 RowMapper 的 mapRow() 方法,并传入一个 ResultSet 和包含行号的整数。在 SpitterRowMapper 的 mapRow() 方法中,我们创建了 Spitter 对象并将 ResultSet 中的值填充进去。
就像 addSpitter() 那样,findOne() 方法也不用写 JDBC 模板代码。不同于传统的 JDBC,这里没有资源管理或者异常处理代码。使用 JdbcTemplate 的方法只需关注于如何从数据库中获取 Spitter 对象即可。
在 JdbcTemplate 中使用 Java 8 的 Lambda 表达式
因为 RowMapper 接口只声明了 addRow() 这一个方法,因此它完全符合函数式接口(functional interface)的标准。这意味着如果使用 Java 8 来开发应用的话,我们可以使用 Lambda 来表达 RowMapper 的实现,而不必再使用具体的实现类了。
例如,程序清单 10.8 中的 findOne() 方法可以使用 Java 8 的 Lambda 表达式改写,如下所示:
1 | public Spitter findOne(long id) { return jdbcOperations.queryForObject( SELECT_SPITTER_BY_ID, (rs, rowNum) ->{ return new Spitter( rs.getLong("id"), rs.getString("username"), rs.getString("password"), rs.getString("fullname"), rs.getString("email"), rs.getBoolean("updateByEmail")); }, id);} |
我们可以看到,Lambda 表达式要比完整的 RowMapper 实现更为易读,不过它们的功能是相同的。Java 会限制 RowMapper 中的Lambda表达式,使其满足所传入的参数。
另外,我们还可以使用 Java 8 的方法引用,在单独的方法中定义映射逻辑:
1 | public Spitter FindOne(long id) { return jdbcOperations.QueryForObject(SELECT_SPITTER_BY_ID, this::mapSpitter, id);}private Spitter mapSpitter(ResultSet rs, int row) throws SQLException { return new Spitter( rs.getLong("id"), rs.getString("username"), rs.getString("password"), rs.getString("fullName"), rs.getString("email"), rs.getBoolean("updateByEmail"));} |
不管采用哪种方式,我们都不必显式实现 RowMapper 接口,但是与实现 RowMapper 类似,我们所提供的 Lambda 表达式和方法必须要接受相同的参数,并返回相同的类型。
使用命名参数
在清单 10.7 的代码中,addSpitter() 方法使用了索引参数。这意味着我们需要留意查询中参数的顺序,在将值传递给 update() 方法的时候要保持正确的顺序。如果在修改 SQL 时更改了参数的顺序,那我们还需要修改参数值的顺序。
除了这种方法之外,我们还可以使用命名参数。命名参数可以赋予 SQL 中的每个参数一个明确的名字,在绑定值到查询语句的时候就通过该名字来引用参数。例如,假设 SQL_INSERT_SPITTER 查询语句是这样定义的:
1 | private static final String SQL_INSERT_SPITTER = "insert into spitter (username, password, fullname)" + "values (:username, :passowrd, :fullname)"; |
使用命名参数查询,绑定值的顺序就不重要了,我们可以按照名字来绑定值。如果查询语句发生了变化导致参数的顺序与之前不一致,我们不需要修改绑定的代码。
NamedParameterJdbcTemplate 是一个特殊的 JDBC 模板类,它支持使用命名参数。在Spring中,NamedParameterJdbcTemplate 的声明方式与常规的 JdbcTemplate 几乎完全相同:
1 | NamedParameterJdbcTemplate jdbcTemplate(DataSource dataSource) { return new NamedParameterJdbcTemplate(dataSource);} |
在这里,我们将 NamedParameterJdbcOperations(NamedParameterJdbcTemplate 所实现的接口)注入到 Repository 中,用它来替代 JdbcOperations。现在的 addSpitter() 方法如下所示:
1 | private static final String INSERT_SPITTER = "insert into Spitter " + "(username, password, fullname, email, updateByEmail)" + "values " + " (:username, :password, :fullname, :email, :updateByEmail)";public void addSpitter(Spitter spitter) { Map<String, Object> paramMap = new HashMap<String, Object>(); paramMap.put("username", spitter.getUsername()); paramMap.put("password", spitter.getPassword()); paramMap.put("fullname", spitter.getFullName()); paramMap.put("email", spitter.getEmail()); paramMap.put("updateByEmail", spitter.isUpdateByEmail()); jdbcOperations.update(INSERT_SPITTER, paramMap);} |
这个版本的 addSpitter() 比前一版本的代码要长一些。这是因为命名参数是通过 java.util.Map 来进行绑定的。不过,每行代码都关注于往数据库中插入 Spitter 对象。这个方法的核心功能并不会被资源管理或异常处理这样的代码所充斥。
小结
数据是应用程序的血液。有些数据中心论者甚至主张数据即应用。鉴于数据的重要地位,以健壮、简单和清晰的方式开发应用程序的数据访问部分就显得举足轻重了。
在 Java 中,JDBC 是与关系型数据库交互的最基本方式。但是按照规范,JDBC 有些太笨重了。Spring 能够解除我们使用 JDBC 中的大多数痛苦,包括消除样板式代码、简化 JDBC 异常处理,你所需要做的仅仅是关注要执行的 SQL 语句。
在本章中,我们学习了 Spring 对数据持久化的支持,以及 Spring 为 JDBC 所提供的基于模板的抽象,它能够极大地简化 JDBC 的使用。
在下一章中,我们会继续 Spring 数据持久化这一话题,将会学习 Spring 为 Java 持久化 API 所提供的功能。
使用对象-关系映射持久化数据
本章内容:
- 使用 Spring 和 Hibernate
- 借助上下文 Session,编写不依赖于 Spring 的 Repository
- 通过 Spring 使用 JPA
- 借助 Spring Data 实现自动化的 JPA Repository
小时候,骑自行车是一件很有趣的事情,对吧?在清晨,我们骑车上学。放学后,我们游逛到朋友家。当天色渐晚之时,在父母的呼喊声中,我们骑车回家。那些日子真的很有意思!
后来,随着慢慢长大,现在我们所需要的不仅仅是一辆自行车了。有时,我们需要走很远的路去上班或需要装载一些生活用品,还有可能接送孩子去上足球课。如果生活在得克萨斯州的话,我们还必须需要一台空调。我们的需求超出了自行车的功能范围。
在数据持久化的世界中,JDBC 就像自行车。对于份内的工作,它能很好地完成并且在一些特定的场景下表现出色。但随着应用程序变得越来越复杂,对持久化的需求也变得更复杂。我们需要将对象的属性映射到数据库的列上,并且需要自动生成语句和查询,这样我们就能从无休止的问号字符串中解脱出来。此外,我们还需要一些更复杂的特性:
- 延迟加载(Lazy loading):随着我们的对象关系变得越来越复杂,有时候我们并不希望立即获取完整的对象间关系。举一个典型的例子,假设我们在查询一组 PurchaseOrder 对象,而每个对象中都包含一个 LineItem 对象集合。如果我们只关心 PurchaseOrder 的属性,那查询出LineItem的数据就毫无意义。而且这可能是开销很大的操作。延迟加载允许我们只在需要的时候获取数据。
- 预先抓取(Eager fetching):这与延迟加载是相对的。借助于预先抓取,我们可以使用一个查询获取完整的关联对象。如果我们需要PurchaseOrder及其关联的LineItem对象,预先抓取的功能可以在一个操作中将它们全部从数据库中取出来,节省了多次查询的成本。
- 级联(Cascading):有时,更改数据库中的表会同时修改其他表。回到我们订购单的例子中,当删除Order对象时,我们希望同时在数据库中删除关联的LineItem。
一些可用的框架提供了这样的服务,这些服务的通用名称是对象/关系映射(object-relational mapping,ORM)。在持久层使用ORM工具,可以节省数千行的代码和大量的开发时间。ORM工具能够把你的注意力从容易出错的SQL代码转向如何实现应用程序的真正需求。
Spring 对多个持久化框架都提供了支持,包括 Hibernate、iBATIS、Java 数据对象(Java Data Objects,JDO)以及 Java 持久化API(Java Persistence API,JPA)。与 Spring 对 JDBC 的支持那样,Spring 对 ORM 框架的支持提供了与这些框架的集成点以及一些附加的服务:
- 支持集成 Spring 声明式事务;
- 透明的异常处理;
- 线程安全的、轻量级的模板类;
- DAO 支持类;
- 资源管理。
本章没有足够的篇幅介绍 Spring 支持的全部 ORM 框架。其实这并不会有什么问题,因为 Spring 对不同 ORM 解决方案的支持是很相似的。一旦掌握了 Spring 对某种 ORM 框架的支持后,你可以轻松地切换到另一个框架。
在本章中,我们将会看到 Spring 如何与最常用的两种 ORM 方案集成:
Hibernate 和 JPA。同时还会通过 Spring Data JPA 了解一下 Spring Data 项目。借助这种方式,我们不仅可以学习到如何借助 Spring Data JPA 移除 JPA Repository 中的样板式代码,还能为下一章的如何将 Spring Data 用于无模式的存储打下基础。
让我们先来看看 Spring 是如何为 Hibernate 提供支持的。
在 Spring 中集成 Hibernate
Hibernate 是在开发者社区很流行的开源持久化框架。它不仅提供了基本的对象关系映射,还提供了 ORM 工具所应具有的所有复杂功能,比如缓存、延迟加载、预先抓取以及分布式缓存。
在本章中,我们会关注 Spring 如何与 Hibernate 集成,而不会涉及太多 Hibernate 使用时的复杂细节。如果你需要了解更多关于 Hibernate 如何使用的知识,我推荐你阅读 Christian Bauer、Gavin King 和 Gary Gregory 撰写的《Java Persistence with Hibernate,Second Edition》(Manning,2014,www.manning.com/bauer3/)或访问 Hibernate 的网站 http://www.hibernate.org。
声明 Hibernate 的 Session 工厂
使用 Hibernate 所需的主要接口是 org.hibernate.Session。Session 接口提供了基本的数据访问功能,如保存、更新、删除以及从数据库加载对象的功能。通过
Hibernate 的 Session接口,应用程序的 Repository 能够满足所有的持久化需求。
获取 Hibernate Session 对象的标准方式是借助于 HibernateSessionFactory 接口的实现类。除了一些其他的任务,SessionFactory 主要负责 Hibernate Session的打开、关闭以及管理。
在 Spring 中,我们要通过 Spring 的某一个 Hibernate Session 工厂 bean 来获取 Hibernate SessionFactory。从 3.1 版本开始,Spring 提供了三个 Session 工厂bean 供我们选择:
- org.springframework.orm.hibernate3.LocalSessionFactoryBean
- org.springframework.orm.hibernate3.annotation.AnnotationSessionFactoryBean
- org.springframework.orm.hibernate4.LocalSessionFactoryBean
这些 Session 工厂 bean 都是 Spring FactoryBean 接口的实现,它们会产生一个 HibernateSessionFactory,它能够装配进任何 SessionFactory 类型的属性中。这样的话,就能在应用的 Spring 上下文中,与其他的 bean 一起配置 Hibernate Session 工厂。
至于选择使用哪一个 Session 工厂,这取决于使用哪个版本的 Hibernate 以及你使用 XML 还是使用注解来定义对象-数据库之间的映射关系。如果你使用Hibernate 3.2 或更高版本(直到 Hibernate 4.0,但不包含这个版本)并且使用 XML 定义映射的话,那么你需要定义 Spring 的 org.springframework.orm.hibernate3 包中的 LocalSessionFactoryBean:
1 | LocalSessionFactoryBean sessionFactory(DataSource dataSource) { LocalSessionFactoryBean sfb = new LocalSessionFactoryBean(); sfb.setDataSource(dataSource); sfb.setMappingResource(new String[] { "Spitter.hbm.xml" }); Properties props = new Properties(); props.setProperty("dialect", "org.hibernate.dialect.H2Dialect"); sfb.setHebernateProperties(props); return sfb;} |
在配置 LocalSessionFactoryBean 时,我们使用了三个属性。属性 dataSource 装配了一个 DataSource bean 的引用。属性 mappingResources 列出了一个或多个的 Hibernate 映射文件,在这些文件中定义了应用程序的持久化策略。最后,hibernateProperties 属性配置了 Hibernate 如何进行操作的细节。在本示例中,我们配置 Hibernate 使用 H2 数据库并且要按照 H2Dialect 来构建 SQL。
如果你更倾向于使用注解的方式来定义持久化,并且你还没有使用 Hibernate 4 的话,那么需要使用 AnnotationSessionFactoryBean 来代替 LocalSessionFactoryBean:
1 | AnnotationSessionFactoryBean sessionFactory(DataSource ds) { AnnotationSessionFactoryBean sfb = new AnnotationSessionFactoryBean(); sfb.setDataSource(ds); sfb.setMappingResource(new String[] { "Spitter.hbm.xml" }); Properties props = new Properties(); props.setProperty("dialect", "org.hibernate.dialect.H2Dialect"); sfb.setHebernateProperties(props); return sfb;} |
如果你使用 Hibernate 4 的话,那么就应该使用 org.springframework.orm.hibernate4 中的 LocalSessionFactoryBean。尽管它与 Hibernate 3 包中的 LocalSessionFactoryBean 使用了相同的名称,但是 Spring 3.1 新引入的这个 Session 工厂类似于 Hibernate 3 中 LocalSessionFactoryBean 和 AnnotationSessionFactoryBean 的结合体。它有很多相同的属性,能够支持基于 XML 的映射和基于注解的映射。如下的代码展现了如何对它进行配置,使其支持基于注解的映射:
1 | LocalSessionFactoryBean sessionFactory(DataSource dataSource) { LocalSessionFactoryBean sfb = new LocalSessionFactoryBean(); sfb.setDataSource(dataSource); sfb.setPackagesToScan(new String[] { "com.habuma.spittr.domain" }); Properties props = new Properties(); props.setProperty("dialect", "org.hibernate.dialect.H2Dialect"); sfb.setHebernateProperties(props); return sfb;} |
在这两个配置中,dataSource 和 hibernateProperties 属性都声明了从哪里获取数据库连接以及要使用哪一种数据库。这里不再列出 Hibernate 配置文件,而是使用 packagesToScan 属性告诉 Spring 扫描一个或多个包以查找域类,这些类通过注解的方式表明要使用 Hibernate 进行持久化,这些类可以使用的注解包括 JPA 的 @Entity 或 @MappedSuperclass 以及 Hibernate 的 @Entity。
如果愿意的话,你还可以使用 annotatedClasses 属性来将应用程序中所有的持久化类以全限定名的方式明确列出:
1 | sfb.setAnnotationClasses( new Class<?>[] { Spitter.class, Spittle.class }); |
annotatedClasses 属性对于准确指定少量的域类是不错的选择。如果你有很多的域类并且不想将其全部列出,又或者你想自由地添加或移除域类而不想修改 Spring 配置的话,那使用 packagesToScan 属性是更合适的。
在 Spring 应用上下文中配置完 Hibernate 的 Session 工厂 bean 后,那我们就可以创建自己的 Repository 类了。
构建不依赖于 Spring 的 Hibernate 代码
在 Spring 和 Hibernate 的早期岁月中,编写 Repository 类将会涉及到使用 Spring 的 HibernateTemplate。HibernateTemplate 能够保证每个事务使用同一个 Session。但是这种方式的弊端在于我们的 Repository 实现会直接与 Spring 耦合。
现在的最佳实践是不再使用 HibernateTemplate,而是使用上下文 Session(Contextual session)。通过这种方式,会直接将 Hibernate SessionFactory 装配到 Repository 中,并使用它来获取 Session,如下面的程序清单所示。
1 | HibernateSpitterRepository(SessionFactory sessionFactory) { this.sessionFactory = sessionFactory;}private Session currentSession() { return sessionFactory.getCurrentSession();} public long count() { return findAll().size();}public Spitter save(Spitter spitter) { Serializable id = currentSession().save(spitter); return new Spitter((Long) id, spitter.getUsername(), spitter.getPassword(), spitter.getFullName(), spitter.getEmail(), spitter.isUpdateByEmail());}public Spitter findOne(long id) { return (Spitter) currentSession().get(Spitter.class, id); }public Spitter findByUsername(String username) { return (Spitter) currentSession() .createCriteria(Spitter.class) .add(Restrictions.eq("username", username)) .list().get(0);}public List<Spitter> findAll() { return (List<Spitter>) currentSession() .createCriteria(Spitter.class).list(); } |
在程序清单 11.1 中有几个地方需要注意。首先,我们通过 @Inject 注解让 Spring 自动将一个 SessionFactory 注入到 HibernateSpitterRepository 的 sessionFactory 属性中。接下来,在 currentSession() 方法中,我们使用这个 SessionFactory 来获取当前事务的 Session。
另外需要注意的是,我们在类上使用了 @Repository 注解,这会为我们做两件事情。首先,@Repository 是 Spring 的另一种构造性注解,它能够像其他注解一样被 Spring 的组件扫描所扫描到。这样就不必明确声明 HibernateSpitterRepository bean 了,只要这个 Repository 类在组件扫描所涵盖的包中即可。
除了帮助减少显式配置以外,@Repository 还有另外一个用处。让我们回想一下模板类,它有一项任务就是捕获平台相关的异常,然后使用 Spring 统一非检查型异常的形式重新抛出。如果我们使用 Hibernate 上下文 Session 而不是 Hibernate 模板的话,那异常转换会怎么处理呢?
为了给不使用模板的 Hibernate Repository 添加异常转换功能,我们只需在 Spring 应用上下文中添加一个 PersistenceExceptionTranslationPostProcessor bean:
1 | BeanPostProcessor persistenceTranslation() { return new PersistenceExceptionTranslationPostProcessor();} |
PersistenceExceptionTranslationPostProcessor 是一个 bean 后置处理器(bean post-processor),它会在所有拥有 @Repository 注解的类上添加一个通知器(advisor),这样就会捕获任何平台相关的异常并以 Spring 非检查型数据访问异常的形式重新抛出。
现在,Hibernate 版本的 Repository 已经完成了。我们开发时,没有依赖 Spring 的特定类(除了 @Repository 注解以外)。这种不使用模板的方式也适用于开发纯粹的基于 JPA 的 Repository,让我们再尝试开发另一个 SpitterRepository 实现类,这次我们使用的是 JPA。
Spring 与 Java 持久化 API
Java 持久化 API(Java Persistence API,JPA)诞生在 EJB 2 实体 Bean 的废墟之上,并成为下一代 Java 持久化标准。JPA 是基于 POJO 的持久化机制,它从 Hibernate 和 Java 数据对象(Java Data Object,JDO)上借鉴了很多理念并加入了 Java 5 注解的特性。
在 Spring 2.0 版本中,Spring 首次集成了 JPA 的功能。具有讽刺意味的是,很多人批评(或赞赏)Spring 颠覆了 EJB。但是,当 Spring 支持 JPA 后,很多开发人员都推荐在基于 Spring 的应用程序中使用 JPA 实现持久化。实际上,有些人还将 Spring-JPA 的组合称为 POJO 开发的梦之队。
在 Spring 中使用 JPA 的第一步是要在 Spring 应用上下文中将实体管理器工厂(entity manager factory)按照 bean 的形式来进行配置。
配置实体管理器工厂
简单来讲,基于 JPA 的应用程序需要使用 EntityManagerFactory 的实现类来获取 EntityManager 实例。JPA 定义了两种类型的实体管理器:
应用程序管理类型(Application-managed):当应用程序向实体管理器工厂直接请求实体管理器时,工厂会创建一个实体管理器。在这种模式下,程序要负责打开或关闭实体管理器并在事务中对其进行控制。这种方式的实体管理器适合于不运行在 Java EE 容器中的独立应用程序。
容器管理类型(Container-managed):实体管理器由 Java EE 创建和管理。应用程序根本不与实体管理器工厂打交道。相反,实体管理器直接通过注入或JNDI 来获取。容器负责配置实体管理器工厂。这种类型的实体管理器最适用于 Java EE 容器,在这种情况下会希望在 persistence.xml 指定的 JPA 配置之外保持一些自己对JPA的控制。
以上的两种实体管理器实现了同一个 EntityManager 接口。关键的区别不在于 EntityManager 本身,而是在于 EntityManager 的创建和管理方式。应用程序管理类型的 EntityManager 是由 EntityManagerFactory 创建的,而后者是通过 PersistenceProvider 的 createEntityManagerFactory() 方法得到的。与此相对,容器管理类型的 EntityManagerFactory 是通过 PersistenceProvider 的 createContainerEntityManagerFactory() 方法获得的。
这对想使用 JPA 的 Spring开发者来说又意味着什么呢?其实这并没太大的关系。不管你希望使用哪种 EntityManagerFactory,Spring 都会负责管理 EntityManager。如果你使用的是应用程序管理类型的实体管理器,Spring承担了应用程序的角色并以透明的方式处理 EntityManager。在容器管理的场景下,Spring 会担当容器的角色。
这两种实体管理器工厂分别由对应的 Spring 工厂 Bean 创建:
- LocalEntityManagerFactoryBean 生成应用程序管理类型的 EntityManagerFactory;
- LocalContainerEntityManagerFactoryBean 生成容器管理类型的 EntityManagerFactory。
需要说明的是,选择应用程序管理类型的还是容器管理类型的 EntityManagerFactory,对于基于 Spring的应用程序来讲是完全透明的。当组合使用 Spring 和 JPA 时,处理 EntityManagerFactory 的复杂细节被隐藏了起来,数据访问代码只需关注它们的真正目标即可,也就是数据访问。
应用程序管理类型和容器管理类型的实体管理器工厂之间唯一值得关注的区别是在 Spring 应用上下文中如何进行配置。让我们先看看如何在 Spring 中配置应用程序管理类型的 LocalEntityManagerFactoryBean,然后再看看如何配置容器管理类型的 LocalContainerEntityManagerFactoryBean。
配置应用程序管理类型的 JPA
对于应用程序管理类型的实体管理器工厂来说,它绝大部分配置信息来源于一个名为 persistence.xml 的配置文件。这个文件必须位于类路径下的 META-INF 目录下。
persistence.xml 的作用在于定义一个或多个持久化单元。持久化单元是同一个数据源下的一个或多个持久化类。简单来讲,persistence.xml 列出了一个或多个的持久化类以及一些其他的配置如数据源和基于XML的配置文件。如下是一个典型的 persistence.xml 文件,它是用于 Spittr 应用程序的:
1 | <persistence version="2.1" xmlns="http://xmlns.jcp.org/xml/ns/persistence"> <persistence-unit name="spitterPU"> <class>com.habuma.spittr.domain.Spitter</class> <class>com.habuma.spittr.domain.Spittle</class> <properties> <property name="toplink.jdbc.driver" value="org.hsqldb.jdbcDriver" /> <property name="toplink.jdbc.url" value="jdbc:hsqldb:hsql://localhost/spitter/spitter" /> <property name="toplink.jdbc.user" value="sa" /> <property name="toplink.jdbc.password" value="" /> </properties> </persistence-unit></persistence> |
因为在 persistence.xml 文件中包含了大量的配置信息,所以在 Spring 中需要配置的就很少了。可以通过以下的 @Bean 注解方法在 Spring 中声明 LocalEntityManagerFactoryBean:
1 | LocalEntityManagerFactoryBean entityManagerFactoryBean() { LocalEntityManagerFactoryBean emfb = new LocalEntityManagerFactoryBean(); emfb.setPersistenceUnitName("spitterPU"); return emfb;} |
赋给 persistenceUnitName 属性的值就是 persistence.xml 中持久化单元的名称。
创建应用程序管理类型的 EntityManagerFactory 都是在 persistence.xml 中进行的,而这正是应用程序管理的本意。在应用程序管理的场景下(不考虑 Spring时),完全由应用程序本身来负责获取 EntityManagerFactory,这是通过 JPA 实现的 PersistenceProvider 做到的。如果每次请求 EntityManagerFactory 时都需要定义持久化单元,那代码将会迅速膨胀。通过将其配置在 persistence.xml 中,JPA 就能够在这个特定的位置查找持久化单元定义了。
但借助于 Spring 对 JPA 的支持,我们不再需要直接处理 PersistenceProvider 了。因此,再将配置信息放在 persistence.xml 中就显得不那么明智了。实际上,这样做妨碍了我们在 Spring 中配置 EntityManagerFactory(如果不是这样的话,我们可以提供一个 Spring 配置的数据源)。
鉴于以上的原因,让我们关注一下容器管理的 JPA:
使用容器管理类型的 JPA
容器管理的 JPA 采取了一个不同的方式。当运行在容器中时,可以使用容器(在我们的场景下是 Spring)提供的信息来生成 EntityManagerFactory。
你可以将数据源信息配置在 Spring 应用上下文中,而不是在 persistence.xml中了。例如,如下的 @Bean 注解方法声明了在 Spring 中如何使用 LocalContainerEntityManagerFactoryBean 来配置容器管理类型的 JPA:
1 | LocalContainerEntityManagerFactoryBean entityManagerFactory(DataSource dataSource, JpaVendorAdapter jpaVendorAdapter) { LocalContainerEntityManagerFactoryBean emfb = new LocalContainerEntityManagerFactoryBean(); emfb.setDataSource(dataSource); emfb.setJpaVendorAdapter(jpaVendorAdapter); return emfb;} |
这里,我们使用了 Spring 配置的数据源来设置 dataSource 属性。任何 javax.sql.DataSource 的实现都是可以的。尽管数据源还可以在 persistence.xml 中进行配置,但是这个属性指定的数据源具有更高的优先级。
jpaVendorAdapter 属性用于指明所使用的是哪一个厂商的 JPA 实现。Spring 提供了多个 JPA 厂商适配器:
- EclipseLinkJpaVendorAdapter
- HibernateJpaVendorAdapter
- OpenJpaVendorAdapter
- TopLinkJpaVendorAdapter(在 Spring 3.1 版本中,已经将其废弃了)
在本例中,我们使用 Hibernate 作为 JPA 实现,所以将其配置 为HibernateJpaVendorAdapter:
1 | JpaVendorAdapter jpaVendorAdapter() { HibernateJpaVendorAdapter adapter = new HibernateJpaVendorAdapter(); adapter.setDatabase("HSQL"); adapter.setShowSql(true); adapter.setGenerateDdl(false); adapter.setDatabasePlatform("org.hibernet.dialect.HSQLDialect"); return adapter;} |
有多个属性需要设置到厂商适配器上,但是最重要的是 database 属性,在上面我们设置了要使用的数据库是 Hypersonic。这个属性支持的其他值如表 11.1 所示。
| 数据库平台 | 属性database的值 |
|---|---|
| IBM DB2 | DB2 |
| Apache Derby | DERBY |
| H2 | H2 |
| Hypersonic | HSQL |
| Informix | INFORMIX |
| MySQL | MYSQL |
| Oracle | ORACLE |
| PostgresQL | POSTGRESQL |
| Microsoft SQL Server | SQLSERVER |
| Sybase | SYBASE |
一些特定的动态持久化功能需要对持久化类按照指令(instrumentation)进行修改才能支持。在属性延迟加载(只在它们被实际访问时才从数据库中获取)的对象中,必须要包含知道如何查询未加载数据的代码。一些框架使用动态代理实现延迟加载,而有一些框架像 JDO,则是在编译时执行类指令。
选择哪一种实体管理器工厂主要取决于如何使用它。但是,下面的小技巧可能会让你更加倾向于使用 LocalContainerEntityManagerFactoryBean。
persistence.xml 文件的主要作用就在于识别持久化单元中的实体类。但是从 Spring 3.1 开始,我们能够在 LocalContainerEntityManagerFactoryBean 中直接设
置 packagesToScan 属性:
1 | LocalContainerEntityManagerFactoryBean entityManagerFactory(DataSource dataSource, JpaVendorAdapter jpaVendorAdapter) { LocalContainerEntityManagerFactoryBean emfb = new LocalContainerEntityManagerFactoryBean(); emfb.setDataSource(dataSource); emfb.setJpaVendorAdapter(jpaVendorAdapter); emfb.setPackagesToScan("com.habuma.spittr.domain"); return emfb;} |
在这个配置中,LocalContainerEntityManagerFactoryBean 会扫描 com.habuma.spittr.domain 包,查找带有 @Entity 注解的类。因此,没有必要在 persistence.xml 文件中进行声明了。同时,因为 DataSource 也是注入到 LocalContainerEntityManagerFactoryBean 中的,所以也没有必要在 persistence.xml 文件中配置数据库信息了。那么结论就是,persistence.xml 文件完全没有必要存在了!你尽可以将其删除,让 LocalContainerEntityManagerFactoryBean 来处理这些事情。
从 JNDI 获取实体管理器工厂
还有一件需要注意的事项,如果将 Spring 应用程序部署在应用服务器中,EntityManagerFactory 可能已经创建好了并且位于 JNDI 中等待查询使用。在这种情况下,可以使用 Spring jee 命名空间下的 <jee:jndi-lookup> 元素来获取对 EntityManagerFactory 的引用:
1 | <jee:jndi-lookup id="emf" jndi-name="persistence/spitterPU" /> |
我们也可以使用如下的 Java 配置来获取 EntityManagerFactory:
1 | JndiObjectFactoryBean entityManagerFactory() { JndiObjectFactoryBean jndiObjectFB = new JndiObjectFactoryBean(); jndiObjectFB.setJndiName("jdbc/SpittrDS"); return jndiObjectFB;} |
尽管这种方法没有返回 EntityManagerFactory,但是它的结果就是一个 EntityManagerFactory bean。这是因为它所返回的 JndiObjectFactoryBean 是 FactoryBean 接口的实现,它能够创建 EntityManagerFactory。
不管你采用何种方式得到 EntityManagerFactory,一旦得到这样的对象,接下来就可以编写 Repository 了。让我们开始吧。
编写基于 JPA 的 Repository
正如 Spring 对其他持久化方案的集成一样,Spring 对 JPA 集成也提供了 JpaTemplate 模板以及对应的支持类 JpaDaoSupport。但是,为了实现更纯粹的 JPA 方式,基于模板的 JPA 已经被弃用了。这与我们在 11.1.2 小节使用的 Hibernate 上下文 Session是很类似的。
鉴于纯粹的 JPA 方式远胜于基于模板的 JPA,所以在本节中我们将会重点关注如何构建不依赖 Spring 的 JPA Repository。如下程序清单中的 JpaSpitterRepository 展现了如何开发不使用 Spring JpaTemplate 的 JPA Repository。
1 | package com.habuma.spittr.persistence;import java.util.List;import javax.persistence.EntityManagerFactory;import javax.persistence.PersistenceUnit;import org.springframework.dao.DataAccessException;import org.springframework.stereotype.Repository;import org.springframework.transaction.annotation.Transactional;import com.habuma.spittr.domain.Spitter;import com.habuma.spittr.domain.Spittle; class JpaSpitterRepository implements SpitterRepository { private EntityManagerFactory emf; public void addSpitter(Spitter spitter) { emf.createEntityManager().persist(spitter); } public Spitter getSpitterById(long id) { return emf.createEntityManager().find(Spitter.class, id); } public void saveSpitter(Spitter spitter) { emf.createEntityManager().merge(spitter); } ...} |
程序清单 11.2 中,需要注意的是 EntityManagerFactory 属性,它使用了 @PersistenceUnit 注解,因此,Spring 会将 EntityManagerFactory 注入到 Repository 之中。有了 EntityManagerFactory 之后,JpaSpitterRepository 的方法就能使用它来创建 EntityManager 了,然后 EntityManager 可以针对数据库执行操作。
在 JpaSpitterRepository 中,唯一的问题在于每个方法都会调用 createEntityManager()。除了引入易出错的重复代码以外,这还意味着每次调用 Repository 的方法时,都会创建一个新的 EntityManager。这种复杂性源于事务。如果我们能够预先准备好 EntityManager,那会不会更加方便呢?
这里的问题在于 EntityManager 并不是线程安全的,一般来讲并不适合注入到像 Repository 这样共享的单例bean中。但是,这并不意味着我们没有办法要求注入 EntityManager。如下的程序清单展现了如何借助 @PersistentContext 注解为 JpaSpitterRepository 设置 EntityManager。
1 | package com.habuma.spittr.persistence;import java.util.List;import javax.persistence.EntityManager;import javax.persistence.PersistenceContext;import org.springframework.dao.DataAccessException;import org.springframework.stereotype.Repository;import org.springframework.transaction.annotation.Transactional;import com.habuma.spittr.domain.Spitter;import com.habuma.spittr.domain.Spittle; class JpaSpitterRepository implements SpitterRepository { private EntityManager em; public void addSpitter(Spitter spitter) { em.persist(spitter); } public Spitter getSpitterById(long id) { return em.find(Spitter.class, id); } public void saveSpitter(Spitter spitter) { em.merge(spitter); } ...} |
在这个新版本的 JpaSpitterRepository 中,直接为其设置了 EntityManager,这样的话,在每个方法中就没有必要再通过 EntityManagerFactory 创建 EntityManager 了。尽管这种方式非常便利,但是你可能会担心注入的 EntityManager 会有线程安全性的问题。
这里的真相是 @PersistenceContext 并不会真正注入 EntityManager——至少,精确来讲不是这样的。它没有将真正的 EntityManager 设置给 Repository,而是给了它一个 EntityManager 的代理。真正的 EntityManager 是与当前事务相关联的那一个,如果不存在这样的 EntityManager 的话,就会创建一个新的。这样的话,我们就能始终以线程安全的方式使用实体管理器。
另外,还需要了解 @PersistenceUnit 和 @PersistenceContext 并不是 Spring 的注解,它们是由 JPA 规范提供的。为了让 Spring 理解这些注解,并注入 EntityManager Factory 或 EntityManager,我们必须要配置 Spring 的 PersistenceAnnotationBeanPostProcessor。如果你已经使用了<context:annotationconfig> 或 <context:componentscan>,那么你就不必再担心了,因为这些配置元素会自动注册 PersistenceAnnotationBeanPostProcessor bean。否则的话,我们需要显式地注册这个 bean:
1 | PersistenceAnnotationBeanPostProcessor paPostProcessor() { return new PersistenceAnnotationBeanPostProcessor();} |
你可能也注意到了 JpaSpitterRepository 使用了 @Repository 和 @Transactional 注解。@Transactional 表明这个Repository中的持久化方法是在事务上下文中执行的。
对于 @Repository 注解,它的作用与开发 Hibernate 上下文 Session 版本的 Repository 时是一致的。由于没有使用模板类来处理异常,所以我们需要为 Repository 添加 @Repository 注解,这样 PersistenceExceptionTranslationPostProcessor 就会知道要将这个 bean 产生的异常转换成 Spring 的统一数据访问异常。
既然提到了 PersistenceExceptionTranslationPostProcessor,要记住的是我们需要将其作为一个 bean 装配到 Spring 中,就像我们在 Hibernate 样例中所做的那样:
1 | BeanPostProcessor persistenceTranslation() { return new PersistenceExceptionTranslationPostProcessor();} |
提醒一下,不管对于 JPA 还是 Hibernate,异常转换都不是强制要求的。如果你希望在 Repository中抛出特定的 JPA 或 Hibernate 异常,只需将 PersistenceExceptionTranslationPostProcessor 省略掉即可,这样原来的异常就会正常地处理。但是,如果使用了 Spring 的异常转换,你会将所有的数据访问异常置于 Spring 的体系之下,这样以后切换持久化机制的话会更容易。
借助 Spring Data 实现自动化的 JPA Repository
尽管程序清单 11.2 和 11.3 程序清单中的方法都很简单,但它们依然还会直接与 EntityManager 交互来查询数据库。并且,仔细看一下的话,这些代码多少还是样板式的。例如,让我们重新审视 addSpitter() 方法:
1 | public void addSpitter(Spitter spitter) { entityManger.persist(spitter);} |
在任何具有一定规模的应用中,你可能会以几乎完全相同的方式多次编写这种方法。实际上,除了所持久化的 Spitter 对象不同以外,我敢打赌你以前肯定写过类似的方法。其实,JpaSpitterRepository 中的其他方法也没有什么太大的创造性。领域对象会有所不同,但是所有 Repository 中的方法都是很通用的。
为什么我们需要一遍遍地编写相同的持久化方法呢,难道仅仅是因为要处理的领域类型不同吗?Spring Data JPA 能够终结这种样板式的愚蠢行为。我们不再需要一遍遍地编写相同的 Repository 实现,Spring Data 能够让我们只编写 Repository 接口就可以了。根本就不再需要实现类了。
例如,看一下 SpitterRepository 接口。
1 | public interface SpitterRepository extends JpaRepository<Spitter, Long> {} |
此时,SpitterRepository 看上去并没有什么作用。但是,它的功能远超出了表面上所看到的那样。编写 Spring Data JPA Repository 的关键在于要从一组接口中挑选一个进行扩展。这里,SpitterRepository 扩展了 Spring Data JPA 的 JpaRepository(稍后,我会介绍几个其他的接口)。通过这种方式,JpaRepository 进行了参数化,所以它就能知道这是一个用来持久化 Spitter 对象的 Repository,并且 Spitter 的 ID 类型为 Long。另外,它还会继承 18个 执行持久化操作的通用方法,如保存 Spitter、删除 Spitter 以及根据 ID 查询 Spitter。
此时,你可能会想下一步就该编写一个类实现 SpitterRepository 和它的 18 个方法了。如果真的是这样的话,那本章就会变得乏味无聊了。其实,我们根本不需要编写 SpitterRepository 的任何实现类,相反,我们让 Spring Data 来为我们做这件事请。我们所需要做的就是对它提出要求。
为了要求 Spring Data 创建 SpitterRepository 的实现,我们需要在 Spring 配置中添加一个元素。如下的程序清单展现了在 XML 配置中启用 Spring Data JPA 所需要添加的内容:
1 | <?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:jpa="http://www.springframework.org/schema/jpa" xsi:schemaLocation="http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa-1.0.xsd"> <jpa:repository base-package="com.habuma.spittr.db" /> ... </beans> |
<jpa:repositories> 元素掌握了Spring Data JPA 的所有魔力。就像 <context:component-scan> 元素一样,<jpa:repositories> 元素也需要指定一个要进行扫描的 base-package。不过,<context:component-scan> 会扫描包(及其子包)来查找带有 @Component 注解的类,而 <jpa:repositories> 会扫描它的基础包来查找扩展自 Spring Data JPA Repository 接口的所有接口。如果发现了扩展自 Repository 的接口,它会自动生成(在应用启动的时候)这个接口的实现。
如果要使用 Java 配置的话,那就不需要使用 <jpa:repositories> 元素了,而是要在 Java 配置类上添加 @EnableJpaRepositories 注解。如下就是一个 Java 配置类,它使用了 @EnableJpaRepositories 注解,并且会扫描 com.habuma.spittr.db 包:
1 | public class JpaConfiguration {} |
让我们回到 SpitterRepository 接口,它扩展自 JpaRepository,而 JpaRepository 又扩展自 Repository 标记接口(虽然是间接的)。因此,SpitterRepository 就传递性地扩展了 Repository 接口,也就是 Repository 扫描时所要查找的接口。当 Spring Data 找到它后,就会创建 SpitterRepository 的实现类,其中包含了继承自 JpaRepository、PagingAndSortingRepository 和 CrudRepository 的18 个方法。
很重要的一点在于 Repository 的实现类是在应用启动的时候生成的,也就是 Spring 的应用上下文创建的时候。它并不是在构建时通过代码生成技术产生的,也不是接口方法调用时才创建的。
很漂亮的技术,对吧?
Spring Data JPA 很棒的一点在于它能为 Spitter 对象提供 18 个便利的方法来进行通用的 JPA 操作,而无需你编写任何持久化代码。但是,如果你的需求超过了它所提供的这 18 个方法的话,该怎么办呢?幸好,Spring Data JPA 提供了几种方式来为 Repository 添加自定义的方法。让我们看一下如何为 Spring Data JPA 编写自定义的查询方法。
定义查询方法
现在,SpitterRepository 需要完成的一项功能是根据给定的 username 查找 Spitter 对象。比如,我们将 SpitterRepository 接口修改为如下所示的样子:
1 | public interface SpitterRepository extends JpaRepository<Spitter, Long> { Spitter findByUsername(String username);} |
这个新的 findByUserName() 非常简单,但是足以满足我们的需求。现在,该如何让 Spring Data JPA 提供这个方法的实现呢?
实际上,我们并不需要实现 findByUsername()。方法签名已经告诉 Spring Data JPA 足够的信息来创建这个方法的实现了。
当创建 Repository 实现的时候,Spring Data 会检查 Repository 接口的所有方法,解析方法的名称,并基于被持久化的对象来试图推测方法的目的。本质上,Spring Data 定义了一组小型的领域特定语言(domainspecific language ,DSL),在这里,持久化的细节都是通过 Repository 方法的签名来描述的。
Spring Data 能够知道这个方法是要查找 Spitter 的,因为我们使用 Spitter 对 JpaRepository 进行了参数化。方法名 findByUsername 确定该方法需要根据 username 属性相匹配来查找 Spitter,而 username 是作为参数传递到方法中来的。另外,因为在方法签名中定义了该方法要返回一个 Spitter 对象,而不是一个集合,因此它只会查找一个 username 属性匹配的 Spitter。
findByUsername() 方法非常简单,但是 Spring Data 也能处理更加有意思的方法名称。Repository 方法是由一个动词、一个可选的主题(Subject)、关键词 By以及一个断言所组成。在 findByUsername() 这个样例中,动词是 find,断言是 Username,主题并没有指定,暗含的主题是 Spitter。
作为编写 Repository 方法名称的样例,我们参照名为 readSpitterByFirstnameOrLastname() 的方法,看一下方法中的各个部分是如何映射的。图 11.1 展现了这个方法是如何拆分的。
我们可以看到,这里的动词是 read,与之前样例中的 find 有所差别。Spring Data 允许在方法名中使用四种动词:get、read、find 和 count。其中,动词 get、read 和 find 是同义的,这三个动词对应的 Repository 方法都会查询数据并返回对象。而动词 count 则会返回匹配对象的数量,而不是对象本身。

Repository 方法的主题是可选的。它的主要目的是让你在命名方法的时候,有更多的灵活性。如果你更愿意将方法称为 readSpittersByFirstnameOrLastname() 而不是 readByFirstnameOrLastname() 的话,那么你尽可以这么做。
对于大部分场景来说,主题会被省略掉。readSpittersByFirstnameOrLastname() 与 readPuppiesByFirstnameOrLastname() 并没有什么差别,它们与 readThoseThingsWeWantByFirstnameOrLastname() 同样没有什么区别。要查询的对象类型是通过如何参数化 JpaRepository 接口来确定的,而不是方法名称中的主题。
在省略主题的时候,有一种例外情况。如果主题的名称以 Distinct 开头的话,那么在生成查询的时候会确保所返回结果集中不包含重复记录。
断言是方法名称中最为有意思的部分,它指定了限制结果集的属性。在 readByFirstnameOrLastname() 这个样例中,会通过 firstname 属性或 lastname 属性的值来限制结果。
在断言中,会有一个或多个限制结果的条件。每个条件必须引用一个属性,并且还可以指定一种比较操作。如果省略比较操作符的话,那么这暗指是一种相等比较操作。不过,我们也可以选择其他的比较操作,包括如下的种类:
- IsAfter、After、IsGreaterThan、GreaterThan
- IsGreaterThanEqual、GreaterThanEqual
- IsBefore、Before、IsLessThan、LessThan
- IsLessThanEqual、LessThanEqual
- IsBetween、Between
- IsNull、Null
- IsNotNull、NotNull
- IsIn、In
- IsNotIn、NotIn
- IsStartingWith、StartingWith、StartsWith
- IsEndingWith、EndingWith、EndsWith
- IsContaining、Containing、Contains
- IsLike、Like
- IsNotLike、NotLike
- IsTrue、True
- IsFalse、False
- Is、Equals
- IsNot、Not
要对比的属性值就是方法的参数。完整的方法签名如下所示:
1 | List<Spitter> readByFirstnameOrLastname(String first, String last); |
要处理 String 类型的属性时,条件中可能还会包含 IgnoringCase 或 IgnoresCase,这样在执行对比的时候就会不再考虑字符是大写还是小写。例如,要在 firstname 和 lastname 属性上忽略大小写,那么可以将方法签名改成如下的形式:
1 | List<Spitter> readByFirstnameIgnoringCaseOrLastnameIgnoringCase(String first, String last); |
需要注意,IgnoringCase 和 IgnoresCase是同义的,你可以随意挑选一个最合适的。
作为 IgnoringCase/IgnoresCase 的替代方案,我们还可以在所有条件的后面添加 AllIgnoringCase 或 AllIgnoresCase,这样它就会忽略所有条件的大小写:
1 | List<Spitter> readByFirstnameOrLastnameAllIgnoresCase(String first, String last); |
注意,参数的名称是无关紧要的,但是它们的顺序必须要与方法名称中的操作符相匹配。
最后,我们还可以在方法名称的结尾处添加 OrderBy,实现结果集排序。例如,我们可以按照 lastname 属性升序排列结果集:
1 | List<Spitter> readByFirstnameOrLastnameOrderByLastnameAsc(String first, String last); |
如果要根据多个属性排序的话,只需将其依序添加到 OrderBy 中即可。例如,下面的样例中,首先会根据 lastname 升序排列,然后根据 firstname 属性降序排列:
1 | List<Spitter> readByFirstnameOrLastnameOrderByLastnameAscFirstnameDesc(String first, String last); |
可以看到,条件部分是通过 And 或者 Or 进行分割的。
我们不可能(至少很难)提供一个权威的列表,将使用 Spring Data 方法命名约定可以编写出来的方法种类全部列出来。但是,如下给出了几个符合方法命名约定的方法签名:
- List
findPetsByBreedIn(List breed) - int countProductsByDiscontinuedTrue()
- List
findByShippingDateBetween(Date start, Date end)
我们只是初步体验了所能声明的方法种类,Spring Data JPA 会为我们实现这些方法。现在,我们只需知道通过使用属性名和关键字构建 Repository 方法签名,就能让 Spring Data JPA 生成方法实现,完成几乎所有能够想象到的查询。
不过,Spring Data 这个小型的 DSL 依旧有其局限性,有时候通过方法名称表达预期的查询很烦琐,甚至无法实现。如果遇到这种情形的话,Spring Data 能够让我们通过 @Query 注解来解决问题。
声明自定义查询
假设我们想要创建一个 Repository 方法,用来查找 E-mail 地址是 Gmail 邮箱的 Spitter。有一种方式就是定义一个 findByEmailLike() 方法,然后每次想查找Gmail 用户的时候就将 “%gmail.com” 传递进来。不过,更好的方案是定义一个更加便利的 findAllGmailSpitters() 方法,这样的话,就不用将 Email 地址的一部分传递进来了:
1 | List<Spitter> findAllGmailSpitters(); |
不过,这个方法并不符合 Spring Data 的方法命名约定。当 Spring Data 试图生成这个方法的实现时,无法将方法名的内容与 Spitter 元模型进行匹配,因此会抛出异常。
如果所需的数据无法通过方法名称进行恰当地描述,那么我们可以使用 @Query 注解,为 Spring Data 提供要执行的查询。对于 findAllGmailSpitters() 方法,我们可以按照如下的方式来使用 @Query 注解:
1 | List<Spitter> findAllGmailSpitters(); |
我们依然不需要编写 findAllGmailSpitters() 方法的实现,只需提供查询即可,让 Spring Data JPA 知道如何实现这个方法。
可以看到,当使用方法命名约定很难表达预期的查询时,@Query 注解能够发挥作用。如果按照命名约定,方法的名称特别长的时候,也可以使用这个注解。例如,考虑如下的查询方法:
1 | List<Order> findByCustomerAddressZipCodeOrCustomerNameAndCustomerAddressState(); |
这真的是一个方法的名称!我不得不在返回类型后将其断开,这样才能适应本书页面的宽度。
我承认这是一个有点牵强的例子。但在现实世界中,确实存在这样的需求,使用 Repository 方法所执行的查询会得到一个很长的方法名。在这种情况下,你最好使用一个较短的方法名,并使用 @Query 来指定该方法要如何查询数据库。
对于 Spring Data JPA 的接口来说,@Query 是一种添加自定义查询的便利方式。但是,它仅限于单个 JPA 查询。如果我们需要更为复杂的功能,无法在一个简单的查询中处理的话,该怎么办呢?
混合自定义的功能
有些时候,我们需要 Repository 所提供的功能是无法用 Spring Data 的方法命名约定来描述的,甚至无法用 @Query 注解设置查询来实现。尽管 Spring Data JPA 非常棒,但是它依然有其局限性,可能需要我们按照传统的方式来编写 Repository 方法:也就是直接使用 EntityManager。当遇到这种情况的时候,我们是不是要放弃 Spring Data JPA,重新按照 11.2.2 小节中的方式来编写 Repository 呢?
简单来说,是这样的。如果你需要做的事情无法通过 Spring Data JPA 来实现,那就必须要在一个比 Spring Data JPA 更低的层级上使用 JPA。
好消息是我们没有必要完全放弃 Spring Data JPA。我们只需在必须使用较低层级 JPA 的方法上,才使用这种传统的方式即可,而对于 Spring Data JP A知道该如何处理的功能,我们依然可以通过它来实现。
当 Spring Data JPA 为 Repository 接口生成实现的时候,它还会查找名字与接口相同,并且添加了 Impl 后缀的一个类。如果这个类存在的话,Spring Data JPA 将会把它的方法与 Spring Data JPA 所生成的方法合并在一起。对于 SpitterRepository 接口而言,要查找的类名为 SpitterRepositoryImpl。
为了阐述该功能,假设我们需要在 SpitterRepository 中添加一个方法,发表 Spittle 数量在 10,000 及以上的 Spitter 将会更新为 Elite 状态。使用 Spring Data JPA 的方法命名约定或使用 @Query 均没有办法声明这样的方法。最为可行的方案是使用如下的 eliteSweep() 方法。
1 | public class SpitterRepositoryImpl implements SpitterSweeper { private EntityManager em; public int eliteSweep() { String update = "UPDATE Spitter spitter " + "SET spitter.status = 'Elite' " + "WHERE spitter.status = 'Newbie' " + "AND spitter.id IN (" + "SELECT s FROM Spitter s WHERE (" + " SELECT COUNT(spittles) FROM s.spittles spittles) > 10000" + ")"; return em.createQuery(update).executeUpdate(); }} |
我们可以看到,eliteSweep() 方法与之前在 11.2.2 小节中所创建的 Repository 方法并没有太大的差别。SpitterRepositoryImpl 没有什么特殊之处,它使用被注入的 EntityManager 来完成预期的任务。
注意,SpitterRepositoryImpl 并没有实现 SpitterRepository 接口。Spring Data JPA 负责实现这个接口。SpitterRepositoryImpl(将它与Spring Data的 Repository 关联起来的是它的名字)实现了 SpitterSweeper接口,它如下所示:
1 | public interface SpitterSweeper { int eliteSweep();} |
我们还需要确保 eliteSweep() 方法会被声明在 SpitterRepository 接口中。要实现这一点,避免代码重复的简单方式就是修改 SpitterRepository,让它扩展 SpitterSweeper:
1 | public interface SpitterRepository extends JpaRepository<Spitter, Long>, SpitterSweeper { ...} |
如前所述,Spring Data JPA 将实现类与接口关联起来是基于接口的名称。但是,Impl 后缀只是默认的做法,如果你想使用其他后缀的话,只需在配置 @EnableJpaRepositories 的时候,设置 repositoryImplementationPostfix 属性即可:
1 | @ |
如果在 XML 中使用 <jpa:repositories> 元素来配置 Spring Data JPA 的话,我们可以借助 repository-impl-postfix 属性指定后缀:
1 | <jpa:repository base-package="com.habuma.spittr.db" repository-impl-postfix="Helper" /> |
我们将后缀设置成了 Helper,Spring Data JPA 将会查找名为 SpitterRepositoryHelper 的类,用它来匹配 SpitterRepository 接口。
小结
对于很多应用来讲,关系型数据库是主流的数据存储形式,并且这种情况已经持续了很多年。使用 JDBC 并且将对象映射为数据库表是很烦琐乏味的事情,像 Hibernate 和 JPA 这样的 ORM 方案能够让我们以更加声明式的模型实现数据持久化。尽管 Spring 没有为 ORM 提供直接的支持,但是它能够与多种流行的 ORM方案集成,包括 Hibernate 与 Java 持久化 API。
在本章中,我们看到了如何在 Spring 应用中使用 Hibernate 的上下文 Session,这样我们的 Repository 就能包含很少甚至不包含 Spring 相关的代码。与之类似,我们还看到了如何将 EntityManagerFactory 或 EntityManager 注入到 Repository 实现中,从而实现不依赖于 Spring 的 JPA Repository。
我们稍后初步了解了 Spring Data,在这个过程中,只需声明 JPARepository 接口即可,让 Spring Data JPA 在运行时自动生成这些接口的实现。当我们需要的 Repository 方法超出了 Spring Data JPA 所提供的功能时,可以借助 @Query 注解以及编写自定义的 Repository 方法来实现。
但是,对于 Spring Data 的整体功能来说,我们只是接触到了皮毛。在下一章中,我们将会更加深入地学习 Spring Data 的方法命名 DSL,以及 Spring Data 如何为关系型数据库以外的领域带来帮助。也就是说:我们将会看到 Spring Data 如何支持新兴的 NoSQL 数据库,这些数据库在最近几年变得越来越流行。
使用 NoSQL 数据库
本章内容:
- 为 MongoDB 和 Neo4j 编写 Repository
- 为多种数据存储形式持久化数据
- 组合使用 Spring 和 Redis
亨利·福特在他的自传中曾经写过一句很著名的话:“任何顾客可以将这辆车漆成任何他所愿意的颜色,只要保持它的黑色就可以”。有人说这句话是傲慢和固执的,而有些人则说这句话反映出了他的幽默。事实上,在这本自传出版的时候,他通过使用一种快速烘干的油漆降低了成本,而当时这种油漆只有黑色的。
福特的这句著名的话也可以用在数据库领域,多年来,我们一直被告知,我们可以使用任意想要的数据库,只要它是关系型数据库就行。关系型数据库已经垄断应用开发领域好多年了。
随着一些竞争者进入数据库领域,关系型数据库的垄断地位开始被弱化。所谓的 “NoSQL” 数据库开始侵入生产型的应用之中,我们也认识到并没有一种全能型的数据库。现在有了更多的可选方案,所以能够为要解决的问题选择最佳的数据库。
在前面的几章中,我们关注于关系型数据库,首先使用 Spring 对 JDBC 支持,然后使用对象-关系映射。在上一章,我们看到了 Spring Data JPA,它是 Spring Data 项目下的多个子项目之一。通过在运行时自动生成 Repository 实现,Spring Data JPA 能够让使用 JPA 的过程更加简单容易。
Spring Data 还提供了对多种 NoSQL 数据库的支持,包括 MongoDB、Neo4j 和 Redis。它不仅支持自动化的 Repository,还支持基于模板的数据访问和映射注解。在本章中,将会看到如何为非关系型的 NoSQL 数据库编写 Repository。首先,我们将从 Spring Data MongoDB 开始,看一下如何编写 Repository 来处理基于文档的数据。
使用 MongoDB 持久化文档数据
有一些数据的最佳表现形式是文档(document)。也就是说,不要把这些数据分散到多个表、节点或实体中,将这些信息收集到一个非规范化(也就是文档)的结构中会更有意义。尽管两个或两个以上的文档有可能会彼此产生关联,但是通常来讲,文档是独立的实体。能够按照这种方式优化并处理文档的数据库,我们称之为文档数据库。
例如,假设我们要编写一个应用程序来获取大学生的成绩单,可能需要根据学生的名字来查询其成绩单,或者根据一些通用的属性来查询成绩单。但是,每个学生是相互独立的,任意的两个成绩单之间没有必要相互关联。尽管我们能够使用关系型数据库模式来获取成绩单数据(也许你曾经这样做过),但文档型数据库可能才是更好的方案。
文档数据库不适用于什么场景
了解文档型数据库能够用于什么场景是很重要的。但是,知道文档型数据库在什么情况下不适用同样也是很重要的。文档数据库不是通用的数据库,它们所擅长解决的是一个很小的问题集。
有些数据具有明显的关联关系,文档型数据库并没有针对存储这样的数据进行优化。例如,社交网络表现了应用中不同的用户之间是如何建立关联的,这种情况就不适合放到文档型数据库中。在文档数据库中存储具有丰富关联关系的数据也并非完全不可能,但这样做的话,你通常会发现遇到的挑战要多于所带来的收益。
Spittr 应用的域对象并不适合文档数据库。在本章中,我们将会在一个购物订单系统中学习 MongoDB。
MongoDB 是最为流行的开源文档数据库之一。Spring Data MongoDB 提供了三种方式在 Spring 应用中使用 MongoDB:
通过注解实现对象-文档映射;
使用 MongoTemplate 实现基于模板的数据库访问;
自动化的运行时 Repository 生成功能。
我们已经看到 Spring Data JPA 如何为基于 JPA 的数据访问实现自动化 Repository 生成功能。Spring Data MongoDB 为基于 MongoDB 的数据访问提供了相同的功能。
不过,与 Spring Data JPA 不同的是,Spring Data MongoDB 提供了将 Java 对象映射为文档的功能。(Spring Data JPA 没有必要为 JPA 提供这样的注解,因为JPA 规范本身就提供了对象-关系映射注解)。除此之外,Spring Data MongoDB 为通用的文档操作任务提供了基于模板的数据访问方式。
但是,在使用这些特性之前,我们首先要配置 Spring Data MongoDB。
启用 MongoDB
为了有效地使用 Spring Data MongoDB,我们需要在 Spring 配置中添加几个必要的 bean。首先,我们需要配置 MongoClient,以便于访问 MongoDB 数据库。同时,我们还需要有一个 MongoTemplate bean,实现基于模板的数据库访问。此外,不是必须,但是强烈推荐启用 Spring Data MongoDB 的自动化 Repository 生成功能。
如下的程序清单展现了如何编写简单的 Spring Data MongoDB 配置类,它包含了上述的几个 bean:
1 | package orders.config;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.mongodb.core.MongoFactoryBean;import org.springframework.data.mongodb.core.MongoOperations;import org.springframework.data.mongodb.core.MongoTemplate;import org.springframework.data.mongodb.repository.config.EnableMongoRepositories;import com.mongodb.Mongo; // 启用 MongoDB 的 Repository 功能public class MongoConfig { @Bean public MongoFactoryBean mongo() { MongoFactoryBean mongo = new MongoFactoryBean(); // MongoDBClient bean mongo.setHost("localhost"); return mongo; } @Bean public MongoOperations mongoTemplate(Mongo mongo) { // MongoDBTemplate bean return new MongoTemplate(mongo, "OrderDB"); }} |
在上一章中,我们通过 @EnableJpaRepositories 注解,启用了 Spring Data 的自动化 JPA Repository 生成功能。与之类似,@EnableMongoRepositories 为 MongoDB 实现了相同的功能。
除了 @EnableMongoRepositories 之外,程序清单 12.1 中还包含了两个带有 @Bean 注解的方法。第一个 @Bean 方法使用 MongoFactoryBean 声明了一个 Mongo 实例。这个 bean 将 Spring Data MongoDB 与数据库本身连接了起来(与使用关系型数据时 DataSource 所做的事情并没有什么区别)。尽管我们可以使用 MongoClient 直接创建 Mongo 实例,但如果这样做的话,就必须要处理 MongoClient 构造器所抛出的 UnknownHostException 异常。在这里,使用 Spring Data MongoDB 的 MongoFactoryBean 更加简单。因为它是一个工厂 bean,因此 MongoFactoryBean 会负责构建 Mongo 实例,我们不必再担心 UnknownHostException 异常。
另外一个 @Bean 方法声明了 MongoTemplate bean,在它构造时,使用了其他 @Bean 方法所创建的 Mongo 实例的引用以及数据库的名称。稍后,你将会看到如何使用 MongoTemplate 来查询数据库。即便不直接使用 MongoTemplate,我们也会需要这个 bean,因为 Repository 的自动化生成功能在底层使用了它。
除了直接声明这些 bean,我们还可以让配置类扩展 AbstractMongoConfiguration 并重载 getDatabaseName() 和 mongo() 方法。如下的程序清单展现了如何使用这种配置方式。
1 | package orders.config;import org.springframework.context.annotation.Configuration;import org.springframework.data.mongodb.config.AbstractMongoConfiguration;import org.springframework.data.mongodb.repository.config.EnableMongoRepositories;import com.mongodb.Mongo;import com.mongodb.MongoClient;public class MongoConfig extends AbstractMongoConfiguration { protected String getDatabaseName() { return "OrdersDB"; // 指定数据库名称 } @Override public Mongo mongo() throws Exception { return new MongoClient(); // 创建 Mongo 客户端 }} |
这个新的配置类与程序清单 12.1 的功能是相同的,只不过在篇幅上更加简洁。最为显著的区别在于这个配置中没有直接声明 MongoTemplate bean,当然它还是会被隐式地创建。我们在这里重载了 getDatabaseName() 方法来提供数据库的名称。mongo() 方法依然会创建一个 MongoClient 的实例,因为它会抛出 Exception,所以我们可以直接使用 MongoClient,而不必再使用 MongoFactoryBean 了。
到目前为止,不管是使用程序清单 12.1 还是 12.2,都为 Spring Data MongoDB 提供了一个运行配置,也就是说,只要 MongoDB 服务器运行在本地即可。如果MongoDB 服务器运行在其他的机器上,那么可以在创建 MongoClient 的时候进行指定:
1 | public Mongo mongo() throws Exception { return new MongoClient("mongodbserver");} |
另外,MongoDB 服务器有可能监听的端口并不是默认的 27017。如果是这样的话,在创建 MongoClient 的时候,还需要指定端口:
1 | public Mongo mongo() throws Exception { return new MongoClient("mongodbserver", 37017);} |
如果 MongoDB 服务器运行在生产配置上,我认为你可能还启用了认证功能。在这种情况下,为了访问数据库,我们还需要提供应用的凭证。访问需要认证的 MongoDB 服务器稍微有些复杂,如下面的程序清单所示。
1 | Environment env; Mongo mongo() throws Exception { MongoCredential credential = MongoCredential.createMongoCRCredential( // 创建 MongoDB 凭证 env.getProperty("mongo.username"), "OrderDB", env.getProperty("mongo.password").toCharArray()); return new MongoClient( nwe ServerAddress("localhost", 37017), //创建 MongoClient Arrays.asList(credential));} |
为了访问需要认证的 MongoDB 服务器,MongoClient 在实例化的时候必须要有一个 MongoCredential 的列表。在程序清单 12.3 中,我们为此创建了一个 MongoCredential。为了将凭证信息的细节放在配置类外边,它们是通过注入的 Environment 对象解析得到的。
为了使这个讨论更加完整,Spring Data MongoDB 还支持通过 XML 来进行配置。你可能也知道,我更喜欢 Java 配置的方案。但是,如果你喜欢 XML 配置的话,如下的程序清单展现了如何使用 mongo 配置命名空间来配置 Spring Data MongoDB。
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:mongo="http://www.springframework.org/schema/data/mongo" xsi:schemaLocation=" http://www.springframework.org/schema/data/mongo http://www.springframework.org/schema/data/mongo/spring-mongo.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd" > <mongo:repositories base-package="order.db" /> <mongo:mongo /> <bean id="mongoTemplate" class="org.springframework.mongodb.core.MongoTemplate"> <constructor-arg ref="mongo"> <constructor-arg value="OrderDB"> </bean></beans> |
现在 Spring Data MongoDB 已经配置完成了,我们很快就可以使用它来保存和查询文档了。但首先,需要使用 Spring Data MongoDB 的对象-文档映射注解为Java 领域对象建立到持久化文档的映射关系。
为模型添加注解,实现 MongoDB 持久化
当使用 JPA 的时候,我们需要将 Java 实体类映射到关系型表和列上。JPA 规范提供了一些支持对象-关系映射的注解,而有一些 JPA 实现,如 Hibernate,也添加了自己的映射注解。
但是,MongoDB 并没有提供对象-文档映射的注解。Spring Data MongoDB 填补了这一空白,提供了一些将 Java 类型映射为 MongoDB 文档的注解。表 12.1 描述了这些注解。
| 注 解 | 描 述 |
|---|---|
| @Document | 标示映射到 MongoDB 文档上的领域对象 |
| @Id | 标示某个域为 ID 域 |
| @DbRef | 标示某个域要引用其他的文档,这个文档有可能位于另外一个数据库中 |
| @Field | 为文档域指定自定义的元数据 |
| @Version | 标示某个属性用作版本域 |
@Document 和 @Id注解类似于 JPA 的 @Entity 和 @Id 注解。我们将会经常使用这两个注解,对于要以文档形式保存到 MongoDB 数据库的每个 Java 类型都会使用这两个注解。例如,如下的程序清单展现了如何为 Order 类添加注解,它会被持久化到 MongoDB 中。
1 | package orders;import java.util.Collection;import java.util.LinkedHashSet;import org.springframework.data.annotation.Id;import org.springframework.data.mongodb.core.mapping.Document;import org.springframework.data.mongodb.core.mapping.Field; // 这是一个文档public class Order { @Id // 指定 id private String id; @Field("customer") // 覆盖默认的域名 private String customer; private String type; private Collection<Item> items = new LinkedHashSet<Item>(); public String getCustomer() { return customer; } public void setCustomer(String customer) { this.customer = customer; } public String getType() { return type; } public void setType(String type) { this.type = type; } public Collection<Item> getItems() { return items; } public void setItems(Collection<Item> items) { this.items = items; } public String getId() { return id; } } |
我们可以看到,Order 类添加了 @Document 注解,这样它就能够借助 MongoTemplate 或自动生成的 Repository 进行持久化。其 id 属性上使用了 @Id 注解,用来指定它作为文档的 ID。除此之外,customer 属性上使用了 @Field 注解,这样的话,当文档持久化的时候 customer 属性将会映射为名为client的域。
注意,其他的属性并没有添加注解。除非将属性设置为瞬时态(transient)的,否则 Java 对象中所有的域都会持久化为文档中的域。并且如果我们不使用 @Field 注解进行设置的话,那么文档域中的名字将会与对应的 Java 属性相同。
同时,需要注意的是 items 属性,它指的是订单中具体条目的集合。在传统的关系型数据库中,这些条目将会保存在另外的一个数据库表中,通过外键进行应用, items 域上很可能还会使用 JPA 的 @OneToMany 注解。但在这里,情形完全不同。
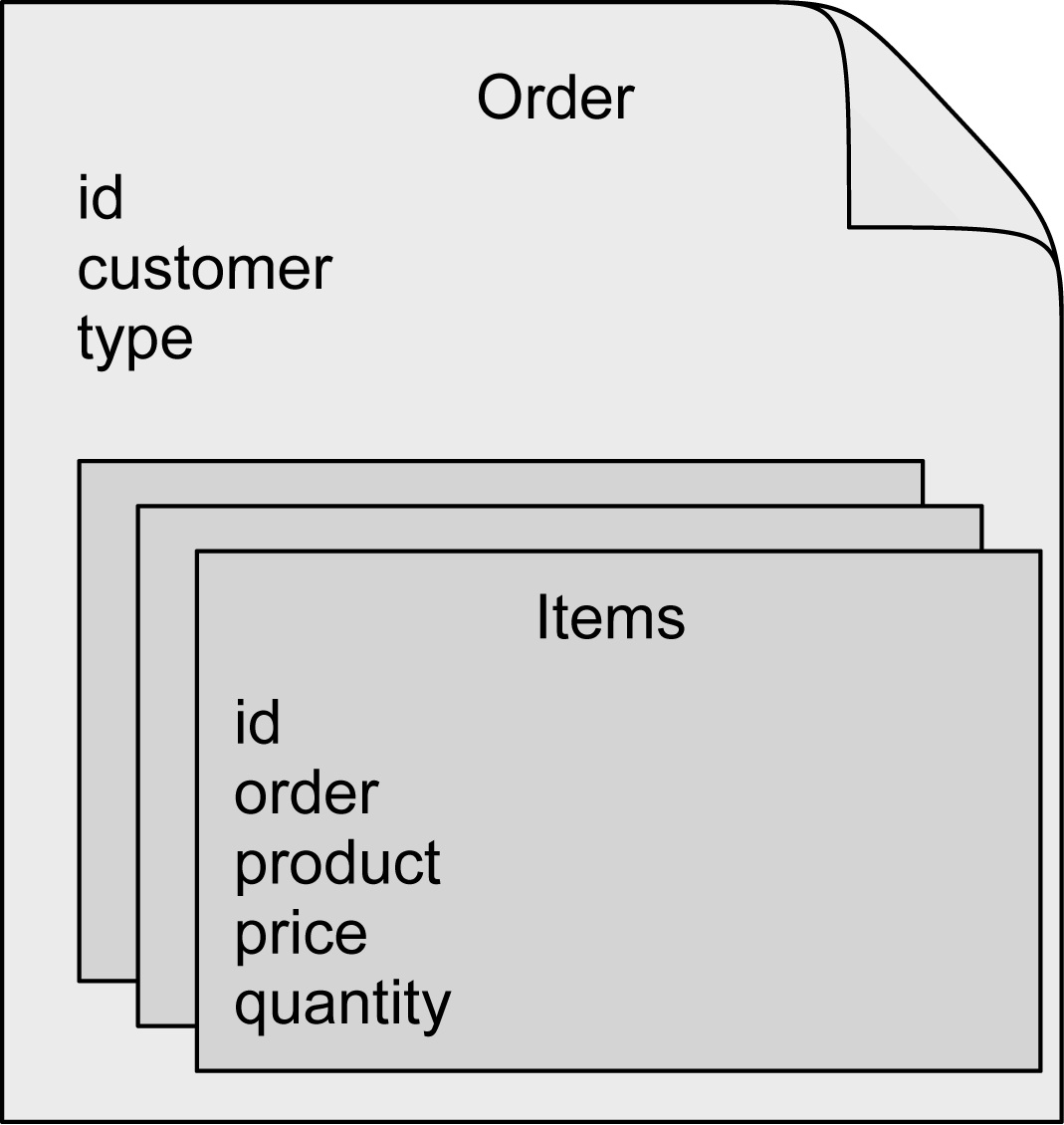
如我前面所述,文档可以与其他的文档产生关联,但这并不是文档数据库所擅长的功能。在本例购买订单与行条目之间的关联关系中,行条目只是同一个订单文档里面内嵌的一部分(如图 12.1 所示)。因此,没有必要为这种关联关系添加任何注解。实际上,Item 类本身并没有任何注解:
1 | package orders;public class Item { private Long id; private Order order; private String product; private double price; private int quantity; public Order getOrder() { return order; } public String getProduct() { return product; } public void setProduct(String product) { this.product = product; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } public int getQuantity() { return quantity; } public void setQuantity(int quantity) { this.quantity = quantity; } public Long getId() { return id; }} |
我们没有必要为 Item 添加 @Document 注解,也没有必要为它的域指定 @Id。这是因为我们不会单独将 Item 持久化为文档。它始终会是 Order 文档中 Item 列表的一个成员,并且会作为文档中的嵌入元素。
当然,如果你想指定 Item 中的某个域如何持久化到文档中,那么可以为对应的 Item 属性添加 @Field 注解。不过在本例中,并没有必要这样做。
我们现在已经为 Java 对象添加了 MongoDB 持久化的注解。接下来,看一下如何使用 MongoTemplate 来存储它们。
使用 MongoTemplate 访问 MongoDB
我们已经在配置类中配置了 MongoTemplate bean,不管是显式声明还是扩展 AbstractMongoConfiguration 都能实现相同的效果。接下来,需要做的就是将其注入到使用它的地方:
1 | mongo; |
注意,在这里我们将 MongoTemplate 注入到一个类型为 MongoOperations 的属性中。MongoOperations 是 MongoTemplate 所实现的接口,不使用具体实现是一个好的做法,尤其是在注入的时候。
MongoOperations 暴露了多个使用 MongoDB 文档数据库的方法。在这里,我们不可能讨论所有的方法,但是可以看一下最为常用的几个操作,比如计算文档集合中有多少条文档。使用注入的 MongoOperations,我们可以得到 Order 集合并调用 count() 来得到数量:
1 | long orderCount = mongo.getCollection("order").count(); |
现在,假设要保存一个新的 Order。为了完成这个任务,我们可以调用 save() 方法:
1 | Order order = new Order();... // set properties and add line itemmongo.save(order, "order"); |
save() 方法的第一个参数是新创建的 Order,第二个参数是要保存的文档存储的名称。
另外,我们还可以调用 findById() 方法来根据 ID 查找订单:
1 | String orderId = ...;Order order = mongo.findById(orderId, Order.class); |
对于更高级的查询,我们需要构造 Query 对象并将其传递给 find() 方法。例如,要查找所有 client 域等于 “Chuck Wagon” 的订单,可以使用如下的代码:
1 | List<Order> chucksOrders = mongo.find( Query.query(Criteria.where("client").is("Chuck Wagon")), Order.class); |
在本例中,用来构造 Query 对象的 Criteria 只检查了一个域,但是它也可以用来构造更加有意思的查询。比如,我们想要查询 Chuck 所有通过 Web 创建的订单:
1 | List<Order> chucksWebOrders = mongo.find(Query.query( Criteria.where("customer").is("Chuck Wagon") .and("type").is("WEB")), Order.class); |
如果你想移除某一个文档的话,那么就应该使用 remove() 方法:
1 | mongo.remove(order); |
如我前面所述,MongoOperations 有多个操作文档数据的方法。我建议你查看一下其 JavaDoc 文档,以了解通过 MongoOperations 都能完成什么功能。
通常来讲,我们会将 MongoOperations 注入到自己设计的 Repository 类中,并使用它的操作来实现 Repository 方法。但是,如果你不愿意编写 Repository 的话,那么 Spring Data MongoDB 能够自动在运行时生成 Repository 实现。下面,我们来看一下是如何实现的。
编写 MongoDB Repository
为了理解如何使用 Spring Data MongoDB 来创建 Repository,让我们先回忆一下在第 11 章中是如何使用 Spring Data JPA 的。在程序清单 11.4 中,我们创建了一个扩展自 JpaRepository 的 SpitterRepository 接口。在那一小节中,我们还启用了 SpringData JPA Repository 功能。这样的结果就是 Spring Data JPA 能够自动创建接口的实现,其中包括了多个内置的方法以及我们所添加的遵循命名约定的方法。
我们已经通过 @EnableMongoRepositories 注解启用了 Spring Data MongoDB 的 Repository 功能,接下来需要做的就是创建一个接口,Repository 实现要基于这个接口来生成。不过,在这里,我们不再扩展 JpaRepository,而是要扩展 MongoRepository。如下程序清单中的 OrderRepository 扩展了 MongoRepository,为 Order 文档提供了基本的 CRUD 操作。
1 | package orders.db;import orders.Order;import org.springframework.data.mongodb.repository.MongoRepository;public interface OrderRepository extends MongoRepository<Order, String> {} |
因为 OrderRepository 扩展了MongoRepository,因此它就会传递性地扩展 Repository 标记接口。回忆一下我们在学习 Spring Data JPA 时所了解的知识,任何扩展 Repository 的接口将会在运行时自动生成实现。在本例中,并不会实现与关系型数据库交互的 JPA Repository,而是会为 OrderRepository 生成读取和写入数据到 MongoDB 文档数据库的实现。
MongoRepository 接口有两个参数,第一个是带有 @Document 注解的对象类型,也就是该 Repository 要处理的类型。第二个参数是带有 @Id 注解的属性类型。
尽管 OrderRepository 本身并没有定义任何方法,但是它会继承多个方法,包括对 Order 文档进行 CRUD 操作的方法。表 12.2 描述了 OrderRepository 继承的所有方法。
| 方 法 | 描 述 |
|---|---|
long count(); |
返回指定 Repository 类型的文档数量 |
void delete(Iterable<? extends T); |
删除与指定对象关联的所有文档 |
void delete(T); |
删除与指定对象关联的文档 |
void delete(ID); |
根据 ID 删除某一个文档 |
void deleteAll(); |
删除指定 Repository 类型的所有文档 |
boolean exists(Object); |
如果存在与指定对象相关联的文档,则返回 true |
boolean exists(ID); |
如果存在指定 ID 的文档,则返回 true |
List<T> findAll(); |
返回指定 Repository 类型的所有文档 |
List<T> findAll(Iterable<ID>); |
返回指定文档 ID 对应的所有文档 |
| 为指定的 Repository 类型,返回分页且排序的文档列表 | |
List<T> findAll(Sort); |
为指定的 Repository 类型,返回排序后的所有文档列表 |
T findOne(ID); |
为指定的 ID 返回单个文档 |
save( terable<s>) ; |
保存指定 Iterable 中的所有文档 |
save ( < S > ); |
为给定的对象保存一条文档 |
表 12.2 中的方法使用了传递进来和方法返回的泛型。OrderRepository 扩展了 MongoRepository<Order, String>,那么 T 就映射为 Order,ID 映射为 String,而 S 映射为所有扩展 Order 的类型。
添加自定义的查询方法
通常来讲,CRUD 操作是很有用的,但我们有时候可能希望 Repository 提供除内置方法以外的其他方法。
在 11.3.1 小节中,我们学习了 Spring Data JPA 支持方法命名约定,它能够帮助 Spring Data 为遵循约定的方法自动生成实现。实际上,相同的约定也适用于 Spring Data MongoDB。这意味着我们可以为 OrderRepository 添加自定义的方法:
1 | public interface OrderReporitory extends MongoRepository<Order, String> { List<Order> findByCustomer(String c); List<Order> findByCustomerLike(String c); List<Order> findByCustomerAndType(String c, String t); List<Order> findByCustomerLikeAndType(String c, String t);} |
这里我们有四个新的方法,每一个都是查找满足特定条件的 Order 对象。其中第一个用来获取 customer 属性等于传入值的 Order 列表;第二个方法获取 customer 属性 like 传入值的 Order 列表;接下来方法会返回 customer 和 type 属性等于传入值的 Order 对象;最后一个方法与前一个类似,只不过 customer 在对比的时候使用的是 like 而不是 equals。
其中,find 这个查询动词并不是固定的。如果喜欢的话,我们还可以使用 get 作为查询动词:
1 | List<Order> getByCustomer(String c); |
如果 read 更适合的话,你还可以使用这个动词:
1 | List<Order> readByCustomer(String c); |
除此之外,还有一个特殊的动词用来为匹配的对象计数:
1 | int countByCustomer(String c); |
与 Spring Data JPA 类似,在查询动词与 By 之前,我们有很大的灵活性。例如,我们可以标示要查找什么内容:
1 | List<Order> findOrdersByCustomer(String c); |
其中,Orders 这个词没并没有什么特殊之处,它不会影响要获取的内容。我们也可以将方法按照如下的方式命名:
1 | List<Order> findSomeStuffWeNeedsByCustomer(String c); |
其实,并不是必须要返回 List<Order>,如果只想要一个 Order 对象的话,我们可以只需简单地返回 Order:
1 | Order findASingleOrderByCustomer(String c); |
这里,所返回的就是原本 List 中的第一个 Order 对象。如果没有匹配元素的话,方法将会返回 null。
指定查询
在 11.3.2 小节中,@Query 注解可以为 Repository 方法指定自定义的查询。@Query 能够像在 JPA 中那样用在MongoDB上。唯一的区别在于针对 MongoDB 时,@Query 会接受一个 JSON 查询,而不是 JPA 查询。
例如,假设我们想要查询给定类型的订单,并且要求 customer 的名称为 “Chuck Wagon”。OrderRepository 中如下的方法声明能够完成所需的任务:
1 | List<Order> findChucksOrders(String t); |
@Query 中给定的 JSON 将会与所有的 Order 文档进行匹配,并返回匹配的文档。需要注意的是,type 属性映射成了 “?0”,这表明 type 属性应该与查询方法的第零个参数相等。如果有多个参数的话,它们可以通过 “?1”、“?2” 等方式进行引用。
混合自定义的功能
在 11.3.3 小节中,我们学习了如何将完全自定义的方法混合到自动生成的 Repository中。对于 JPA 来说,这还涉及到创建一个中间接口来声明自定义的方法,为这些自定义方法创建实现类并修改自动化的 Repository 接口,使其扩展中间接口。对于 Spring Data MongoDB 来说,这些步骤都是相同的。
假设我们想要查询文档中 type 属性匹配给定值的 Order 对象。我们可以通过创建签名为 List<Order> findByType(String t) 的方法,很容易实现这个功能。但是,如果给定的类型是 “NET”,那我们就查找 type 值为 “WEB” 的 Order 对象。要实现这个功能的话,这就有些困难了,即便使用 @Query 注解也不容易实现。不过,混合实现的做法能够完成这项任务。
首先,定义中间接口:
1 | package order.db;import java.util.List;import order.Order;public interface OrderOperations { List<Order> findOrdersByType(String t);} |
这非常简单。接下来,我们要编写混合实现,具体实现如下面的程序清单所示。
1 | package orders.db;import java.util.List;import orders.Order;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.mongodb.core.MongoOperations;import org.springframework.data.mongodb.core.query.Criteria;import org.springframework.data.mongodb.core.query.Query;public class OrderRepositoryImpl implements OrderOperations { private MongoOperations mongo; public List<Order> findOrderByType(String t) { String type = t.equals("NET") ? "WEB" : t; Criteria where = Criteria.where("type").is(t); Query query = Query.query(where); return mongo.find(query, Order.class); }} |
可以看到,混合实现中注入了 MongoOperations(也就是 MongoTemplate 所实现的接口)。findOrdersByType() 方法使用 MongoOperations 对数据库进行了查询,查找匹配条件的文档。
剩下的工作就是修改 OrderRepository,让其扩展中间接口 OrderOperations:
1 | public interface OrderRepository extends MongoRepository<Order, String>, OrderOperation{} |
将这些关联起来的关键点在于实现类的名称为 OrderRepositoryImpl。这个名字前半部分与 OrderRepository 相同,只是添加了 “Impl” 后缀。当 Spring Data
MongoDB 生成 Repository 实现时,它会查找这个类并将其混合到自动生成的实现中。
如果你不喜欢 “Impl” 后缀的话,那么可以配置 Spring Data MongoDB,让其按照名字查找具备不同后缀的类。我们需要做的就是设置 @EnableMongoRepositories 的属性(在 Spring 配置类中):
1 | public class MongoConfig extends AbstractMongoConfiguration {} |
如果使用XML配置的话,我们可以设置 <mongo:repositories> 的 repository-impl-postfix 属性:
1 | <mongo:repositories base-package="orders.db" repository-impl-postfix="Stuff" /> |
不管采用哪种方式,我们现在都让 Spring Data MongoDB 查找名为 OrderRepositoryStuff 的类,而不再查找 OrderRepositoryImpl。
像 MongoDB 这样的文档数据库能够解决特定类型的问题,但是就像关系型数据库不是全能型数据库那样,MongoDB 同样如此。有些问题并不是关系型数据库或文档型数据库适合解决的,不过,幸好我们的选择并不仅限于这两种。
接下来,我们看一下 Spring Data如何支持 Neo4j,这是一种很流行的图数据库。
使用 Neo4j 操作图数据
文档型数据库会将数据存储到粗粒度的文档中,而图数据库会将数据存储到多个细粒度的节点中,这些节点之间通过关系建立关联。图数据库中的一个节点通常会对应数据库中的一个概念(concept),它会具备描述节点状态的属性。连接两个节点的关联关系可能也会带有属性。
按照其最简单的形式,图数据库比文档数据库更加通用,有可能会成为关系型数据库的无模式(schemaless)替代方案。因为数据的结构是图,所以可以遍历关联关系以查找数据中你所关心的内容,这在其他数据库中是很难甚至无法实现的。
Spring Data Neo4j 提供了很多与 Spring Data JPA 和 Spring Data MongoDB 相同的功能,当然所针对的是 Neo4j 图数据库。它提供了将 Java 对象映射到节点和关联关系的注解、面向模板的 Neo4j 访问方式以及 Repository 实现的自动化生成功能。
我们稍后会看到如何在 Neo4j 中使用这些特性,不过首先我们需要配置 Spring Data Neo4j。
配置 Spring Data Neo4j
配置 Spring Data Neo4j 的关键在于声明 GraphDatabaseService bean 和启用 Neo4j Repository 自动生成功能。如下的程序清单展现了 Spring Data Neo4j 所需的基本配置。
1 | package orders.config;import org.neo4j.graphdb.GraphDatabaseService;import org.neo4j.graphdb.factory.GraphDatabaseFactory;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.neo4j.config.EnableNeo4jRepositories;import org.springframework.data.neo4j.config.Neo4jConfiguration;public class Neo4jConfig extends Neo4jConfiguration { public Neo4jConfig() { setBasePackage("orders"); } public GraphDatabaseService graphDatabaseService() { return new GraphDatabaseFactory() .newEmbeddedDatabase("/tmp/graphdb"); }} |
@EnableNeo4jRepositories 注解能够让 Spring Data Neo4j 自动生成 Neo4j Repository 实现。它的 basePackages 属性设置为 orders.db 包,这样它就会扫描这个包来查找(直接或间接)扩展 Repository 标记接口的其他接口。
Neo4jConfig 扩展自 Neo4jConfiguration,后者提供了多个便利的方法来配置 Spring Data Neo4j。在这些方法中,就包括 setBasePackage(),它会在Neo4jConfig 的构造器中调用,用来告诉 Spring Data Neo4j 要在 orders 包中查找模型类。
这个拼图的最后一部分是定义 GraphDatabaseServicebean。在本例中,graphDatabaseService() 方法使用 GraphDatabaseFactory 来创建嵌入式的 Neo4j 数据库。在 Neo4j 中,嵌入式数据库不要与内存数据库相混淆。在这里,“嵌入式”指的是数据库引擎与应用运行在同一个 JVM 中,作为应用的一部分,而不是独立的服务器。数据依然会持久化到文件系统中(在本例中,也就是 “/tmp/graphdb” 中)。
作为另外的一种方式,你可能会希望配置 GraphDatabaseService 连接远程的 Neo4j 服务器。如果 spring-data-neo4j-rest 库在应用的类路径下,那么我们就可以配置 SpringRestGraphDatabase,它会通过 RESTful API 来访问远程的 Neo4j 数据库:
1 | public GraphDatabaseService grapthDatabaseService() { return new SpringRestGraphDatabser( "http://graphdbserver:7474/db/data/");} |
如上所示,SpringRestGraphDatabase 在配置时,假设远程的数据库并不需要认证。但是,在生产环境的配置中,当创建 SpringRestGraphDatabase 的时候,我们可能希望提供应用的凭证:
1 | public GraphDatabaseService grapthDatabaseService(Enviroment env) { return new SpringRestGraphDatabser( "http://graphdbserver:7474/db/data/", env.getProperty("db.username"), env.getProperty("db.password"));} |
在这里,凭证是通过注入的 Environment 获取到的,避免了在配置类中的硬编码。
Spring Data Neo4j 同时还提供了 XML 命名空间。如果你更愿意在 XML 中配置 Spring Data Neo4j 的话,那可以使用该命名空间中的 <neo4j:config> 和 <neo4j:repositories> 元素。在功能上,程序清单 12.9 所展示的配置与程序清单 12.8 中的 Java 配置是相同的。
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:neo4j="http://www.springframework.org/schema/data/neo4j" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/data/neo4j http://www.springframework.org/schema/data/neo4j/spring-neo4j.xsd" > <neo4j:config storeDirectory="/tmp/graphdb" base-package="orders" /> <neo4j:repositoried base-package="orders.db" /></beans> |
<neo4j:config> 元素配置了如何访问数据库的细节。在本例中,它配置 Spring Data Neo4j 使用嵌入式的数据库。具体来讲,storeDirectory 属性指定了数据要持久化到哪个文件系统路径中。base-package 属性设置了模型类定义在哪个包中。
至于 <neo4j:repositories> 元素,它启用Spring Data Neo4j 自动生成 Repository 实现的功能,它会扫描 orders.db 包,查找所有扩展 Repository 的接口。
如果要配置 Spring Data Neo4j 访问远程的 Neo4j 服务器,我们所需要做的就是声明 SpringRestGraphDatabasebean,并设置 <neo4j:config> 的 graphDatabaseService 属性:
1 | <neo4j:config base-package="orders" graphDatabaseService="graphDatabaseService" /> <bean id="graphDatabaseService" class="org.springframework.data.neo4j.rest.SpringRestGraphDatabase"> <constructor-arg value="http://graphserver:7474/db/data/" /> <constructor-arg value="db.username" /> <constructoe-arg value="db.password" /> </bean> <neo4j:repositoried base-package="orders.db" /> |
不管是通过 Java 还是通过 XML 来配置 Spring Data Neo4j,我们都需要确保模型类位于基础包所指定的包中(通过 @EnableNeo4jRepositories 的 basePackages 属性或 <neo4j:config> 的 base-package 属性来进行设置)。它们都需要使用注解将其标注为节点实体或关联关系实体。这就是我们接下来的任务。
使用注解标注图实体
Neo4j 定义了两种类型的实体:节点(node)和关联关系(relationship)。一般来讲,节点反映了应用中的事物,而关联关系定义了这些事物是如何联系在一起的。
Spring Data Neo4j 提供了多个注解,它们可以应用在模型类型及其域上,实现 Neo4j 中的持久化。表 12.3 描述了这些注解。
| 注 解 | 描 述 |
|---|---|
| @NodeEntity | 将 Java 类型声明为节点实体 |
| @RelationshipEntity | 将 Java 类型声明为关联关系实体 |
| @StartNode | 将某个属性声明为关联关系实体的开始节点 |
| @EndNode | 将某个属性声明为关联关系实体的结束节点 |
| @Fetch | 将实体的属性声明为立即加载 |
| @GraphId | 将某个属性设置为实体的 ID 域(这个域的类型必须是 Long) |
| @GraphProperty | 明确声明某个属性 |
| @GraphTraversal | 声明某个属性会自动提供一个 iterable 元素,这个元素是图遍历所构建的 |
| @Indexed | 声明某个属性应该被索引 |
| @Labels | 为 @NodeEntity 声明标签 |
| @Query | 声明某个属性会自动提供一个 iterable 元素,这个元素是执行给定的 Cypher 查询所构建的 |
| @QueryResult | 声明某个 Java 或接口能够持有查询的结果 |
| @RelatedTo | 通过某个属性,声明当前的 @NodeEntity 与另外一个 @NodeEntity 之间的关联关系 |
| @RelatedToVia | 在 @NodeEntity 上声明某个属性,指定其引用该节点所属的某一个 @RelationshipEntity |
| @RelationshipType | 将某个域声明为关联实体类型 |
| @ResultColumn | 在带有 @QueryResult 注解的类型上,将某个属性声明为获取 |
查询结果集中的某个特定列
为了了解如何使用其中的某些注解,我们会将其应用到订单/条目样例中。
在该样例中,数据建模的一种方式就是将订单设定为一个节点,它会与一个或多个条目关联。图 12.2 以图的形式描述了这种模型。

为了将订单指定为节点,我们需要为 Order 类添加 @NodeEntity 注解。如下的程序清单展现了带有 @NodeEntity 注解的 Order 类,它还包含了表 12.3 中的几个其他注解。
1 | package orders;import java.util.LinkedHashSet;import java.util.Set;import org.springframework.data.neo4j.annotation.GraphId;import org.springframework.data.neo4j.annotation.NodeEntity;import org.springframework.data.neo4j.annotation.RelatedTo; class Order { private Long id; private String customer; private String type; private Set<Item> items = new LinkedHashSet<Item>(); ... } |
除了类级别上的@NodeEntity,还要注意id属性上使用了 @GraphId 注解。Neo4j 上的所有实体必要要有一个图 ID。这大致类似于 JPA @Entity 以及 MongoDB @Document 类中使用 @Id 注解的属性。在这里,@GraphId 注解标注的属性必须是 Long 类型。
customer 和 type 属性上没有任何注解。只要这些属性不是瞬态的,它们都会成为数据库中节点的属性。items 属性上使用了 @RelatedTo 注解,这表明 Order 与一个 Item 的 Set 存在关联关系。type 属性实际上就是为关联关系建立了一个文本标记。它可以设置成任意的值,但通常会给定一个易于人类阅读的文本,用来简单描述这个关联关系的特征。稍后,你将会看到如何将这个标记用在查询中,实现跨关联关系的查询。
就 Item 本身来说,下面展现了如何为其添加注解实现图的持久化。
1 | package orders;import org.springframework.data.neo4j.annotation.GraphId;import org.springframework.data.neo4j.annotation.NodeEntity; class Item { private Long id; private Order order; private String product; private double price; private int quantity; ...} |
类似于 Order,Item 也使用了 @NodeEntity 注解,将其标记为一个节点。它同时也有一个 Long 类型的属性,借助 @GraphId 注解将其标注为节点的图 ID,而product、price 以及 quantity 属性均会作为图数据库中节点的属性。
Order 和 Item 之间的关联关系很简单,关系本身并不包含任何的数据。因此,@RelatedTo注解就足以定义关联关系。但是,并不是所有的关联关系都这么简单。
让我们重新考虑该如何为数据建模,从而学习如何使用更为复杂的关联关系。在当前的数据模型中,我们将条目和产品的信息组合到了 Item 类中。但是,当我们重新考虑的时候,会发现订单会与一个或多个产品相关联。订单与产品之间的关系构成了订单的一个条目。图 12.3 描述了另外一种在图中建模数据的方式。
在这个新的模型中,订单中产品的数量是条目中的一个属性,而产品本身是另外一个概念。与前面一样,订单和产品都是节点,而条目是关联关系。因为现在的条目必须要包含一个数量值,关联关系不像前面那么简单。我们需要定义一个类来代表条目,比如如下程序清单所示的 LineItem。
1 | package orders;import org.springframework.data.neo4j.annotation.EndNode;import org.springframework.data.neo4j.annotation.GraphId;import org.springframework.data.neo4j.annotation.RelationShipEntity;import org.springframework.data.neo4j.annotation.StartNode;public class LineItem { private Long id; private Order order; private String product; private int quantity; ...} |
Order 类通过 @NodeEntity 注解将其标示为一个节点,而 LineItem 类则使用了 @RelationshipEntity 注解。LineItem 同样也有一个 id 属性标注了 @GraphId 注解,不管是节点实体还是关联关系实体,都必须要有一个图 ID,而且其类型必须为 Long。
关联关系实体的特殊之处在于它们连接了两个节点。@StartNode 和@ EndNode 注解用在定义关联关系两端的属性上。在本例中,Order 是开始节点,Product 是结束节点。
最后,LineItem 类有一个 quantity 属性,当关联关系创建的时候,它会持久化到数据库中。
领域对象已经添加了注解,现在就可以保存与读取节点和关联关系了。我们首先看一下如何使用 Spring Data Neo4j 中的 Neo4jTemplate 实现面向模板的数据访问。
使用 Neo4jTemplate
Spring Data MongoDB 提供了 MongoTemplate 实现基于模板的 MongoDB 持久化,与之类似,Spring Data Neo4j 提供了 Neo4jTemplate 来操作 Neo4j 图数据库中的节点和关联关系。如果你已经按照前面的方式配置了 Spring Data Neo4j,在 Spring 应用上下文中就已经具备了一个 Neo4jTemplate bean。接下来需要做的就是将其注入到任意想使用它的地方。
例如,我们可以直接将其自动装配到某个 bean 的属性上:
1 | Neo4jOperations neo4j; |
Neo4jTemplate 定义了很多的方法,包括保存节点、删除节点以及创建节点间的关联关系。我们没有足够的篇幅介绍所有的方法,但是我们会看一下 Neo4jTemplate 所提供的最为常用的方法。
我们想借助 Neo4jTemplate 完成的最基本的一件事情可能就是将某个对象保存为节点。假设这个对象已经使用了 @NodeEntity 注解,那么我们可以按照如下的方式来使用 save() 方法:
1 | Order order = ...;Order saveOrder = neo4j.save(order); |
如果你能知道对象的图 ID,那么可以通过 findOne() 方法来获取它:
1 | Order order = neo4j.findOne(42, Order.class); |
如果按照给定的 ID 找不到节点的话,那么 findOne() 方法将会抛出 NotFound(Exception)。
如果你想获取给定类型的所有对象,那么可以使用 findAll() 方法:
1 | EndResult<Order> allOrders = neo4j.findAll(Order.class); |
这里返回的 EndResult 是一个 Iterable,它能够用在 for-each 循环以及任何可以使用 Iterable 的地方。如果不存在这样的节点的话,findAll() 方法将会返回空的 Iterable。
如果你只是想知道 Neo4j 数据库中指定类型的对象数量,那么就可以调用 count() 方法:
1 | long orderCount = count(Order.class); |
delete() 方法可以用来删除对象:
1 | neo4j.delete(order); |
createRelationshipBetween() 是 Neo4jTemplate 所提供的最有意思的方法之一。我们可以猜到,它会为两个节点创建关联关系。
例如,我们可以在 Order 节点和 Product 节点之间建立 LineItem 关联关系:
1 | Order order = ...;Product prod = ...;LineItem lineItem = neo4j.createRelationShipBetween( order, prod, LineItem.class, "HAS_LINE_ITEM_FOR", false);lineItem.setQuantity(5);neo4j.save(lineItem); |
createRelationshipBetween() 方法的前两个参数是关联关系两端的节点对象。接下来的参数指定了使用 @RelationshipEntity 注解的类型,它会代表这种关系。接下来的 String 值描述了关联关系的特征。最后的参数是一个 boolean 值,它表明这两个节点实体之间是否允许存在重复的关联关系。
createRelationshipBetween() 会返回关联关系类的一个实例。通过它,我们可以设置任意的属性。上面的示例中设置了 quantity 属性。当这一切完成后,我们调用 save() 方法将关联关系保存到数据库中。
Neo4jTemplate 提供了很便利的方式来使用 Neo4j 图数据库中的节点和关联关系。但是,这种方式需要借助 Neo4jTemplate 编写自己的 Repository 实现。接下来,我们看一下 Spring Data Neo4j 怎样为我们自动化生成 Repository 实现。
创建自动化的 Neo4j Repository
大多数 Spring Data 项目都具备的最棒的一项功能就是为 Repository 接口自动生成实现。我们已经在 Spring Data JPA 和 Spring Data MongoDB 中看到了这项功能。Spring Data Neo4j 也不例外,它同样支持 Repository 自动化生成功能。
我们已经将 @EnableNeo4jRepositories 添加到了配置中,所以 Spring Data Neo4j 已经配置为支持自动化生成 Repository 的功能。我们所需要做的就是编写接口,如下的 OrderRepository 就是很好的起点:
1 | package orders.db;import orders.Order;import org.springframework.data.neo4j.repository.GraphRepository;public interface OrderRepository extends GraphRepository<Order> {} |
与其他的 Spring Data 项目一样,Spring Data Neo4j 会为扩展 Repository 接口的其他接口生成 Repository 方法实现。在本例中,OrderRepository 扩展了 GraphRepository,而后者又间接扩展了 Repository 接口。因此,Spring Data Neo4j 将会在运行时创建 OrderRepository 的实现。
注意,GraphRepository 使用 Order 进行了参数化,也就是这个 Repository 所要使用的实体类型。因为 Neo4j 要求图 ID 的类型为 Long,因此在扩展 GraphRepository 的时候,没有必要再去指定 ID 类型。
现在,我们就能够使用很多通用的 CRUD 操作,这与 JpaRepository 和 MongoRepository 所提供的功能类似。表 12.4 描述了扩展 GraphRepository 所能够得到的方法。
| 方 法 | 描 述 |
|---|---|
| long count(); | 返回在数据库中,目标类型有多少实体 |
| void delete(Iterable<?extendsT>); | 删除多个实体 |
| void delete(Long id); | 根据 ID,删除一个实体 |
| void delete(T); | 删除一个实体 |
| void deleteAll(); | 删除目标类型的所有实体 |
| boolean exists(Long id); | 根据指定的 ID,检查实体是否存在 |
| EndResult |
获取目标类型的所有实体 |
| 根据给定的 ID,获取目标类型的实体 | |
| Page |
返回目标类型分页和排序后的实体列表 |
| EndResult |
返回目标类型排序后的实体列表 |
| EndResult |
返回指定属性匹配给定值的所有实体 |
| Iterable |
返回从某个节点开始,图遍历到达的节点 |
| T findBySchemaPropertyValue (String,Object); | 返回指定属性匹配给定值的一个实体 |
| T findOne(Long); | 根据 ID,获得某一个实体 |
| EndResult |
返回匹配给定 Cypher 查询的所有实体 |
| Iterable |
保存多个实体 |
| S save(S); | 保存一个实体 |
我们没有足够的篇幅介绍所有的方法,但是有些方法你可能会经常用到。例如,如下的代码能够保存一个 Order 实体:
1 | Order saveOrder = orderRepository.save(order); |
当实体保存之后,save() 方法将会返回被保存的实体,如果之前它使用 @GraphId 注解的属性值为 null 的话,此时这个属性将会填充上值。
我们还可以使用 findOne() 方法查询某一个实体。例如,下面的这行代码将会查询图 ID 为 4 的 Order:
1 | Order order = orderRepository.findOne(4L); |
我们还可以查询所有的 Order:
1 | EndResult<Order> allOrders = orderRepository.findAll(); |
当然,你可能还希望删除某一个实体。这种情况下,可以使用 delete() 方法:
1 | delete(order); |
这将会从数据库中删除给定的 Order 节点。如果你只有图 ID 的话,那可以将其传递到 delete() 方法中,而不是再使用节点类型本身:
1 | delete(orderId); |
如果你希望进行自定义的查询,那么可以使用 query() 方法对数据库执行任意的 Cypher 查询。但是这与使用 Neo4jTemplate 的 query() 方法并没有太大的差别。其实,我们还可以为 OrderRepository 添加自定义的查询方法。
添加查询方法
我们已经看过如何按照命名约定使用 Spring Data JPA 和 Spring Data MongoDB 来添加自定义的查询方法。如果 Spring Data Neo4j 没有提供相同功能的话,那我们就该失望了。
如下面的程序清单所示,其实我们完全没有必要失望:
1 | package orders.db;import java.util.List;import orders.Order;import org.springframework.data.neo4j.repository.GraphRepository;public interface OrderRepository extends GraphRepository<Order> { List<Order> findByCustomer(String customer); List<Order> findByCustomerAndType(String customer, String type);} |
这里,我们添加了两个方法。其中一个会查询 customer 属性等于给定 String 值的 Order 节点。另外一个方法与之类似,但是除了匹配我们之前已经讨论过查询方法的命名约定,所以这里没有必要再进行深入地讨论。可以翻看之前学习 Spring Data JPA 的章节,重新温习如何编写这些方法。
指定自定义查询
当命名约定无法满足需求时,我们还可以为方法添加 @Query 注解,为其指定自定义的查询。我们之前已经见过 @Query 注解。在 Spring Data JPA 中,我们使用它来为 Repository 方法指定 JPA 查询。在 Spring Data MongoDB 中,我们使用它来指定匹配 JSON 的查询。但是,在使用 Spring Data Neo4j 的时候,我们必须指定 Cypher 查询:
1 | List<Order> findSiAOrders(); |
在这里,findSiAOrders() 方法上使用了 @Query 注解,并设置了一个 Cypher 查询,它会查找与 Item 关联并且 product 属性等于 “Spring in Action” 的所有 Order 节点。
混合自定义的 Repository 行为
当命名约定和 @Query 注解均无法满足满足需求的时候,我们还可以混合自定义的 Repository 逻辑。
例如,假设我们想自己编写 findSiAOrders() 方法的实现,而不是依赖于 @Query 注解。那么可以首先定义一个中间接口,该接口包含 findSiAOrders() 方法的定义:
1 | package orders.db;import java.util.List;import oders.Order;public interface OrderOperations { List<Order> findSiAOrders();} |
然后,我们修改 OrderRepository,让它扩展 OrderOperations 和 GraphRepository:
1 | public interface OrderRepository extends GraphRepository<Order>, OrderOperations {} |
最后,我们需要自己编写实现。与 Spring Data JPA 和 Spring Data MongoDB 类似,Spring Data Neo4j 将会查找名字与 Repository 接口相同且添加 “Impl” 后缀的实现类。因此,我们需要创建 OrderRepositoryImpl 类。如下的程序清单展示了 OrderRepositoryImpl 类,它实现了 findSiAOrders() 方法。
1 | package orders.db;import java.util.Collections;import java.util.List;import java.util.Map;import orders.Order;import org.neo4j.helpers.collection.IteratorUtil;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.neo4j.conversion.EndResult;import org.springframework.data.neo4j.conversion.Result;import org.springframework.data.neo4j.template.Neo4jOperations;public class OrderRepositorylmpl implements OrderOperations { private final Neo4jOperations neo4j; public OrderRepositorylmpl(Neo4jOperations neo4j) { this.neo4j = neo4j; } public List<Order> findSiAOrders() { Result<Map<String, Object>> result = neo4j.query( "match (o:Order)-[:HAS_ITEMS]->(i:Item) " + "where i.product='Spring in Action' return o", EndResult<Order> endResult = result.to{Order.class); return IteratorUtil.asList(endResult); }} |
OrderRepositoryImpl 中注入了一个 Neo4jOperations(具体来讲,就是 Neo4jTemplate 的实例),它会用来查询数据库。因为 query() 方法返回的是 Result<Map<String, Object>>,我们需要将其转换为 List
IteratorUtil.asList() 方法将 EndResult
对于能够表达为节点和关联关系的数据,像 Neo4j 这样的图数据库是非常合适的。如果将我们生活的世界理解为各种互相关联的事物,那么图数据库能够适用于很大的范围。就我个人而言,我非常喜欢的数据持久化。
使用 Redis 操作 key-value 数据
Redis 是一种特殊类型的数据库,它被称之为 key-value 存储。顾名思义,key-value 存储保存的是键值对。实际上,key-value 存储与哈希 Map 有很大的相似性。可以不太夸张地说,它们就是持久化的哈希 Map。
当你思考这一点的时候,可能会意识到,对于哈希 Map 或者 key-value 存储来说,其实并没有太多的操作。我们可以将某个 value 存储到特定的 key 上,并且能够根据特定 key,获取 value。差不多也就是这样了。因此,Spring Data 的自动 Repository 生成功能并没有应用到 Redis 上。不过,Spring Data 的另外一个关键特性,也就是面向模板的数据访问,能够在使用 Redis 的时候,为我们提供帮助。
Spring Data Redis 包含了多个模板实现,用来完成 Redis 数据库的数据存取功能。稍后,我们就会看到如何使用它们。但是为了创建 Spring Data Redis 的模板,我们首先需要有一个 Redis 连接工厂。幸好,Spring Data Redis 提供了四个连接工厂供我们选择。
连接到Redis
Redis 连接工厂会生成到 Redis 数据库服务器的连接。Spring Data Redis 为四种 Redis 客户端实现提供了连接工厂:
- JedisConnectionFactory
- JredisConnectionFactory
- LettuceConnectionFactory
- SrpConnectionFactory
具体选择哪一个取决于你。我建议你自行测试并建立基准,进而确定哪一种 Redis 客户端和连接工厂最适合你的需求。从 Spring Data Redis 的角度来看,这些连接工厂在适用性上都是相同的。
在做出决策之后,我们就可以将连接工厂配置为 Spring 中的 bean。例如,如下展示了如何配置 JedisConnectionFactory bean:
1 | RedisConnectionFactory redisCF() { return new JedisConnectionFactory();} |
通过默认构造器创建的连接工厂会向 localhost 上的 6379 端口创建连接,并且没有密码。如果你的 Redis 服务器运行在其他的主机或端口上,在创建连接工厂的时候,可以设置这些属性:
1 | RedisConnectionFactory redisCF() { JedisConnectionFactory cf = new JedisConnectionFactory(); cf.setHostName("redis-server"); cf.setPort(7379); return cf;} |
类似地,如果你的 Redis 服务器配置为需要客户端认证的话,那么可以通过调用 setPassword() 方法来设置密码:
1 | RedisConnectionFactory redisCF() { JedisConnectionFactory cf = new JedisConnectionFactory(); cf.setHostName("redis-server"); cf.setPort(7379); cf.setPassword("foobared"); return cf;} |
在上面的这些例子中,我都假设使用的是 JedisConnectionFactory。如果你选择使用其他连接工厂的话,只需进行简单地替换就可以了。例如,假设你要使
用 LettuceConnectionFactory 的话,可以按照如下的方式进行配置:
1 | RedisConnectionFactory redisCF() { JedisConnectionFactory cf = new LettuceConnectionFactory(); cf.setHostName("redis-server"); cf.setPort(7379); cf.setPassword("foobared"); return cf;} |
所有的 Redis 连接工厂都具有 setHostName()、setPort() 和 setPassword() 方法。这样,它们在配置方面实际上是相同的。
现在,我们有了 Redis 连接工厂,接下来就可以使用 Spring Data Redis 模板了。
顾名思义,Redis 连接工厂会生成到 Redis key-value 存储的连接(以 RedisConnection 的形式)。借助 RedisConnection,可以存储和读取数据。例如,我们可以获取连接并使用它来保存一个问候信息,如下所示:
1 | RedisConnectionFactory cf = ...;RedisConnection conn = cf.getConnection();conn.set("greeting".getBytes(), "Hello World".getBytes()); |
与之类似,我们还可以使用 RedisConnection 来获取之前存储的问候信息:
1 | byte[] greetingBytes = conn.get("greeting".getBytes());String greeting = new String(greetingBytes()); |
毫无疑问,这可以正常运行,但是你难道真的愿意使用字节数组吗?
使用 Redis Template
与其他的 Spring Data 项目类似,Spring Data Redis 以模板的形式提供了较高等级的数据访问方案。实际上,Spring Data Redis 提供了两个模板:
- RedisTemplate
- StringRedisTemplate
RedisTemplate 可以极大地简化 Redis 数据访问,能够让我们持久化各种类型的 key 和 value,并不局限于字节数组。在认识到 key 和 value 通常是 String 类型之后,StringRedisTemplate 扩展了 RedisTemplate,只关注 String 类型。
假设我们已经有了 RedisConnectionFactory,那么可以按照如下的方式构建 RedisTemplate:
1 | RedisConnectionFactory cf = ...;RedisTemplate<String, Product> redis = new RedisTemplate<String, Product>();redis.setConnectionFactory(cf); |
注意,RedisTemplate 使用两个类型进行了参数化。第一个是key的类型,第二个是 value 的类型。在这里所构建的 RedisTemplate 中,将会保存 Product 对象作为 value,并将其赋予一个 String 类型的 key。
如果你所使用的 value 和 key 都是 String 类型,那么可以考虑使用 StringRedisTemplate 来代替 RedisTemplate:
1 | RedisConnectionFactory cf = ...;RedisTemplate redis = new StringRedisTemplate(); |
注意,与 RedisTemplate 不同,StringRedisTemplate 有一个接受 RedisConnectionFactory 的构造器,因此没有必要在构建后再调用 setConnectionFactory()。
尽管这并非必须的,但是如果你经常使用 RedisTemplate 或 StringRedisTemplate 的话,你可以考虑将其配置为 bean,然后注入到需要的地方。如下就是一个声明 RedisTemplate 的简单 @Bean 方法:
1 | RedisTemplate<String, Product> redisTemplate(RedisConnectionFactory cf) { RedisTemplate<String, Product> redis = new RedisTemplate<String, Product>(); redis.setConnectionFactory(cf); return redis;} |
如下是声明 StringRedisTemplate bean 的 @Bean 方法:
1 | StringRedisTemplate stringRedisTemplate(RedisConnectionFactory cf) { return new StringRedisTemplate(cf);} |
有了 RedisTemplate(或 StringRedisTemplate)之后,我们就可以开始保存、获取以及删除 key-value 条目了。RedisTemplate 的大多数操作都是表 12.5 中的子 API 提供的。
| 方 法 | 子API接口 | 描 述 |
|---|---|---|
| opsForValue() | ValueOperations<K, V> | 操作具有简单值的条目 |
| opsForList() | ListOperations<K, V> | 操作具有 list 值的条目 |
| opsForSet() | SetOperations<K, V> | 操作具有 set 值的条目 |
| opsForZSet() | ZSetOperations<K, V> | 操作具有 ZSet 值(排序的 set)的条目 |
| opsForHash() | HashOperations<K, HK, HV> | 操作具有 hash 值的条目 |
| boundValueOps(K) | BoundValueOperations<K,V> | 以绑定指定 key 的方式,操作具有简单值的条目 |
| boundListOps(K) | BoundListOperations<K,V> | 以绑定指定 key 的方式,操作具有 list 值的条目 |
| boundSetOps(K) | BoundSetOperations<K,V> | 以绑定指定 key 的方式,操作具有 set 值的条目 |
| boundZSet(K) | BoundZSetOperations<K,V> | 以绑定指定 key 的方式,操作具有 ZSet 值(排序的 set)的条目 |
| boundHashOps(K) | BoundHashOperations<K,V> | 以绑定指定 key 的方式,操作具有 hash 值的条目 |
我们可以看到,表 12.5 中的子 API 能够通过 RedisTemplate(和 StringRedis-Template)进行调用。其中每个子 API 都提供了使用数据条目的操作,基于 value 中所包含的是单个值还是一个值的集合它们会有所差别。
这些子 API 中,包含了很多从 Redis 中存取数据的方法。我们没有足够的篇幅介绍所有的方法,但是会介绍一些最为常用的操作。
使用简单的值
假设我们想通过 RedisTemplate<String, Product> 保存 Product,其中 key 是 sku 属性的值。如下的代码片段展示了如何借助 opsForValue() 方法完成该功能:
1 | redis.opsForValue().set(product.getSku(), product); |
类似地,如果你希望获取 sku 属性为 123456 的产品,那么可以使用如下的代码片段:
1 | Product product = redis.opsForValue().get("123456"); |
如果按照给定的 key,无法获得条目的话,将会返回 null。
使用 List 类型的值
使用 List 类型的 value 与之类似,只需使用 opsForList() 方法即可。例如,我们可以在一个 List 类型的条目尾部添加一个值:
1 | redis.opsForList().rightPush("cart", product); |
通过这种方式,我们向列表的尾部添加了一个 Product,所使用的这个列表在存储时 key 为 cart。如果这个 key 尚未存在列表的话,将会创建一个。
rightPush() 会在列表的尾部添加一个元素,而 leftPush() 则会在列表的头部添加一个值:
1 | redis.opsForList().leftPush("cart", product); |
我们有很多方式从列表中获取元素,可以通过 leftPop() 或 rightPop() 方法从列表中弹出一个元素:
1 | Product first = redis.opsForList().leftPop("cart");Product last = redis.opsForList().rightPop("cart"); |
除了从列表中获取值以外,这两个方法还有一个副作用就是从列表中移除所弹出的元素。如果你只是想获取值的话(甚至可能要在列表的中间获取),那么可以使用 range() 方法:
1 | List<Product> products = redis.opsForList().range("cart", 2, 12); |
range() 方法不会从列表中移除任何元素,但是它会根据指定的 key 和索引范围,获取范围内的一个或多个值。前面的样例中,会获取 11 个元素,从索引为 2 的元素到索引为 12 的元素(不包含)。如果范围超出了列表的边界,那么只会返回索引在范围内的元素。如果该索引范围内没有元素的话,将会返回一个空的列表。
在 Set 上执行操作
除了操作列表以外,我们还可以使用 opsForSet() 操作 Set。最为常用的就是向其中添加一个元素:
1 | redis.opsForSet().add("cart", product); |
在我们有多个 Set 并填充值之后,就可以对这些 Set 进行一些有意思的操作,如获取其差异、求交集和求并集:
1 | List<Product> diff = redis.opsForSet().difference("cart1", "cart2");List<Product> union = redis.opsForSet().union("cart1", "cart2");List<Product> isect = redis.opsForSet().isect("cart1", "cart2"); |
当然,我们还可以移除它的元素:
1 | redis.opsForSet().remove(product); |
我们甚至还可以随机获取 Set 中的一个元素:
1 | Product random = redis.opsForSet().randomMember("cart"); |
因为 Set 没有索引和内部的排序,因此我们无法精准定位某个点,然后从 Set 中获取元素。
绑定到某个 key 上
表 12.5 包含了五个子 API,它们能够以绑定 key 的方式执行操作。这些子 API 与其他的 API 是对应的,但是关注于某一个给定的 key。
为了举例阐述这些子 API 的用法,我们假设将 Product 对象保存到一个 list 中,并且 key 为 cart。在这种场景下,假设我们想从 list 的右侧弹出一个元素,然后在 list 的尾部新增三个元素。我们此时可以使用 boundListOps() 方法所返回的 BoundListOperations:
1 | BoundListOperations<String, Product> cart = redis.boundListOps("cart");Product popped = cart.rightPop();cart.rightPush(product1);cart.rightPush(product2);cart.rightPush(product3); |
注意,我们只在一个地方使用了条目的 key,也就是调用 boundListOps() 的时候。对返回的 BoundListOperations 执行的所有操作都会应用到这个 key 上。
使用 key 和 value 的序列化器
当某个条目保存到 Redis key-value 存储的时候,key 和 value 都会使用 Redis 的序列化器(serializer)进行序列化。Spring Data Redis 提供了当某个条目保存到 Redis key-value 存储的时候,key 和 value 都会使用 Redis 的序列化器(serializer)进行序列化。Spring Data Redis 提供了多个这样的序列化器,包括:
- GenericToStringSerializer:使用 Spring 转换服务进行序列化;
- JacksonJsonRedisSerializer:使用 Jackson 1,将对象序列化为 JSON;
- Jackson2JsonRedisSerializer:使用 Jackson 2,将对象序列化为 JSON;
- JdkSerializationRedisSerializer:使用 Java 序列化;
- OxmSerializer:使用 Spring O/X 映射的编排器和解排器(marshaler 和 unmarshaler)实现序列化,用于 XML 序列化;
- StringRedisSerializer:序列化 String 类型的 key 和 value。
这些序列化器都实现了 RedisSerializer 接口,如果其中没有符合需求的序列化器,那么你还可以自行创建。
RedisTemplate 会使用 JdkSerializationRedisSerializer,这意味着 key 和 value 都会通过 Java 进行序列化。StringRedisTemplate 默认会使用 StringRedisSerializer,这在我们的预料之中,它实际上就是实现 String 与 byte 数组之间的相互转换。这些默认的设置适用于很多的场景,但有时候你可能会发现使用一个不同的序列化器也是很有用处的。
例如,假设当使用 RedisTemplate 的时候,我们希望将 Product 类型的 value 序列化为 JSON,而 key 是 String 类型。RedisTemplate 的 setKeySerializer() 和 setValueSerializer() 方法就需要如下所示:
1 | RedisTemplate<String, Product> redisTemplate(RedisConnectionFactory cf) { RedisTemplate<String, Product> redis = new RedisTemplate<String, Product>(); redis.setConnectionFactory(cf); redis.setKeySerializer(new StringRedisSerializer()); redis.setValueSerializer(new Jackson2JsonRedisSerializer<Product>(Product.class)); return redis;} |
在这里,我们设置 RedisTemplate 在序列化 key 的时候,使用 StringRedisSerializer,并且也设置了在序列化 Product 的时候,使用了 Jackson2JsonRedisSerializer。
小结
关系型数据库作为数据持久化领域唯一可选方案的时代已经一去不返了。现在,我们有多种不同的数据库,每一种都代表了不同形式的数据,并提供了适应多种领域模型的功能。Spring Data 能够让我们在 Spring 应用中使用这些数据库,并且使用一致的抽象方式访问各种数据库方案。
在本章中,我们基于前一章使用 JPA 时所学到的 Spring Data 知识,将其应用到了 MongoDB 文档数据库和 Neo4j 图数据库中。与 JPA 对应的功能类似,Spring Data MongoDB 和 Spring Data Neo4j 项目都提供了基于接口定义自动生成 Repository 的功能。除此之外,我们还看到了如何使用 Spring Data 所提供的注解将领域模型映射为文档、节点和关联关系。
Spring Data 还支持将数据持久化到 Redis key-value 存储中。Key-value 存储明显要简单一些,因此没有必要支持自动化 Repository 和映射注解。不过,Spring Data Redis 还是提供了两个不同的模板类来使用 Redis key-value 存储。
不管你选择使用哪种数据库,从数据库中获取数据都是消耗成本的操作。实际上,数据库查询是很多应用最大的性能瓶颈。我们已经看过了如何通过各种数据源存储和获取数据,现在看一下如何避免出现这种瓶颈。在下一章中,我们将会看到如何借助声明式缓存避免不必要的数据库查询。
缓存数据
本章内容:
- 启用声明式缓存
- 使用 Ehcache、Redis 和 GemFire 实现缓存功能
- 注解驱动的缓存
你有没有遇到过有人反复问你同一个问题的场景,你刚刚给出完解答,马上就会被问相同的问题?我的孩子经常会问我这样的问题:
“我能吃点糖吗?”
“现在几点了?”
“我们到了吗?”
“我能吃点糖吗?”
在很多方面看来,在我们所编写的应用中,有些的组件也是这样的。无状态的组件一般来讲扩展性会更好一些,但它们也会更加倾向于一遍遍地问相同的问题。因为它们是无状态的,所以一旦当前的任务完成,就会丢弃掉已经获取到的所有解答,下一次需要相同的答案时,它们就不得不再问一遍这个问题。
对于所提出的问题,有时候需要一点时间进行获取或计算才能得到答案。我们可能需要在数据库中获取数据,调用远程服务或者执行复杂的计算。为了得到答案,这就会花费时间和资源。
如果问题的答案变更不那么频繁(或者根本不会发生变化),那么按照相同的方式再去获取一遍就是一种浪费了。除此之外,这样做还可能会对应用的性能产生负面的影响。一遍又一遍地问相同的问题,而每次得到的答案都是一样的,与其这样,我们还不如只问一遍并将答案记住,以便稍后再次需要时使用。
缓存(Caching)可以存储经常会用到的信息,这样每次需要的时候,这些信息都是立即可用的。在本章中,我们将会了解到Spring的缓存抽象。尽管 Spring 自身并没有实现缓存解决方案,但是它对缓存功能提供了声明式的支持,能够与多种流行的缓存实现进行集成。
启用对缓存的支持
Spring 对缓存的支持有两种方式:
- 注解驱动的缓存
- XML 声明的缓存
使用 Spring 的缓存抽象时,最为通用的方式就是在方法上添加 @Cacheable 和 @CacheEvict 注解。在本章中,大多数内容都会使用这种类型的声明式注解。在 13.3 小节中,我们会看到如何使用 XML 来声明缓存边界。
在往 bean 上添加缓存注解之前,必须要启用 Spring 对注解驱动缓存的支持。如果我们使用 Java 配置的话,那么可以在其中的一个配置类上添加 @EnableCaching,这样的话就能启用注解驱动的缓存。程序清单 13.1 展现了如何实际使用 @EnableCaching。
1 | package spittr.config;import net.sf.ehcache.CacheManager;import org.springframework.cache.annotation.EnableCaching;import org.springframework.cache.ehcache.EhCacheCacheManager;import org.springframework.cache.ehcache.EhCacheManagerFactoryBean;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.core.io.ClassPathResource; class CachingConfig { public EhCacheCacheManager cacheManager(CacheManager cm) { return new EhCacheCacheManager(cm); }} |
如果以 XML 的方式配置应用的话,那么可以使用 Spring cache 命名空间中的 <cache:annotation-driven> 元素来启用注解驱动的缓存。
1 | <?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:cache="http://www.springframework.org/schema/cache" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/cache http://www.springframework.org/schema/cache/spring-cache.xsd" > <cache:annotation-driven /> <bean id="cacheManager" class="org.springframework.cache.concurrent.ConcurrentMapCacheManager" /></beans> |
其实在本质上,@EnableCaching 和 <cache:annotationdriven> 的工作方式是相同的。它们都会创建一个切面(aspect)并触发 Spring 缓存注解的切点(pointcut)。根据所使用的注解以及缓存的状态,这个切面会从缓存中获取数据,将数据添加到缓存之中或者从缓存中移除某个值。
在程序清单 13.1和程序清单 13.2 中,你可能已经注意到了,它们不仅仅启用了注解驱动的缓存,还声明了一个缓存管理器(cacheManager)的 bean。缓存管理器是 Spring 缓存抽象的核心,它能够与多个流行的缓存实现进行集成。
在本例中,声明了 ConcurrentMapCacheManager,这个简单的缓存管理器使用 java.util.concurrent.ConcurrentHashMap 作为其缓存存储。它非常简单,因此对于开发、测试或基础的应用来讲,这是一个很不错的选择。但它的缓存存储是基于内存的,所以它的生命周期是与应用关联的,对于生产级别的大型企业级应用程序,这可能并不是理想的选择。
幸好,有多个很棒的缓存管理器方案可供使用。让我们看一下几个最为常用的缓存管理器。
配置缓存管理器
Spring 3.1 内置了五个缓存管理器实现,如下所示:
- SimpleCacheManager
- NoOpCacheManager
- ConcurrentMapCacheManager
- CompositeCacheManager
- EhCacheCacheManager
Spring 3.2 引入了另外一个缓存管理器,这个管理器可以用在基于 JCache(JSR-107)的缓存提供商之中。除了核心的 Spring 框架,Spring Data 又提供了两个缓存管理器:
- RedisCacheManager(来自于 Spring Data Redis 项目)
- GemfireCacheManager(来自于 Spring Data GemFire 项目)
所以可以看到,在为 Spring 的缓存抽象选择缓存管理器时,我们有很多可选方案。具体选择哪一个要取决于想要使用的底层缓存供应商。每一个方案都可以为应用提供不同风格的缓存,其中有一些会比其他的更加适用于生产环境。尽管所做出的选择会影响到数据如何缓存,但是 Spring 声明缓存的方式上并没有什么差别。
我们必须选择一个缓存管理器,然后要在 Spring 应用上下文中,以 bean 的形式对其进行配置。我们已经看到了如何配置 ConcurrentMapCacheManager,并且知道它可能并不是实际应用的最佳选择。现在,看一下如何配置Spring其他的缓存管理器,从 EhCacheCacheManager 开始吧。
使用 Ehcache 缓存
Ehcache 是最为流行的缓存供应商之一。Ehcache 网站上说它是 “Java 领域应用最为广泛的缓存”。鉴于它的广泛采用,Spring 提供集成 Ehcache 的缓存管理器是很有意义的。这个缓存管理器也就是 EhCacheCacheManager。
当读这个名字的时候,在 cache 这个词上似乎有点结结巴巴的感觉。在 Spring 中配置 EhCacheCacheManager 是很容易的。程序清单 13.3 展现了如何在 Java 中对其进行配置。
1 | package spittr.config;import net.sf.ehcache.CacheManager;import org.springframework.cache.annotation.EnableCaching;import org.springframework.cache.ehcache.EhCacheCacheManager;import org.springframework.cache.ehcache.EhCacheManagerFactoryBean;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.core.io.ClassPathResource; class CachingConfig { public EhCacheCacheManager cacheManager(CacheManager cm) { return new EhCacheCacheManager(cm); } public EhCacheManagerFactoryBean ehcache() { EhCacheManagerFactoryBean ehCacheFactoryBean = new EhCacheManagerFactoryBean(); ehCacheFactoryBean.setConfigLocation( new ClassPathResource("spittr/cache/ehcache.xml")); return ehCacheFactoryBean; } } |
在程序清单 13.3 中,cacheManager() 方法创建了一个 EhCacheCacheManager 的实例,这是通过传入 EhcacheCacheManager 实例实现的。在这里,稍微有点诡异的注入可能会让人感觉迷惑,这是因为 Spring 和 EhCache 都定义了 CacheManager 类型。需要明确的是,EhCache 的 CacheManager 要被注入到 Spring的 EhCacheCacheManager(Spring CacheManager 的实现)之中。
我们需要使用 EhCache 的 CacheManager 来进行注入,所以必须也要声明一个 CacheManager bean。为了对其进行简化,Spring 提供了 EhCacheManagerFactoryBean 来生成 EhCache 的 CacheManager。方法 ehcache() 会创建并返回一个 EhCacheManagerFactoryBean 实例。因为它是一个工厂 bean(也就是说,它实现了 Spring 的 FactoryBean 接口),所以注册在 Spring 应用上下文中的并不是 EhCacheManagerFactoryBean 的实例,而是 CacheManager 的一个实例,因此适合注入到 EhCacheCacheManager 之中。
除了在 Spring 中配置的 bean,还需要有针对 EhCache 的配置。EhCache 为 XML 定义了自己的配置模式,我们需要在一个 XML 文件中配置缓存,该文件需要符合 EhCache 所定义的模式。在创建 EhCacheManagerFactoryBean 的过程中,需要告诉它 EhCache 配置文件在什么地方。在这里通过调用 setConfigLocation()方法,传入 ClassPathResource,用来指明 EhCache XML 配置文件相对于根类路径(classpath)的位置。
至于 ehcache.xml 文件的内容,不同的应用之间会有所差别,但是至少需要声明一个最小的缓存。例如,如下的 EhCache 配置声明一个名为 spittleCache 的缓存,它最大的堆存储为 50 MB,存活时间为 100 秒。
1 | <ehcache> <cache name="spittleCache" maxBytesLocalHeap="50m" timeToLiveSeconds="100"> </cache></ehcache> |
显然,这是一个基础的 EhCache 配置。在你的应用之中,可能需要使用 EhCache 所提供的丰富的配置选项。参考 EhCache 的文档以了解调优 EhCache 配置的细节,地址是 http://ehcache.org/documentation/configuration。
使用 Redis 缓存
如果你仔细想一下的话,缓存的条目不过是一个键值对(key-valuepair),其中 key 描述了产生 value 的操作和参数。因此,很自然地就会想到,Redis 作为 key-value 存储,非常适合于存储缓存。
Redis 可以用来为 Spring 缓存抽象机制存储缓存条目,Spring Data Redis 提供了 RedisCacheManager,这是 CacheManager 的一个实现。 RedisCacheManager 会与一个 Redis 服务器协作,并通过 RedisTemplate 将缓存条目存储到 Redis 中。
为了使用 RedisCacheManager,我们需要 RedisTemplate bean 以及 RedisConnectionFactory 实现类(如 JedisConnectionFactory)的一个 bean。在第 12 章中,我们已经看到了这些 bean 该如何配置。在 RedisTemplate 就绪之后,配置 RedisCacheManager 就是非常简单的事情了,如程序清单 13.4 所示。
1 | package spittr.config;import net.sf.ehcache.CacheManager;import org.springframework.cache.annotation.EnableCaching;import org.springframework.context.annotation.Bean;import org.springframework.data.redis.cache.RedisCacheManager;import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.context.annotation.Configuration; class CachingConfig { public CacheManager cacheManager(RedisTemplate redisTemplate) { return new RedisCacheManager(redisTemplate); } public JedisConnectionFactory redisConnectionFactory() { JedisConnectionFactory jedisConnectionFactory = new JedisConnectionFactory(); jedisConnectionFactory.afterPropertiesSet(); return jedisConnectionFactory; } public RedisTemplate<String, String> redisTemplate( RedisConnectionFactory redisCF) { RedisTemplate<String, String> redisTemplate = new RedisTemplate<String, String>(); redisTemplate.setConnectionFactory(redisCf); redisTemplate.afterPropertiesSet(); return redisTemplate; } } |
可以看到,我们构建了一个 RedisCacheManager,这是通过传递一个 RedisTemplate 实例作为其构造器的参数实现的。
使用多个缓存管理器
我们并不是只能有且仅有一个缓存管理器。如果你很难确定该使用哪个缓存管理器,或者有合法的技术理由使用超过一个缓存管理器的话,那么可以尝试使用 Spring 的 CompositeCacheManager。
CompositeCacheManager 要通过一个或更多的缓存管理器来进行配置,它会迭代这些缓存管理器,以查找之前所缓存的值。以下的程序清单展现了如何创建 CompositeCacheManager bean,它会迭代 JCacheCacheManager、EhCacheCacheManager 和 RedisCacheManager。
1 | CacheManager ehcacheManager( net.sf.ehcache.CacheManager cm, javax.cache.CacheManager jcm) { CompositeCacheManager cacheManager = new CompositeCacheManager(); List<CacheManager> managers = new ArrayList<CacheManager>(); managers.add(new JCacheCacheManager(jcm)); managers.add(new EhcacheCacheManager(cm)); managers.add(new RedisCacheManager(redisTemplate())); cacheManager,setCacheManagers(managers); return cacheManager;} |
当查找缓存条目时,CompositeCacheManager 首先会从 JCacheCacheManager 开始检查 JCache 实现,然后通过 EhCacheCacheManager 检查 Ehcache,最后会使用 RedisCacheManager 来检查 Redis,完成缓存条目的查找。
在配置完缓存管理器并启用缓存后,就可以在 bean 方法上应用缓存规则了。让我们看一下如何使用 Spring 的缓存注解来定义缓存边界。
为方法添加注解以支持缓存
如前文所述,Spring 的缓存抽象在很大程度上是围绕切面构建的。在 Spring 中启用缓存时,会创建一个切面,它触发一个或更多的 Spring 的缓存注解。表 13.1 列出了 Spring 所提供的缓存注解。
表 13.1 中的所有注解都能运用在方法或类上。当将其放在单个方法上时,注解所描述的缓存行为只会运用到这个方法上。如果注解放在类级别的话,那么缓存行为就会应用到这个类的所有方法上。
| 注 解 | 描 述 |
|---|---|
| @Cacheable | 表明 Spring 在调用方法之前,首先应该在缓存中查找方法的返回值。如果这个值能够找到,就会返回缓存的值。否则的话,这个方法就会被调用,返回值会放到缓存之中 |
| @CachePut | 表明 Spring 应该将方法的返回值放到缓存中。在方法的调用前并不会检查缓存,方法始终都会被调用 |
| @CacheEvict | @CacheEvict 表明 Spring 应该在缓存中清除一个或多个条目 |
| @Caching | 这是一个分组的注解,能够同时应用多个其他的缓存注解 |
填充缓存
我们可以看到,@Cacheable 和 @CachePut 注解都可以填充缓存,但是它们的工作方式略有差异。
@Cacheable 首先在缓存中查找条目,如果找到了匹配的条目,那么就不会对方法进行调用了。如果没有找到匹配的条目,方法会被调用并且返回值要放到缓存之中。而 @CachePut 并不会在缓存中检查匹配的值,目标方法总是会被调用,并将返回值添加到缓存之中。
@Cacheable 和 @CachePut 有一些属性是共有的,参见表 13.2。
| 属 性 | 类 型 | 描 述 |
|---|---|---|
| value | String[] | 要使用的缓存名称 |
| condition | String | SpEL 表达式,如果得到的值是 false 的话,不会将缓存应用到方法调用上 |
| key | String | SpEL 表达式,用来计算自定义的缓存 key |
| unless | String | SpEL 表达式,如果得到的值是 true 的话,返回值不会放到缓存之中 |
在最简单的情况下,在 @Cacheable 和 @CachePut 的这些属性中,只需使用 value 属性指定一个或多个缓存即可。例如,考虑 SpittleRepository 的 findOne() 方法。在初始保存之后,Spittle 就不会再发生变化了。如果有的 Spittle 比较热门并且会被频繁请求,反复地在数据库中进行获取是对时间和资源的浪费。通过在 findOne() 方法上添加 @Cacheable 注解,如下面的程序清单所示,能够确保将 Spittle 保存在缓存中,从而避免对数据库的不必要访问。
1 | public Spittle findOne(long id) { try { return jdbcTemplate.queryForObject( SELECT_SPITTLE_BY_ID, new SpittleRowMapper(), id); } catch (EmptyResultDataAccessException e) { return null; }} |
当 findOne() 被调用时,缓存切面会拦截调用并在缓存中查找之前以名 spittleCache 存储的返回值。缓存的 key 是传递到 findOne() 方法中的 id 参数。如果按照这个 key 能够找到值的话,就会返回找到的值,方法不会再被调用。如果没有找到值的话,那么就会调用这个方法,并将返回值放到缓存之中,为下一次调用 findOne() 方法做好准备。
在程序清单 13.6 中,@Cacheable 注解被放到了 JdbcSpittleRepository 的 findOne() 方法实现上。这样能够起作用,但是缓存的作用只限于 JdbcSpittleRepository 这个实现类中,SpittleRepository 的其他实现并没有缓存功能,除非也为其添加上 @Cacheable 注解。因此,可以考虑将注解添加到 SpittleRepository 的方法声明上,而不是放在实现类中:
1 | Spittle findOne(long id); |
当为接口方法添加注解后,@Cacheable 注解会被 SpittleRepository 的所有实现继承,这些实现类都会应用相同的缓存规则。
将值放到缓存之中
@Cacheable 会条件性地触发对方法的调用,这取决于缓存中是不是已经有了所需要的值,对于所注解的方法,@CachePut 采用了一种更为直接的流程。带有 @CachePut 注解的方法始终都会被调用,而且它的返回值也会放到缓存中。这提供一种很便利的机制,能够让我们在请求之前预先加载缓存。
例如,当一个全新的 Spittle 通过 SpittleRepository 的 save() 方法保存之后,很可能马上就会请求这条记录。所以,当 save() 方法调用后,立即将 Spittle 塞到缓存之中是很有意义的,这样当其他人通过 findOne() 对其进行查找时,它就已经准备就绪了。为了实现这一点,可以在 save() 方法上添加 @CachePut 注解,如下所示:
1 | ;Spittle save(Spittle spittle); |
当 save() 方法被调用时,它首先会做所有必要的事情来保存 Spittle,然后返回的 Spittle 会被放到 spittleCache 缓存中。
在这里只有一个问题:缓存的 key。如前文所述,默认的缓存 key 要基于方法的参数来确定。因为 save() 方法的唯一参数就是 Spittle,所以它会用作缓存的 key。将 Spittle 放在缓存中,而它的缓存 key 恰好是同一个 Spittle,这是不是有一点诡异呢?
显然,在这个场景中,默认的缓存 key 并不是我们想要的。我们需要的缓存 key 是新保存 Spittle 的 ID,而不是 Spittle 本身。所以,在这里需要指定一个 key 而不是使用默认的 key。让我们看一下怎样自定义缓存 key。
自定义缓存 key
@Cacheable 和 @CachePut 都有一个名为 key 属性,这个属性能够替换默认的 key,它是通过一个 SpEL 表达式计算得到的。任意的 SpEL 表达式都是可行的,但是更常见的场景是所定义的表达式与存储在缓存中的值有关,据此计算得到 key。
具体到我们这个场景,我们需要将 key 设置为所保存 Spittle 的 ID。以参数形式传递给 save() 的 Spittle 还没有保存,因此并没有 ID。我们只能通过 save() 返回的 Spittle 得到 id 属性。
幸好,在为缓存编写 SpEL 表达式的时候,Spring 暴露了一些很有用的元数据。表 13.3 列出了 SpEL 中可用的缓存元数据。
| 表 达 式 | 描 述 |
|---|---|
| #root.args | 传递给缓存方法的参数,形式为数组 |
| #root.caches | 该方法执行时所对应的缓存,形式为数组 |
| #root.target | 目标对象 |
| #root.targetClass | 目标对象的类,是 #root.target.class 的简写形式 |
| #root.method | 缓存方法 |
| #root.methodName | 缓存方法的名字,是 #root.method.name 的简写形式 |
| #result | 方法调用的返回值(不能用在 @Cacheable 注解上) |
| #Argument | 任意的方法参数名(如 #argName)或参数索引(如 #a0 或 #p0) |
对于 save() 方法来说,我们需要的键是所返回 Spittle 对象的 id 属性。表达式 #result 能够得到返回的 Spittle。借助这个对象,我们可以通过将 key 属性设置为 #result.id 来引用 id 属性:
1 | Spittle save(Spittle spittle) |
按照这种方式配置 @CachePut,缓存不会去干涉 save() 方法的执行,但是返回的 Spittle 将会保存在缓存中,并且缓存的 key 与 Spittle 的 id 属性相同。
条件化缓存
通过为方法添加 Spring 的缓存注解,Spring 就会围绕着这个方法创建一个缓存切面。但是,在有些场景下我们可能希望将缓存功能关闭。
@Cacheable 和 @CachePut 提供了两个属性用以实现条件化缓存:unless 和 condition,这两个属性都接受一个 SpEL 表达式。如果 unless 属性的 SpEL 表达式计算结果为 true,那么缓存方法返回的数据就不会放到缓存中。与之类似,如果 condition 属性的 SpEL 表达式计算结果为 false,那么对于这个方法缓存就会被禁用掉。
表面上来看,unless 和 condition 属性做的是相同的事情。但是,这里有一点细微的差别。unless 属性只能阻止将对象放进缓存,但是在这个方法调用的时候,依然会去缓存中进行查找,如果找到了匹配的值,就会返回找到的值。与之不同,如果 condition 的表达式计算结果为 false,那么在这个方法调用的过程中,缓存是被禁用的。就是说,不会去缓存进行查找,同时返回值也不会放进缓存中。
作为样例(尽管有些牵强),假设对于 message 属性包含 “NoCache” 的 Spittle 对象,我们不想对其进行缓存。为了阻止这样的 Spittle 对象被缓存起来,可以这样设置 unless 属性:
1 | Spittle findOne(long id); |
为 unless 设置的 SpEL 表达式会检查返回的 Spittle 对象(在表达式中通过 #result 来识别)的 message 属性。如果它包含 “NoCache” 文本内容,那么这个表达式的计算值为 true,这个 Spittle 对象不会放进缓存中。否则的话,表达式的计算结果为 false,无法满足 unless 的条件,这个 Spittle 对象会被缓存。
属性 unless 能够阻止将值写入到缓存中,但是有时候我们希望将缓存全部禁用。也就是说,在一定的条件下,我们既不希望将值添加到缓存中,也不希望从缓存中获取数据。
例如,对于 ID 值小于 10 的 Spittle 对象,我们不希望对其使用缓存。在这种场景下,这些 Spittle 是用来进行调试的测试条目,对其进行缓存并没有实际的价值。为了要对 ID 小于 10 的 Spittle 关闭缓存,可以在 @Cacheable 上使用 condition 属性,如下所示:
1 | Spittle findOne(long id); |
如果 findOne() 调用时,参数值小于 10,那么将不会在缓存中进行查找,返回的 Spittle 也不会放进缓存中,就像这个方法没有添加 @Cacheable 注解一样。
如样例所示,unless 属性的表达式能够通过 #result 引用返回值。这是很有用的,这么做之所以可行是因为 unless 属性只有在缓存方法有返回值时才开始发挥作用。而 condition 肩负着在方法上禁用缓存的任务,因此它不能等到方法返回时再确定是否该关闭缓存。这意味着它的表达式必须要在进入方法时进行计算,所以我们不能通过 #result 引用返回值。
我们现在已经在缓存中添加了内容,但是这些内容能被移除掉吗?接下来看一下如何借助 @CacheEvict 将缓存数据移除掉。
移除缓存条目
@CacheEvict 并不会往缓存中添加任何东西。相反,如果带有 @CacheEvict 注解的方法被调用的话,那么会有一个或更多的条目会在缓存中移除。
那么在什么场景下需要从缓存中移除内容呢?当缓存值不再合法时,我们应该确保将其从缓存中移除,这样的话,后续的缓存命中就不会返回旧的或者已经不存在的值,其中一个这样的场景就是数据被删除掉了。这样的话,SpittleRepository 的 remove() 方法就是使用 @CacheEvict 的绝佳选择:
1 | void remove(long spittlId) |
注意:与 @Cacheable 和 @CachePut 不同,@CacheEvict 能够应用在返回值为 void 的方法上,而 @Cacheable 和 @CachePut 需要非 void 的返回值,它将会作为放在缓存中的条目。因为 @CacheEvict 只是将条目从缓存中移除,因此它可以放在任意的方法上,甚至 void 方法。
从这里可以看到,当 remove() 调用时,会从缓存中删除一个条目。被删除条目的 key 与传递进来的 spittleId 参数的值相等。
@CacheEvict 有多个属性,如表 13.4 所示,这些属性会影响到该注解的行为,使其不同于默认的做法。
可以看到,@CacheEvict 的一些属性与 @Cacheable 和 @CachePut 是相同的,另外还有几个新的属性。与 @Cacheable 和 @CachePut 不同,@CacheEvict 并没有提供 unless 属性。
Spring 的缓存注解提供了一种优雅的方式在应用程序的代码中声明缓存规则。但是,Spring 还为缓存提供了 XML 命名空间。在结束对缓存的讨论之前,我们快速地看一下如何以 XML 的形式配置缓存规则。
| 属 性 | 类 型 | 描 述 |
|---|---|---|
| value | String[] | 要使用的缓存名称 |
| key | String | SpEL 表达式,用来计算自定义的缓存 key |
| condition | String | SpEL 表达式,如果得到的值是 false 的话,缓存不会应用到方法调用上 |
| allEntries | boolean | 如果为 true 的话,特定缓存的所有条目都会被移除掉 |
| beforeInvocation | boolean | 如果为 true 的话,在方法调用之前移除条目。如果为 false(默认值)的话,在方法成功调用之后再移除条目 |
使用 XML 声明缓存
你可能想要知道为什么想要以 XML 的方式声明缓存。毕竟,本章中我们所看到的缓存注解要优雅得多。
我认为有两个原因:
- 你可能会觉得在自己的源码中添加 Spring 的注解有点不太舒服;
- 你需要在没有源码的 bean 上应用缓存功能。
在上面的任意一种情况下,最好(或者说需要)将缓存配置与缓存数据的代码分隔开来。Spring 的 cache 命名空间提供了使用 XML 声明缓存规则的方法,可以作为面向注解缓存的替代方案。因为缓存是一种面向切面的行为,所以 cache 命名空间会与 Spring 的 aop 命名空间结合起来使用,用来声明缓存所应用的切点在哪里。
要开始配置 XML 声明的缓存,首先需要创建 Spring 配置文件,这个文件中要包含 cache 和 aop 命名空间:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:cache="http://www.springframework.org/schema/cache" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation=" http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/cache http://www.springframework.org/schema/cache/spring-cache.xsd" > <!-- Caching configuration go here /></beans> |
cache 命名空间定义了在 Spring XML 配置文件中声明缓存的配置元素。表 13.5 列出了 cache 命名空间所提供的所有元素。
| 元素 | 描述 |
|---|---|
<cache:annotationdriven> |
启用注解驱动的缓存。等同于 Java 配置中的 @EnableCaching |
<cache:advice> |
定义缓存通知(advice)。结合 <aop:advisor>,将通知应用到切点上 |
<cache:caching> |
在缓存通知中,定义一组特定的缓存规则 |
<cache:cacheable> |
指明某个方法要进行缓存。等同于 @Cacheable 注解 |
<cache:cache-put> |
指明某个方法要填充缓存,但不会考虑缓存中是否已有匹配的值。等同于 @CachePut 注解 |
<cache:cacheevict> |
指明某个方法要从缓存中移除一个或多个条目,等同于 @CacheEvict 注解 |
<cache:annotation-driven> 元素与 Java 配置中所对应的 @EnableCaching 非常类似,会启用注解驱动的缓存。我们已经讨论过这种风格的缓存,因此没有必要再对其进行介绍。
表 13.5 中其他的元素都用于基于 XML 的缓存配置。接下来的代码清单展现了如何使用这些元素为 SpittleRepositorybean 配置缓存,其作用等同于本章前面章使用缓存注解的方式。
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:cache="http://www.springframework.org/schema/cache" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation=" http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/cache http://www.springframework.org/schema/cache/spring-cache.xsd" > <aop:config> <aop:advice advice-ref="cacheAdvice" pointcut="execution(* com.habuma.spittr.db.SpittleRepository.*(..))" /> </aop:config> <cache:advice id="cacheAdvice"> <cache:caching> <cache:cacheable cache="spittleCache" method="findRecent" /> <cache:cacheable cache="spittleCache" method="findBySpitterId" /> <cache:cacheable cache="spittleCache" method="findOne" /> <cache:cache-put cache="spittleCache" method="save" key="#result.id" /> <cache:cache-evict cache="spittleCache" method="remove" /> </cache:caching> </cache:advice> <bean id="cacheManage" class="org.springframework.cache.concurrent.ConcurrentMapCacheManager" /></beans> |
在程序清单 13.7 中,我们首先看到的是 <aop:advisor>,它引用 ID 为 cacheAdvice 的通知,该元素将这个通知与一个切点进行匹配,因此建立了一个完整的切面。在本例中,这个切面的切点会在执行 SpittleRepository 的任意方法时触发。如果这样的方法被 Spring 应用上下文中的任意某个 bean 所调用,那么就会调用切面的通知。
在这里,通知利用 <cache:advice> 元素进行了声明。在 <cache:advice> 元素中,可以包含任意数量的 <cache:caching> 元素,这些元素用来完整地定义应用的缓存规则。在本例中,只包含了一个 <cache:caching> 元素。这个元素又包含了三个 <cache:cacheable> 元素和一个 <cache:cacheput> 元素。
每个 <cache:cacheable> 元素都声明了切点中的某一个方法是支持缓存的。这是与 @Cacheable 注解同等作用的 XML 元素。具体来讲,findRecent()、findOne() 和 findBySpitterId() 都声明为支持缓存,它们的返回值将会保存在名为 spittleCache 的缓存之中。
<cache:cache-put> 是 Spring XML 中与 @CachePut 注解同等作用的元素。它表明一个方法的返回值要填充到缓存之中,但是这个方法本身并不会从缓存中获取返回值。在本例中,save() 方法用来填充缓存。同面向注解的缓存一样,我们需要将默认的 key 改为返回 Spittle 对象的 id 属性。
最后,<cache:cache-evict> 元素是 Spring XML 中用来替代 @CacheEvict 注解的。它会从缓存中移除元素,这样的话,下次有人进行查找的时候就找不到了。在这里,调用 remove() 时,会将缓存中的 Spittle 删除掉,其中 key 与 remove() 方法所传递进来的 ID 参数相等的条目会从缓存中移除。
需要注意的是,<cache:advice> 元素有一个 cache-manager 元素,用来指定作为缓存管理器的 bean。它的默认值是 cacheManager,这与程序清单 13.7 底部的 <bean> 声明恰好是一致的,所以没有必要再显式地进行设置。但是,如果缓存管理器的 ID 与之不同的话(使用多个缓存管理器的时候,可能会遇到这样的场
景),那么可以通过设置 cache-manager 属性指定要使用哪个缓存管理器。
另外,还要留意的是,<cache:cacheable>、<cache:cacheput> 和 <cache:cache-evict> 元素都引用了同一个名为 spittleCache 的缓存。为了消除这种重复,我们可以在 <cache:caching> 元素上指明缓存的名字:
1 | <cache:advice id="cacheAdvice"> <cache:caching cache="spittleCache"> <cache:cacheable method="findRecent" /> <cache:cacheable method="findBySpitterId" /> <cache:cacheable method="findOne" /> <cache:cache-put method="save" key="#result.id" /> <cache:cache-evict method="remove" /> </cache:caching></cache:advice> |
<cache:caching> 有几个可以供 <cache:cacheable>、<cache:cache-put> 和 <cache:cache-evict> 共享的属性,包括:
cache:指明要存储和获取值的缓存;
condition:SpEL表达式,如果计算得到的值为false,将会为这个方法禁用缓存;
key:SpEL表达式,用来得到缓存的key(默认为方法的参数);
method:要缓存的方法名。
除此之外,<cache:cacheable> 和 <cache:cache-put> 还有一个 unless 属性,可以为这个可选的属性指定一个 SpEL 表达式,如果这个表达式的计算结果为true,那么将会阻止将返回值放到缓存之中。
<cache:cache-evict>元素还有几个特有的属性:
all-entries:如果是 true 的话,缓存中所有的条目都会被移除掉。如果是 false 的话,只有匹配 key 的条目才会被移除掉。
before-invocation:如果是 true 的话,缓存条目将会在方法调用之前被移除掉。如果是 false 的话,方法调用之后才会移除缓存。
all-entries 和 before-invocation 的默认值都是 false。这意味着在使用 <cache:cache-evict> 元素且不配置这两个属性时,会在方法调用完成后只删除一个缓存条目。要删除的条目会通过默认的 key(基于方法的参数)进行识别,当然也可以通过为名为 key 的属性设置一个 SpEL 表达式指定要删除的 key。
小结
如果想让应用程序避免一遍遍地为同一个问题推导、计算或查询答案的话,缓存是一种很棒的方式。当以一组参数第一次调用某个方法时,返回值会被保存在缓存中,如果这个方法再次以相同的参数进行调用时,这个返回值会从缓存中查询获取。在很多场景中,从缓存查找值会比其他的方式(比如,执行数据库查询)成本更低。因此,缓存会对应用程序的性能带来正面的影响。
在本章中,我们看到了如何在Spring应用中声明缓存。首先,看到的是如何声明一个或更多的 Spring 缓存管理器。然后,将缓存用到了 Spittr 应用程序中,这是通过将 @Cacheable、@CachePut 和 @CacheEvic t添加到 SpittleRepository 上实现的。
我们还看到了如何借助 XML 将缓存规则的配置与应用程序代码分离开来。<cache:cacheable>、<cache:cache-put> 和 <cache:cache-evict> 元素的作用与本章前面所使用的注解是一致的。
在这个过程中,我们讨论了缓存实际上是一种面向切面的行为。Spring 将缓存实现为一个切面。在使用 XML 声明缓存规则时,这一点非常明显:我们必须要将缓存通知绑定到一个切点上。
Spring 在将安全功能应用到方法上时,同样使用了切面。在下一章中,我们将会看到如何借助 Spring Security 确保 bean 方法的安全性。
保护方法应用
本章内容:
- 保护方法调用
- 使用表达式定义安全规则
- 创建安全表达式计算器
在离家或上床睡觉之前,我做的最后一件事就是确保房间的门已经关好。但是在此之前,我会设置好警报。为什么呢?这是因为,尽管门锁是保证安全的一个好办法,但是警报系统提供了第二层防护,窃贼有可能会越过门锁的保护。
在第 9 章中,我们看到了如何使用 Spring Security 保护应用的 Web 层。Web 安全是非常重要的,它能阻止用户访问没有权限的内容。但是,如果应用的 Web 层出现安全漏洞会怎样呢?如果用户能够请求他们不允许访问的内容会怎样呢?
尽管我们没有理由认为用户能够攻破应用的安全层,但是在 Web 层出现安全漏洞实在是太容易了。例如,假设用户请求了一个允许访问的页面,但是由于开发人员不认真,处理这个请求的控制器方法返回了该用户不允许看到的数据。这是一个无心之失,不过,安全问题很可能就是无心之失所造成的,因为他们是非常聪明的攻击者。
我们可以同时保护应用的 Web 层以及场景后面的方法,这样就能保证如果用户不具备权限的话,就无法执行相应的逻辑。
在本章中,我们将会看到如何使用 Spring Security 保护 bean 方法。通过这种方式,就能声明安全规则,保证如果用户没有执行方法的权限,就不会执行相应的方法。首先,我们会看一些可以放在方法上的简单注解,它们能够将方法锁定,阻止无权限用户的访问。
使用注解保护方法
在 Spring Security 中实现方法级安全性的最常见办法是使用特定的注解,将这些注解应用到需要保护的方法上。这样有几个好处,最重要的是当我们在编辑器中查看给定的方法时,能够很清楚地看到它的安全规则。
Spring Security 提供了三种不同的安全注解:
- Spring Security 自带的 @Secured 注解;
- JSR-250 的 @RolesAllowed 注解;
- 表达式驱动的注解,包括 @PreAuthorize、@PostAuthorize、@PreFilter 和 @PostFilter。
@Secured 和 @RolesAllowed 方案非常类似,能够基于用户所授予的权限限制对方法的访问。当我们需要在方法上定义更灵活的安全规则时,Spring Security 提供了 @PreAuthorize 和 @PostAuthorize,而 @PreFilter/@PostFilter 能够过滤方法返回的以及传入方法的集合。
在本章中,你将会看到如何使用这些注解。作为开始,我们首先看一下 @Secured 注解,这是 Spring Security 所提供的方法级安全注解里面最简单的一个。
使用 @Secured 注解限制方法调用
在 Spring 中,如果要启用基于注解的方法安全性,关键之处在于要在配置类上使用 @EnableGlobalMethodSecurity,如下所示:
1 | public class MethodSecurityConfig extends GlobalMethodSecurityConfiguration {} |
除了使用 @EnableGlobalMethodSecurity 注解,我们可能也注意到配置类扩展了 GlobalMethodSecurityConfiguration。在第 9 章中,Web 安全的配置类扩展了 WebSecurityConfigurerAdapter,与之类似,这个类能够为方法级别的安全性提供更精细的配置。
例如,如果我们在 Web 层的安全配置中设置认证,那么可以通过重载 GlobalMethodSecurityConfiguration 的 configure() 方法实现该功能:
1 | void configure(AuthenticationManagerBuilder auth) throws Exception { auth.inMemoryAuthentication() .withUser("user").password("password").role("USER");} |
在本章稍后的14.2.2小节中,我们将会看到如何重载 GlobalMethodSecurityConfiguration 的 createExpressionHandler() 方法,提供一些自定义的安全表达式处理行为。
让我们回到 @EnableGlobalMethodSecurity 注解,注意它的 securedEnabled 属性设置成了 true。如果 securedEnabled 属性的值为 true 的话,将会创建一个切点,这样的话 Spring Security 切面就会包装带有 @Secured 注解的方法。例如,考虑如下这个带有 @Secured 注解的 addSpittle() 方法:
1 | public void addSpittle(Spittle spittle) { // ...} |
@Secured 注解会使用一个 String 数组作为参数。每个 String 值是一个权限,调用这个方法至少需要具备其中的一个权限。通过传递进来 ROLE_SPITTER,我们告诉 Spring Security 只允许具有 ROLE_SPITTER 权限的认证用户才能调用 addSpittle() 方法。
如果传递给 @Secured 多个权限值,认证用户必须至少具备其中的一个才能进行方法的调用。例如,下面使用 @Secured 的方式表明用户必须具备 ROLE_SPITTER 或 ROLE_ADMIN 权限才能触发这个方法:
1 | public void addSpittle(Spittle spittle) { // ...} |
如果方法被没有认证的用户或没有所需权限的用户调用,保护这个方法的切面将抛出一个 Spring Security 异常(可能是 AuthenticationException 或 AccessDeniedException 的子类)。它们是非检查型异常,但这个异常最终必须要被捕获和处理。如果被保护的方法是在 Web 请求中调用的,这个异常会被Spring Security 的过滤器自动处理。否则的话,你需要编写代码来处理这个异常。
@Secured 注解的不足之处在于它是 Spring 特定的注解。如果更倾向于使用 Java 标准定义的注解,那么你应该考虑使用 @RolesAllowed 注解。
在 Spring Security 中使用 JSR-250 的 @RolesAllowed 注解
@RolesAllowed 注解和 @Secured 注解在各个方面基本上都是一致的。唯一显著的区别在于 @RolesAllowed 是 JSR-250 定义的 Java 标准注解。
差异更多在于政治考量而非技术因素。但是,当使用其他框架或 API 来处理注解的话,使用标准的 @RolesAllowed 注解会更有意义。
如果选择使用 @RolesAllowed 的话,需要将 @EnableGlobalMethodSecurity 的 jsr250Enabled 属性设置为 true,以开启此功能:
1 | public class MethodSecurityConfig extends GlobalMethodSecurityConfiguration {} |
尽管我们这里只是启用了 jsr250Enabled,但需要说明的一点是这与 securedEnabled 并不冲突。这两种注解风格可以同时启用。
在将 jsr250Enabled 设置为 true 之后,将会启用一个切点,这样带有 @RolesAllowed 注解的方法都会被 Spring Security 的切面包装起来。因此,在方法上使用 @RolesAllowed 的方式与使用 @Secured 类似。例如,如下的 addSpittle() 方法使用了 @RolesAllowed 注解来代替 @Secured:
1 | public void addSpittle(Spittle spittle) { // ...} |
尽管 @RolesAllowed 比 @Secured 在政治上稍微有点优势,它是实现方法安全的标准注解,但是这两个注解有一个共同的不足。它们只能根据用户有没有授予特定的权限来限制方法的调用。在判断方式是否执行方面,无法使用其他的因素。我们在第 9 章曾经看到过,在保护 URL 方面,能够使用 SpEL 表达式克服这一限制。接下来,我们看一下如何组合使用 SpEL 与 Spring Security 所提供的方法调用前后注解,实现基于表达式的方法安全性。
使用表达式实现方法级别的安全性
尽管 @Secured 和 @RolesAllowed 注解在拒绝未认证用户方面表现不错,但这也是它们所能做到的所有事情了。有时候,安全性约束不仅仅涉及用户是否有权限。
Spring Security 3.0 引入了几个新注解,它们使用 SpEL 能够在方法调用上实现更有意思的安全性约束。这些新的注解在表 14.1 中进行了描述。
这些注解的值参数中都可以接受一个 SpEL 表达式。表达式可以是任意合法的 SpEL 表达式,可能会包含表 9.5 所列的 Spring Security 对 SpEL 的扩展。如果表达式的计算结果为 true,那么安全规则通过,否则就会失败。安全规则通过或失败的结果会因为所使用注解的差异而有所不同。
| 注 解 | 描 述 |
|---|---|
| @PreAuthorize | 在方法调用之前,基于表达式的计算结果来限制对方法的访问 |
| @PostAuthorize | 允许方法调用,但是如果表达式计算结果为 false,将抛出一个安全性异常 |
| @PostFilter | 允许方法调用,但必须按照表达式来过滤方法的结果 |
| @PreFilter | 允许方法调用,但必须在进入方法之前过滤输入值 |
稍后,我们将会看到每个注解的例子。但首先,我们需要将 @EnableGlobalMethodSecurity 注解的 prePostEnabled 属性设置为 true,从而启用它们:
1 | class MethodSecurityConfig extends GlobalMethodSecurityConfiguration {} |
现在,方法调用前后的注解都已经启用了,我们可以使用它们了。我们首先看一下如何使用 @PreAuthorize 和 @PostAuthorize 注解限制对方法的调用。
表述方法访问规则
到目前为止,我们已经看到 @Secured 和 @RolesAllowed 能够限制只有用户具备所需的权限才能触发方法的执行。但是,这两个注解的不足在于它们只能基于用户授予的权限来做出决策。
Spring Security 还提供了两个注解,@PreAuthorize 和 @PostAuthorize,它们能够基于表达式的计算结果来限制方法的访问。在定义安全限制方面,表达式带了极大的灵活性。通过使用表达式,只要我们能够想象得到,就可以定义任意允许访问或不允许访问方法的条件。
@PreAuthorize 和 @PostAuthorize之间的关键区别在于表达式执行的时机。@PreAuthorize 的表达式会在方法调用之前执行,如果表达式的计算结果不为 true 的话,将会阻止方法执行。与之相反,@PostAuthorize 的表达式直到方法返回才会执行,然后决定是否抛出安全性的异常。
在方法调用前验证权限
@PreAuthorize 乍看起来可能只是添加了 SpEL 支持的 @Secured 和 @RolesAllowed。实际上,你可以基于用户所授予的角色,使用 @PreAuthorize 来限制访问:
1 | public void addSpittle(Spittle spittle) { // ...} |
如果按照这种方式的话,@PreAuthorize 相对于 @Secured 和 @RolesAllowed 并没有什么优势。如果用户具有 ROLE_SPITTER 角色的话,允许方法调用。否则,将会抛出安全性异常,方法也不会执行。
但是,@PreAuthorize 的功能并不限于这个简单例子所展现的。@PreAuthorize 的 String类型参数是一个 SpEL 表达式。借助于 SpEL 表达式来实现访问决策,我们能够编写出更高级的安全性约束。例如,Spittr 应用程序的一般用户只能写 140 个字以内的Spittle,而付费用户不限制字数。
虽然 @Secured 和 @RolesAllowed 在这里无能为力,但是 @PreAuthorize 注解恰好能够适用于这种场景:
1 | public void addSpittle(Spittle spittle) { // ...} |
表达式中的 #spittle 部分直接引用了方法中的同名参数。这使得 Spring Security 能够检查传入方法的参数,并将这些参数用于认证决策的制定。在这里,我们深入到 Spitter 的文本内容中,保证不超过 Spittr 标准用户的长度限制。如果是付费用户,那么就没有长度限制了。
在方法调用之后验证权限
在方法调用之后验证权限并不是比较常见的方式。事后验证一般需要基于安全保护方法的返回值来进行安全性决策。这种情况意味着方法必须被调用执行并且得到了返回值。
例如,假设我们想对 getSpittleById() 方法进行保护,确保返回的 Spittle 对象属于当前的认证用户。我们只有得到 Spittle 对象之后,才能判断它是否属于当前用户。因此,getSpittleById() 方法必须要先执行。在得到 Spittle 之后,如果它不属于当前用户的话,将会抛出安全性异常。
除了验证的时机之外,@PostAuthorize 与 @PreAuthorize 的工作方式差不多,只不过它会在方法执行之后,才会应用安全规则。此时,它才有机会在做出安全决策时,考虑到返回值的因素。例如,要保护上面描述的 getSpittleById() 方法,我们可以按照如下的方式使用 @PostAuthorize 注解:
1 | public Spittle getSpittleById(long id) { // ...} |
为了便利地访问受保护方法的返回对象,Spring Security 在 SpEL 中提供了名为 returnObject 的变量。在这里,我们知道返回对象是一个 Spittle 对象,所以这个表达式可以直接访问其 spittle 属性中的 username 属性。
在对比表达式双等号的另一侧,表达式到内置的 principal 对象中取出其 username 属性。principal 是另一个 Spring Security 内置的特殊名称,它代表了当前认证用户的主要信息(通常是用户名)。
在 Spittle 对象所包含 Spitter 中,如果 username 属性与 principal 的 username 属性相同,这个 Spittle 将返回给调用者。否则,会抛出一个 AccessDeniedException 异常,而调用者也不会得到 Spittle 对象。
有一点需要注意,不像 @PreAuthorize 注解所标注的方法那样,@PostAuthorize 注解的方法会首先执行然后被拦截。这意味着,你需要小心以保证如果验证失败的话不会有一些负面的结果。
过滤方法的输入和输出
如果我们希望使用表达式来保护方法的话,那使用 @PreAuthorize 和 @PostAuthorize 是非常好的方案。但是,有时候限制方法调用太严格了。有时,需要保护的并不是对方法的调用,需要保护的是传入方法的数据和方法返回的数据。
例如,我们有一个名为 getOffensiveSpittles() 的方法,这个方法会返回标记为具有攻击性的 Spittle 列表。这个方法主要会给管理员使用,以保证 Spittr 应用中内容的和谐。但是,普通用户也可以使用这个方法,用来查看他们所发布的 Spittle 有没有被标记为具有攻击性。这个方法的签名大致如下所示;
1 | public List<Spittle> getOffensiveSpittles() { ... } |
按照这种方法的定义,getOffensiveSpittles() 方法与具体的用户并没有关联。它只会返回攻击性 Spittle 的一个列表,并不关心它们属于哪个用户。对于管理员使用来说,这是一个很好的方法,但是它无法限制列表中的 Spittle 都属于当前用户。
当然,我们也可以重载 getOffensiveSpittles(),实现另一个版本,让它接受一个用户 ID 作为参数,查询给定用户的 Spittle。但是,正如我在本章开头所讲的那样,始终会有这样的可能性,那就是将较为宽松限制的版本用在具有一定安全限制的场景中。
我们需要有一种方式过滤 getOffensiveSpittles() 方法返回的Spittle集合,将结果限制为允许当前用户看到的内容,而这就是 Spring Security 的 @PostFilter 所能做的事情。我们来试一下。
事后对方法的返回值进行过滤
与 @PreAuthorize 和 @PostAuthorize 类似,@PostFilter 也使用一个 SpEL 作为值参数。但是,这个表达式不是用来限制方法访问的,@PostFilter 会使用这个表达式计算该方法所返回集合的每个成员,将计算结果为 false 的成员移除掉。
为了阐述该功能,我们将 @PostFilter 应用在 getOffensiveSpittles() 方法上:
1 | public List<Spittle> getOffensiveSpittles() { ...} |
在这里,@PreAuthorize 限制只有具备 ROLE_SPITTER 或 ROLE_ADMIN 权限的用户才能访问该方法。如果用户能够通过这个检查点,那么方法将会执行,并且会返回 Spittle 所组成的一个 List。但是,@PostFilter 注解将会过滤这个列表,确保用户只能看到允许的 Spittle。具体来讲,管理员能够看到所有攻击性的 Spittle,非管理员只能看到属于自己的 Spittle。
表达式中的 filterObject 对象引用的是这个方法所返回List中的某一个元素(我们知道它是一个 Spittle)。在这个 Spittle 对象中,如果 Spitter 的用户名与认证用户(表达式中的 principal.name)相同或者用户具有 ROLE_ADMIN 角色,那这个元素将会最终包含在过滤后的列表中。否则,它将被过滤掉。
事先对方法的参数进行过滤
除了事后过滤方法的返回值,我们还可以预先过滤传入到方法中的值。这项技术不太常用,但是在有些场景下可能会很便利。
例如,假设我们希望以批处理的方式删除Spittle组成的列表。为了完成该功能,我们可能会编写一个方法,其签名大致如下所示:
1 | public void deleteSpittles(List<Spittle> spittles) { ... } |
看起来很简单,对吧?但是,如果我们想在它上面应用一些安全规则的话,比如 Spittle 只能由其所有者或管理员删除,那该怎么做呢?如果是这样的话,我们可以将逻辑放在 deleteSpittles() 方法中,在这里循环列表中的 Spittle,只删除属于当前用户的那一部分对象(如果当前用户是管理员的话,则会全部删除)。
这能够运行正常,但是这意味着我们需要将安全逻辑直接嵌入到方法之中。相对于删除 Spittle 来讲,安全逻辑是独立的关注点(当然,它们也有所关联)。如果列表中能够只包含实际要删除的 Spittle,这样会更好一些,因为这能帮助 deleteSpittles() 方法中的逻辑更加简单,只关注于删除 Spittle 的任务。
Spring Security 的 @PreFilter 注解能够很好地解决这个问题。与 @PostFilter 非常类似,@PreFilter 也使用 SpEL 来过滤集合,只有满足 SpEL 表达式的元素才会留在集合中。但是它所过滤的不是方法的返回值,@PreFilter 过滤的是要进入方法中的集合成员。
@PreFilter 的使用非常简单。如下的 deleteSpittles() 方法使用了 @PreFilter 注解:
1 | public void deleteSpittles(List<Spittle> spittles) { ... } |
与前面一样,对于没有 ROLE_SPITTER 或 ROLE_ADMIN 权限的用户,@PreAuthorize 注解会阻止对这个方法的调用。但同时,@PreFilter 注解能够保证传递给 deleteSpittles() 方法的列表中,只包含当前用户有权限删除的 Spittle。这个表达式会针对集合中的每个元素进行计算,只有表达式计算结果为 true 的元素才会保留在列表中。targetObject 是 Spring Security 提供的另外一个值,它代表了要进行计算的当前列表元素。
Spring Security 提供了注解驱动的功能,这是通过一系列注解来实现的,到此为止,我们已经对这些注解进行了介绍。相对于判断用户所授予的权限,使用表达式来定义安全限制是一种更为强大的方式。
即便如此,我们也不应该让表达式过于聪明智能。我们应该避免编写非常复杂的安全表达式,或者在表达式中嵌入太多与安全无关的业务逻辑。而且,表达式最终只是一个设置给注解的 String 值,因此它很难测试和调试。
如果你觉得自己的安全表达式难以控制了,那么就应该看一下如何编写自定义的许可计算器(permission evaluator),以简化你的 SpEL 表达式。下面我们看一下如何编写自定义的许可计算器,用它来简化之前用于过滤的表达式。
定义许可计算器
我们在 @PreFilter 和 @PostFilter 中所使用的表达式还算不上太复杂。但是,它也并不简单,我们可以很容易地想象如果还要实现其他的安全规则,这个表达式会不断膨胀。在变得很长之前,表达式就会笨重、复杂且难以测试。
其实我们能够将整个表达式替换为更加简单的版本,如下所示:
1 | public void deleteSpittles(List<Spittle> spittles) { ... } |
现在,设置给 @PreFilter 的表达式更加紧凑。它实际上只是在问一个问题“用户有权限删除目标对象吗?”。如果有的话,表达式的计算结果为 true,Spittle 会保存在列表中,并传递给 deleteSpittles() 方法。如果没有权限的话,它将会被移除掉。
但是,hasPermission() 是哪来的呢?它的意思是什么?更为重要的是,它如何知道用户有没有权限删除 targetObject 所对应的 Spittle 呢?
hasPermission() 函数是 Spring Security 为 SpEL 提供的扩展,它为开发者提供了一个时机,能够在执行计算的时候插入任意的逻辑。我们所需要做的就是编写并注册一个自定义的许可计算器。程序清单 14.1 展现了 SpittlePermissionEvaluator 类,它就是一个自定义的许可计算器,包含了表达式逻辑。
1 | package spittr.security;import java.io.Serializable;import org.springframework.security.access.PermissionEvaluator;import org.springframework.security.core.Authentication;import spittr.Spittle;public class SpittlePermissionEvaluator implements PermissionEvaluator { private static final GrantedAuthority ADMIN_AUTHORITY = new GrantedAuthoritylmpl("ROLE_ADMIN"); public boolean hasPermission(Authentication authentication, Object target, Object permission) { if (target instanceof Spittle) { Spittle spittle = (Spittle) target; String username = spittle.getSpitter().getUsername(); if ("delete".equals(permission)) { return isAdmin(authentication) || username.equals(authentication.getName()); } } throw new UnsupportedOperationException( "hasPermission not supported for object <" + target + "> and permission <" + permission + ">"); } public boolean hasPermission(Authentication authentication, Serializable targetId, String targetType, Object permission) { throw new UnsupportedOperationException(); } private boolean isAdmin(Authentication authentication) { return authentication.getAuthorities().contains(ADMIN_AUTHORITY); }} |
SpittlePermissionEvaluator 实现了 Spring Security 的 PermissionEvaluator 接口,它需要实现两个不同的 hasPermission() 方法。其中的一个 hasPermission() 方法把要评估的对象作为第二个参数。第二个 hasPermission() 方法在只有目标对象的 ID 可以得到的时候才有用,并将 ID作 为 Serializable 传入第二个参数。
为了满足我们的需求,我们假设使用 Spittle 对象来评估权限,所以第二个方法只是简单地抛出 UnsupportedOperationException。
对于第一个 hasPermission() 方法,要检查所评估的对象是否为一个 Spittle,并判断所检查的是否为删除权限。如果是这样,它将对比 Spitter 的用户名是否与认证用户的名称相等,或者当前用户是否具有 ROLE_ADMIN 权限。
许可计算器已经准备就绪,接下来需要将其注册到 Spring Security 中,以便在使用 @PreFilter 表达式的时候支持 hasPermission() 操作。为了实现该功能,我们需要替换原有的表达式处理器,换成使用自定义许可计算器的处理器。
默认情况下,Spring Security 会配置为使用 DefaultMethodSecurityExpressionHandler,它会使用一个 DenyAllPermissionEvaluator 实例。顾名思义, DenyAllPermissionEvaluator 将会在 hasPermission() 方法中始终返回 false,拒绝所有的方法访问。但是,我们可以为 Spring Security 提供另外一个 DefaultMethodSecurityExpressionHandler,让它使用我们自定义的 SpittlePermissionEvaluator,这需要重载 GlobalMethodSecurityConfiguration 的 createExpressionHandler 方法:
1 | MethodSecurityExpressionHandler createExpressionHandler() { DefaultMethodSecurityExpressionHandler expressionHandler = new DefaultMethodSecurityExpressionHandler(); expressionHandler.setPermissionEvaluator(new SpittlePermissionEvaluator()); return expressionHandler;} |
现在,我们不管在任何地方的表达式中使用 hasPermission() 来保护方法,都会调用 SpittlePermissionEvaluator 来决定用户是否有权限调用方法。
小结
方法级别的安全性是 Spring Security Web 级别安全性的一个重要补充,我们曾在第 9 章讨论过 Web 安全性。对于非 Web 应用来说,方法级别的安全性则是最前沿的防护。对于 Web 应用来讲,基于安全规则所声明的方法级别安全性能够保护 Web 请求。
在本章中,我们看到了六个可以在方法上声明安全性限制的注解。对于简单场景来说,面向权限的注解,包括 Spring Security 的 @Secured 以及基于标准的 @RolesAllowed 都很便利。当安全规则更为复杂的时候,组合使用 @PreAuthorize、@PostAuthorize 以及 SpEL 能够发挥更强大的威力。我们还看到通过为 @PreFilter 和 @PostFilter 提供 SpEL 表达式,过滤方法的输入和输出。
最后,我们还看到了让安全规则更加易于维护、测试和调试的方法,那就是自定义表达式计算器,它能够用在 SpEL 表达式的 hasPermission() 函数中。
从下一章开始,我们将会转移方向,从使用 Spring 开发后端应用程序转向与其他应用集成。在接下来的几章中,我们将会看到各种集成技术,包括远程服务、异步消息、REST 甚至还有发送 E-mail。在下一章我们将会探讨第一项集成技术,也就是使用 Spring 远程服务。
Spring 集成
应用程序都不是孤岛。如今,企业级应用程序必须要与其他的系统协作才能完成其目标。在第 4 部分,你将会学到如何跨越应用程序本身的边界,与其他的应用程序和企业级服务实现集成。
在第 15 章“使用远程服务”中,你会学到如何将应用程序中的对象导出为远程服务,还会学习如何透明地访问远程服务,这些服务就像是应用程序中的其他对象一样。我们将会介绍各种远程技术,包括 RMI、Hessian/Burlap 以及使用 JAX-WS 的 SOAP Web 服务。
与第 15 章所介绍的 RPC 风格的远程服务不同,第 16 章 “使用 Spring MVC 创建 REST API” 将会探讨如何使用 Spring MVC 构建 RESTful 服务,它关注于应用程序中的资源。
第 17 章 “Spring 消息” 将会探索一种不同的应用集成方式,也就是 Spring 如何用于 Java 消息服务(Java Message Service,JMS)和高级消息队列协议(Advanced Message Queuing Protocol,AMQP),从而实现应用程序之间的异步通信。
Web 应用需要越来越多的交互性,我们希望它能展现实时的数据。第 18 章 “使用 WebSocket 和 STOMP 实现消息功能”将会展现 Spring 的一项新功能,它支持在服务器和 Web 客户端之间实现异步通信。
另外一种形式的异步通信不一定发生在应用程序之间。在第 19 章“使用 Spring 发送 Email” 中,将会展现如何借助 Spring 以 Email 的形式发送异步消息给目标人群。
管理和监控 Spring bean 是第 20 章 “使用 JMX 管理 Spring Bean” 的主题。在该章中,你会学到如何把配置在 Spring 中 bean 自动导出为 JMXMBean。
本书的结尾是很新但是很必要的内容。第 21 章 “借助 Spring Boot 简化 Spring 开发” 介绍了在 Spring 开发中一个令人兴奋且能够改变游戏规则的项目。在典型的 Spring 应用中,会有很多繁杂的样板式配置,在这一章将会看到 Spring Boot 如何移除这些配置,能够让我们关注于业务功能的实现。
使用远程服务
本章内容:
- 访问和发布 RMI 服务
- 使用 Hessian 和 Burlap 服务
- 使用 Spring 的 HTTP invoker
- 使用 Spring 开发Web服务
想象一下,我们被困在一个荒凉的小岛上,这听上去就像是一场梦境变成了现实。毕竟,谁不想在海滩上静静地独处,可以幸福地不顾外面世界的纷纷扰扰呢?
但是在一个荒岛上,我们不可能总是享受冰镇果汁朗姆酒和日光浴,就算我们能享受这样宁静的隐居生活,但是过不了多久我们就会感到饥饿、厌烦和孤独。在这样的时光里,我们只能以椰子和用叉子所捕的鱼为生。我们终究还是需要食物、新的衣服以及其他供给。而且如果不能和其他人取得联系,不久我们就只能和排球说话了!
我们开发的很多应用就像被遗弃的荒岛。表面上看,它们好像能自给自足,但实际上,它们可能还需要和其他系统相互合作,这些系统既包括组织内部的也包括组织外部的。
例如,采购系统需要与厂商的供应链系统通信;公司的人力资源系统可能需要集成薪金系统;或者,薪金系统需要和打印、邮寄工资等外部系统进行通信。无论哪种情况,我们的应用都需要和其他系统进行交互,远程访问它们的服务。
作为一个 Java 开发者,我们有多种可以使用的远程调用技术,包括:
- 远程方法调用(Remote Method Invocation,RMI);
- Caucho 的 Hessian 和 Burlap;
- Spring 基于HTTP的远程服务;
- 使用 JAX-RPC 和 JAX-WS 的 Web Service。
不管我们选择哪种远程调用技术,Spring 为使用这几种不同的技术访问和创建远程服务都提供了广泛的支持。在本章,我们将学习 Spring 如何简化和完善这些远程调用服务。但是首先,让我们先简要了解一下远程调用是如何在 Spring 中工作的。
Spring 远程调用概览
远程调用是客户端应用和服务端之间的会话。在客户端,它所需要的一些功能并不在该应用的实现范围之内,所以应用要向能提供这些功能的其他系统寻求帮助。而远程应用通过远程服务暴露这些功能。
假设我们想把Spittr应用中的某些功能发布为远程服务并提供给其他应用来使用。或许除了现有的基于浏览器的用户界面,我们还想为Spittr应用提供桌面应用或移动端应用,如图15.1所示。为了实现此想法,我们需要把SpitterService接口的基本功能发布为远程服务。
图15.1 第三方客户端能够远程调用Spittr的服务,从而实现与Spittr应用交互
其他应用与Spittr之间的会话开始于客户端应用的一个远程过程调用(remote procedure call,RPC)。从表面上看,RPC类似于调用一个本地对象的一个方法。这两者都是同步操作,会阻塞调用代码的执行,直到被调用的过程执行完毕。
它们的差别仅仅是距离的问题,类似于人与人之间的交流。如果我们在公共场所的饮水机旁讨论周末足球比赛的结果,那我们就是在进行一个本地会话——两人之间的会话发生在同一房间内。同样,本地方法调用是指同一个应用中的两个代码块之间的执行流交换。
另一方面,如果我们拿起电话打给另一个城市的客户端,那我们之间的会话就是通过电话网络远程进行的。类似地,RPC调用就是执行流从一个应用传递给另一个应用,理论上另一个应用部署在跨网络的一台远程机器上。
正如我之前所述,Spring支持多种不同的RPC模型,包括RMI、Caucho的Hessian和Burlap以及Spring自带的HTTP invoker。表15.1概述了每一个RPC模型,并简要讨论了它们所适用的不同场景。
表15.1 Spring通过多种远程调用技术支持RPC
| RPC模型 | 适用场景 |
|---|---|
| 远程方法调用(RMI) | 不考虑网络限制时(例如防火墙),访问/发布基于Java的服务 |
| Hessian 或 Burlap | 考虑网络限制时,通过HTTP访问/发布基于Java的服务。Hessian是二进制协议,而Burlap是基于XML的 |
| HTTP invoker | 考虑网络限制,并希望使用基于XML或专有的序列化机制实现Java序列化时,访问/发布基于Spring的服务 |
| JAX-RPC和JAX-WS | 访问/发布平台独立的、基于SOAP的Web服务 |
不管你选择哪种远程调用模型,我们会发现Spring都提供了风格一致的支持。这意味着一旦理解了如何配置Spring来使用其中的一种模型,如果我们决定使用另外一种模型的话,将拥有非常低的学习曲线。
在所有的模型中,服务都作为Spring所管理的bean配置到我们的应用中。这是通过一个代理工厂bean实现的,这个bean能够把远程服务像本地对象一样装配到其他bean的属性中去。图15.2展示了它是如何工作的。
图15.2 在Spring中,远程服务被代理,所以它们能够像其他Spring bean一样被装配到客户端代码中
客户端向代理发起调用,就像代理提供了这些服务一样。代理代表客户端与远程服务进行通信,由它负责处理连接的细节并向远程服务发起调用。
更重要的是,如果调用远程服务时发生java.rmi.RemoteException异常,代理会处理此异常并重新抛出非检查型异常RemoteAccessException。远程异常通常预示着系统发生了无法优雅恢复的问题,如网络或配置问题。既然客户端通常无法从远程异常中恢复,那么重新抛出RemoteAccessException异常就能让客户端来决定是否处理此异常。
在服务器端,我们可以使用表15.1所列出的任意一种模型将Spring管理的bean发布为远程服务。图15.3展示了远程导出器(remote exporter)如何将bean方法发布为远程服务。
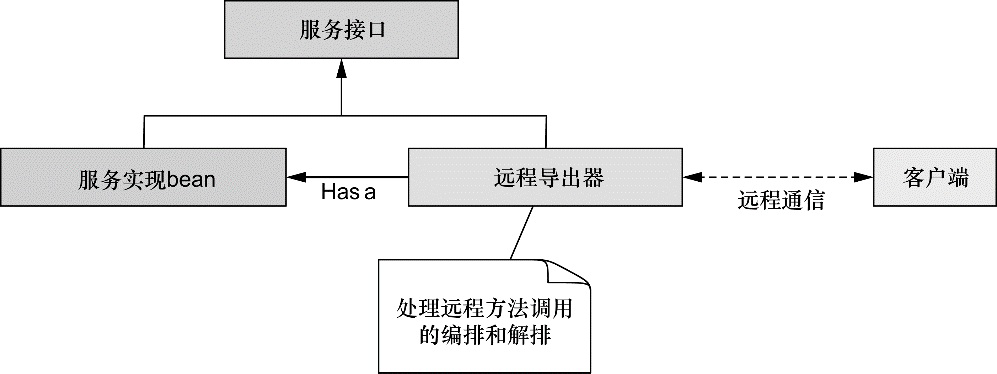
图15.3 使用远程导出器将Spring管理的bean发布为远程服务
无论我们开发的是使用远程服务的代码,还是实现这些服务的代码,或者两者兼而有之,在Spring中,使用远程服务纯粹是一个配置问题。我们不需要编写任何Java代码就可以支持远程调用。我们的服务bean也不需要关心它们是否参与了一个RPC(当然,任何传递给远程调用的bean或从远程调用返回的bean可能需要实现java.io.Serializable接口)。
让我们通过RMI——Java最初的远程调用技术——来开始探索Spring对远程调用的支持吧。
使用RMI
如果你已经使用Java编程有些年头的话,你肯定会听说过(也可能使用过)RMI。RMI最初在JDK 1.1被引入到Java平台中,它为Java开发者提供了一种强大的方法来实现Java程序间的交互。在RMI之前,对于Java开发者来说,远程调用的唯一选择就是CORBA(在当时,需要购买一种第三方产品,叫作Object Request Broker[ORB]),或者手工编写Socket程序。
但是开发和访问RMI服务是非常乏味无聊的,它涉及到好几个步骤,包括程序的和手工的。Spring简化了RMI模型,它提供了一个代理工厂bean,能让我们把RMI服务像本地JavaBean那样装配到我们的Spring应用中。Spring还提供了一个远程导出器,用来简化把Spring管理的bean转换为RMI服务的工作。
对于Spittr应用,我们将展示如何把一个RMI服务装配进客户端应用程序的Spring应用上下文中。但首先,让我们看看如何使用RMI导出器把SpitterService的实现发布为RMI服务。
导出RMI服务
如果你曾经创建过RMI服务,应该会知道这会涉及如下几个步骤:
- 编写一个服务实现类,类中的方法必须抛出java.rmi.RemoteException异常;
- 创建一个继承于java.rmi.Remote的服务接口;
- 运行RMI编译器(rmic),创建客户端stub类和服务端skeleton类;
- 启动一个RMI注册表,以便持有这些服务;
- 在RMI注册表中注册服务。
哇!发布一个简单的RMI服务需要做这么多的工作。除了这些必需的步骤外,你可能注意到了,会抛出相当多的RemoteException和 MalformedURLException异常。虽然这些异常通常意味着一个无法从catch代码块中恢复的致命错误,但是我们仍然需要编写样板式的代码来捕获并处理这些异常——即使我们不能修复它们。
很明显,发布一个RMI服务涉及到大量的代码和手工作业。Spring是否能够做一些工作来让这些事情变得不再那么棘手呢?
在Spring中配置RMI服务
幸运的是,Spring提供了更简单的方式来发布RMI服务,不用再编写那些需要抛出RemoteException异常的特定RMI类,只需简单地编写实现服务功能的POJO就可以了,Spring会处理剩余的其他事项。
我们将要创建的RMI服务需要发布SpitterService接口中的方法,如下的程序清单展现了该接口定义。
程序清单15.1 SpitterService定义了Spittr应用的服务层
1 | package com.habuma.spittr.service;import java.util.List;import com.habuma.spittr.domain.Spitter;import com.habuma.spittr.domain.Spittle;public interface SpitterService { List<Spittle> getRecentSpittles(int count); void saveSpittle{Spittle spittle); void saveSpitter{Spitter spitter); Spitter getSpitter(long id); void startFollowing(Spitter follower, Spitter followee); List<Spittle> getSpittlesForSpitter(Spitter spitter); List<Spittle> getSpittlesForSpitter(String username); Spitter getSpitter(String username); Spittle getSpittleById(long id); void deleteSpittle(long id); List<Spitter> getAllSpitters();} |
如果我们使用传统的RMI来发布此服务,SpitterService和SpitterServiceImpl中的所有方法都需要抛出java.rmi.RemoteException。但是如果我们使用Spring的
RmiServiceExporter把该类转变为RMI服务,那现有的实现不需要做任何改变。
RmiServiceExporter可以把任意Spring管理的bean发布为RMI服务。如图15.4所示,RmiServiceExporter把bean包装在一个适配器类中,然后适配器类被绑定到RMI注册表中,并且代理到服务类的请求——在本例中服务类也就是SpitterServiceImpl。
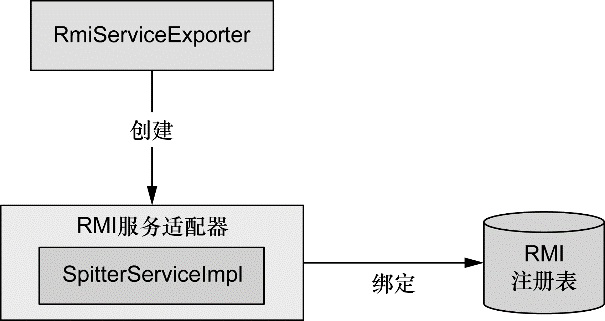
图15.4 RmiServiceExporter把POJO包装到服务适配器中,并将服务适配器绑定到RMI注册表中,从而将POJO转换为RMI服务
使用RmiServiceExporter将SpitterServiceImpl发布为RMI服务的最简单方式是在Spring中使用如下的@Bean方法进行配置:
1 | RmiServiceExporter rmiExporter(SpitterService spitterService) { RmiServiceExporter rmiExporter = new RmiServiceExporter(); rmiExporter.setService(spitterService); rmiExporter.setServiceName("SpitterService"); rmiExporter.setServiceInterface(SpitterService.class); return rmiExporter;} |
这里会把spitterServicebean设置到service属性中,表明RmiServiceExporter要把该bean发布为一个RMI服务。serviceName属性命名了RMI服务,serviceInterface属性指定了此服务所实现的接口。
默认情况下,RmiServiceExporter会尝试绑定到本地机器1099端口上的RMI注册表。如果在这个端口没有发现RMI注册表,RmiServiceExporter将会启动一个注册表。如果希望绑定到不同端口或主机上的RMI注册表,那么我们可以通过registryPort和registryHost属性来指定。例如,下面的RmiServiceExporter会尝试绑定rmi.spitter.com主机1199端口上的RMI注册表:
1 | RmiServiceExporter rmiExporter(SpitterService spitterService) { RmiServiceExporter rmiExporter = new RmiServiceExporter(); rmiExporter.setService(spitterService); rmiExporter.setServiceName("SpitterService"); rmiExporter.setServiceInterface(SpitterService.class); rmiExporter.setRegistryHost("rmi.spitter.com"); rmiExporter.setRegistryPort(1199); return rmiExporter;} |
这就是我们使用Spring把某个bean转变为RMI服务所需要做的全部工作。现在Spitter服务已经导出为RMI服务,我们可以为Spittr应用创建其他的用户界面或邀请第三方使用此RMI服务创建新的客户端。如果使用Spring,客户端开发者访问Spitter的RMI服务会非常容易。
让我们转换一下视角来看看如何编写Spitter RMI服务的客户端。
装配RMI服务
传统上,RMI客户端必须使用RMI API的Naming类从RMI注册表中查找服务。例如,下面的代码片段演示了如何获取Spitter的RMI服务:
1 | try { String serviceUrl = "rmi:/spitter/SpitterService"; SpitterService spitterService = (SpitterService) Naming.lookup(serviceId) ...} catch (RemoteException e) { ...} catch (NotBoundException e) { ...} catch (MalformedURLException e) { ...} |
虽然这段代码可以获取Spitter的RMI服务的引用,但是它存在两个问题:
- 传统的RMI查找可能会导致3种检查型异常的任意一种(RemoteException、NotBoundException和MalformedURLException),这些异常必须被捕获或重新抛出;
- 需要Spitter服务的任何代码都必须自己负责获取该服务。这属于样板代码,与客户端的功能并没有直接关系。
RMI查找过程中所抛出的异常通常意味着应用发生了致命的不可恢复的问题。例如,MalformedURLException异常意味着这个服务的地址是无效的。为了从这个异常中恢复,应用至少要重新配置,也可能需要重新编译。try/catch代码块并不能在发生异常时优雅地恢复,既然如此,为什么还要强制我们的代码捕获并处理这个异常呢?
但是,更糟糕的事情是这段代码直接违反了依赖注入(DI)原则。因为客户端代码需要负责查找Spitter服务,并且这个服务是RMI服务,我们甚至没有任何机会去提供SpitterService对象的不同实现。
理想情况下,应该可以为任意一个bean注入SpitterService对象,而不是让bean自己去查找服务。利用DI,SpitterService的任何客户端都不需要关心此服务来源于何处。
Spring的RmiProxyFactoryBean是一个工厂bean,该bean可以为RMI服务创建代理。使用RmiProxyFactoryBean引用SpitterService的RMI服务是非常简单的,只需要在客户端的Spring配置中增加如下的@Bean方法:
1 | RmiProxyFactoryBean spitterService() { RmiProxyFactoryBean rmiProxy = new RmiProxyFactoryBean(); rmiProxy.setServiceUrl("rmi://localhost/SpitterService"); rmiProxy.setServiceInterface(SpitterService.class); return rmiProxy;} |
服务的URL是通过RmiProxyFactoryBean的serviceUrl属性来设置的,在这里,服务名被设置为SpitterService,并且声明服务是在本地机器上的;同时,服务提供的接口由serviceInterface属性来指定。图15.5展示了客户端和RMI代理的交互。
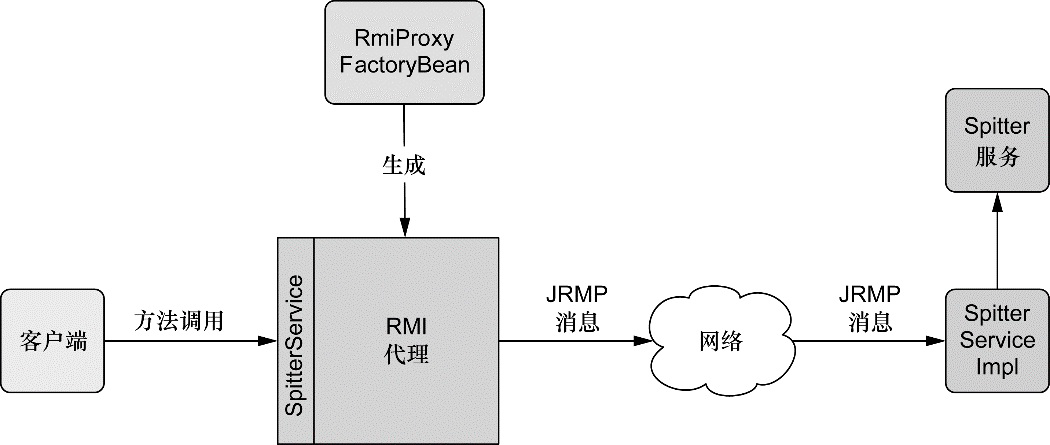
图15.5 RmiProxyFactoryBean生成一个代理对象,该对象代表客户端来负责与远程的RMI服务进行通信。客户端通过服务的接口与代理进行交互,就如同远程服
务就是一个本地的POJO
现在已经把RMI服务声明为Spring管理的bean,我们就可以把它作为依赖装配进另一个bean中,就像任意非远程的bean那样。例如,假设客户端需要使用Spitter服务为指定的用户获取Spittle列表,我们可以使用@Autowired注解把服务代理装配进客户端中:
1 | spitterService; |
我们还可以像本地bean一样调用它的方法:
1 | public List<Spittle> getSpittles(String userName) { Spitter spitter = spitterService.getSpitter(userName); return spitterService.getSpittersForSpitter(spitter);} |
以这种方式访问RMI服务简直太棒了!客户端代码甚至不需要知道所处理的是一个RMI服务。它只是通过注入机制接受了一个SpitterService对象,根本不必关心它来自何处。实际上,谁知道客户端得到的就是一个基于RMI的实现呢?
此外,代理捕获了这个服务所有可能抛出的RemoteException异常,并把它包装为运行期异常重新抛出,这样我们就可以放心地忽略这些异常。我们也可以非常容易地把远程服务bean替换为该服务的其他实现——或许是不同的远程服务,或者可能是客户端代码单元测试时的一个mock实现。
虽然客户端代码根本不需要关心所赋予的SpitterService是一个远程服务,但我们需要非常谨慎地设计远程服务的接口。提醒一下,客户端不得不调用两次服务:一次是根据用户名查找Spitter,另一次是获取Spittle对象的列表。这两次远程调用都会受网络延迟的影响,进而可能会影响到客户端的性能。清楚了客户端是如何使用服务的,我们或许会重写接口,把这两个调用放进一个方法中。但是现在我们要接受这样的服务接口。
RMI是一种实现远程服务交互的好办法,但是它存在某些限制。首先,RMI很难穿越防火墙,这是因为RMI使用任意端口来交互——这是防火墙通常所不允许的。在企业内部网络环境中,我们通常不需要担心这个问题。但是如果在互联网上运行,我们用RMI可能会遇到麻烦。即使RMI提供了对HTTP的通道的支持(通常防火墙都允许),但是建立这个通道也不是件容易的事。
另外一件需要考虑的事情是RMI是基于Java的。这意味着客户端和服务端必须都是用Java开发的。因为RMI使用了Java的序列化机制,所以通过网络传输的对象类型必须要保证在调用两端的Java运行时中是完全相同的版本。对我们的应用而言,这可能是个问题,也可能不是问题。但是选择RMI做远程服务时,必须要牢记这一点。
Caucho Technology(Resin应用服务器背后的公司)开发了一套应对RMI限制的远程调用解决方案。实际上,Caucho提供了两种解决方案:Hessian和Burlap。让我们看一下如何在Spring中使用Hessian和Burlap处理远程服务。
使用Hessian和Burlap发布远程服务
Hessian和Burlap是Caucho Technology提供的两种基于HTTP的轻量级远程服务解决方案。借助于尽可能简单的API和通信协议,它们都致力于简化Web服务。
你可能会好奇,为什么Caucho对同一个问题会有两种解决方案。Hessian和Burlap就如同一个事物的两面,但是每一个解决方案都服务于略微不同的目的。
Hessian,像RMI一样,使用二进制消息进行客户端和服务端的交互。但与其他二进制远程调用技术(例如RMI)不同的是,它的二进制消息可以移植到其他非Java的语言中,包括PHP、Python、C++和C#。
Burlap是一种基于XML的远程调用技术,这使得它可以自然而然地移植到任何能够解析XML的语言上。正因为它基于XML,所以相比起Hessian的二进制格式而言,Burlap可读性更强。但是和其他基于XML的远程技术(例如SOAP或XML-RPC)不同,Burlap的消息结构尽可能的简单,不需要额外的外部定义语言(例如WSDL或IDL)。
你可能想知道如何在Hessian和Burlap之间做出选择。很大程度上,它们是一样的。唯一的区别在于Hessian的消息是二进制的,而Burlap的消息是XML。由于Hessian的消息是二进制的,所以它在带宽上更具优势。但是如果我们更注重可读性(如出于调试的目的)或者我们的应用需要与没有Hessian实现的语言交互,那么Burlap的XML消息会是更好的选择。
为了在Spring中演示Hessian和Burlap服务,让我们回顾一下在前一节中使用RMI解决Spitter服务的示例。但是这一次,我们将看看如何使用Hessian和Burlap作为远程调用模型来解决这个问题。
使用Hessian和Burlap导出bean的功能
像之前一样,我们希望把SpitterServiceImpl类的功能发布为远程服务——这次是一个Hessian服务。即使没有Spring,编写一个Hessian服务也是相当容易的。我们只需要编写一个继承com.caucho.hessian.server.HessianServlet的类,并确保所有的服务方法是public的(在Hessian里,所有public方法被视为服务方法)。
因为Hessian服务很容易实现,Spring并没有做更多简化Hessian模型的工作。但是和Spring一起使用时,Hessian服务可以在各方面利用Spring框架的优势,这是纯Hessian服务所不具备的。包括利用Spring的AOP来为Hessian服务提供系统级服务,例如声明式事务。
导出Hessian服务
在Spring中导出一个Hessian服务和在Spring中实现一个RMI服务惊人的相似。为了把Spitter服务bean发布为RMI服务,我们需要在Spring配置文件中配置一个RmiServiceExporterbean。同样的方式,为了把Spitter服务发布为Hessian服务,我们需要配置另一个导出bean,只不过这次是HessianServiceExporter。
HessianServiceExporter对Hessian服务所执行的功能
与RmiServiceExporter对RMI服务所执行的功能是相同的:它把POJO的public方法发布成Hessian服务的方法。不过,正如图15.6所示,其实现过程与 RmiServiceExporter将POJO发布为RMI服务是不同的。
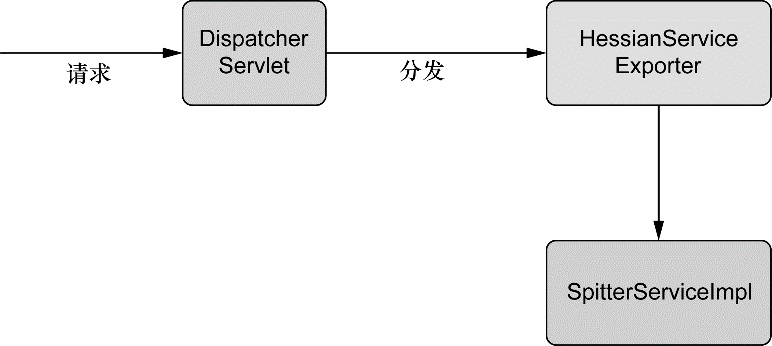
图15.6 HessianServiceExporter是一个Spring MVC控制器,它可以接收Hessian请求,并把这些请求转换成对POJO的调用从而将POJO导出为一个Hessian服务
HessianServiceExporter(稍后会有更详细的介绍)是一个Spring MVC控制器,它接收Hessian请求,并将这些请求转换成对被导出POJO的方法调用。在如下Spring的声明中,HessianServiceExporter会把spitterService bean导出为Hessian服务:
1 | HessianServiceExporter hessianExportedSpitterService(SpitterService service) { HessianServiceExporter exporter = new HessianServiceExporter(); exporter.setService(service); exporter.setServiceInterface(SpitterService.class); return exporter;} |
正如RmiServiceExporter一样,service属性的值被设置为实现了这个服务的bean引用。在这里,它引用的是spitterServicebean。serviceInterface属性用来标识这个服务实现了SpitterService接口。
与RmiServiceExporter不同的是,我们不需要设置serviceName属性。在RMI中,serviceName属性用来在RMI注册表中注册一个服务。而Hessian没有注册表,因此也就没必要为Hessian服务进行命名。
配置Hessian控制器
RmiServiceExporter和HessianServiceExporter另外一个主要区别就是,由于Hessian是基于HTTP的,所以HessianSeriviceExporter实现为一个Spring MVC控制器。这意味着为了使用导出的Hessian服务,我们需要执行两个额外的配置步骤:
在web.xml中配置Spring的DispatcherServlet,并把我们的应用部署为 Web应用;
在Spring的配置文件中配置一个URL处理器,把Hessian服务的URL分发给对应的Hessian服务bean。
我们在第5章学习了如何配置Spring的DispatcherServlet和URL处理器,所以这些步骤看起来有些熟悉。首先,我们需要一个DispatcherServlet。还好,这个我们已经在Spittr应用的web.xml文件中配置了。但是为了处理Hessian服务,DispatcherServlet还需要配置一个Servlet映射来拦截后缀为 *.service 的URL:
1 | <servlet-mapping> <servlet-name>spitter</servlet-name> <url-pattern>*.service</url-pattern></servlet-mapping> |
如果你在Java中通过实现WebApplicationInitializer来配置DispatcherServlet的话,那么需要将URL模式作为映射添加到ServletRegistration.Dynamic中,在
将DispatcherServlet添加到容器中的时候,我们能够得到ServletRegistration.Dynamic对象:
1 | ServletRegistration.Dynamic dispatcher = container.addServlet( "appServlet", new DispatcherServlet(dispatcherServletContext));dispatcher.setLoadOnStartup();dispatcher.addMapping("/");dispatcher.addMapping("*.service"); |
或者,如果你通过扩展AbstractDispatcherServletInitializer或AbstractAnnotationConfigDispatcherServletInitializer的方式来配置DispatcherServlet,那么在重
载getServletMappings()的时候,需要包含该映射:
1 | String[] getServletMapping() { return new String[] { "/", "*.service"};} |
这样配置后,任何以“.service”结束的URL请求都将由DispatcherServlet处理,它会把请求传递给匹配这个URL的控制器。因此“/spitter.service”的请求最终将被
hessianSpitterServicebean所处理(它实际上仅仅是一个SpitterServiceImpl的代理)。
那我们是如何知道这个请求会转给hessianSpitterSevice处理呢?我们还需要配置一个URL映射来确保DispatcherServlet把请求转给hessianSpitterService。如下的SimpleUrlHandlerMappingbean可以做到这一点:
1 | HandlerMapping hessianMapping() { SimpleUrlHandlerMapping mapping = new SimpleUrlHandlerMapping(); Properties mappings = new Properties(); mappings.setProperty("/spitter.service", "hessianExportedSpitterService"); mapping.setMappings(mappings); return mapping;} |
如果不喜欢Hessian的二进制协议,我们还可以选择使用Burlap基于XML的协议。让我们看看如何把一个服务导出为Burlap服务。
导出Burlap服务
从任何方面上看,BurlapServiceExporter与HessianServiceExporter实际上都是相同的,只不过它使用基于XML的协议而不是二进制协议。下面的bean定义展示了如何使用BurlapServiceExporter把Spitter服务导出为一个Burlap服务:
1 | BurlapServiceExporter burlapExportedSpitterService(SpitterService service) { BurlapServiceExporter exporter = new BurlapServiceExporter(); exporter.setService(service); exporter.setServiceInterface(SpitterService.class); return exporter;} |
正如我们所看到的,这个bean与使用Hessian所对应bean的唯一区别在于bean的方法和导出类。配置Burlap服务和配置Hessian服务是一模一样的,这包括需要准备一个URL处理器和一个DispatcherServlet。
现在让我们看看会话的另一端,如何访问我们使用Hessian(或Burlap)所发布的服务。
访问Hessian/Burlap服务
回顾一下在15.2.2小节中,在使用RmiProxyFactoryBean访问Spitter服务的客户端代码中,完全不知道这个服务是一个RMI服务。事实上,也根本没有任何迹象表明这个服务是一个远程服务。它只是与SpitterService接口打交道——RMI的所有细节完全包含在Spring配置中这个bean的配置中。好处是客户端不需要了解服务的实现,因此从RMI客户端转到Hessian客户端会变得极其简单,不需要改变任何客户端的Java代码。
坏处是,如果你真的喜欢编写Java代码的话,那么这一节或许让你大失所望。这是因为在客户端代码中,基于RMI的服务与基于Hessian的服务之间唯一的差别在于要使用Spring的HessianProxyFactoryBean来代替RmiProxyFactoryBean。客户端调用基于Hessian的Spitter服务可以用如下的配置声明:
1 | HessianProxyFactoryBean spitterService() { HessianProxyFactoryBean proxy = new HessianProxyFactoryBean(); proxy.setServiceUrl("http://localhost:8080/Spitter/spitter.service"); proxy.setServiceInterface(SpitterService.class); return proxy;} |
就像基于RMI服务那样,serviceInterface属性指定了这个服务实现的接口。并且,像RmiProxyFactoryBean一样,serviceUrl标识了这个服务的URL。既然Hessian是基于HTTP的,当然我们在这里要设置一个HTTP URL(URL是由我们先前定义的URL映射所决定的)。图15.7展示了客户端以及由HessianProxyFactoryBean所生成的代理之间是如何交互的。
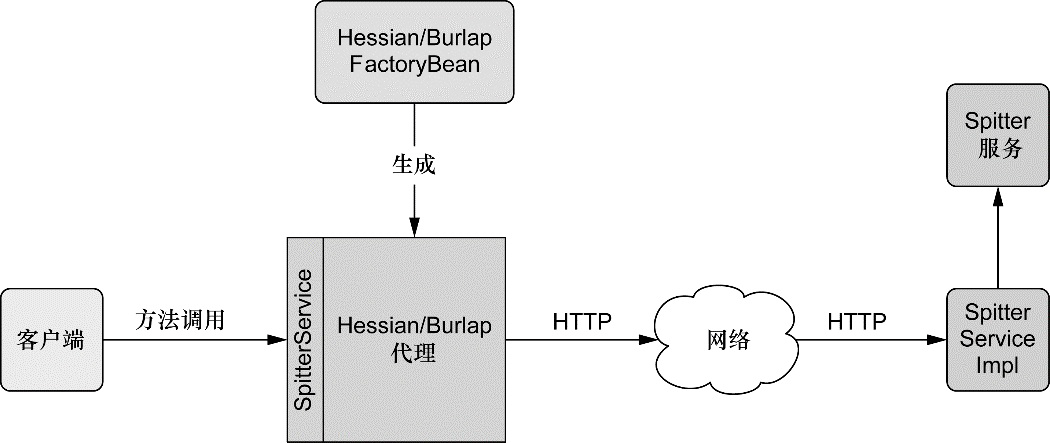
图15.7 HessianProxyFactoryBean和BurlapProxyFactoryBean生成的代理对象负责
通过HTTP(Hessian为二进制、Burlap为XML)与远程对象通信事实证明,把Burlap服务装配进客户端同样也没有太多新意。二者唯一的区别在于,我们要使用BurlapProxyFactoryBean来代替HessianProxyFactoryBean:
1 | BurlapProxyFactoryBean spitterService() { BurlapProxyFactoryBean proxy = new BurlapProxyFactoryBean(); proxy.setServiceUrl("http://localhost:8080/Spitter/spitter.service"); proxy.setServiceInterface(SpitterService.class); return proxy;} |
尽管我们觉得在RMI、Hessian和Burlap服务之间稍微不同的配置是很无趣的,但是这样的单调恰恰是有好处的。它意味着我们可以很容易在各种Spring所支持的远程调用技术之间进行切换,而不需要重新学习一个全新的模型。一旦我们配置了对RMI服务的引用,把它重新配置为Hessian或Burlap服务也是很轻松的工作。
因为Hessian和Burlap都是基于HTTP的,它们都解决了RMI所头疼的防火墙渗透问题。但是当传递过来的RPC消息中包含序列化对象时,RMI就完胜Hessian和Burlap了。因为Hessian和Burlap都采用了私有的序列化机制,而RMI使用的是Java本身的序列化机制。如果我们的数据模型非常复杂,Hessian/Burlap的序列化模型就可能无法胜任了。
我们还有一个两全其美的解决方案。让我们看一下Spring的HTTP invoker,它基于HTTP提供了RPC(像Hessian/Burlap一样),同时又使用了Java的对象序列化机制(像RMI一样)。
使用Spring的HttpInvoker
Spring开发团队意识到RMI服务和基于HTTP的服务(例如Hessian和Burlap)之间的空白。一方面,RMI使用Java标准的对象序列化机制,但是很难穿透防火墙。另一方面,Hessian和Burlap能很好地穿透防火墙,但是使用私有的对象序列化机制。
就这样,Spring的HTTP invoker应运而生了。HTTP invoker是一个新的远程调用模型,作为Spring框架的一部分,能够执行基于HTTP的远程调用(让防火墙不为难),并使用Java的序列化机制(让开发者也乐观其变)。使用基于HTTP invoker的服务和使用基于Hessian/Burlap的服务非常相似。
为了开始学习HTTP invoker,让我们再来看一下Spitter服务——这一次我们将作为HTTP invoker服务来实现。
将bean导出为HTTP服务
要将bean导出为RMI服务,我们需要使用RmiServiceExporter;要将bean导出为Hessian服务,我们需要使用HessianServiceExporter;要将bean导出为Burlap服务,我们需要使用BurlapServiceExporter。把这种千篇一律的用法带到HTTP invoker上,应该也不会有任何意外的事情发生,那就是导出HTTP invoker服务,我们需要使用HttpInvokerServiceExporter。
为了把Spitter服务导出为一个基于HTTP invoker的服务,我们需要像下面的配置一样声明一个HttpInvokerServiceExporterbean:
1 | HttpInvokerServiceExporter httpExportedSpitterService(SpitterService service) { HttpInvokerServiceExporter exporter = new HttpInvokerServiceExporter(); exporter.setService(service); exporter.setServiceInterface(SpitterService.class); return exporter;} |
是否有点似曾相识的感觉?我们很难找出这个bean的定义和那些在15.3.2小节中所声明的bean有什么不同。唯一的区别在于类名:HttpInvokerServiceExporter。否则的话,这个导出器和其他的远程服务的导出器就没有任何区别了。
如图15.8所示,HttpInvokerServiceExporter的工作方式与HessianService-Exporter和BurlapServiceExporter很相似。HttpInvokerServiceExporter也是一个Spring的MVC控制器,它通过DispatcherServlet接收来自于客户端的请求,并将这些请求转换成对实现服务的POJO的方法调用。
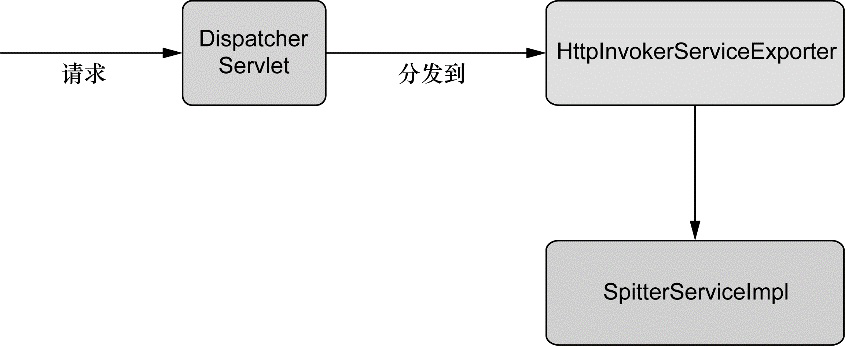
图15.8 HttpInvokerServiceExporter工作方式与Hessian和Burlap很相似,通过Spring MVC的DispatcherServlet接收请求,并将这些请求转换成对Spring bean
的方法调用
因为HttpInvokerServiceExporter是一个Spring MVC控制器,我们需要建立一个URL处理器,映射HTTP URL到对应的服务上,就像Hessian和Burlap导出器所做的一样:
1 | HandlerMapping hessianMapping() { SimpleUrlHandlerMapping mapping = new SimpleUrlHandlerMapping(); Properties mappings = new Properties(); mappings.setProperty("/spitter.service", "httpExportedSpitterService"); mapping.setMappings(mappings); return mapping;} |
同样,像之前一样,我们需要确保匹配了DispatcherServlet,这样才能处理对“*.service”扩展的请求。参考15.3.1小节了解如何设置映射。
我们已经知道如何访问由RMI、Hessian或Burlap所创建的远程服务,现在我们再次让Spitter客户端使用刚才所导出的基于HTTP invoker的服务。
通过HTTP访问服务
这听起来像打破记录,但是我还得告诉你,访问基于HTTP invoker的服务很类似于我们之前使用的其他远程服务代理。实际上就是一样的。如图15.9所示,HttpInvokerProxyFactoryBean填充了相同的位置,正如我们在本章所看到的其他远程服务代理工厂bean一样。
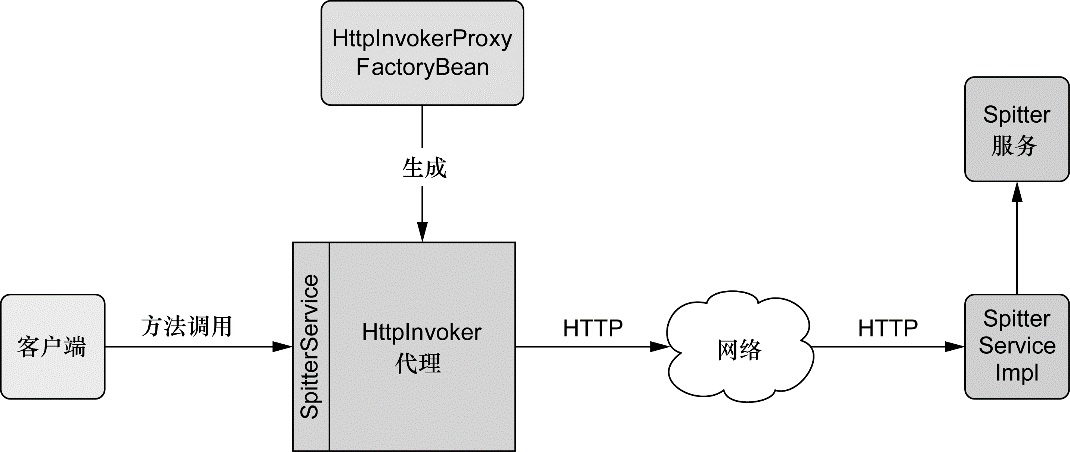
图15.9 HttpInvokerProxyFactoryBean是一个代理工厂bean,用于生成一个代理,该代理使用Spring特有的基于HTTP协议进行远程通信
为了把基于HTTP invoker的远程服务装配进我们的客户端Spring应用上下文中,我们必须将 HttpInvokerProxyFactoryBean 配置为一个bean来代理它,如下所示:
1 | HttpInvokerProxyFactoryBean spitterService() { HttpInvokerProxyFactoryBean proxy = new HttpInvokerProxyFactoryBean(); proxy.setServiceUrl("http://localhost:8080/Spitter/spitter.service"); proxy.setServiceInterface(SpitterService.class); return proxy;} |
与15.2.2小节和15.3.2小节的bean定义相对比,我们会发现几乎没什么变化。serviceInterface属性仍然用来标识Spitter服务所实现的接口,而serviceUrl属性仍然用来标识远程服务的位置。因为HTTP invoker是基于HTTP的,如同Hessian和Burlap一样,serviceUrl可以包含与Hessian和Burlap版本中的bean一样的URL。
难道你不喜欢对称美吗?
Spring的HTTP invoker是作为两全其美的远程调用解决方案而出现的,把HTTP的简单性和Java内置的对象序列化机制融合在一起。这使得HTTP invoker服务成为一个引人注目的替代RMI或Hessian/Burlap的可选方案。
要记住HTTP invoker有一个重大的限制:它只是一个Spring框架所提供的远程调用解决方案。这意味着客户端和服务端必须都是Spring应用。并且,至少目前而言,也隐含表明客户端和服务端必须是基于Java的。另外,因为使用了Java的序列化机制,客户端和服务端必须使用相同版本的类(与RMI类似)。
RMI、Hessian、Burlap和HTTP invoker都是远程调用的可选解决方案。但是当面临无所不在的远程调用时,Web服务是势不可挡的。下一节,我们将了解Spring如何对基于SOAP的Web服务远程调用提供支持。
发布和使用Web服务
近几年,最流行的一个TLA(三个字母缩写)就是SOA(面向服务的架构)。SOA对不同的人意味着不同的意义。但是,SOA的核心理念是,应用程序可以并且应该被设计成依赖于一组公共的核心服务,而不是为每个应用都重新实现相同的功能。
例如,一个金融机构可能有若干个应用,其中很多都需要访问借款者的账户信息。在这种情况下,应用应该都依赖于一个公共的获取账户信息的服务,而不应该在每一个应用中都建立账户访问逻辑(其中大部分逻辑都是重复的)。
Java与Web服务的结合已经有很长的历史了,而且在Java中使用Web服务有多种选择。其中的大多数可选方案已经以某种方式与Spring进行了整合。虽然Spring为使用Java API for XML Web Service(JAX-WS)来发布和使用SOAP Web服务提供了大力支持,但是在本书我不可能涵盖每一个Spring所支持的Web服务框架和工具箱。
在本节,我们重新回顾下Spitter服务示例,不过这次我们将使用Spring对JAX-WS的支持来把Spitter服务发布为Web服务并使用此Web服务。首先,我们来看一下如何在Spring中创建JAX-WS Web服务。
创建基于Spring的JAX-WS端点
在本章前面的内容中,我们使用Spring的服务导出器创建了远程服务。这些服务导出器很神奇地将Spring配置的POJO转换成了远程服务。我们看到了如何使用RmiServiceExporter创建RMI服务,如何使用HessianServiceExporter创建Hessian服务,如何使用BurlapServiceExporter创建Burlap服务,以及如何使用HttpInvokerServiceExporter创建HTTP invoker服务。现在你或许期望我在本节展示如何使用一个JAX-WS服务导出器创建Web服务。
Spring的确提供了一个JAX-WS服务导出器,SimpleJaxWsServiceExporter,我们很快就可以看到。但在这之前,你必须知道它并不一定是所有场景下的最好选择。你是知道的,SimpleJaxWsServiceExporter要求JAX-WS运行时支持将端点发布到指定地址上。Sun JDK 1.6自带的JAX-WS可以符合要求,但是其他的JAX-WS实现,包括JAX-WS的参考实现,可能并不能满足此需求。
如果我们将要部署的JAX-WS运行时不支持将其发布到指定地址上,那我们就要以更为传统的方式来编写JAX-WS端点。这意味着端点的生命周期由JAX-WS运行时来进行管理,而不是Spring。但是这并不意味着它们不能装配Spring上下文中的bean。
在Spring中自动装配JAX-WS端点
JAX-WS编程模型使用注解将类和类的方法声明为Web服务的操作。使用@WebService注解所标注的类被认为Web服务的端点,而使用@WebMethod注解所标注的方法被认为是操作。
就像大规模应用中的其他对象一样,JAX-WS端点很可能需要与其他对象交互来完成工作。这意味着JAX-WS端点可以受益于依赖注入。但是如果端点的生命周期由JAX-WS运行时来管理,而不是由Spring来管理的话,这似乎不可能把Spring管理的bean装配进JAX-WS管理的端点实例中。
装配JAX-WS端点的秘密在于继承SpringBeanAutowiringSupport。通过继承SpringBeanAutowiringSupport,我们可以使用@Autowired注解标注端点的属性,依赖就会自动注入了。SpitterServiceEndpoint展示了它是如何工作的。
程序清单15.2 JAX-WS端点中的SpitterBeanAutowiringSupport
1 | package com.habuma.spittr.remoting.jaxws;import java.util.List;import javax.jws.WebMethod;import javax.jws.WebService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.context.support.SpringBeanAutowiringSupport;import com.habuma.spittr.domain.Spitter;import com.habuma.spittr.domain.Spittle;import com.habuma.spittr.service.SpitterServicepublic class SpitterServiceEndpoint extends SpringBeanAutowiringSupport { SpitterService spitterService; public void addSpittle(Spittle spittle) { spitterService.saveSpittle(spittle); } public void deleteSpittle(long spittleld) { spitterService.deleteSpittle(spittleld); } public List<Spittle> getRecentSpittles(int spittleCount) { return SpitterService.getRecentSpittles(spittleCount); } public List<Spittle> getSpittlesForSpitter(Spitter spitter) { return spitterService.getSpittlesForSpitter(spitter); }} |
我们在SpitterService属性上使用@Autowired注解来表明它应该自动注入一个从Spring应用上下文中所获取的bean。在这里,端点委托注入的SpitterService来完成实际的工作。
导出独立的JAX-WS端点
正如我所说的,当对象的生命周期不是由Spring管理的,而对象的属性又需要注入Spring所管理的bean时,SpringBeanAutowiringSupport很有用。在合适场景下,还是可以把Spring管理的bean导出为JAX-WS端点的。
SpringSimpleJaxWsServiceExporter的工作方式很类似于本章前边所介绍的其他服务导出器。它把Spring管理的bean发布为JAXWS运行时中的服务端点。与其他服务导出器不同,SimpleJaxWsServiceExporter不需要为它指定一个被导出bean的引用,它会将使用JAX-WS注解所标注的所有bean发布为JAXWS服务。
SimpleJaxWsServiceExporter可以使用如下的@Bean方法来配置:
1 | SimpleJaxWsServiceExporter jaxWsExporter() { return new SimpleJaxWsServiceExporter();} |
正如我们所看到的,SimpleJaxWsServiceExporter不需要再做其他的事情就可以完成所有的工作。当启动的时候,它会搜索Spring应用上下文来查找所有使用@WebService注解的bean。当找到符合的bean时,SimpleJaxWsServiceExporter使用http://localhost:8080/ 地址将bean发布为JAX-WS端点。SpitterServiceEndpoint就是其中一个被查找到的bean。
程序清单15.3 SimpleJaxWsServiceExporter将bean转变为JAX-WS端点
1 | package com.habuma.spittr.remoting.jaxws;import java.util.List;import javax.jws.WebMethod;import javax.jws.WebService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Component;import com.habuma.spittr.domain.Spitter;import com.habuma.spittr.domain.Spittle;import com.habuma.spittr.service.SpitterService;public class SpitterServiceEndpoint { SpitterService SpitterService; public void addSpittle(Spittle spittle) { SpitterService.saveSpittle(spittle); } public void deleteSpittle(long spittleld) { spitterService.deleteSpittle(spittleld); ) public List<Spittle> getRecentSpittles(int spittleCount) { return SpitterService.getRecentSpittles(spittleCount); } public List<Spittle> getSpittlesForSpitter(Spitter spitter) { return SpitterService.getSpittlesForSpitter(spitter); }} |
我们注意到SpitterServiceEndpoint的新实现不再继承SpringBeanAutowiringSupport了。它完全就是一个Springbean,因此SpitterServiceEndpoint不需要继承任何特殊的支持类就可以实现自动装配。
因为SimpleJaxWsServiceEndpoint的默认基本地址为http://localhost:8080/,而SpitterServiceEndpoint使用了@Webservice(servicename="SpitterService")注解,所以这两个bean所形成的Web服务地址均为http://localhost:8080/SpitterService。但是我们可以完全控制服务URL,如果希望调整服务URL的话,我们可以调整基本地址。例如,如下SimpleJaxWsServiceEndpoint的配置把相同的服务端点发布到http://localhost:8888 /srvices/SpitterService。
1 | SimpleJaxWsServiceExporter jaxWsExporter() { SimpleJaxWsServiceExporter exporter = new SimpleJaxWsServiceExporter(); exporter.setBaseAddress("http://localhost:8888/services/");} |
SimpleJaxWsServiceEndpoint就像看起来那么简单,但是我们应该注意它只能用在支持将端点发布到指定地址的JAX-WS运行时中。这包含了Sun 1.6 JDK自带的JAX-WS运行时。其他的JAX-WS运行时,例如JAX-WS 2.1的参考实现,不支持这种类型的端点发布,因此也就不能使用SimpleJaxWsServiceEndpoint。
在客户端代理JAX-WS服务
使用Spring发布Web服务与我们使用RMI、Hessian、Burlap和HTTP invoker发布服务是有所不同的。但是我们很快就会发现,借助Spring使用Web服务所涉及的客户端代理的工作方式与基于Spring的客户端使用其他远程调用技术是相同的。
使用JaxWsProxyFactoryBean,我们可以在Spring中装配Spitter Web服务,与任意一个其他的bean一样。JaxWsProxyFactoryBean是Spring工厂bean,它能生成一个知道如何与SOAP Web服务交互的代理。所创建的代理实现了服务接口(如图15.10所示)。因此,JaxWsProxyFactoryBean让装配和使用一个远程Web服务变成了可能,就像这个远程Web服务是本地POJO一样。
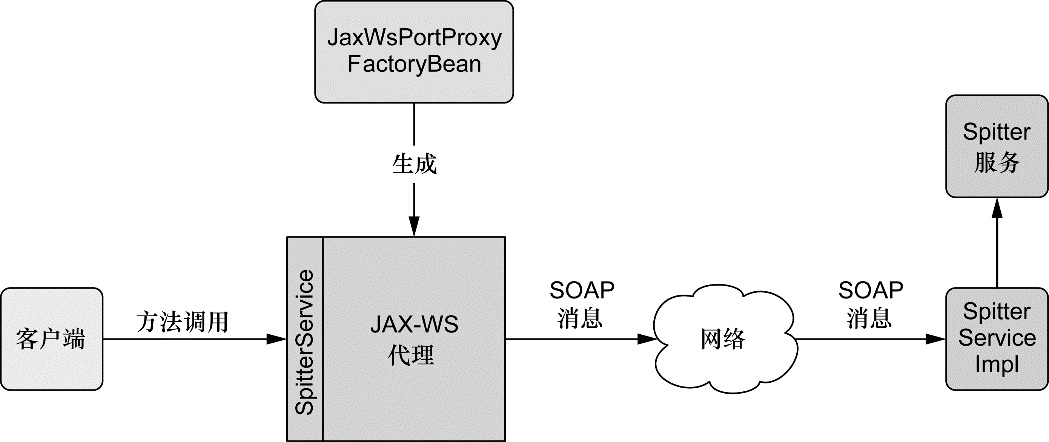
图15.10 JaxWsPortProxyFactoryBean生成可以与远程Web服务交互的代理。这些代理可以被装配到其他bean中,就像它们是本地POJO一样我们可以像下面这样配置JaxWsPortProxyFactoryBean来引用Spitter服务:
1 | JaxWsProxyFactoryBean spitterService() { JaxWsProxyFactoryBean proxy = new JaxWsProxyFactoryBean(); proxy.setWsdlDocument("http://localhost:8080/services/SpitterService?wsdl"); proxy.setServiceName("spitterService"); proxy.setPortName("spitterServiceHttpPort"); proxy.setServiceInterface(SpitterService.class); proxy.setNamespaceUrl("http://spitter.com"); return proxy;} |
我们可以看到,为JaxWsPortProxyFactoryBean设置几个属性就可以工作了。wsdlDocumentUrl属性标识了远程Web服务定义文件的位置。 JaxWsPortProxyFactory bean将使用这个位置上可用的WSDL来为服务创建代理。由JaxWsPortProxyFactoryBean所生成的代理实现了serviceInterface属性所指定的SpitterService接口。
剩下的三个属性的值通常可以通过查看服务的WSDL来确定。为了演示,我们假设为Spitter服务的WSDL如下所示:
1 | <wsdl:definitions targetNamespace="http://spitter.com">... <wsdl:service name="spitterService"> <wsdl:port name="spitterServiceHttpPort" binding="tns:spitterServiceHttpBinding">... </wsdl:port> </wsdl:service></wsdl:definitions> |
虽然不太可能这么做,但是在服务的WSDL中定义多个服务和端口是允许的。鉴于此,JaxWsPortProxyFactoryBean需要我们使用portName和serviceName属性指定端口和服务名称。WSDL中<wsdl:port>和<wsdl:service>元素的name属性可以帮助我们识别出这些属性该设置成什么。
最后,namespaceUri属性指定了服务的命名空间。命名空间将有助于JaxWsPortProxyFactoryBean去定位WSDL中的服务定义。正如端口和服务名一样,我们可以在WSDL中找到该属性的正确值。它通常会在wsdl:definitions的targetNamespace属性中。
小结
使用远程服务通常是一个乏味的苦差事,但是Spring提供了对远程服务的支持,让使用远程服务与使用普通的JavaBean一样简单。
在客户端,Spring提供了代理工厂bean,能让我们在Spring应用中配置远程服务。不管是使用RMI、Hessian、Burlap、Spring的HTTP invoker,还是Web服务,都可以把远程服务装配进我们的应用中,好像它们就是POJO一样。Spring甚至捕获了所有的RemoteExecption异常,并在发生异常的地方重新抛出运行期异常RemoteAccessException,让我们的代码可以从处理不可恢复的异常中解放出来。
即便Spring隐藏了远程服务的很多细节,让它们表现得好像是本地JavaBean一样,但是我们应该时刻谨记它们是远程服务的事实。远程服务,本质上来讲,通常比本地服务更低效。当编写访问远程服务的代码时,我们必须考虑到这一点,限制远程调用,以规避性能瓶颈。
在本章,我们看到了Spring是如何使用几种基本的远程调用技术来发布和使用服务的。尽管这些远程调用方案在分布式应用中很有价值,但这只是涉及面向服务架构(SOA)的一鳞半爪。
我们还了解了如何将bean导出为基于SOAP的Web服务。尽管这是开发Web服务的一种简单方式,但从架构角度来看,它可能不是最佳的选择。在下一章,我们将学习构建分布式应用的另一种选择,把应用暴露为RESTful资源。
使用 Spring MVC 创建 REST API
本章内容:
- 编写处理REST资源的控制器
- 以XML、JSON及其他格式来表述资源
- 使用REST资源
数据为王。
作为开发人员,我们经常关注于构建伟大的软件来解决业务问题。数据只是软件完成工作时要处理的原材料。但是如果你问一下业务人员,数据和软件谁更重要的话,他们很可能会选择数据。数据是许多业务的生命之血。软件通常是可以替换的,但是多年积累的数据是永远不能替换的。
你是不是觉得有些奇怪,既然数据如此重要,为何在开发软件的时候却经常将其视为事后才考虑的事情?以我们前面上一章所介绍的远程服务为例,这些服务是以操作和处理为中心的,而不是信息和资源。
近几年来,以信息为中心的表述性状态转移(Representational State Transfer,REST)已成为替换传统SOAP Web服务的流行方案。SOAP一般会关注行为和处理,而REST关注的是要处理的数据。
从Spring 3.0版本开始,Spring为创建REST API提供了良好的支持。Spring的REST实现在Spring 3.1、3.2和如今的4.0版本中不断得到发展。
好消息是Spring对REST的支持是构建在Spring MVC之上的,所以我们已经了解了许多在Spring中使用REST所需的知识。在本章中,我们将基于已了解的Spring MVC知识来开发处理RESTful资源的控制器。但在深入了解细节之前,先让我们看看使用REST到底是什么。
了解REST
我敢打赌这并不是你第一次听到或读到REST这个词。近些年来,关于REST已经有了许多讨论,在软件开发中你可能会发现有一种很流行的做法,那就是在推动REST替换SOAP Web服务的时候,会谈论到SOAP的不足。
诚然,对于许多应用程序而言,使用SOAP可能会有些大材小用了,而REST提供了一个更简单的可选方案。另外,很多的现代化应用都会有移动或富JavaScript客户端,它们都会使用运行在服务器上REST API。
问题在于并不是每个人都清楚REST到底是什么。结果就出现了许多误解。有很多打着REST幌子的事情其实并不符合REST真正的本意。在谈论Spring如何支持REST之前,我们需要对REST是什么达成共识。
REST的基础知识
当谈论REST时,有一种常见的错误就是将其视为“基于URL的Web服务”——将REST作为另一种类型的远程过程调用(remote procedure call,RPC)机制,就像SOAP一样,只不过是通过简单的HTTP URL来触发,而不是使用SOAP大量的XML命名空间。
恰好相反,REST与RPC几乎没有任何关系。RPC是面向服务的,并关注于行为和动作;而REST是面向资源的,强调描述应用程序的事物和名词。
为了理解REST是什么,我们将它的首字母缩写拆分为不同的构成部分:
- 表述性(Representational):REST资源实际上可以用各种形式来进行表述,包括XML、JSON(JavaScript Object Notation)甚至HTML——最适合资源使用者的任意形式;
- 状态(State):当使用REST的时候,我们更关注资源的状态而不是对资源采取的行为;
- 转移(Transfer):REST涉及到转移资源数据,它以某种表述性形式从一个应用转移到另一个应用。
更简洁地讲,REST就是将资源的状态以最适合客户端或服务端的形式从服务器端转移到客户端(或者反过来)。在REST中,资源通过URL进行识别和定位。至于RESTful URL的结构并没有严格的规则,但是URL应该能够识别资源,而不是简单的发一条命令到服务器上。再次强调,关注的核心是事物,而不是行为。
REST中会有行为,它们是通过HTTP方法来定义的。具体来讲,也就是GET、POST、PUT、DELETE、PATCH以及其他的HTTP方法构成了REST中的动作。这些HTTP方法通常会匹配为如下的CRUD动作:
- Create:POST
- Read:GET
- Update:PUT或PATCH
- Delete:DELETE
尽管通常来讲,HTTP方法会映射为CRUD动作,但这并不是严格的限制。有时候,PUT可以用来创建新资源,POST可以用来更新资源。实际上,POST请求非幂等性(non-idempotent)的特点使其成为一个非常灵活的方法,对于无法适应其他HTTP方法语义的操作,它都能够胜任。
基于对REST的这种观点,所以我尽量避免使用诸如REST服务、REST Web服务或类似的术语,这些术语会不恰当地强调行为。相反,我更愿意强调REST面向资源的本质,并讨论RESTful资源。
Spring是如何支持REST的
Spring很早就有导出REST资源的需求。从3.0版本开始,Spring针对Spring MVC的一些增强功能对REST提供了良好的支持。当前的4.0版本中,Spring支持以下方式来创建REST资源:
- 控制器可以处理所有的HTTP方法,包含四个主要的REST方法:GET、PUT、DELETE以及POST。Spring 3.2及以上版本还支持PATCH方法;
- 借助@PathVariable注解,控制器能够处理参数化的URL(将变量输入作为URL的一部分);
- 借助Spring的视图和视图解析器,资源能够以多种方式进行表述,包括将模型数据渲染为XML、JSON、Atom以及RSS的View实现;
- 可以使用ContentNegotiatingViewResolver来选择最适合客户端的表述;
- 借助@ResponseBody注解和各种HttpMethodConverter实现,能够替换基于视图的渲染方式;
- 类似地,@RequestBody注解以及HttpMethodConverter实现可以将传入的HTTP数据转化为传入控制器处理方法的Java对象;
- 借助RestTemplate,Spring应用能够方便地使用REST资源。
本章中,我们将会介绍Spring RESTful的所有特性,首先介绍如何借助Spring MVC生成资源。然后在16.4小节中,我们会转向REST的客户端,看一下如何使用这些资源。那么,就从了解RESTful Spring MVC控制器是什么样子开始吧。
创建第一个REST端点
借助Spring的支持来实现REST功能有一个很有利的地方,那就是我们已经掌握了很多创建RESTful控制器的知识。从第5章到第7章中,我学到了创建Web应用的知识,它们可以用在通过REST API暴露资源上。首先,我们会在名为SpittleApiController的新控制器中创建第一个REST端点。
如下的程序清单展现了这个新REST控制器起始的样子,它会提供Spittle资源。这是一个很简单的开始,但是在本章中,随着不断学习Spring REST编程模型的细节,我们将会不断构建这个控制器。
程序清单16.1 实现RESTful功能的Spring MVC控制器
1 | package spittr.api;import java.util.List;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Controller;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.web.bind.annotation.RequestParam;import spittr.Spittle;import spittr.data.SpittleRepository;public class SpittleController { private static final String MAX_LONG_AS_STRING = "9223372036854775807"; private SpittleRepository spittleRepository; public SpittleController(SpittleRepository spittleRepository) { this.spittleRepository = spittleRepository; } public List<Spittle> spittles( long max, int count) { return spittleRepository.findSpittles(max, count); }} |
让我们仔细看一下程序清单16.1。你能够看出来它服务于一个REST资源而不是Web页面吗?
可能看不出来!按照这个控制器的写法,并没有地方表明它是RESTful、服务于资源的控制器。实际上,你也许能够认出这个spittles()方法,我们曾经在第5章(5.3.1小节)见过它。
我们回忆一下,当发起对“/spittles”的GET请求时,将会调用spittles()方法。它会查找并返回Spittle列表,而这个列表会通过注入的SpittleRepository获取到。列表会放到模型中,用于视图的渲染。对于基于浏览器的Web应用,这可能意味着模型数据会渲染到HTML页面中。
但是,我们现在讨论的是创建REST API。在这种情况下,HTML并不是合适的数据表述形式。
表述是REST中很重要的一个方面。它是关于客户端和服务器端针对某一资源是如何通信的。任何给定的资源都几乎可以用任意的形式来进行表述。如果资源的使用者愿意使用JSON,那么资源就可以用JSON格式来表述。如果使用者喜欢尖括号,那相同的资源可以用XML来进行表述。同时,如果用户在浏览器中查看资源的话,可能更愿意以HTML的方式来展现(或者PDF、Excel及其他便于人类阅读的格式)。资源没有变化——只是它的表述方式变化了。
注意:尽管Spring支持多种资源表述形式,但是在定义REST API的时候,不一定要全部使用它们。对于大多数客户端来说,用JSON和XML来进行表述就足够了。
当然,如果内容要由人类用户来使用的话,那么我们可能需要支持HTML格式的资源。根据资源的特点和应用的需求,我们还可能选择使用PDF文档或Excel表格来展现资源。
对于非人类用户的使用者,比如其他的应用或调用REST端点的代码,资源表述的首选应该是XML和JSON。借助Spring同时支持这两种方案非常简单,所以没有必要做一个非此即彼的选择。
按照我的意见,我推荐至少要支持JSON。JSON使用起来至少会像XML一样简单(很多人会说JSON会更加简单),并且如果客户端是JavaScript(最近一段时间以来,这种做法越来越常见)的话,JSON更是会成为优胜者,因为在JavaScript中使用JSON数据根本就不需要编排和解排(marshaling/demarshaling)。
需要了解的是控制器本身通常并不关心资源如何表述。控制器以Java对象的方式来处理资源。控制器完成了它的工作之后,资源才会被转化成最适合客户端的形式。Spring提供了两种方法将资源的Java表述形式转换为发送给客户端的表述形式:
- 内容协商(Content negotiation):选择一个视图,它能够将模型渲染为呈现给客户端的表述形式;
- 消息转换器(Message conversion):通过一个消息转换器将控制器所返回的对象转换为呈现给客户端的表述形式。
鉴于我们在第5章和第6章中已经讨论过视图解析器,并且已经熟悉了基于视图的渲染(在第6章中),所以首先看一下如何使用内容协商来选择视图或视图解析器,它们将资源渲染为客户端能够接受的形式。
协商资源表述
你可以回忆一下在第5章中(以及图5.1所示),当控制器的处理方法完成时,通常会返回一个逻辑视图名。如果方法不直接返回逻辑视图名(例如方法返回void),那么逻辑视图名会根据请求的URL判断得出。DispatcherServlet接下来会将视图的名字传递给一个视图解析器,要求它来帮助确定应该用哪个视图来渲染请求结果。
在面向人类访问的Web应用程序中,选择的视图通常来讲都会渲染为HTML。视图解析方案是个简单的一维活动。如果根据视图名匹配上了视图,那这就是我们要用的视图了。
当要将视图名解析为能够产生资源表述的视图时,我们就有另外一个维度需要考虑了。视图不仅要匹配视图名,而且所选择的视图要适合客户端。如果客户端想要JSON,那么渲染HTML的视图就不行了——尽管视图名可能匹配。
Spring的ContentNegotiatingViewResolver是一个特殊的视图解析器,它考虑到了客户端所需要的内容类型。按照其最简单的形式,ContentNegotiatingViewResolver可以按照下述形式进行配置:
1 | ViewResolver cnViewResilver() { return new ContentNegotiatingViewResolver();} |
在这个简单的bean声明背后会涉及到很多事情。要理解ContentNegotiating-ViewResolver是如何工作的,这涉及内容协商的两个步骤:
- 确定请求的媒体类型;
- 找到适合请求媒体类型的最佳视图。
让我们深入了解每个步骤来了解ContentNegotiatingViewResolver是如何完成其任务的,首先从弄明白客户端需要什么类型的内容开始。
确定请求的媒体类型
在内容协商两步骤中,第一步是确定客户端想要什么类型的内容表述。表面上看,这似乎是一个很简单的事情。难道请求的Accept头部信息不是已经很清楚地表明要发送什么样的表述给客户端吗?
遗憾的是,Accept头部信息并不总是可靠的。如果客户端是Web浏览器,那并不能保证客户端需要的类型就是浏览器在Accept头部所发送的值。Web浏览器一般只接受对人类用户友好的内容类型(如text/html),所以没有办法(除了面向开发人员的浏览器插件)指定不同的内容类型。
ContentNegotiatingViewResolver将会考虑到Accept头部信息并使用它所请求的媒体类型,但是它会首先查看URL的文件扩展名。如果URL在结尾处有文件扩展名的话,ContentNegotiatingViewResolver将会基于该扩展名确定所需的类型。如果扩展名是“.json”的话,那么所需的内容类型必须是“application/json”。如果扩展名是“.xml”,那么客户端请求的就是“application/xml”。当然,“.html”扩展名表明客户端所需的资源表述为HTML(text/html)。
如果根据文件扩展名不能得到任何媒体类型的话,那就会考虑请求中的Accept头部信息。在这种情况下,Accept头部信息中的值就表明了客户端想要的MIME类型,没有必要再去查找了。
最后,如果没有Accept头部信息,并且扩展名也无法提供帮助的话,ContentNegotiatingViewResolver将会使用“/”作为默认的内容类型,这就意味着客户端必须要接收服务器发送的任何形式的表述。
一旦内容类型确定之后,ContentNegotiatingViewResolver就该将逻辑视图名解析为渲染模型的View。与Spring的其他视图解析器不同,ContentNegotiatingViewResolver本身不会解析视图。而是委托给其他的视图解析器,让它们来解析视图。
ContentNegotiatingViewResolver要求其他的视图解析器将逻辑视图名解析为视图。解析得到的每个视图都会放到一个列表中。这个列表装配完成后,ContentNegotiatingViewResolver会循环客户端请求的所有媒体类型,在候选的视图中查找能够产生对应内容类型的视图。第一个匹配的视图会用来渲染模型。
影响媒体类型的选择
在上述的选择过程中,我们阐述了确定所请求媒体类型的默认策略。但是通过为其设置一个ContentNegotiationManager,我们能够改变它的行为。借助ContentNegotiationManager我们所能做到的事情如下所示:
指定默认的内容类型,如果根据请求无法得到内容类型的话,将会使用默认值;
- 通过请求参数指定内容类型;
- 忽视请求的Accept头部信息;
- 将请求的扩展名映射为特定的媒体类型;
- 将JAF(Java Activation Framework)作为根据扩展名查找媒体类型的备用方案。
有三种配置ContentNegotiationManager的方法:
- 直接声明一个ContentNegotiationManager类型的bean;
- 通过ContentNegotiationManagerFactoryBean间接创建bean;
- 重载WebMvcConfigurerAdapter的configureContentNegotiation()方法。
直接创建ContentNegotiationManager有一些复杂,除非有充分的原因,否则我们不会愿意这样做。后两种方案能够让创建ContentNegotiationManager更加简单。
ContentNegotiationManager是在Spring 3.2中加入的
ContentNegotiationManager是Spring中相对比较新的功能,是在Spring 3.2中引入的。在Spring 3.2之前,ContentNegotiatingViewResolver的很多行为都是通过直接设置ContentNegotiatingViewResolver的属性进行配置的。从Spring 3.2开始,ContentNegotiatingViewResolver的大多数Setter方法都废弃了,鼓励通过ContentNegotiationManager来进行配置。
尽管我不会在本章中介绍配置ContentNegotiatingViewResolver的旧方法,但是我们在创建ContentNegotiationManager所设置的很多属性,在ContentNegotiatingViewResolver中都有对应的属性。如果你使用较早版本的Spring的话,应该能够很容易地将新的配置方式对应到旧配置方式中。
一般而言,如果我们使用XML配置ContentNegotiationManager的话,那最有用的将会是ContentNegotiationManagerFactoryBean。例如,我们可能希望在XML中配置ContentNegotiationManager使用“application/json”作为默认的内容类型:
1 | <bean id="contentNegotiotionManager" class="org.springframework.http.ContentNegotiationManagerFactoryBean" p:defaultContentType="application/json" /> |
因为ContentNegotiationManagerFactoryBean是FactoryBean的实现,所以它会创建一个ContentNegotiationManager bean。这个ContentNegotiationManager能够注入到ContentNegotiatingViewResolver的contentNegotiationManager属性中。
如果使用Java配置的话,获得ContentNegotiationManager的最简便方法就是扩展WebMvcConfigurerAdapter并重载configureContentNegotiation()方法。在创建Spring MVC应用的时候,我们很可能已经扩展了WebMvcConfigurerAdapter。例如,在Spittr应用中,我们已经有了WebMvcConfigurerAdapter的扩展类,名为WebConfig,所以需要做的就是重载configureContentNegotiation()方法。如下就是configureContentNegotiation()的一个实现,它设置了默认的内容类型:
1 | void configureContentNegotiation(ContentNegotiationConfigurer configurer) { configurer.defualtContentType(MediaType.APPLICATION_JSON);} |
我们可以看到,configureContentNegotiation()方法给定了一个ContentNegotiationConfigurer对象。ContentNegotiationConfigurer中的一些方法对应于
ContentNegotiationManager的Setter方法,这样我们就能在ContentNegotiation-Manager创建时,设置任意内容协商相关的属性。在本例中,我们调用defaultContentType()方法将默认的内容类型设置为“application/json”。
现在,我们已经有了ContentNegotiationManager bean,接下来就需要将它注入到ContentNegotiatingViewResolver的contentNegotiationManager属性中。这需要我们稍微修改一下之前声明ContentNegotiatingViewResolver的@Bean方法:
1 | ViewResolver cnViewResilver(ContentNegotiatingManager cnm) { ContentNegotiatingViewResolver cnvr = new ContentNegotiatingViewResolver(); cnvr.setContentNegotiation(cnm); return cnvr;} |
这个@Bean方法注入了ContentNegotiationManager,并使用它调用了setContentNegotiationManager()。这样的结果就是ContentNegotiatingView、Resolver将会使用ContentNegotiationManager所定义的行为。
配置ContentNegotiationManager有很多的细节,在这里无法对它们进行一一介绍。如下的程序清单是一个非常简单的配置样例,当我使用ContentNegotiatingViewResolver的时候,通常会采用这种用法:它默认会使用HTML视图,但是对特定的视图名称将会渲染为JSON输出。
程序清单16.2 配置ContentNegotiationManager
1 | ViewResolver cnViewResolver(ContentNegotiationManager cnm) { ContentNegotiatingViewResolver cnvr = new ContentNegotiatingViewResolver(); cnvr.setContentNegotiationManager(cnm); return cnvr;} void configureContentNegotiation(ContentNegotiationConfigurer configurer) { configurer.defaultContentType(MediaType.TEXT_HTML);} ViewResolver beanNameViewResolver() { return new BeanNameViewResolver();} View spittles() { return new MappingJackson2JsonView();} |
除了程序清单16.2中的内容以外,还应该有一个能够处理HTML的视图解析器(如InternalResourceViewResolver或TilesViewResolver)。在大多数场景下,ContentNegotiatingViewResolver会假设客户端需要HTML,如ContentNegotiationManager配置所示。但是,如果客户端指定了它想要JSON(通过在请求路径上使用“.json”扩展名或Accept头部信息)的话,那么ContentNegotiatingViewResolver将会查找能够处理JSON视图的视图解析器。
如果逻辑视图的名称为“spittles”,那么我们所配置的BeanNameViewResolver将会解析spittles()方法中所声明的View。这是因为bean名称匹配逻辑视图的名称。如果没有匹配的View的话,ContentNegotiatingViewResolver将会采用默认的行为,将其输出为HTML。
ContentNegotiatingViewResolver一旦能够确定客户端想要什么样的媒体类型,接下来就是查找渲染这种内容的视图。
ContentNegotiatingViewResolver的优势与限制
ContentNegotiatingViewResolver最大的优势在于,它在Spring MVC之上构建了REST资源表述层,控制器代码无需修改。相同的一套控制器方法能够为面向人类的用户产生HTML内容,也能针对不是人类的客户端产生JSON或XML。
如果面向人类用户的接口与面向非人类客户端的接口之间有很多重叠的话,那么内容协商是一种很便利的方案。在实践中,面向人类用户的视图与REST API在细节上很少能够处于相同的级别。如果面向人类用户的接口与面向非人类客户端的接口之间没有太多重叠的话,那么ContentNegotiatingViewResolver的优势就体现不出来了。
ContentNegotiatingViewResolver还有一个严重的限制。作为ViewResolver的实现,它只能决定资源该如何渲染到客户端,并没有涉及到客户端要发送什么样的表述给控制器使用。如果客户端发送JSON或XML的话,那么ContentNegotiatingViewResolver就无法提供帮助了。
ContentNegotiatingViewResolver还有一个相关的小问题,所选中的View会渲染模型给客户端,而不是资源。这里有个细微但很重要的区别。当客户端请求JSON格式的Spittle对象列表时,客户端希望得到的响应可能如下所示:
1 | [ { "id": 42, "latitude": 28.419489, "longitude": -81.581184, "message": "Hello World", "time": 140038920000 }, { "id": 43, "latitude": 28.419136, "longitude": -81.577225, "message": "Blast off!", "time": 140047560000 }] |
而模型是key-value组成的Map,那么响应可能会如下所示:
1 | { "spittleList": [ { "id": 42, "latitude": 28.419489, "longitude": -81.581184, "message": "Hello World", "time": 140038920000 }, { "id": 43, "latitude": 28.419136, "longitude": -81.577225, "message": "Blast off!", "time": 140047560000 } ]} |
尽管这不是很严重的问题,但确实可能不是客户端所预期的结果。因为有这些限制,我通常建议不要使用ContentNegotiatingViewResolver。我更加倾向于使用
Spring的消息转换功能来生成资源表述。接下来,我们看一下如何在控制器代码中使用Spring的消息转换器。
使用HTTP信息转换器
消息转换(message conversion)提供了一种更为直接的方式,它能够将控制器产生的数据转换为服务于客户端的表述形式。当使用消息转换功能时,DispatcherServlet不再需要那么麻烦地将模型数据传送到视图中。实际上,这里根本就没有模型,也没有视图,只有控制器产生的数据,以及消息转换器(message converter)转换数据之后所产生的资源表述。
Spring自带了各种各样的转换器,如表16.1所示,这些转换器满足了最常见的将对象转换为表述的需要。
例如,假设客户端通过请求的Accept头信息表明它能接受“application/json”,并且Jackson JSON在类路径下,那么处理方法返回的对象将交给MappingJacksonHttpMessageConverter,并由它转换为返回客户端的JSON表述形式。
另一方面,如果请求的头信息表明客户端想要“text/xml”格式,那么Jaxb2RootElementHttpMessageConverter将会为客户端产生XML响应。
注意,表16.2中的HTTP信息转换器除了其中的五个以外都是自动注册的,所以要使用它们的话,不需要Spring配置。但是为了支持它们,你需要添加一些库到应用程序的类路径下。例如,如果你想使用MappingJacksonHttpMessageConverter来实现JSON消息和Java对象的互相转换,那么需要将Jackson JSON Processor库添加到类路径中。类似地,如果你想使用Jaxb2RootElementHttpMessageConverter来实现XML消息和Java对象的互相转换,那么需要JAXB库。如果信息是Atom或RSS格式的话,那么Atom-FeedHttpMessageConverter和RssChannelHttpMessageConverter会需要Rome库。
表16.1 Spring提供了多个HTTP信息转换器,用于实现资源表述与各种Java类型之间的互相转换
| 信息转换器 | 描 述 |
|---|---|
| AtomFeedHttpMessageConverter | Rome Feed对象和Atom feed(媒体类型application/atom+xml)之间的互相转换。如果 Rome 包在类路径下将会进行注册 |
| BufferedImageHttpMessageConverter | BufferedImages与图片二进制数据之间互相转换 |
| ByteArrayHttpMessageConverter | 读取/写入字节数组。从所有媒体类型(*/*)中读取,并以application/octetstream格式写入 |
| FormHttpMessageConverter | 将application/x-www-form-urlencoded内容读入到MultiValueMap<String,String>中,也会将MultiValueMap<String,String>写入到application/x-www-form-urlencoded中或将MultiValueMap<String, Object>写入到multipart/form-data中 |
| Jaxb2RootElementHttpMessageConverter | 在XML(text/xml或application/xml)和使用JAXB2注解的对象间互相读取和写入。如果 JAXB v2 库在类路径下,将进行注册 |
| MappingJacksonHttpMessageConverter | 在JSON和类型化的对象或非类型化的HashMap间互相读取和写入。如果 Jackson JSON 库在类路径下,将进行注册 |
| MappingJackson2HttpMessageConverter | 在JSON和类型化的对象或非类型化的HashMap间互相读取和写入。如果 Jackson 2 JSON 库在类路径下,将进行注册 |
| MarshallingHttpMessageConverter | 使用注入的编排器和解排器(marshaller和unmarshaller)来读入和写入XML。支持的编排器和解排器包括Castor、JAXB2、JIBX、XMLBeans以及Xstream ResourceHttpMessageConverter 读取或写入Resource |
| RssChannelHttpMessageConverter | 在RSS feed和Rome Channel对象间互相读取或写入。如果 Rome 库在类路径下,将进行注册 |
| SourceHttpMessageConverter | 在XML和javax.xml.transform.Source对象间互相读取和写入。默认注册 |
| StringHttpMessageConverter | 将所有媒体类型(*/*)读取为String。将String写入为text/plain |
| XmlAwareFormHttpMessageConverter | FormHttpMessageConverter的扩展,使用SourceHttp MessageConverter来支持基于XML的部分 |
你可能已经猜到了,为了支持消息转换,我们需要对Spring MVC的编程模型进行一些小调整。
在响应体中返回资源状态
正常情况下,当处理方法返回Java对象(除String外或View的实现以外)时,这个对象会放在模型中并在视图中渲染使用。但是,如果使用了消息转换功能的话,我们需要告诉Spring跳过正常的模型/视图流程,并使用消息转换器。有不少方式都能做到这一点,但是最简单的方法是为控制器方法添加@ResponseBody注解。
重新看一下程序清单16.1中的spittles()方法,我们可以为其添加@ResponseBody注解,这样就能让Spring将方法返回的List
1 | public List<Spittle> spittles( long max, int count) { return spittleRepository.findSpittles(max, count);} |
@ResponseBody注解会告知Spring,我们要将返回的对象作为资源发送给客户端,并将其转换为客户端可接受的表述形式。更具体地讲,DispatcherServlet将会考虑到请求中Accept头部信息,并查找能够为客户端提供所需表述形式的消息转换器。
举例来讲,假设客户端的Accept头部信息表明它接受“application/json”,并且Jackson JSON库位于应用的类路径下,那么将会选择appingJacksonHttpMessageConverter或MappingJackson2HttpMessageConverter(这取决于类路径下是哪个版本的Jackson)。消息转换器会将控制器返回的Spittle列表转换为JSON文档,并将其写入到响应体中。响应大致会如下所示:
1 | [ { "id": 42, "latitude": 28.419489, "longitude": -81.581184, "message": "Hello World", "time": 140038920000 }, { "id": 43, "latitude": 28.419136, "longitude": -81.577225, "message": "Blast off!", "time": 140047560000 }] |
Jackson默认会使用反射
注意在默认情况下,Jackson JSON库在将返回的对象转换为JSON资源表述时,会使用反射。对于简单的表述内容来讲,这没有什么问题。但是如果你重构了Java类型,比如添加、移除或重命名属性,那么所产生的JSON也将会发生变化(如果客户端依赖这些属性的话,那客户端有可能会出错)。
但是,我们可以在Java类型上使用Jackson的映射注解,从而改变产生JSON的行为。这样我们就能更多地控制所产生的JSON,从而防止它影响到API或客户端。
Jackson映射注解的内容超出了本书的讨论范围,不过关于这个主题,在http://wiki.fasterxml.com/Jackson-Annotations上有一些有用的文档。
谈及Accept头部信息,请注意getSpitter()的@RequestMapping注解。在这里,我使用了produces属性表明这个方法只处理预期输出为JSON的请求。也就是说,这个方法只会处理Accept头部信息包含“application/json”的请求。其他任何类型的请求,即使它的URL匹配指定的路径并且是GET请求也不会被这个方法处理。这样的请求会被其他的方法来进行处理(如果存在适当方法的话),或者返回客户端HTTP 406(Not Acceptable)响应。
在请求体中接收资源状态
到目前为止,我们只关注了REST端点如何为客户端提供资源。但是REST并不是只读的,REST API也可以接受来自客户端的资源表述。
如果要让控制器将客户端发送的JSON和XML转换为它所使用的Java对象,那是非常不方便的。在处理逻辑离开控制器的时候,Spring的消息转换器能够将对象转换为表述——它们能不能在表述传入的时候完成相同的任务呢?
@ResponseBody能够告诉Spring在把数据发送给客户端的时候,要使用某一个消息器,与之类似,@RequestBody也能告诉Spring查找一个消息转换器,将来自客户端的资源表述转换为对象。例如,假设我们需要一种方式将客户端提交的新Spittle保存起来。我们可以按照如下的方式编写控制器方法来处理这种请求:
1 | public Spittle saveSpittle( Spittle spittle) { return spittleRepository.save(spittle);} |
如果忽略掉注解的话,那saveSpittle()是一个非常简单的方法。它接受一个Spittle对象作为参数,并使用SpittleRepository进行保存,最终返回spittleRepository.save()方法所得到的Spittle对象。
但是,通过使用注解,它会变得更加有意思也更加强大。@RequestMapping表明它只能处理“/spittles”(在类级别的@RequestMapping中进行了声明)的POST请求。POST请求体中预期要包含一个Spittle的资源表述。因为Spittle参数上使用了@RequestBody,所以Spring将会查看请求中的Content-Type头部信息,并查找能够将请求体转换为Spittle的消息转换器。
例如,如果客户端发送的Spittle数据是JSON表述形式,那么Content-Type头部信息可能就会是“application/json”。在这种情况下,DispatcherServlet会查找能够将JSON转换为Java对象的消息转换器。如果Jackson 2库在类路径中,那么MappingJackson2HttpMessageConverter将会担此重任,将JSON表述转换为Spittle,然后传递到saveSpittle()方法中。
这个方法还使用了@ResponseBody注解,因此方法返回的Spittle对象将会转换为某种资源表述,发送给客户端。
注意,@RequestMapping有一个consumes属性,我们将其设置为“application/ json”。consumes属性的工作方式类似于produces,不过它会关注请求的Content-Type头部信息。它会告诉Spring这个方法只会处理对“/spittles”的POST请求,并且要求请求的Content-Type头部信息为“application/json”。如果无
法满足这些条件的话,会由其他方法(如果存在合适的方法的话)来处理请求。
为控制器默认设置消息转换
当处理请求时,@ResponseBody和@RequestBody是启用消息转换的一种简洁和强大方式。但是,如果你所编写的控制器有多个方法,并且每个方法都需要信息转换功能的话,那么这些注解就会带来一定程度的重复性。
Spring 4.0引入了@RestController注解,能够在这个方面给我们提供帮助。如果在控制器类上使用@RestController来代替@Controller的话,Spring将会为该控制器的所有处理方法应用消息转换功能。我们不必为每个方法都添加@ResponseBody了。我们所定义的SpittleController可能就会如下所示:
程序清单16.3 使用@RestController注解
1 | package spittr.api;import java.util.List;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Controller;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.web.bind.annotation.RequestParam;import spittr.Spittle;import spittr.data.SpittleRepository;public class SpittleApiController { private static final String MAX_LONG_AS_STRING = "9223372036854775807"; private SpittleRepository spittleRepository; public SpittleApiController(SpittleRepository spittleRepository) { this.spittleRepository = spittleRepository; } public List<Spittle> spittles( long max, int count) { return spittleRepository.findSpittles(max, count); } public Spittle saveSpittle( Spittle spittle) { return spittleRepository.save(spittle); }} |
程序清单16.3的关键点在于代码中此时不包含什么。这两个处理器方法都没有使用@ResponseBody注解,因为控制器使用了@RestController,所以它的方法所返回的对象将会通过消息转换机制,产生客户端所需的资源表述。
到目前为止,我们看到了如何使用Spring MVC编程模型将RESTful资源发布到响应体之中。但是响应除了负载以外还会有其他的内容。头部信息和状态码也能够为客户端提供响应的有用信息。接下来,我们看一下在提供资源的时候,如何填充头部信息和设置状态码。
提供资源之外的其他内容
@ResponseBody提供了一种很有用的方式,能够将控制器返回的Java对象转换为发送到客户端的资源表述。实际上,将资源表述发送给客户端只是整个过程的一部分。一个好的REST API不仅能够在客户端和服务器之间传递资源,它还能够给客户端提供额外的元数据,帮助客户端理解资源或者在请求中出现了什么情况。
发送错误信息到客户端
例如,我们为SpittleController添加一个新的处理器方法,它会提供单个Spittle对象:
1 | public Spittle spittleById( long id) { return spittleRepository.findOne(id);} |
在这里,通过id参数传入了一个ID,然后根据它调用Repository的findOne()方法,查找Spittle对象。处理器方法会返回findOne()方法得到的Spittle对象,消息转换器会负责产生客户端所需的资源表述。
非常简单,对吧?我们没办法让它更棒了。它还能更好吗?
如果根据给定的ID,无法找到某个Spittle对象的ID属性能够与之匹配,findOne()方法返回null的时候,你觉得会发生什么呢?
结果就是spittleById()方法会返回null,响应体为空,不会返回任何有用的数据给客户端。同时,响应中默认的HTTP状态码是200(OK),表示所有的事情运行正常。
但是,所有的事情都是不对的。客户端要求Spittle对象,但是它什么都没有得到。它既没有收到Spittle对象也没有收到任何消息表明出现了错误。服务器实际上是在说:“这是一个没用的响应,但是能够告诉你一切都正常!”
现在,我们考虑一下在这种场景下应该发生什么。至少,状态码不应该是200,而应该是404(Not Found),告诉客户端它们所要求的内容没有找到。如果响应体中能够包含错误信息而不是空的话就更好了。
Spring提供了多种方式来处理这样的场景:
- 使用@ResponseStatus注解可以指定状态码;
- 控制器方法可以返回ResponseEntity对象,该对象能够包含更多响应相关的元数据;
- 异常处理器能够应对错误场景,这样处理器方法就能关注于正常的状况。
在这个方面,Spring提供了很多的灵活性,其实也不存在唯一正确的方式。我不会用某一种固定的策略来处理所有的错误或涵盖所有的场景,而是会向读者展现多种修改spittleById()的方法,以应对Spittle无法找到的场景。
使用ResponseEntity
作为@ResponseBody的替代方案,控制器方法可以返回一个ResponseEntity对象。ResponseEntity中可以包含响应相关的元数据(如头部信息和状态码)以及要转换成资源表述的对象。
因为ResponseEntity允许我们指定响应的状态码,所以当无法找到Spittle的时候,我们可以返回HTTP 404错误。如下是新版本的spittleById(),它会返回ResponseEntity:
1 | public Spittle spittleById( long id) { Spittle spittle = spittleRepository.findOne(id); HttpStatus status = spittle != null ? HttpStatus.OK : HttpStatus.NOT_FOUND; return new ResponseEntity<Spittle>(spittle, status);} |
像前面一样,路径中得到的ID用来从Repository中检索Spittle。如果找到的话,状态码设置为HttpStatus.OK(这是之前的默认值),但是如果Repository返回null的话,状态码设置为HttpStatus.NOT_FOUND,这会转换为HTTP 404。最后,会创建一个新的ResponseEntity,它会把Spittle和状态码传送给客户端。
注意这个spittleById()方法没有使用@ResponseBody注解。除了包含响应头信息、状态码以及负载以外,ResponseEntity还包含了@ResponseBody的语义,因此负载部分将会渲染到响应体中,就像之前在方法上使用@ResponseBody注解一样。如果返回ResponseEntity的话,那就没有必要在方法上使用@ResponseBody注解了。
我们在正确的方向上走出了第一步,如果所要求的Spittle无法找到的话,客户端能够得到一个合适的状态码。但是在本例中,响应体依然为空。我们可能会希望在响应体中包含一些错误信息。我们重试一次,首先定义一个包含错误信息的Error对象:
1 | public Error { private int code; private String message; public Error(int code, String message) { this.code = code; this.message = message; } public int getCode() { return code; } public int getMessage() { return message; }} |
然后,我们可以修改spittleById(),让它返回Error:
1 | public ResponseEntity<?> spittleById( long id) { Spittle spittle = spittleRepository.findOne(id); if (spittle == null) { Error error = new Error(4, "Spittle [" + id + "] not found"); return new ResponseEntity<Error>(error, HttpStatus.NOT_FOUND); } return new ResponseEntity<Spittle>(spittle, HttpStatus.OK);} |
现在,这个方法的行为已经符合我们的预期了。如果找到Spittle的话,就会把返回的对象以及200(OK)的状态码封装到ResponseEntity中。另一方面,如果findOne()返回null的话,将会创建一个Error对象,并将其与404(Not Found)状态码一起封装到ResponseEntity中,然后返回。
你也许觉得我们可以到此结束这个话题了。毕竟,方法按照我们期望的方式在运行。但是,还有一点事情让我不太舒服。
首先,这比我们开始的时候更为复杂。涉及到了更多的逻辑,包括条件语句。另外,方法返回ResponseEntity<?>感觉有些问题。ResponseEntity所使用的泛型为它的解析或出现错误留下了太多的空间。
不过,我们可以借助错误处理器来修正这些问题。
处理错误
spittleById()方法中的if代码块是处理错误的,但这是控制器中错误处理器(error handler)所擅长的领域。错误处理器能够处理导致问题的场景,这样常规的处理器方法就能只关心正常的逻辑处理路径了。
我们重构一下代码来使用错误处理器。首先,定义能够对应SpittleNotFoundException的错误处理器:
1 | public Error spittleNotFound(SpittleNotFoundException e) { long spittleId = e.getSpittleId(); return new Error(4, "Spittle [" + spittleId + "] not found");} |
@ExceptionHandler注解能够用到控制器方法中,用来处理特定的异常。这里,它表明如果在控制器的任意处理方法中抛出SpittleNotFoundException异常,就会调用spittleNotFound()方法来处理异常。
至于SpittleNotFoundException,它是一个很简单异常类:
1 | package spittr.data;public class SpittleNotFoundException extends RuntimeException { private static final long serialVersionUID = 1L; private long spittleId; public SpittleNotFoundException(long spittleId) { this.spittleId = spittleId; } public long getSpittleId() { return spittleId; } } |
现在,我们可以移除掉spittleById()方法中大多数的错误处理代码:
1 | public ResponseEntity<Spittle> spittleById( long id) { Spittle spittle = spittleRepository.findOne(id); if (spittle == null) { throw new SpittleNotFoundException(id); } return new ResponseEntity<Spittle>(spittle, HttpStatus.OK);} |
这个版本的spittleById()方法确实干净了很多。除了对返回值进行null检查,它完全关注于成功的场景,也就是能够找到请求的Spittle。同时,在返回类型中,我们能移除掉奇怪的泛型了。
不过,我们能够让代码更加干净一些。现在我们已经知道spittleById()将会返回Spittle并且HTTP状态码始终会是200(OK),那么就可以不再使用ResponseEntity,而是将其替换为@ResponseBody:
1 | public Spittle spittleById( long id) { Spittle spittle = spittleRepository.findOne(id); if (spittle == null) { throw new SpittleNotFoundException(id); } return spittle;} |
当然,如果控制器类上使用了@RestController,我们甚至不再需要@ResponseBody:
1 | public Spittle spittleById( long id) { Spittle spittle = spittleRepository.findOne(id); if (spittle == null) { throw new SpittleNotFoundException(id); } return spittle;} |
鉴于错误处理器的方法会始终返回Error,并且HTTP状态码为404(Not Found),那么现在我们可以对spittleNotFound()方法进行类似的清理:
1 | public Error spittleNotFound(SpittleNotFoundException e) { long spittleId = e.getSpittleId(); return new Error(4, "Spittle [" + spittleId + "] not found");} |
因为spittleNotFound()方法始终会返回Error,所以使用ResponseEntity的唯一原因就是能够设置状态码。但是通过为spittleNotFound()方法添加@ResponseStatus(HttpStatus.NOT_FOUND)注解,我们可以达到相同的效果,而且可以不再使用ResponseEntity了。
同样,如果控制器类上使用了@RestController,那么就可以移除掉@ResponseBody,让代码更加干净:
1 | public Error spittleNotFound(SpittleNotFoundException e) { long spittleId = e.getSpittleId(); return new Error(4, "Spittle [" + spittleId + "] not found");} |
在一定程度上,我们已经圆满达到了想要的效果。为了设置响应状态码,我们首先使用ResponseEntity,但是稍后我们借助异常处理器以及@ResponseStatus,避免使用ResponseEntity,从而让代码更加整洁。
似乎,我们不再需要使用ResponseEntity了。但是,有一种场景ResponseEntity能够很好地完成,但是其他的注解或异常处理器却做不到。现在,我们看一下如何在响应中设置头部信息。
在响应中设置头部信息
在saveSpittle()方法中,我们在处理POST请求的过程中创建了一个新的Spittle资源。但是,按照目前的写法(参考程序清单16.3),我们无法准确地与客户端交流。
在saveSpittle()处理完请求之后,服务器在响应体中包含了Spittle的表述以及HTTP状态码200(OK),将其返回给客户端。这里没有什么大问题,但是还不是完全准确。
当然,假设处理请求的过程中成功创建了资源,状态可以视为OK。但是,我们不仅仅需要说“OK”。我们创建了新的内容,HTTP状态码也将这种情况告诉给了客户端。不过,HTTP 201不仅能够表明请求成功完成,而且还能描述创建了新资源。如果我们希望完整准确地与客户端交流,那么响应是不是应该为201(Created),而不仅仅是200(OK)呢?
根据我们目前所学到的知识,这个问题解决起来很容易。我们需要做的就是为saveSpittle()方法添加@ResponseStatus注解,如下所示:
1 | public Spittle saveSpittle( Spittle spittle) { return spittleRepository.save(spittle);} |
这应该能够完成我们的任务,现在状态码能够精确反应发生了什么情况。它告诉客户端我们新创建了资源。问题已经得以解决!
但这只是问题的一部分。客户端知道新创建了资源,你觉得客户端会不会感兴趣新创建的资源在哪里呢?毕竟,这是一个新创建的资源,会有一个新的URL与之关联。难道客户端只能猜测新创建资源的URL是什么吗?我们能不能以某种方式将其告诉客户端?
当创建新资源的时候,将资源的URL放在响应的Location头部信息中,并返回给客户端是一种很好的方式。因此,我们需要有一种方式来填充响应头部信息,此时我们的老朋友ResponseEntity就能提供帮助了。如下的程序清单展现了一个新版本的saveSpittle(),它会返回ResponseEntity用来告诉客户端新创建的资源。
程序清单16.4 当返回ResponseEntity时,在响应中设置头部信息
1 | public ResponseEntity<Spittle> saveSpittle( Spittle spittle) { Spittle spittle = spittleRepository.save(spittle); HttpHeaders headers = new HttpHeaders(); URI locationUri = URI.create("http://localhost:8080/spittr/spittles" + spittle.getId()); headers.setLocation(locationUri); ResponseEntity<Spittle> responseEntity = new ResponseEntity<Spittle>(spittle, headers, HttpStatus.CREATED); return responseEntity; } |
在这个新的版本中,我们创建了一个HttpHeaders实例,用来存放希望在响应中包含的头部信息值。HttpHeaders是MultiValueMap<String, String>的特殊实现,它有一些便利的Setter方法(如setLocation()),用来设置常见的HTTP头部信息。在得到新创建Spittle资源的URL之后,接下来使用这个头部信息来创建ResponseEntity。
哇!原本简单的saveSpittle()方法瞬间变得臃肿了。但是,更值得关注的是,它使用硬编码值的方式来构建Location头部信息。URL中“localhost”以及“8080”这两个部分尤其需要注意,因为如果我们将应用部署到其他地方,而不是在本地运行的话,它们就不适用了。
我们其实没有必要手动构建URL,Spring提供了UriComponentsBuilder,可以给我们一些帮助。它是一个构建类,通过逐步指定URL中的各种组成部分(如host、端口、路径以及查询),我们能够使用它来构建UriComponents实例。借助UriComponentsBuilder所构建的UriComponents对象,我们就能获得适合设置给Location头部信息的URI。
为了使用UriComponentsBuilder,我们需要做的就是在处理器方法中将其作为一个参数,如下面的程序清单所示。
程序清单16.5 使用UriComponentsBuilder来构建Location URI
1 | public ResponseEntity<Spittle> saveSpittle( Spittle spittle, UriComponentsBuilder ucb) { Spittle saved = spittleRepository.save(spittle); HttpHeaders headers = new HttpHeaders(); URI locationUri = ucb.path("/spittles/") .path(String.valueOf(saved.getId())) .build() .toUri(); headers.setLocation(locationUri); ResponseEntity<Spittle> responseEntity = new ResponseEntity<Spittle>(saved, headers, HttpStatus.CREATED); return responseEntity;} |
在处理器方法所得到的UriComponentsBuilder中,会预先配置已知的信息如host、端口以及Servlet内容。它会从处理器方法所对应的请求中获取这些基础信息。基于这些信息,代码会通过设置路径的方式构建UriComponents其余的部分。
注意,路径的构建分为两步。第一步调用path()方法,将其设置为“/ spittles/”,也就是这个控制器所能处理的基础路径。然后,在第二次调用path()的时候,使用了已保存Spittle的ID。我们可以推断出来,每次调用path()都会基于上次调用的结果。在路径设置完成之后,调用build()方法来构建UriComponents对象,根据这个对象调用toUri()就能得到新创建Spittle的URI。
在REST API中暴露资源只代表了会话的一端。如果发布的API没有人关心和使用的话,那也没有什么价值。通常来讲,移动或JavaScript应用会是REST API的客户端,但是Spring应用也完全可以使用这些资源。我们换个方向,看一下如何编写Spring代码实现RESTful交互的客户端。
编写REST客户端
作为客户端,编写与REST资源交互的代码可能会比较乏味,并且所编写的代码都是样板式的。例如,假设我们需要借助Facebook的Graph API,编写方法来获取某人的Facebook基本信息。不过,获取基本信息的代码会有点复杂,如下面的程序清单所示。
程序清单16.6 使用Apache HTTP Client获取Facebook中的个人基本信息
1 | public Profile fetchFacebookProfile(String id) { try { HttpClient client = HttpClients.createDefault(); HttpGet request = new HttpGet("http://graph.facebook.com/" + id); request.setHeader("Accept", "application/json"); HttpResponse response = client.execute(request); HttpEntity entity = response.getEntity(); ObjectMapper mapper = new ObjectMapper(); return mapper.readValue(entity.getContent(), Profile.class); } catch (IOException e) { throw new RuntimeException(e); }} |
你可以看到,在使用REST资源的时候涉及很多代码。这里我甚至还偷懒使用了Jakarta Commons HTTP Client发起请求并使用Jackson JSON processor解析响应。
仔细看一下fetchFacebookProfile()方法,你可能会发现方法中只有少量代码与获取Facebook个人信息直接相关。如果你要编写另一个方法来使用其他的REST资源,很可能会有很多代码是与fetchFacebookProfile()相同的。
另外,还有一些地方可能会抛出的IOException异常。因为IOException是检查型异常,所以要么捕获它,要么抛出它。在本示例中,我选择捕获它并在它的位置重新抛出一个非检查型异常RuntimeException。
鉴于在资源使用上有如此之多的样板代码,你可能会觉得最好的方式是封装通用代码并参数化可变的部分。这正是Spring的RestTemplate所做的事情。就像 JdbcTemplate处理了JDBC数据访问时的丑陋部分,RestTemplate让我们在使用RESTful资源时免于编写那些乏味的代码。
稍后,我们将会看到如何借助RestTemplate重写fetchFacebookProfile()方法,这会戏剧性的简化该方法并消除掉样板式代码。但首先,让我们整体了解一下RestTemplate提供的所有REST操作。
了解RestTemplate的操作
RestTemplate定义了36个与REST资源交互的方法,其中的大多数都对应于HTTP的方法。但是,在本章中我没有足够的篇幅涵盖所有的36个方法。其实,这里面只有11个独立的方法,其中有十个有三种重载形式,而第十一个则重载了六次,这样一共形成了36个方法。表16.2描述了RestTemplate所提供的11个独立方法。除了TRACE以外,RestTemplate涵盖了所有的HTTP动作。除此之外,execute()和exchange()提供了较低层次的通用方法来使用任意的HTTP方法。
表16.2中的大多数操作都以三种方法的形式进行了重载:
- 一个使用java.net.URI作为URL格式,不支持参数化URL;
- 一个使用String作为URL格式,并使用Map指明URL参数;
- 一个使用String作为URL格式,并使用可变参数列表指明URL参数。
明确了RestTemplate所提供的11个操作以及各个变种如何工作之后,你就能以自己的方式编写使用REST资源的客户端了。我们通过对四个主要HTTP方法的支持(也就是GET、PUT、DELETE和POST)来研究RestTemplate的操作。我们从GET方法的getForObject()和getForEntity()开始。
表16.2 RestTemplate定义了11个独立的操作,而每一个都有重载,这样一共是36个方法
| 方 法 | 描 述 |
|---|---|
| delete() | 在特定的URL上对资源执行HTTP DELETE操作 |
| exchange() | 在URL上执行特定的HTTP方法,返回包含对象的ResponseEntity,这个对象是从响应体中映射得到的 |
| execute() | 在URL上执行特定的HTTP方法,返回一个从响应体映射得到的对象 |
| getForEntity() | 发送一个HTTP GET请求,返回的ResponseEntity包含了响应体所映射成的对象 |
| getForObject() | 发送一个HTTP GET请求,返回的请求体将映射为一个对象 |
| headForHeaders() | 发送HTTP HEAD请求,返回包含特定资源URL的HTTP头 |
| optionsForAllow() | 发送HTTP OPTIONS请求,返回对特定URL的Allow头信息 |
| postForEntity() | POST数据到一个URL,返回包含一个对象的ResponseEntity,这个对象是从响应体中映射得到的 |
| postForLocation() | POST数据到一个URL,返回新创建资源的URL |
| postForObject() | POST数据到一个URL,返回根据响应体匹配形成的对象 |
| put() | PUT资源到特定的URL |
GET资源
你可能意识到在表16.2中列出了两种执行GET请求的方法:getForObject()和getForEntity()。正如之前所描述的,每个方法又有三种形式的重载。三个getForObject()方法的签名如下:
1 | <T> T getForObject(URI url, Class<T> responseType) throws RestClientException;<T> T getForObject(String url, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> T getForObject(String url, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException; |
类似地,getForEntity()方法的签名如下:
1 | <T> ResponseEntity<T> getForEntity(URI url, Class<T> responseType) throws RestClientException;<T> ResponseEntity<T> getForEntity(String url, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> ResponseEntity<T> getForEntity(String url, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException; |
除了返回类型,getForEntity()方法就是getForObject()方法的镜像。实际上,它们的工作方式大同小异。它们都执行根据URL检索资源的GET请求。它们都将资源根据responseType参数匹配为一定的类型。唯一的区别在于getForObject()只返回所请求类型的对象,而getForEntity()方法会返回请求的对象以及响应相关的额外信息。
让我们首先看一下稍微简单的getForObject()方法。然后再看看如何使用getForEntity()方法来从GET响应中获取更多的信息。
检索资源
getForObject()方法是检索资源的合适选择。我们请求一个资源并按照所选择的Java类型接收该资源。作为getForObject()能够做什么的一个简单示例,让我们看一
下fetchFacebookProfile()的另一个实现:
1 | public Profile fetchFacebookProfile(String id) { RestTemplate rest = new RestTemplate(); return rest.getForObject("http://graph.facebook.com/{spitter}", Profile.class, id);} |
在程序清单11.5中,fetchFacebookProfile()涉及十多行代码。通过使用RestTemplate,现在减少到了几行(如果我不是为了适应本书页面的边界,可能会更少)。
fetchFacebookProfile()首先构建了一个RestTemplate的实例(另一种可行的方式是注入实例)。接下来,它调用了getForObject()来得到Facebook个人信息。为了做到这一点,它要求结果是Profile对象。在接收到Profile对象后,该方法将其返回给调用者。
注意,在这个新版本的fetchFacebookProfile ()中,我们没有使用字符串连接来构建URL,而是利用了RestTemplate可以接受参数化URL这一功能。URL中的{id}占位符最终将会用方法的id参数来填充。getForObject()方法的最后一个参数是大小可变的参数列表,每个参数都会按出现顺序插入到指定URL的占位符中。
另外一种替代方案是将id参数放到Map中,并以id作为key,然后将这个Map作为最后一个参数传递给getForObject():
1 | public Profile fetchFacebookProfile(String id) { Map<String, String> urlVariable = new HashMap<String, String>(); urlVariable.put("id", id); RestTemplate rest = new RestTemplate(); return rest.getForObject("http://graph.facebook.com/{spitter}", Profile.class, urlVariable);} |
这里没有任何形式的JSON解析和对象映射。在表面之下,getForObject()为我们将响应体转换为对象。它实现这些需要依赖表16.1中所列的HTTP消息转换器,与带有@ResponseBody注解的Spring MVC处理方法所使用的一样。
这个方法也没有任何异常处理。这不是因为getForObject()不能抛出异常,而是因为它抛出的异常都是非检查型的。如果在getForObject()中有错误,将抛出非检查型RestClientException异常(或者它的一些子类)。如果愿意的话,你可以捕获它——但编译器不会强制你捕获它。
抽取响应的元数据
作为getForObject()的一个替代方案,RestTemplate还提供了getForEntity()。getForEntity()方法与getForObject()方法的工作很相似。getForObject()只返回资源(通过HTTP信息转换器将其转换为Java对象),getForEntity()会在ResponseEntity中返回相同的对象,而且ResponseEntity还带有关于响应的额外信息,如HTTP状态码和响应头。
我们可能想使用ResponseEntity所做的事就是获取响应头的一个值。例如,假设除了获取资源,还想要知道资源的最后修改时间。假设服务端在LastModified头部信息中提供了这个信息,我们可以这样像这样使用getHeaders()方法:
1 | Date lastModified = new Date(response.getHeaders().getLastModified()); |
getHeaders()方法返回一个HttpHeaders对象,该对象提供了多个便利的方法来查询响应头,包括getLastModified(),它将返回从1970年1月1日开始的毫秒数。
除了getLastModified(),HttpHeaders还包含如下的方法来获取头信息:
1 | public List<MediaType> getAccept{) { ...}public List<Charset> getAcceptCharset() { ...}public Set<HttpMethod> getAllow() { ...} public String getCacheControl{) { ...}public List<String> getConnection() { ...}public long getContentLength() { ...}public MediaType getContentType() { ...} public long getDate() ( ...) public String getETagO { ...} public long getExpires() { ...}public long getlfNotModifiedSince() { ...}public List<String> getlfNoneMatch() { ...} public long getLastModified() { ...}public URI getLocation() { ...}public String getOrigin{) { ...} public String getPragma{) { ...} public String getUpgrade() { ...} |
为了实现更通用的HTTP头信息访问,HttpHeaders提供了get()方法和getFirst()方法。两个方法都接受String参数来标识所需要的头信息。get()将会返回一个String值的列表,其中的每个值都是赋给该头部信息的,而getFirst()方法只会返回第一个头信息的值。
如果你对响应的HTTP状态码感兴趣,那么你可以调用getStatusCode()方法。例如,考虑下面这个获取Spittle对象的方法:
1 | public Spittle fetchSpittle(String id) { RestTemplate rest = new RestTemplate(); ResponseEntity<Spittle> response = rest.getForEntity( "http://localhost:8080/spittr-api/spittles/{id}", Spittle.class, id); if (response.getStatusCode() == HttpStatus.NOT_MODIFIED) { throw new NotModifiedException(); } return response.getBody();} |
在这里,如果服务器响应304状态,这意味着服务器端的内容自从上一次请求之后再也没有修改。在这种情况下,将会抛出自定义的NotModifiedException异常来表明客户端应该检查它的缓存来获取Spittle。
PUT资源
为了对数据进行PUT操作,RestTemplate提供了三个简单的put()方法。就像其他的RestTemplate方法一样,put()方法有三种形式:
1 | void put(String url, Object request, Object... uriVariables) throws RestClientException;void put(String url, Object request, Map<String, ?> uriVariables) throws RestClientException;void put(URI url, Object request) throws RestClientException; |
按照它最简单的形式,put()接受一个java.net.URI,用来标识(及定位)要将资源发送到服务器上,另外还接受一个对象,这代表了资源的Java表述。
例如,以下展现了如何使用基于URI版本的put()方法来更新服务器上的Spittle资源:
1 | public void updateSpittle(Spittle spittle) throws SpitterException { RestTemplate rest = new RestTemplate(); String url = "http://localhost:8080/spittr-api/spittles/" + spittle.getId(); rest.put(URI.create(url), spittle);} |
在这里,尽管方法签名很简单,但是使用java.net.URI作为参数的影响很明显。为了创建所更新Spittle对象的URL,我们要进行字符串拼接。
从getForObject()和getForEntity()方法中我们也看到了,使用基于String的其他put()方法能够为我们减少创建URI的不便。这些方法可以将URI指定为模板并对可变部分插入值。以下是使用基于String的put()方法重写的updateSpittle():
1 | public void updateSpittle(Spittle spittle) throws SpitterException { RestTemplate rest = new RestTemplate(); rest.put("http://localhost:8080/spittr-api/spittles/{id}", spittle, spittle.getId());} |
现在的URI使用简单的String模板来进行表示。当RestTemplate发送PUT请求时,URI模板将{id}部分用spittle.getId()方法的返回值来进行替换。就像getForObject()和getForEntity()一样,这个版本的put()方法最后一个参数是大小可变的参数列表,每一个值会出现按照顺序赋值给占位符变量。
你还可以将模板参数作为Map传递进来:
1 | public void updateSpittle(Spittle spittle) throws SpitterException { RestTemplate rest = new RestTemplate(); Map<String, String> params = new HashMap<String, String>(); params.put("id", spittle.getId()); rest.put("http://localhost:8080/spittr-api/spittles/{id}", spittle, params);} |
当使用Map来传递模板参数时,Map条目的每个key值与URI模板中占位符变量的名字相同。
在所有版本的put()中,第二个参数都是表示资源的Java对象,它将按照指定的URI发送到服务器端。在本示例中,它是一个Spittle对象。RestTemplate将使用表16.1中的某个HTTP消息转换器将Spittle对象转换为一种表述形式,并在请求体中将其发送到服务器端。
对象将被转换成什么样的内容类型很大程度上取决于传递给put()方法的类型。如果给定一个String值,那么将会使用StringHttpMessageConverter:这个值直接被写到请求体中,内容类型设置为“text/plain”。如果给定一个MultiValueMap<String,String>,那么这个Map中的值将会被FormHttpMessageConverter以“application/x-wwwform-urlencoded”的格式写到请求体中。
因为我们传递进来的是Spittle对象,所以需要一个能够处理任意对象的信息转换器。如果在类路径下包含Jackson 2库,那么MappingJacksonHttpMessageConverter将以application/json格式将Spittle写到请求中。
DELETE资源
当你不需要在服务端保留某个资源时,那么可能需要调用RestTemplate的delete()方法。就像PUT方法那样,delete()方法有三个版本,它们的签名如下:
1 | void delete(String url, Object... uriVariables) throws RestClientException;void delete(String url, Map<String, ?> uriVariables) throws RestClientException;void delete(URI url) throws RestClientException; |
很容易吧,delete()方法是所有RestTemplate方法中最简单的。你唯一要提供的就是要删除资源的URI。例如,为了删除指定ID的Spittle,你可以这样调 delete():
1 | public void deleteSpittle(long id) { RestTemplate rest = new RestTemplate(); rest.delete(URI.create("http://localhost:8080/spittr-api/spittles/" + id));} |
这很简单,但在这里我们还是依赖字符串连接来创建URI对象。所以,我们再看一个更简单的delete()方法,它能够使得我们免于这些麻烦:
1 | public void deleteSpittle(long id) { RestTemplate rest = new RestTemplate(); rest.delete("http://localhost:8080/spittr-api/spittles/{id}", id);} |
你看,我感觉好多了。你呢?
现在我已经为你展现了最简单的RestTemplate方法,让我们看看RestTemplate最多样化的一组方法——它们能够支持HTTPPOST请求。
POST资源数据
在16.2节的表中,你会看到RestTemplate有三个不同类型的方法来发送POST请求。当你再乘上每个方法的三个不同变种,那就是有九个方法来POST数据到服务器端。
这些方法中有两个的名字看起来比较类似。postForObject()和postForEntity()对POST请求的处理方式与发送GET请求的getForObject()和getForEntity()方法是类似的。另一个方法是getForLocation(),它是POST请求所特有的。
在POST请求中获取响应对象
假设你正在使用RestTemplate来POST一个新的Spitter对象到Spittr应用程序的REST API。因为这是一个全新的Spitter,服务端并(还)不知道它。因此,它还不是真正的REST资源,也没有URL。另外,在服务端创建之前,客户端并不知道Spitter的ID。
POST资源到服务端的一种方式是使用RestTemplate的postForObject()方法。postForObject()方法的三个变种签名如下:
1 | <T> T postForObject(String url, Object request, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> T postForObject(String url, Object request, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException;<T> T postForObject(URI url, Object request, Class<T> responseType) throws RestClientException; |
在所有情况下,第一个参数都是资源要POST到的URL,第二个参数是要发送的对象,而第三个参数是预期返回的Java类型。在将URL作为String类型的两个版本中,第四个参数指定了URL变量(要么是可变参数列表,要么是一个Map)。
当POST新的Spitter资源到Spitter REST API时,它们应该发送到http://localhost:8080/spittr-api/spitters,这里会有一个应对POST请求的处理方法来保存对象。因为这个URL不需要URL参数,所以我们可以使用任何版本的postForObject()。但为了保持尽可能简单,我们可以这样调用:
1 | public Spitter postSpitterForObject(Spitter spitter) { RestTemplate rest = new RestTemplate(); return rest.postForObject("http://localhost:8080/spittr-api/spitters", spitter, Spitter.class);} |
postSpitterForObject()方法给定了一个新创建的Spitter对象,并使用postForObject()将其发送到服务器端。在响应中,它接收到一个Spitter对象并将其返回给调用者。
就像getForEntity()方法一样,你可能想得到请求带回来的一些元数据。在这种情况下,postForEntity()是更合适的方法。postForEntity()方法有着与postForObject()几乎相同的一组签名:
1 | <T> ResponseEntity<T> postForEntity(String url, Object request, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> ResponseEntity<T> postForEntity(String url, Object request, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException;<T> ResponseEntity<T> postForEntity(URI url, Object request, Class<T> responseType) throws RestClientException; |
假设除了要获取返回的Spitter资源,还要查看响应中Location头信息的值。在这种情况下,你可以这样调用postForEntity():
1 | RestTemplate rest = new RestTemplate();ResponseEntity<Spitter> response = rest.postForEntity( "http://localhost:8080/spittr-api/spitters", spitter, Spitter.class);Spitter spitter = response.getBody();URI url = response.getHeaders().getLocation(); |
与getForEntity()方法一样,postForEntity()返回一个ResponseEntity
在POST请求后获取资源位置
如果要同时接收所发送的资源和响应头,postForEntity()方法是很便利的。但通常你并不需要将资源发送回来(毕竟,将其发送到服务器端是第一位的)。如果你真正需要的是Location头信息的值,那么使用RestTemplate的postForLocation()方法会更简单。
类似于其他的POST方法,postForLocation()会在POST请求的请求体中发送一个资源到服务器端。但是,响应不再是相同的资源对象,postForLocation()的响应是新创建资源的位置。它有如下三个方法签名:
1 | URI postForLocation(String url, Object request, Object... uriVariables) throws RestClientException;URI postForLocation(String url, Object request, Map<String, ?> uriVariables) throws RestClientException;URI postForLocation(URI url, Object request) throws RestClientException; |
为了展示postForLocation(),让我们再次POST一个Spitter。这次,我们希望在返回中包含资源的URL:
1 | public String postSpitter(Spitter spitter) { RestTemplate rest = new RestTemplate(); return rest.postForLocation("http://localhost:8080/spittr-api/spitters", spitter).toString();} |
在这里,我们以String的形式将目标URL传递进来,还有要POST的Spitter对象(在本示例中没有URL参数)。在创建资源后,如果服务端在响应的Location头信息中返回新资源的URL,接下来postForLocation()会以String的格式返回该URL。
交换资源
到目前为止,我们已经看到RestTemplate的各种方法来GRT、PUT、DELETE以及POST资源。在它们之中,我们看到两个特殊的方法:getForEntity()和postForEntity(),这两个方法将结果资源包含在一个ResponseEntity对象中,通过这个对象我们可以得到响应头和状态码。
能够从响应中读取头信息是很有用的。但是如果你想在发送给服务端的请求中设置头信息的话,怎么办呢?这就是RestTemplate的exchange()的用武之地。
像RestTemplate的其他方法一样,exchange()也重载为三个签名格式。一个使用java.net.URI来标识目标URL,而其他两个以String的形式传入URL并带有URL变量。如下所示:
1 | <T> ResponseEntity<T> exchange(URI url, HttpMethod method, HttpEntity<?> requestEntity, Class<T> responseType) throws RestClientException;<T> ResponseEntity<T> exchange(String url, HttpMethod method, HttpEntity<?> requestEntity, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> ResponseEntity<T> exchange(String url, HttpMethod method, HttpEntity<?> requestEntity, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException; |
exchange()方法使用HttpMethod参数来表明要使用的HTTP动作。根据这个参数的值,exchange()能够执行与其他RestTemplate方法一样的工作。
例如,从服务器端获取Spitter资源的一种方式是使用RestTemplate的getForEntity()方法,如下所示:
1 | ResponseEntity<Spitter> response = rest.getForEntity( "http://localhost:8080/spittr-api/spitters/{spitter}", Spitter.class, spitterId);Spitter spitter = response.getBody(); |
在下面的代码片段中,可以看到exchange()也可以完成这项任务:
1 | ResponseEntity<Spitter> response = rest.exchange( "http://localhost:8080/spittr-api/spitters/{spitter}", HttpMethod.GET, null, Spitter.class, spitterId);Spitter spitter = response.getBody(); |
通过传入HttpMethod.GET作为HTTP动作,我们会要求exchange()发送一个GET请求。第三个参数是用于在请求中发送资源的,但因为这是一个GET请求,它可以是null。下一个参数表明我们希望将响应转换为Spitter对象。最后一个参数用于替换URL模板中{spitter}占位符的值。
按照这种方式,exchange()与之前使用的getForEntity()是几乎相同的,但是,不同于getForEntity()——或getForObject()——exchange()方法允许在请求中设置头信息。接下来,我们不再给exchange()传递null,而是传入带有请求头信息的HttpEntity。
如果不指明头信息,exchange()对Spitter的GET请求会带有如下的头信息:
1 | GET /Spitter/spitters/habuma HTTP/1.1Accept: application/xml, text/xml, application/*+xml, application/jsonContent-Length: 0User-Agent: Java/1.6.0_20Host: localhost:8080Connection: keep-alive |
让我们看一下Accept头信息。Accept头信息表明它能够接受多种不同的XML内容类型以及application/json。这样服务器端在决定采用哪种格式返回资源时,就有很大的可选空间。假设我们希望服务端以JSON格式发送资源。在这种情况下,我们需要将“application/json”设置为Accept头信息的唯一值。
设置请求头信息是很简单的,只需构造发送给exchange()方法的HttpEntity对象即可,HttpEntity中包含承载头信息的MultiValueMap:
1 | MultiValue<String, String> headers = new LinkedMultiValue<String, String>();headers.add("Accept", "application/json");HttpEntity<Object> requestEntity = new HttpEntity<Object>(headers); |
在这里,我们创建了一个LinkedMultiValueMap并添加值为“application/json”的Accept头信息。接下来,我们构建了一个HttpEntity(使用Object泛型类型),将MultiValueMap作为构造参数传入。如果这是一个PUT或POST请求,我们需要为HttpEntity设置在请求体中发送的对象——对于GET请求来说,这是没有必要的。
现在,我们可以传入HttpEntity来调用exchange():
1 | ResponseEntity<Spitter> response = rest.exchange( "http://localhost:8080/spittr-api/spitters/{spitter}", HttpMethod.GET, requestEntity, Spitter.class, spitterId);Spitter spitter = response.getBody(); |
表面上看,结果是一样的。我们得到了请求的Spitter对象。但在表面之下,请求将会带有如下的头信息发送:
1 | GET /Spitter/spitters/habuma HTTP/1.1Accept: application/jsonContent-Length: 0User-Agent: Java/1.6.0_20Host: localhost:8080Connection: keep-alive |
假设服务器端能够将Spitter序列化为JSON,响应体将会以JSON格式来进行表述。
小结
RESTful架构使用Web标准来集成应用程序,使得交互变得简单自然。系统中的资源采用URL进行标识,使用HTTP方法进行管理并且会以一种或多种适合客户端的方式来进行表述。
在本章中,我们看到了如何编写响应RESTful资源管理请求的SpringMVC控制器。借助参数化的URL模式并将控制器处理方法与特定的HTTP方法关联,控制器能够响应对资源的GET、POST、PUT以及DELETE请求。
为了响应这些请求,Spring能够将资源背后的数据以最适合客户端的形式展现。对于基于视图的响应,ContentNegotiatingViewResolver能够在多个视图解析器
产生的视图中选择出最适合客户端期望内容类型的那一个。或者,控制器的处理方法可以借助@ResponseBody注解完全绕过视图解析,并使用信息转换器将返回值转换为客户端的响应。
REST API为客户端暴露了应用的功能,它们暴露功能的方式恐怕最原始的API设计者做梦都想不到。REST API的客户端通常是移动应用或运行在Web浏览器中的JavaScript。但是,Spring应用也可以借助RestTemplate来使用这些API。
REST只是应用间通信的方法之一,在下一章中,我们将会学习如何在Spring应用中借助消息实现异步通信。
Spring 消息
本章内容:
- 异步消息简介
- 基于JMS的消息功能
- 使用Spring和AMQP发送消息
- 消息驱动的POJO
在星期五下午4点55分,再有几分钟你就可以开始休假了。现在,你的时间只够开车到机场赶上航班了。但是在你打包离开之前,你需要确定老板和同事了解你目前的工作进展,这样他们就可以在星期一继续完成你留下的工作。不过,你的一些同事已经提前离开过周末去了,而你的老板正在忙于开会。你该怎么办呢?
你可以给老板打电话,但是这样做就会因为一个不重要的状态报告而造成不必要的会议中断。或许你可以再坚持一会,等到会议结束。但是令人郁闷的是,你根本不知道会议还要持续多长时间,而你又要赶飞机。或者,你可以在他的显示器上留一个便条,不过要和其他的100个便条贴在一起。要想既传达到你的工作状态又能赶上飞机,最有效的方式就是发送一封电子邮件给你的老板和同事,详述工作进展并且承诺给他们寄张明信片。你不知道他们在哪里,也不知道他们什么时候才能真正读到你的邮件。但是你知道,他们终究会回到他们的办公桌旁,阅读你的邮件。而此时,你正在赶往机场的路上。
有些时候,需要直接和某些人交谈。如果你受伤了,需要救护车,你可能会拿起电话——而不会给医院发电子邮件。不过,在通常情况下,发送消息就可以满足要求,并且跟直接通信相比更具有一些优势,例如可以让你继续你的假期。
在前面的一些章中,你看到了如何使用RMI、Hessian、Burlap、HTTPinvoker和Web服务在应用程序之间进行通信。所有这些通信机制都是同步的,客户端应用程序直接与远程服务相交互,并且一直等到远程过程完成后才继续执行。
同步通信有它自己的适用场景。不过,对于开发者而言,这种通信方式并不是应用程序之间进行交互的唯一方式。异步消息是一个应用程序向另一个应用程序间接发送消息的一种方式,这种方式无需等待对方的响应。相对于同步消息,异步消息具有多个优势,关于这一点你很快就会看到。
借助Spring,我们有多个实现异步消息的可选方案。在本章中,我们将会看到如何在Spring中使用Java消息服务(Java Message Service,JMS)和高级消息队列协议(Advanced Message Queuing Protocol,AMQP)发送和接收消息。除了基本的消息发送和接收之外,我们还会看到Spring对消息驱动POJO的支持,它是一种与EJB的消息驱动Bean(message-driven bean,MDB)类似的消息接收方式。
异步消息简介
与前面几章中介绍的远程调用机制以及REST接口类似,异步消息也是用于应用程序之间通信的。但是,在系统之间传递信息的方式上,它与其他机制有所不同。
像RMI和Hessian/Burlap这样的远程调用机制是同步的。如图17.1所示,当客户端调用远程方法时,客户端必须等到远程方法完成后,才能继续执行。即使远程方法不向客户端返回任何信息,客户端也要被阻塞直到服务完成。
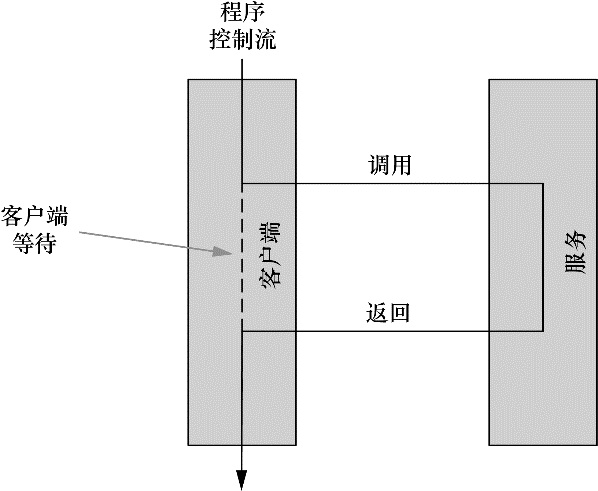
图17.1 如果通信是同步的,客户端必须等待服务完成
消息则是异步发送的,如图17.2所示,客户端不需要等待服务处理消息,甚至不需要等待消息投递完成。客户端发送消息,然后继续执行,这是因为客户端假定服务最终可以收到并处理这条消息。
图17.2 异步通信是一种不需要等待的通信形式
相对于同步通信,异步通信具有多项优势,我们很快就会看到这些优点。但是首先,让我们看看如何异步发送消息。
发送消息
大多数人都使用过邮政服务。每天会有数百万信件、明信片和包裹交到邮递员手上,我们相信自己邮寄的东西会被送到目的地。世界实在是太大了,我们无法自己去运送这些东西,因此我们依赖邮政系统为我们运送。我们在信封上写明地址,贴张邮票,接着把它们投到信箱里,而不需要考虑信件如何到达目的地。
邮政服务的关键在于间接性。当奶奶的生日到来时,如果我们直接送给她一张贺卡,这非常不方便。我们必须留出几小时甚至是几天的时间去为她送生日贺卡,这取决于她住哪里。幸运的是,邮局可以将贺卡送到奶奶那里,而我们可以继续自己的生活。
与此类似,间接性也是异步消息的关键所在。当一个应用向另一个应用发送消息时,两个应用之间没有直接的联系。相反的是,发送方的应用程序会将消息交给一个服务,由服务确保将消息投递给接收方应用程序。
在异步消息中有两个主要的概念:消息代理(message broker)和目的地(destination)。当一个应用发送消息时,会将消息交给一个消息代理。消息代理实际上类似于邮局。消息代理可以确保消息被投递到指定的目的地,同时解放发送者,使其能够继续进行其他的业务。
当我们通过邮局邮递信件时,最重要的是要写上地址,这样邮局就可以知道这封信应该被投递到哪里。与此类似,每条异步消息都带有一个目的地,目的地就好像一个邮箱,可以将消息放入这个邮箱,直到有人将它们取走。
但是,并不像信件地址那样必须标识特定的收件人或街道地址,消息中的目的地相对来说并不那么具体。目的地只关注消息应该从哪里获得——而不关心是由谁取走消息的。这种情况下,目的地就如同信件的地址为“本地居民”。
尽管不同的消息系统会提供不同的消息路由模式,但是有两种通用的目的地:队列(queue)和主题(topic)。每种类型都与特定的消息模型相关联,分别是点对点模型(队列)和发布/订阅模型(主题)。
点对点消息模型
在点对点模型中,每一条消息都有一个发送者和一个接收者,如图17.3所示。当消息代理得到消息时,它将消息放入一个队列中。当接收者请求队列中的下一条消息时,消息会从队列中取出,并投递给接收者。因为消息投递后会从队列中删除,这样就可以保证消息只能投递给一个接收者。

图17.3 消息队列对消息发送者和消息接收者进行了解耦。
虽然队列可以有多个接收者,但是每一条消息只能被一个接收者取走尽管消息队列中的每一条消息只被投递给一个接收者,但是并不意味着只能使用一个接收者从队列中获取消息。事实上,通常可以使用几个接收者来处理队列中的消息。不过,每个接收者都会处理自己所接收到的消息。
这与在银行排队等候类似。在等待时,我们可能注意到很多银行柜员都可以帮助我们处理金融业务。在柜员帮助客户完成业务后,她就空闲了,此时,她会要求排队等候的下一个人前来办理业务。如果我们排在队伍的最前边时,我们就会被叫到,然后由其中的一个空闲柜员来帮助我们处理业务,而其他的柜员则会帮助其他的银行客户。
从另一个角度看,我们在银行排队时,并不知道哪一个柜员会帮助我们办理业务。我们可以计算队伍中有多少人,与柜员的数目进行比较,注意哪一个柜员业务办理速度最快,然后猜测会由哪一个柜员办理我们的业务。但是,一般情况下我们都会猜错,最终会由另一个柜员来办理。
同样,在点对点的消息中,如果有多个接收者监听队列,我们也无法知道某条特定的消息会由哪一个接收者处理。这种不确定性实际上有很多好处,因为我们只需要简单地为队列添加新的监听器就能提高应用的消息处理能力。
发布—订阅消息模型
在发布—订阅消息模型中,消息会发送给一个主题。与队列类似,多个接收者都可以监听一个主题。但是,与队列不同的是,消息不再是只投递给一个接收者,而是主题的所有订阅者都会接收到此消息的副本,如图17.4所示。

图17.4 与队列类似,主题可以将消息发送者与消息接收者进行解耦。与队列不同的是,主题消息可以发送给多个主题订阅者
正如它的名字所暗示的,发布—订阅消息模型与杂志发行商和杂志订阅者很相似。杂志(消息)出版后,发送给邮局,然后所有的订阅者都会收到杂志的副本。
杂志的类比就到此为至,因为对于异步消息来讲,发布者并不知道谁订阅了它的消息。发布者只知道它的消息要发送到一个特定的主题——而不知道有谁在监听这个主题。也就是说,发布者并不知道消息是如何被处理的。
现在,我们已经介绍了异步消息的基本概念,下面让我们看看它与同步RPC的对比。
评估异步消息的优点
虽然同步通信比较容易理解,建立起来也很简单,但是采用同步通信机制访问远程服务的客户端存在几个限制,最主要的是:
- 同步通信意味着等待。当客户端调用远程服务的方法时,它必须等待远程方法结束后才能继续执行。如果客户端与远程服务频繁通信,或者远程服务响应很慢,就会对客户端应用的性能带来负面影响。
- 客户端通过服务接口与远程服务相耦合。如果服务的接口发生变化,此服务的所有客户端都需要做相应的改变。
- 客户端与远程服务的位置耦合。客户端必须配置服务的网络位置,这样它才知道如何与远程服务进行交互。如果网络拓扑进行调整,客户端也需要重新配置新的网络位置。
- 客户端与服务的可用性相耦合。如果远程服务不可用,客户端实际上也无法正常运行。
虽然同步通信仍然有它的适用场景,但是在决定应用程序更适合哪种通信机制时,我们必须考量以上的这些缺点。如果这些限制正是你所担心的,那你可能很想知道异步通信是如何解决这些问题的。
无需等待
当使用JMS发送消息时,客户端不必等待消息被处理,甚至是被投递。客户端只需要将消息发送给消息代理,就可以确信消息会被投递给相应的目的地。
因为不需要等待,所以客户端可以继续执行其他任务。这种方式可以有效地节省时间,所以客户端的性能能够极大的提高。
面向消息和解耦
与面向方法调用的RPC通信不同,发送异步消息是以数据为中心的。这意味着客户端并没有与特定的方法签名绑定。任何可以处理数据的队列或主题订阅者都可以处理由客户端发送的消息,而客户端不必了解远程服务的任何规范。
位置独立
同步RPC服务通常需要网络地址来定位。这意味着客户端无法灵活地适应网络拓扑的改变。如果服务的IP地址改变了,或者服务被配置为监听其他端口,客户端必须进行相应的调整,否则无法访问服务。
与之相反,消息客户端不必知道谁会处理它们的消息,或者服务的位置在哪里。客户端只需要了解需要通过哪个队列或主题来发送消息。因此,只要服务能够从队列或主题中获取消息即可,消息客户端根本不需要关注服务来自哪里。
在点对点模型中,可以利用这种位置的独立性来创建服务的集群。如果客户端不知道服务的位置,并且服务的唯一要求就是可以访问消息代理,那么我们就可以配置多个服务从同一个队列中接收消息。如果服务过载,处理能力不足,我们只需要添加一些新的服务实例来监听相同的队列就可以了。
在发布-订阅模型中,位置独立性会产生另一种有趣的效应。多个服务可以订阅同一个主题,接收相同消息的副本。但是每一个服务对消息的处理逻辑却可能有所不同。例如,假设我们有一组服务可以共同处理描述新员工信息的消息。一个服务可能会在工资系统中增加该员工,另一个服务则会将新员工增加到HR门户中,同时还有一个服务为新员工分配可访问系统的权限。每一个服务都基于相同的数据(都是从同一个主题接收的),但各自进行独立的处理。
确保投递
为了使客户端可以与同步服务通信,服务必须监听指定的IP地址和端口。如果服务崩溃了,或者由于某种原因无法使用了,客户端将不能继续处理。
但是,当发送异步消息时,客户端完全可以相信消息会被投递。即使在消息发送时,服务无法使用,消息也会被存储起来,直到服务重新可以使用为止。
现在,我们已经对异步消息的基础知识有所了解,接下来看一下如何将其付诸实施。首先,我们会使用JMS来发送和接收消息。
使用JMS发送消息
Java消息服务(Java Message Service ,JMS)是一个Java标准,定义了使用消息代理的通用API。在JMS出现之前,每个消息代理都有私有的API,这就使得不同代理之间的消息代码很难通用。但是借助JMS,所有遵从规范的实现都使用通用的接口,这就类似于JDBC为数据库操作提供了通用的接口一样。
Spring通过基于模板的抽象为JMS功能提供了支持,这个模板也就是JmsTemplate。使用JmsTemplate,能够非常容易地在消息生产方发送队列和主题消息,在消费消息的那一方,也能够非常容易地接收这些消息。Spring还提供了消息驱动POJO的理念:这是一个简单的Java对象,它能够以异步的方式响应队列或主题上到达的消息。
我们将会讨论Spring对JMS的支持,包括JmsTemplate和消息驱动POJO。但是在发送和接收消息之前,我们首先需要一个消息代理,它能够在消息的生产者和消费者之间传递消息。对Spring JMS的探索就从在Spring中搭建消息代理开始吧。
在Spring中搭建消息代理
ActiveMQ是一个伟大的开源消息代理产品,也是使用JMS进行异步消息传递的最佳选择。在我编写本书的时候,ActiveMQ的最新版本为5.9.1。在开始使用ActiveMQ之前,我们需要从http://activemq.apache.org下载二进制发行包。下载完ActiveMQ后,我们将其解压缩到本地硬盘中。在解压目录中,我们会找到文件activemq-core-5.9.1.jar。为了能够使用ActiveMQ的API,我们需要将此JAR文件添加到应用程序的类路径中。
在bin目录下,我们可以看到为各种操作系统所创建的对应子目录。在这些子目录下,我们可以找到用于启动ActiveMQ的脚本。例如,要在OS X下启动ActiveMQ,我们只需要在“bin/macosx”目录下运行activemq start。运行脚本后,ActiveMQ就准备好了,这时可以使用它作为消息代理。
创建连接工厂
在本章中,我们将了解如何采用不同的方式在Spring中使用JMS发送和接收消息。在所有的示例中,我们都需要借助JMS连接工厂通过消息代理发送消息。因为选择了ActiveMQ作为我们的消息代理,所以我们必须配置JMS连接工厂,让它知道如何连接到ActiveMQ。ActiveMQConnectionFactory是ActiveMQ自带的连接工厂,在Spring中可以使用如下方式进行配置:
1 | <bean id="connectionFactory" class="org.apache.activemq.spring.ActiveMQConnectionFactory" /> |
默认情况下,ActiveMQConnectionFactory会假设ActiveMQ代理监听localhost的61616端口。对于开发环境来说,这没有什么问题,但是在生产环境下,ActiveMQ可能会在不同的主机和/端口上。如果是这样的话,我们可以使用brokerURL属性来指定代理的URL:
1 | <bean id="connectionFactory" class="org.apache.activemq.spring.ActiveMQConnectionFactory" p:brokerURL="tcp://localhost:61616" /> |
配置连接工厂还有另外一种方式,既然我们知道正在与ActiveMQ打交道,那我们就可以使用ActiveMQ自己的Spring配置命名空间来声明连接工厂(适用于ActiveMQ 4.1之后的所有版本)。首先,我们必须确保在Spring的配置文件中声明了amq命名空间:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:jms="http://www.springframework.org/schema/jms" xmlns:amq="http://activemq.apache.org/schema/core" xsi:schemaLocation=" http://activemq.apache.org/schema/core http://activemq.apache.org/schema/core/activemq-core.xsd http://www.springframework.org/schema/jms http://www.springframework.org/schema/jms/spring-jms.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd" > ...</beans> |
现在我们就可以使用<amq:connectionFactory>元素声明连接工厂:
1 | <amq:connectionFatory id="connectionFactory" brokerURL="tcp://localhost:61616" /> |
注意,<amq:connectionFactory>元素很明显是为ActiveMQ所准备的。如果我们使用不同的消息代理实现,它们不一定会提供Spring配置命名空间。如果没有提供的话,那我们就需要使用
在本章的后续内容中,我们会多次使用connectionFactorybean,但是现在,我们只需要通过配置brokerURL属性来告知连接工厂消息代理的位置就足够了。在本例中,brokerURL属性中的URL指定连接工厂要连接到本地机器的61616端口(这个端口是ActiveMQ监听的默认端口)上的ActiveMQ。
声明ActiveMQ消息目的地
除了连接工厂外,我们还需要消息传递的目的地。目的地可以是一个队列,也可以是一个主题,这取决于应用的需求。
不论使用的是队列还是主题,我们都必须使用特定的消息代理实现类在Spring中配置目的地bean。例如,下面的<bean>声明定义了一个ActiveMQ队列:
1 | <bean id="queue" class="org.apache.activemq.command.ActiveMQQueue" c:_="spitter.queue" /> |
同样,下面的<bean>声明定义了一个ActiveMQ主题:
1 | <bean id="queue" class="org.apache.activemq.command.ActiveMQTopic" c:_="spitter.queue" /> |
在第一个示例中,构造器指定了队列的名称,这样消息代理就能获知该信息,而在接下来示例中,名称则为spitter.topic。
与连接工厂相似的是,ActiveMQ命名空间提供了另一种方式来声明队列和主题。对于队列,我们可以使用amq:quence元素来声明:
1 | <amq:queue id="spittleQueue" physicalName="spittle.alert.queue" /> |
如果是JMS主题,我们可以使用<amq:topic>元素来声明:
1 | <amq:queue id="spittleTopic" physicalName="spittle.alert.topic" /> |
不管是哪种类型,都是借助physicalName属性指定消息通道的名称。
到此为止,我们已经看到了如何声明使用JMS所需的组件。现在我们已经准备好发送和接收消息了。为此,我们将使用Spring的JmsTemplate——Spring 对JMS支持的核心部分。但是首先,让我们先看看如果没有JmsTemplate,JMS是怎样使用的,以此了解JmsTemplate到底提供了些什么。
使用Spring的JMS模板
正如我们所看到的,JMS为Java开发者提供了与消息代理进行交互来发送和接收消息的标准API,而且几乎每个消息代理实现都支持JMS,因此我们不必因为使用不同的消息代理而学习私有的消息API。
虽然JMS为所有的消息代理提供了统一的接口,但是这种接口用起来并不是很方便。使用JMS发送和接收消息并不像拿一张邮票并贴在信封上那么简单。正如我们将要看到的,JMS还要求我们为邮递车加油(只是比喻的说法)。
处理失控的JMS代码
在10.3.1小节中,我向你展示了传统的JDBC代码在处理连接、语句、结果集和异常时是多么冗长和繁杂。遗憾的是,传统的JMS使用了类似的编程模型,如下面的程序清单所示。
程序清单17.1 使用传统的JMS(不使用Spring)发送消息
1 | ConnectionFactory cf = new ActiveMQConnectionFactory("tcp://localhost:61616");Connection conn = null;Session session = null;try { conn = cf.createConnection(); session = conn.createSession(false, Session.AUTO_ACKNOWLEDGE); Destination destination = new ActiveMQQueue("spitter.queue"); MessageProducer producer = session.createProducer(destination); TextMessage message = session.createTextMessage(); message.setText("Hello world!"); producer.send(message);} catch (JMSException e) { // handle exception?} finally { try { if (session != null) { session.close(); } if (conn != null) { conn.close(); } } catch (JMSException ex) { }} |
再次声明这是一段失控的代码!就像JDBC示例一样,差不多使用了20行代码,只是为了发送一条“Hello world!”消息。实际上,其中只有几行代码是用来发送消息的,剩下的代码仅仅是为了发送消息而进行的设置。
接收端也没有好到哪里去,如下面的程序清单所示。与程序清单17.1一样,程序清单17.2也是用一大段代码来实现如此简单的事情。如果我们逐行地比较,我们会发现它们几乎是完全一样的。如果查看上千个其他的JMS例子,我们会发现它们也是很相似的。只不过,其中一些会从JNDI中获取连接工厂,而另一些则是使用主题代替队列。但是无论如何,它们都大致遵循相同的模式。
程序清单17.2 使用传统的JMS(不使用Spring)接收消息
1 | ConnectionFactory cf = new ActiveMQConnectionFactory("tcp://localhost:61616");Connection conn = null;Session session = null;try { conn = cf.createConnection(); conn.start(); session = conn.createSession(false, Session.AUTO_ACKNOWLEDGE); Destination destination = new ActiveMQQueue("spitter.queue"); MessageConsumer consumer = session.createConsumer(destination); Message message = consumer.receive(); TextMessage textMessage = (TextMessage) message; System.out.println("GOT A MESSAGE: " + textMessage.getText()); conn.start();} catch (JMSException e) { // handle exception?} finally { try { if (session != null) { session.close(); } if (con != null) { conn.close(); } } catch (JMSException ex) { }} |
因为这些样板式代码,我们每次使用JMS时都要不断地做很多重复工作。更糟糕的是,你会发现我们在重复编写其他开发者的JMS代码。
我们已经在第10章看到了Spring的JdbcTemplate是如何处理失控的JDBC样板式代码的。现在,让我来介绍一下Spring的JmsTemplate如何对JMS的样板式代码实现相同的功能。
使用JMS模版
针对如何消除冗长和重复的JMS代码,Spring给出的解决方案是JmsTemplate。JmsTemplate可以创建连接、获得会话以及发送和接收消息。这使得我们可以专注于构建要发送的消息或者处理接收到的消息。
另外,JmsTemplate可以处理所有抛出的笨拙的JMSException异常。如果在使用JmsTemplate时抛出JMSException异常,JmsTemplate将捕获该异常,然后抛出一个非检查型异常,该异常是Spring自带的JmsException异常的子类。表17.1列出了标准的JMSException异常与Spring的非检查型异常之间的映射关系。
表17.1 Spring的JmsTemplate会捕获标准的JMSException异常,再以Spring的非检查型异常JmsException子类重新抛出
| Spring(org.springframework.jms.*) | 标准的JMS(javax.jms.*) |
|---|---|
| DestinationResolutionException | Spring特有的——当Spring无法解析目的地名称时抛出 |
| IllegalStateException | IllegalStateException |
| InvalidClientIDException | InvalidClientIDException |
| InvalidDestinationException | InvalidSelectorException |
| InvalidSelectorException | InvalidSelectorException |
| JmsSecurityException | JmsSecurityException |
| ListenerExecutionFailedException | Spring特有的——当监听器方法执行失败时抛出 |
| MessageConversionException | Spring特有的——当消息转换失败时抛出 |
| MessageEOFException | MessageEOFException |
| MessageFormatException | MessageFormatException |
| MessageNotReadableException | MessageNotReadableException |
| MessageNotWriteableException | MessageNotWriteableException |
| ResourceAllocationException | ResourceAllocationException |
| SynchedLocalTransactionFailedException | Spring特有的——当同步的本地事务不能完成时抛出 |
| TransactionInprogressException | TransactionInprogressException |
| TransactionRolledBackException | TransactionRolledBackException |
| UncategorizedJmsException | Spring特有的——当没有其他异常适用时抛出 |
对于JMS API来说,JMSException的确提供了丰富且具有描述性的子类集合,让我们更清楚地知道发生了什么错误。不过,所有的JMSException异常的子类都是检查型异常,因此必须要捕获。JmsTemplate为我们捕获这些异常,并重新抛出对应非检查型JMSException异常的子类。
为了使用JmsTemplate,我们需要在Spring的配置文件中将它声明为一个bean。如下的XML可以完成这项工作:
1 | <bean id="jmsTemplate" class="org.springframework.jms.core.JmsTemplate" c:_-ref="connectionFactory" /> |
因为JmsTemplate需要知道如何连接到消息代理,所以我们必须为connectionFactory属性设置实现了JMS的ConnectionFactory接口的bean引用。在这里,我们使用在12.2.1小节中所声明的connectionFactorybean引用来装配该属性。
这就是配置JmsTemplate所需要做的所有工作——现在JmsTemplate已经准备好了。让我们开始发送消息吧!
发送消息
在我们想建立的Spittr应用程序中,其中有一个特性就是当创建Spittle的时候提醒其他用户(或许是通过E-mail)。我们可以在增加Spittle的地方直接实现该特性。但是搞清楚发送提醒给谁以及实际发送这些提醒可能需要一段时间,这会影响到应用的性能。当增加一个新的Spittle时,我们希望应用是敏捷的,能够快速做出响应。
与其在增加Spittle时浪费时间发送这些信息,不如对该项工作进行排队,在响应返回给用户之后再处理它。与直接发送消息给其他用户所花费的时间相比,发送消息给队列或主题所花费的时间是微不足道的。
为了在Spittle创建的时候异步发送spittle提醒,让我们为Spittr应用引入AlertService:
1 | package com.habuma.spittr.alerts;import com.habuma.spittr.domain.Spittle;public interface AlertService { void sendSpittleAlert(Spittle spittle);} |
正如我们所看到的,AlertService是一个接口,只定义了一个操作—— sendSpittleAlert()。
如程序清单17.3所示,AlertServiceImpl实现了AlertService接口,它使用JmsOperation(JmsTemplate所实现的接口)将Spittle对象发送给消息队列,而队列会在稍后得到处理。
程序清单17.3 使用JmsTemplate发送一个Spittle
1 | package com.habuma.spittr.alerts;import javax.jms.JMSException;import javax.jms.Message;import javax.jms.Session;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.jms.core.JmsOperations;import org.springframework.jms.core.MessageCreator;import com.habuma.spittr.domain.Spittle;public class AlertServicelmpl implements AlertService { private JmsOperations jmsOperations; public AlertServicelmpl (JmsOperations jmsOperatons) { this.jmsOperations = jmsOperations; } public void sendSpittleAlert(final Spittle spittle) { jmsOperations.send( "spittie.alert.queue", new MessageCreator() { public Message createMessage(Session session)throws JMSException { return session.createObjectMessage(spittle); } }); }} |
JmsOperations的send()方法的第一个参数是JMS目的地名称,标识消息将发送给谁。当调用send()方法时,JmsTemplate将负责获得JMS连接、会话并代表发送者发送消息(如图17.5所示)。

图17.5 JmsTemplate代表发送者来负责处理发送消息的复杂过程
我们使用MessageCreator(在这里的实现是作为一个匿名内部类)来构造消息。在MessageCreator的createMessage()方法中,我们通过session创建了一个对象消息:传入一个Spittle对象,返回一个对象消息。
就是这么简单!注意,sendSpittleAlert()方法专注于组装和发送消息。在这里没有连接或会话管理的代码,JmsTemplate帮我们处理了所有的相关事项,而且我们也不需要捕获JMSException异常。JmsTemplate将捕获抛出的所有JMSException异常,然后重新抛出表17.1所列的某一种非检查型异常。
设置默认目的地
在程序清单17.3中,我们明确指定了一个目的地,在send()方法中将Spittle消息发向此目的地。当我们希望通过程序选择一个目的地时,这种形式的send()方法很适用。但是在AlertServiceImpl案例中,我们总是将Spittle消息发给相同的目的地,所以这种形式的send()方法并不能带来明显的好处。
与其每次发送消息时都指定一个目的地,不如我们为JmsTemplate装配一个默认的目的地:
1 | <bean id="jmsTemplate" class="org.springframework.jms.core.JmsTemplate" c:_-ref="connectionFactory" p:defaultDestinationName="spittle.alert.queue" /> |
在这里,将目的地的名称设置为spittle.alert.queue,但它只是一个名称:它并没有说明你所处理的目的地是什么类型。如果已经存在该名称的队列或主题的话,就会使用已有的。如果尚未存在的话,将会创建一个新的目的地(通常会是队列)。但是,如果你想指定要创建的目的地类型的话,那么你可以将之前创建的队列或主题的目的地bean装配进来:
1 | <bean id="jmsTemplate" class="org.springframework.jms.core.JmsTemplate" c:_-ref="connectionFactory" p:defaultDestination="spittleTopic" /> |
现在,调用JmsTemplate的send()方法时,我们可以去除第一个参数了:
1 | jmsOperations.send( new MessageCreator() { ... }); |
这种形式的send()方法只需要传入一个MessageCreator。因为希望消息发送给默认目的地,所以我们没有必要再指定特定的目的地。
在调用send()方法时,我们不必再显式指定目的地能够让任务得以简化。但是如果我们使用消息转换器的话,发送消息会更加简单。
在发送时,对消息进行转换
除了send()方法,JmsTemplate还提供了convertAndSend()方法。与send()方法不同,convertAndSend()方法并不需要MessageCreator作为参数。这是因为convertAndSend()会使用内置的消息转换器(message converter)为我们创建消息。
当我们使用convertAndSend()时,sendSpittleAlert()可以减少到方法体中只包含一行代码:
1 | public void sendSpittleAlert(Spittle spittle) { jmsOperations.convertAndSend(spitlle);} |
就像变魔术一样,Spittle会在发送之前转换为Message。不过就像所有的魔术一样,JmsTemplate内部会进行一些处理。它使用一个MessageConverter的实现类将对象转换为Message。
MessageConverter是Spring定义的接口,只有两个需要实现的方法:
1 | public interface MessageConverter { Message toMessage(Object object, Session session) throws JMSException, MessageConversionException; Object fromMessage(Message message) throws JMSException, MessageConversionException;} |
尽管这个接口实现起来很简单,但我们通常并没有必要创建自定义的实现。Spring已经提供了多个实现,如表17.2所示。
表17.2 Spring为通用的转换任务提供了多个消息转换器(所有的消息转换器都位于org.springframework.jms.support.converter包中)
| 消息转换器 | 功 能 |
|---|---|
| MappingJacksonMessageConverter | 使用Jackson JSON库实现消息与JSON格式之间的相互转换 |
| MappingJackson2MessageConverter | 使用Jackson 2 JSON库实现消息与JSON格式之间的相互转换 |
| MarshallingMessageConverter | 使用JAXB库实现消息与XML格式之间的相互转换 |
| SimpleMessageConverter | 实现String与TextMessage之间的相互转换,字节数组与BytesMessage之间的相互转换,Map与MapMessage之间的相互转换以及Serializable对象与ObjectMessage之间的相互转换 |
默认情况下,JmsTemplate在convertAndSend()方法中会使用SimpleMessage Converter。但是通过将消息转换器声明为bean并将其注入到JmsTemplate的messageConverter属性中,我们可以重写这种行为。例如,如果你想使用JSON消息的话,那么可以声明一个MappingJacksonMessageConverter bean:
1 | <bean id="messageConverter" class="org.springframework.jms.support.converter.MappingJacksonMessageConverter" /> |
然后,我们可以将其注入到JmsTemplate中,如下所示:
1 | <bean id="jmsTemplate" class="org.springframework.jms.core.JmsTemplate" c:_-ref="connectionFactory" p:defaultDestinationName="spittle.alert.queue" p:messageConverter-ref="messageConverter" /> |
各个消息转换器可能会有额外的配置,进而实现转换过程的细粒度控制。例如,MappingJacksonMessageConverter能够让我们配置转码以及自定义Jackson ObjectMapper。可以查阅每个消息转换器的JavaDoc以了解如何更加细粒度地配置它们。
接收消息
现在我们已经了解了如何使用JmsTemplate发送消息。但如果我们是接收端,那要怎么办呢?JmsTemplate是不是也可以接收消息呢?
没错,的确可以。事实上,使用JmsTemplate接收消息甚至更简单,我们只需要调用JmsTemplate的receive()方法即可,如程序清单12.4所示。
当调用JmsTemplate的receive()方法时,JmsTemplate会尝试从消息代理中获取一个消息。如果没有可用的消息,receive()方法会一直等待,直到获得消息为止。图17.6展示了这个交互过程。
程序清单17.4 使用JmsTemplate接收消息
1 | public Spittle receiveApittleAlert() { try { ObjectMessage receivedMessage = (ObjectMessage) jmsOperations.receive(); return (Spittle) receivedMessage.getObject(); } catch (JMSException jmsException) { throws JmsUtils.convertJmsAccessException(jmsException); }} |

图17.6 使用JmsTemplate从主题或队列中接收消息的时候,只需要简单地调用receive()方法。JmsTemplate会处理其他的事情
因为我们知道Spittle消息是作为一个对象消息来发送的,所以它可以在到达后转型为ObjectMessage。然后,我们调用getObject()方法把ObjectMessage转换为Spittle对象并返回此对象。
但是这里存在一个问题,我们不得不对可能抛出的JMSException进行处理。正如我已经提到的,JmsTemplate可以很好地处理抛出的JmsException检查型异常,然后把异常转换为Spring非检查型异常JmsException并重新抛出。但是它只对调用JmsTemplate的方法时才适用。JmsTemplate无法处理调用ObjectMessage的
getObject()方法时所抛出的JMSException异常。
因此,我们要么捕获JMSException异常,要么声明本方法抛出JMSException异常。为了遵循Spring规避检查型异常的设计理念,我们不建议本方法抛出JMSException异常,所以我们选择捕获该异常。在catch代码块中,我们使用Spring中JmsUtils的convertJmsAccessException()方法把检查型异常JMSException转换为非检查型异常JmsException。这其实是在其他场景中由JmsTemplate为我们做的事情。
在receiveSpittleAlert()方法中,我们可以改善的一点就是使用消息转换器。在convertAndSend()中,我们已经看到了如何将对象转换为Message。不过,它们还可以用在接收端,也就是使用JmsTemplate的receiveAndConvert():
1 | public Spittle retrieveSpittleAlert() { return (Spittle) jmsOperation.receiveAndConverter();} |
现在,没有必要将Message转换为ObjectMessage,也没有必要通过调用getObject()来获取Spittle,更无需担心检查型的JMSException异常。这个新的retrieve SpittleAlert()简洁了许多。但是,依然还有一个很小且不容易察觉的问题。
使用JmsTemplate接收消息的最大缺点在于receive()和receiveAndConvert()方法都是同步的。这意味着接收者必须耐心等待消息的到来,因此这些方法会一直被阻塞,直到有可用消息(或者直到超时)。同步接收异步发送的消息,是不是感觉很怪异?
这就是消息驱动POJO的用武之处。让我们看看如何使用能够响应消息的组件异步接收消息,而不是一直等待消息的到来。
创建消息驱动的POJO
在学校时的一个暑假期间,我得到了在黄石国家公园工作的机会。这个工作并不是公园巡逻者或者开关老忠实泉(Old Faithful)这样的高级工作,而是在老忠实泉酒店进行更换床单、清理卫生间以及打扫地板等家务工作。虽然不是很吸引人,但至少我是在这个世界上最美丽的地方工作。
每天工作之后,我都到当地的邮局看看是否有我的邮件。我已经离家好几个星期了,所以能收到学校朋友的来信或者明信片是一件非常美好的事情。我没有自己的邮箱,所以必须走着去邮局,并询问坐在柜台后的工作人员是否有我的邮件。接着就是开始等待。
要知道,柜台后的那个人大约有195岁了。像他这个岁数的人,走动起来很费时间。他从椅子上站起来,慢慢走过地板,消失在隔墙后。过了一会儿,他出现了,慢慢回到柜台,坐到椅子上,然后看着我说:“今天没有邮件”。
JmsTemplate的receive()方法与这个上了年纪的邮局雇员很像。当我们调用receive()方法时,JmsTemplate会查看队列或主题中是否有消息,直到收到消息或者等待超时才会返回。这期间,应用无法处理任何事情,只能等待是否有消息。如果应用能够继续进行其他业务处理,当消息到达时再去通知它,不是更好吗?
EJB2规范的一个重要内容是引入了消息驱动bean(message-driven bean,MDB)。MDB是可以异步处理消息的EJB。换句话说,MDB将JMS目的地中的消息作为事件,并对这些事件进行响应。而与之相反的是,同步消息接收者在消息可用前会一直处于阻塞状态。
MDB是EJB中的一个亮点。即使那些狂热的EJB反对者也认为MDB可以优雅地处理消息。EJB 2 MDB的唯一缺点是它们必须要实现java.ejb.MessageDrivenBean。此外,它们还必须实现一些EJB生命周期的回调方法。简而言之,EJB 2 MDB 不是纯的POJO。
在EJB 3规范中,MDB进一步简化了,使其更像POJO。我们不再需要实现MessageDrivenBean接口,而是实现更通用的javax.jms.MessageListener接口,并使用@MessageDriven注解标注MDB。
Spring 2.0提供了它自己的消息驱动bean来满足异步接收消息的需求,这种形式与EJB 3的MDB很相似。在本节中,我们将学习到Spring是如何使用消息驱动POJO(我们将其简称为MDP)来支持异步接收消息的。
创建消息监听器
如果使用EJB的消息驱动模型来创建Spittle的提醒处理器,我们需要使用@MessageDriven注解进行标注。即使它不是严格要求的,但EJB规范还是建议MDB实现MessageListener接口。Spittle的提醒处理器最终可能是这样的:
1 | public class SpittleAlertHandler implements MessageListener { private MessageDrivenContext mdc; public void onMessage(Message message) { ... }} |
想象一下,如果消息驱动组件不需要实现MessageListener接口,世界将是多么的简单。在这里,天是蔚蓝的,鸟儿唱着我们喜欢的歌,我们不再需要实现onMessage()方法或者注入MessgeDrivenContext。
好吧,可能EJB 3规范所要求的MDB也算不上太麻烦。但是事实上,SpittleAlertHandler的EJB 3实现太依赖于EJB的消息驱动API,并不是我们所希望的POJO。理想情况下,我们希望提醒处理器能够处理消息,但是不用编码,就好像它知道应该做什么。
Spring提供了以POJO的方式处理消息的能力,这些消息来自于JMS的队列或主题中。例如,基于POJO实现SpittleAlertHandler就足以做到这一点。
程序清单17.5 Spring MDP异步接收和处理消息
1 | package com.habuma.spittr.alerts;import com.habuma.spittr.domain.Spittle;public class SpittleAlertHandler { public void handleSpittleAlert(Spittle spittle) { // ... implementation goes here ... }} |
虽然改变天空的颜色和训练鸟儿歌唱超出了Spring的范围,但程序清单17.5所展示的现实与我描绘的理想世界非常接近。我们稍后会编写handleSpittleAlert()方法的具体内容。现在,程序清单 17.5所展示的SpittleAlertHandler没有任何JMS的痕迹。从任意一个角度观察,它都是一个纯粹的POJO。它仍然可以像EJB那样处理消息,只不过它还需要一些Spring的配置。
配置消息监听器
为POJO赋予消息接收能力的诀窍是在Spring中把它配置为消息监听器。Spring的jms命名空间为我们提供了所需要的一切。首先,让我们先把处理器声明为bean:
1 | <bean id="spittleHandler" class="com.habuma.spittr.alerts.SpittleAlertHandler" /> |
然后,为了把SpittleAlertHandler转变为消息驱动的POJO,我们需要把这个bean声明为消息监听器:
1 | <jms:listener-container connection-factory="connectionFactory"> <jms:listener destination="spitter.alert.queue" ref="spittleHandler" method="handleSpittleAlert" /></jms:listener-container> |
在这里,我们在消息监听器容器中包含了一个消息监听器。消息监听器容器(message listener container)是一个特殊的bean,它可以监控JMS目的地并等待消息到达。一旦有消息到达,它取出消息,然后把消息传给任意一个对此消息感兴趣的消息监听器。如图17.7展示了这个交互过程。

图17.7 消息监听器容器监听队列和主题。当消息到达时,消息将转给消息监听器(例如消息驱动的POJO)
为了在Spring中配置消息监听器容器和消息监听器,我们使用了Spring jms命名空间中的两个元素。<jms:listener-container>中包含了<jms:listener>元素。这里的connection-factory属性配置了对connectionFactory的引用,容器中的每个<jms:listener>都使用这个连接工厂进行消息监听。在本示例中,connection-factory属性可以移除,因为该属性的默认值就是connectionFactory。
对于<jms:listener>元素,它用于标识一个bean和一个可以处理消息的方法。为了处理Spittle提醒消息,ref元素引用了spittleHandler bean。当消息到达spitter.alert.queue队列(通过destination属性配置)时,spittleHandlerbean的handleSpittleAlert()方法(通过method属性指定的)会被触发。
值得一提的是,如果ref属性所标示的bean实现了MessageListener,那就没有必要再指定method属性了,默认就会调用onMessage()方法。
使用基于消息的RPC
在第15章中,我们展示了Spring把bean的方法暴露为远程服务以及从客户端向这些服务发起调用的几种方式。在本章,我们学习了如何通过队列和主题在应用程序之间发送消息。现在我们将了解一下如何使用JMS作为传输通道来进行远程调用。
为了支持基于消息的RPC,Spring提供了JmsInvokerServiceExporter,它可以把bean导出为基于消息的服务;为客户端提供了JmsInvokerProxyFactoryBean来使用这些服务。
让我们回顾一下第15章,Spring提供了多种方式把bean导出为远程服务。我们使用RmiServiceExporter把bean导出为RMI服务,使用HessianExporter和BurlapExporter导出为基于HTTP的Hessian和Burlap服务,还使用HttpInvoker Service Exporter创建基于HTTP的HTTP invoker服务。但Spring还提供了一种在第15章中我们未探讨的服务导出器。
导出基于JMS的服务
JmsInvokerServiceExporter很类似于其他的服务导出器。事实上,JmsInvokerServiceExporter与HttpInvokerServiceExporter在名称上有某种对称型。如果
HttpInvokerServiceExporter可以导出基于HTTP通信的服务,那么JmsInvokerServiceExporter就应该可以导出基于JMS的服务。
为了演示JmsInvokerServiceExporter是如何工作的,考虑如下的AlertServiceImpl。
程序清单17.6 AlertServiceImpl是一个处理JMS消息的POJO,但是不依赖于JMS
1 | package com.habuma.spittr.alerts;import org.springframework.mail.SimpleMailMessage;import org.springframework.mail.javamail.JavaMailSender;import org.springframework.stereotype.Component;import com.habuma.spittr.domain.Spittle;public class AlertServicelmpl implements AlertService { private JavaMailSender mailSender; private String alertEmailAddress; public AlertServicelmpl(JavaMailSender mailSender, String alertEmailAddress) { this.mailSender = mailSender; this.alertEmailAddress = alertEmailAddress; } public void sendSpittleAlert(final Spittle spittle) { SimpleMailMessage message = new SimpleMailMessage(); String spitterName = spittle.getSpitter().getFullName(); message.setFrom("noreply@spitter.com"); message.setTo(alertEmailAddress); message.setSubject{"New spittle from " + spitterName); message.setText(spitterName + " says: " + spittle.getText()); mailSender.send(message); }} |
我们现在不要过于关注sendSpittleAlert()方法的细节。在第19章,我们将会继续探讨如何使用Spring发送E-mail。现在,我们需要关注的重点在于AlertServiceImpl是一个简单的POJO,没有任何迹象标示它要用来处理JMS消息。它只是实现了简单的AlertService接口,该接口如下所示:
1 | package com.habuma.spittr.alerts;import com.habuma.spittr.domain.Spittle;public interface AlertService { void sendSpittleAlert(Spittle spittle);} |
正如我们所看到的,AlertServiceImpl使用了@Component注解来标注,所以它会被Spring自动发现并注册为Spring应用上下文中ID为alertService的bean。在配置JmsInvokerServiceExporter时,我们将引用这个bean:
1 | <bean id="alertServiceExporter" class="org.springframework.jms.remoting.JmsInvokerServiceExporter" p:service-ref="alertService" p:serviceInterface="com.habuma.spittr.alerts.AlertService" /> |
这个bean的属性描述了导出的服务应该是什么样子的。service属性设置为alertServicebean的引用,它是远程服务的实现。同时,serviceInterface属性设置为远程服务对外提供接口的全限定类名。
导出器的属性并没有描述服务如何基于JMS通信的细节。但好消息是JmsInvokerServiceExporter可以充当JMS监听器。因此,我们使用<jms:listenercontainer>元素配置它:
1 | <jms:listener-container connection-factory="connectionFactory"> <jms:listener destination="spitter.alert.queue" ref="alertServiceExporter" /></jms:listener-container> |
我们为JMS监听器容器指定了连接工厂,所以它能够知道如何连接消息代理,而<jms:listener>声明指定了远程消息的目的地。
使用基于JMS的服务
这时候,基于JMS的提醒服务已经准备好了,等待队列中名字为spitter.alert.queue的RPC消息到达。在客户端,JmsInvokerProxyFactoryBean用来访问服务。
JmsInvokerProxyFactoryBean很类似于我们在第15章中所讨论的其他远程代理工厂bean。它隐藏了访问远程服务的细节,并提供一个易用的接口,通过该接口客户端与远程服务进行交互。与代理RMI服务或HTTP服务的最大区别在于,JmsInvokerProxyFactoryBean代理了通过JmsInvokerServiceExporter所导出的JMS服务。
为了使用提醒服务,我们可以像下面那样配置JmsInvokerProxyFactoryBean:
1 | <bean id="alertService" class="org.springframework.jms.remoting.JmsInvokerProxyFactoryBean" p:connectionFactory-ref="connectionFactory" p:queueName="spittle.alert.queue" p:serviceInterface="com.habuma.spittr.alerts.AlertService" /> |
connectionFactory和queryName属性指定了RPC消息如何被投递——在这里,也就是在给定的连接工厂中,我们所配置的消息代理里面名为spitter.alert.queue的队列。对于serviceInterface,指定了代理应该通过AlertService接口暴露功能。
多年来,JMS一直是Java应用中主流的消息解决方案。但是对于Java和Spring开发者来说,JMS并不是唯一的消息可选方案。在过去的几年中,高级消息队列协议(Advanced Message Queuing Protocol ,AMQP)得到了广泛的关注。因此,Spring也为通过AMQP发送消息提供了支持,这就是我们下面要讲解的内容。
使用AMQP实现消息功能
你可能会疑惑为什么还需要另外一个消息规范。难道JMS还不够好吗?AMQP提供了哪些JMS所不具备的特性呢?实际上,AMQP具有多项JMS所不具备的优势。首先,AMQP为消息定义了线路层(wire-level protocol)的协议,而JMS所定义的是API规范。JMS的API协议能够确保所有的实现都能通过通用的API来使用,但是并不能保证某个JMS实现所发送的消息能够被另外不同的JMS实现所使用。而AMQP的线路层协议规范了消息的格式,消息在生产者和消费者间传送的时候会遵循这个格式。这样AMQP在互相协作方面就要优于JMS——它不仅能跨不同的AMQP实现,还能跨语言和平台。
相比JMS,AMQP另外一个明显的优势在于它具有更加灵活和透明的消息模型。使用JMS的话,只有两种消息模型可供选择:点对点和发布-订阅。这两种模型在AMQP当然都是可以实现的,但AMQP还能够让我们以其他的多种方式来发送消息,这是通过将消息的生产者与存放消息的队列解耦实现的。
Spring AMQP是Spring框架的扩展,它能够让我们在Spring应用中使用AMQP风格的消息。稍后可以看到,Spring AMQP提供了一个API,借助这个API,我们能够以非常类似于Spring JMS抽象的形式来使用AMQP。这意味着,我们在本章之前所学习的JMS内容能够帮助你理解如何使用Spring AMQP来发送和接收消息。
我们稍后就会介绍如何使用Spring AMQP,但是在深入学习如何在Spring中发送和接收消息之前,首先看一下到底是什么让AMQP如此引人关注。
AMQP简介
简单回忆一下JMS的消息模型,可能会有助于理解AMQP的消息模型。在JMS中,有三个主要的参与者:消息的生产者、消息的消费者以及在生产者和消费者之间传递消息的通道(队列或主题)。JMS消息模型中的关键元素在图17.3和图17.4中进行了描述。
在JMS中,通道有助于解耦消息的生产者和消费者,但是这两者依然会与通道相耦合。生产者会将消息发布到一个特定的队列或主题上,消费者从特定的队列或主题上接收这些消息。通道具有双重责任,也就是传递数据以及确定这些消息该发送到什么地方,队列的话会使用点对点算法发送,主题的话就使用发布-订阅的方式。
与之不同的是,AMQP的生产者并不会直接将消息发布到队列中。AMQP在消息的生产者以及传递信息的队列之间引入了一种间接的机制:Exchange。这种关系如图17.8所示。

图17.8 在AMQP中,通过引入处理信息路由的Exchange,消息的生产者 与消息队列之间实现了解耦
可以看到,消息的生产者将信息发布到一个Exchange。Exchange会绑定到一个或多个队列上,它负责将信息路由到队列上。信息的消费者会从队列中提取数据并进行处理。
图17.8所没有展现出来的一点是Exchange不是简单地将消息传递到队列中,并不仅仅是一种穿透(pass-through)机制。AMQP定义了四种不同类型的Exchange,每一种都有不同的路由算法,这些算法决定了是否要将信息放到队列中。根据Exchange的算法不同,它可能会使用消息的routing key和/或参数,并将其与Exchange和队列之间binding的routing key和参数进行对比。(routing key可以大致理解为Email的收件人地址,指定了预期的接收者。)如果对比结果满足相应的算法,那么消息将会路由到队列上。否则的话,将不会路由到队列上。
四种标准的AMQP Exchange如下所示:
- Direct:如果消息的routing key与binding的routing key直接匹配的话,消息将会路由到该队列上;
- Topic:如果消息的routing key与binding的routing key符合通配符匹配的话,消息将会路由到该队列上;
- Headers:如果消息参数表中的头信息和值都与bingding参数表中相匹配,消息将会路由到该队列上;
- Fanout:不管消息的routing key和参数表的头信息/值是什么,消息将会路由到所有队列上。
借助这四种类型的Exchange,很容易就能想到我们可以定义任意数量的路由模式,而不再仅限于点对点和发布-订阅的方式。好消息是,当发送和接收消息的时候,所涉及的路由算法对于如何编写消息的生产者和消费者并没有什么影响。简单来讲,生产者将信息发送给Exchange并带有一个routing key,消费者从队列中获取消息。
我们已经快速了解了AMQP消息的基本知识——此时应该已经能够理解我们接下来所要介绍的如何使用Spring发送和接收消息。但是,我建议你更深入的学习一下AMQP,可以阅读规范和www.amqp.org站点上的其他资料,或者可以阅读Alvaro Videla和Jason J.W. Williams所编写的《RabbitMQ in Action》(Manning, 2012, www.manning.com/videla/)。
现在,我们结束对AMQP的抽象讨论,开始着手编写借助Spring AMQP发送和接收消息的代码。首先我们将看到的是一些通用的配置,它们同时适用于生产者和消费者。
配置Spring支持AMQP消息
当我们第一次使用Spring JMS抽象的时候,首先配置了一个连接工厂。与之类似,使用Spring AMQP前也要配置一个连接工厂。只不过,所要配置的不是JMS的连接工厂,而是需要配置AMQP的连接工厂。更具体来讲,需要配置RabbitMQ连接工厂。
什么是RabbitMQ
RabbitMQ是一个流行的开源消息代理,它实现了AMQP。Spring AMQP为RabbitMQ提供了支持,包括RabbitMQ连接工厂、模板以及Spring配置命名空间。
在使用它发送和接收消息之前,你需要预先安装RabbitMQ。我们可以在www.rabbitmq.com/download.html上找到安装指南。根据你所运行的OS不同,这会有所差别,所以根据环境的不同,遵循相应指南进行安装的任务就留给读者自己完成。
配置RabbitMQ连接工厂最简单的方式就是使用Spring AMQP所提供的rabbit配置命名空间。为了使用这项功能,需要确保在Spring配置文件中已经声明了该模式:
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns="http://www.springframework.org/schema/rabbit" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/rabbit http://www.springframework.org/schema/rabbit/spring-rabbit-1.0.xsd" > ...</beans> |
尽管不是必须的,但我还选择在这个配置中将rabbit作为首选的命名空间,将beans作为第二位的命名空间。这是因为在这个配置中,我会更多的声明rabbit而不是bean,这样的话,只会有少量的bean元素使用“beans:”前缀,而rabbit元素就能够避免使用前缀了。
rabbit命名空间包含了多个在Spring中配置RabbitMQ的元素。但此时,你最感兴趣的可能就是<connection-factory>。按照其最简单的形式,我们可以在配置RabbitMQ连接工厂的时候没有任何属性:
1 | <connect-factory /> |
这的确能够运行起来,但是所导致的结果就是连接工厂bean没有可用的bean ID,这样的话就难将连接工厂装配到需要它的bean中。因此,我们可能希望通过id属性为其设置一个bean ID:
1 | <connection-factory id="connectionFactory" /> |
默认情况下,连接工厂会假设RabbitMQ服务器监听localhost的5672端口,并且用户名和密码均为guest。对于开发来讲,这是合理的默认值,但是对于生产环境,我们可能希望修改这些默认值。如下<connection-factory>的设置重写了默认的做法:
1 | <connection-factory id="connectionFactory" host="${rabbitmq.host}" username="${rabbitmq.username}" password="${rabbitmq.password}" /> |
我们使用占位符来指定值,这样配置项可以在Spring配置文件之外进行管理(很可能位于属性文件中)。
除了连接工厂以外,我们还要考虑使用其他的几个配置元素。接下来,看一下如何创建队列、Exchange以及binding。
声明队列、Exchange以及binding
<<<<<<< HEAD
在JMS中,队列和主题的路由行为都是通过规范建立的,AMQP与之不同,它的路由更加丰富和灵活,依赖于如何定义队列和Exchange以及如何将它们绑定在一起。声明队列、Exchange和binding的一种方式是使用RabbitMQ Channel接口的各种方法。但是直接使用RabbitMQ的Channel接口非常麻烦。Spring AMQP能否帮助我们声明消息路由组件呢?
幸好,rabbit命名空间包含了多个元素,帮助我们声明队列、Exchange以及将它们结合在一起的binding。表17.3中列出了这些元素。
表17.3 Spring AMQP的rabbit命名空间包含了多个元素,用来创建队列、Exchange以及将它们结合在一起的binding
| 元 素 | 作 用 |
|---|---|
| 创建一个队列 | |
| 创建一个fanout类型的Exchange | |
| 创建一个header类型的Exchange | |
| 创建一个topic类型的Exchange | |
| 创建一个direct类型的Exchange | |
| 元素定义一个或多个元素的集合。元素创建Exchange和队列之间的binding |
这些配置元素要与
例如,如果你希望声明名为spittle.alert.queue的队列,只需要在Spring配置中添加如下的两个元素即可:
1 | <admin connection-factory="connnectionFactory" /><queue id="spittleAlertQueue" name="spittle.alerts" /> |
对于简单的消息来说,我们只需做这些就足够了。这是因为默认会有一个没有名称的direct Exchange,所有的队列都会绑定到这个Exchange上,并且routing key与队列的名称相同。在这个简单的配置中,我们可以将消息发送到这个没有名称的Exchange上,并将routing key设定为spittle.alert.queue,这样消息就会路由到这个队列中。实际上,我们重新创建了JMS的点对点模型。
但是,更加有意思的路由需要我们声明一个或更多的Exchange,并将其绑定到队列上。例如,如果要将消息路由到多个队列中,而不管routing key是什么,我们可以按照如下的方式配置一个fanout以及多个队列:
1 | <amdin connection-factory="connectionFactory" /><queue name="spittle.alert.queue.1" ><queue name="spittle.alert.queue.2" ><queue name="spittle.alert.queue.3" ><fanout-exchange name="spittle.fanout" > <bindings> <binding queue="spittle.alert.queue.1" /> <binding queue="spittle.alert.queue.2" /> <binding queue="spittle.alert.queue.3" /> <bindings></fanout-exchange> |
借助表17.3中的元素,会有无数种在RabbitMQ配置路由的方式,但是我却没有无尽的篇幅来为读者描述它们,所以为了让我们的讨论不至于偏离方向,我将这些创造性的路由作为练习留给读者,我将会继续讨论如何发送消息。
使用RabbitTemplate发送消息
顾名思义,RabbitMQ连接工厂的作用是创建到RabbitMQ的连接。如果你希望通过RabbitMQ发送消息,那么你可以将connectionFactorybean注入到AlertServiceImpl类中,并使用它来创建Connection,使用这个Connection来创建Channel,然后使用这个Channel发布消息到Exchange上。
是的,你的确可以这样做。但是,如果这样做的话,你要做许多的工作并且会涉及到很多样板式代码。Spring所讨厌的一件事情就是样板式代码。我们已经看到
Spring提供模板来消除样板式代码的多个例子——包括本章前面所介绍的JmsTemplate,它消除了JMS的样板式代码。因此,Spring AMQP提供RabbitTemplate来消除RabbitMQ发送和接收消息相关的样板式代码就一点也不让人感觉奇怪了。
配置RabbitTemplate的最简单方式是使用rabbit命名空间的<template>元素,如下所示:
1 | <template id="rabbitTemplate" connection-factory="connectionFactory" /> |
现在,要发送消息的话,我们只需要将模板bean注入到AlertServiceImpl中,并使用它来发送Spittle。如下的程序清单展现了一个新版本的AlertServiceImpl,它使用RabbitTemplate代替JmsTemplate来发送Spittle提醒。
=======
在JMS中,队列和主题的路由行为都是通过规范建立的,AMQP与之
不同,它的路由更加丰富和灵活,依赖于如何定义队列和Exchange以
及如何将它们绑定在一起。声明队列、Exchange和binding的一种方式
是使用RabbitMQ Channel接口的各种方法。但是直接使用RabbitMQ
的Channel接口非常麻烦。Spring AMQP能否帮助我们声明消息路由
组件呢?
幸好,rabbit命名空间包含了多个元素,帮助我们声明队列、Exchange
以及将它们结合在一起的binding。表17.3中列出了这些元素。
表17.3 Spring AMQP的rabbit命名空间包含了多个元素,用来创建队列、
Exchange以及将它们结合在一起的binding
元 素作 用
元素定义一个或多个元素的集合。元素创建Exchange和
队列之间的binding
这些配置元素要与
个RabbitMQ管理组件(administrative component),它会自动创建
(如果它们在RabbitMQ代理中尚未存在的话)上述这些元素所声明
的队列、Exchange以及binding。
例如,如果你希望声明名为spittle.alert.queue的队列,只需
要在Spring配置中添加如下的两个元素即可:
569
对于简单的消息来说,我们只需做这些就足够了。这是因为默认会有
一个没有名称的direct Exchange,所有的队列都会绑定到这个Exchange
上,并且routing key与队列的名称相同。在这个简单的配置中,我们
可以将消息发送到这个没有名称的Exchange上,并将routing key设定
为spittle.alert.queue,这样消息就会路由到这个队列中。实
际上,我们重新创建了JMS的点对点模型。
但是,更加有意思的路由需要我们声明一个或更多的Exchange,并将
其绑定到队列上。例如,如果要将消息路由到多个队列中,而不管
routing key是什么,我们可以按照如下的方式配置一个fanout以及多个
队列:
借助表17.3中的元素,会有无数种在RabbitMQ配置路由的方式,但是
我却没有无尽的篇幅来为读者描述它们,所以为了让我们的讨论不至
于偏离方向,我将这些创造性的路由作为练习留给读者,我将会继续
讨论如何发送消息。
17.3.3 使用RabbitTemplate发送消息
顾名思义,RabbitMQ连接工厂的作用是创建到RabbitMQ的连接。如
果你希望通过RabbitMQ发送消息,那么你可以
将connectionFactorybean注入到AlertServiceImpl类中,并
使用它来创建Connection,使用这个Connection来创建
Channel,然后使用这个Channel发布消息到Exchange上。
是的,你的确可以这样做。
但是,如果这样做的话,你要做许多的工作并且会涉及到很多样板式
代码。Spring所讨厌的一件事情就是样板式代码。我们已经看到
Spring提供模板来消除样板式代码的多个例子——包括本章前面所介
绍的JmsTemplate,它消除了JMS的样板式代码。因此,Spring
AMQP提供RabbitTemplate来消除RabbitMQ发送和接收消息相关
570
的样板式代码就一点也不让人感觉奇怪了。
配置RabbitTemplate的最简单方式是使用rabbit命名空间的
元素,如下所示:
现在,要发送消息的话,我们只需要将模板bean注入
到AlertServiceImpl中,并使用它来发送Spittle。如下的程序清
单展现了一个新版本的AlertServiceImpl,它使
用RabbitTemplate代替JmsTemplate来发送Spittle提醒。
f1aaa068b9ac5f8ec08770544f6994940c9e1eff
程序清单17.7 使用RabbitTemplate来发送Spittle
1 | package com.habuma.spitter.alerts;import org.springframework.amqp.rabbit.core.RabbitTemplate;import org.springframework.beans.factory.annotation.Autowired;import com.habuma.spitter.domain.Spittle;public class AlertServicelmpl implements AlertService { private RabbitTemplate rabbit; public AlertServicelmpl(RabbitTemplate rabbit) { this.rabbit = rabbit; } public void sendSpittleAlert(Spittle spittle) { rabbit.convertAndSend("spittle.alert.exchange", "spittle.alerts", spittle); }} |
可以看到,现在sendSpittleAlert()调用RabbitTemplate的convertAndSend()方法,其中RabbitTemplate是被注入进来的。它传入了三个参数:Exchange的名称、routing key以及要发送的对象。注意,这里并没有指定消息该路由到何处、要发送给哪个队列以及期望哪个消费者来获取消息。
RabbitTemplate有多个重载版本的convertAndSend()方法,这些方法可以简化它的使用。例如,使用某个重载版本的convertAndSend()方法,我们可以在调用convertAndSend()的时候,不设置Exchange的名称:
1 | rabbit.convertAndSend("spittle.alerts", spittle); |
如果你愿意的话,还可以同时省略Exchange名称和routing key:
1 | rabbit.convertAndSend(spittle); |
如果在参数列表中省略Exchange名称,或者同时省略Exchange名称和routing key的话,RabbitTemplate将会使用默认的Exchange名称和routing key。按照我们之前的配置,默认的Exchange名称为空(或者说是默认没有名称的那一个Exchange),默认的routing key也为空。但是,我们可以在<template>元素上借助exchange和routingkey属性配置不同的默认值:
1 | <template id="rabbitTemplate" connection-factory="connectionFactory" exchange="spittle.alert.exchange" routing-key="spittle.alerts" /> |
不管设置的默认值是什么,我们都可以在调用convertAndSend()方法的时候,以参数的形式显式指定它们,从而覆盖掉默认值。
RabbitTemplate还有其他的方法来发送消息,你可能会对此感兴趣。例如,我们可以使用较低等级的send()方法来发送org.springframework.amqp.core.Message对象,如下所示:
1 | Message helloMessage = new Message("Hello World!".getBytes(), new MessageProperties());rabbit.send("hello.exchange", "hello.routing", helloMessage); |
与convertAndSend()方法类似,send()方法也有重载形式,它们不需要提供Exchange名称和/或routing key。
使用send()方法的技巧在于构造要发送的Message对象。在这个“Hello World”样例中,我们通过给定字符串的字节数组来构建Message实例。对于String值来说,这足够了,但是如果消息的负载是复杂对象的话,那它就会复杂得多。
鉴于这种情况,我们有了convertAndSend()方法,它会自动将对象转换为Message。它需要一个消息转换器的帮助来完成该任务,默认的消息转换器是SimpleMessageConverter,它适用于String、Serializable实例以及字节数组。Spring AMQP还提供了其他几个有用的消息转换器,其中包括使用JSON和XML数据的消息转换器。
现在,我们已经发送了消息,接下来我们转向回话的另外一端,看一下如何获取消息。
接收AMQP消息
我们可以回忆一下,JMS提供了两种从队列中获取信息的方式:使用JmsTemplate的同步方式以及使用消息驱动POJO的异步方式。Spring AMQP提供了类似的方式来获取通过AMQP发送的消息。因为我们已经有了RabbitTemplate,所以首先看一下如何使用它同步地从队列中获取消息。
使用RabbitTemplate来接收消息
RabbitTemplate提供了多个接收信息的方法。最简单就是receive()方法,它位于消息的消费者端,对应于RabbitTemplate的send()方法。借助receive()方法,我们可以从队列中获取一个Message对象:
1 | Message message = rabbit.receive("spittle.alert.queue"); |
或者,如果愿意的话,你还可以配置获取消息的默认队列,这是通过在配置模板的时候,设置queue属性实现的:
1 | <template id="rabbitTemplate" connection-factory="connectionFactory" exchange="spittle.alert.exchanges" routing-key="spittle.alerts" queue="spittle.alert.queue" /> |
这样的话,我们在调用receive()方法的时候,不需要设置任何参数就能从默认队列中获取消息了:
1 | Message message = rabbit.receive(); |
在获取到Message对象之后,我们可能需要将它body属性中的字节数组转换为想要的对象。就像在发送的时候将领域对象转换为Message一样,将接收到的Message转换为领域对象同样非常繁琐。因此,我们可以考虑使用RabbitTemplate的receiveAndConvert()方法作为替代方案:
1 | Spittle spittle = (Spittle) rabbit.receiveAndConvert("spittle.alert.queue"); |
我们还可以省略调用参数中的队列名称,这样它就会使用模板的默认队列名称:
1 | Spittle spittle = (Spittle) rabbit.receiveAndConvert(); |
receiveAndConvert()方法会使用与sendAndConvert()方法相同的消息转换器,将Message对象转换为原始的类型。
调用receive()和receiveAndConvert()方法都会立即返回,如果队列中没有等待的消息时,将会得到null。这就需要我们来管理轮询(polling)以及必要的线程,实现队列的监控。
我们并非必须同步轮询并等待消息到达,Spring AMQP还提供了消息驱动POJO的支持,这不禁使我们回忆起Spring JMS中的相同特性。让我们看一下如何通过消息驱动AMQP POJO的方式来接收消息。
定义消息驱动的AMQP POJO
如果你想在消息驱动POJO中异步地消费使用Spittle对象,首先要解决的问题就是这个POJO本身。如下的SpittleAlertHandler扮演了这个角色:
1 | package com.habuma.spittr.alerts;import com.habuma.spittr.domain.Spittle;public class SpittleAlertHandler { public void handleSpittleAlert(Spittle spittle) { // ... implementation goes here ... }} |
注意,这个类与借助JMS消费Spittle时所用到SpittleAlertHandler完全一致。我们之所以能够重用相同的POJO是因为这个类丝毫没有依赖于JMS或AMQP,并且不管通过什么机制传递过来Spittle对象,它都能够进行处理。
我们还需要在Spring应用上下文中将SpittleAlertHandler声明为一个bean:
1 | <bean id="spittleListener" class="com.habuma.spittr.alert.SpittleAlertHandler" /> |
同样,在使用基于JMS的MDP时,我们已经做过相同的事情,没有什么丝毫的差异。最后,我们需要声明一个监听器容器和监听器,当消息到达的时候,能够调用SpittleAlertHandler。在基于JMS的MDP中,我们做过相同的事情,但是基于AMQP的MDP在配置上有一个细微的差别:
1 | <listener-container connection-factory="connectionFactory"> <listener ref="spittleListener" method="handleSpittleAlert" queue-names="spittle.alert.queue" /></listener-container> |
你看到有什么差别了吗?我也同意这并不那么明显。<listenercontainer>与<listener>都与JMS对应的元素非常类似。但是,这些元素来自rabbit命名空间,而不是JMS命名空间。
我都说过了,没那么明显。
哦,还有一个细微的差别,我们不再通过destination属性(JMS中的做法)来监听队列或主题,这里我们通过queue-names属性来指定要监听的队列。但是,除此之外,基于AMQP的MDP与基于JMS的MDP都非常类似。
你可能也意识到了,queue-names属性的名称使用了复数形式。在这里我们只设定了一个要监听的队列,但是允许设置多个队列的名称,用逗号分割即可。
另外一种指定要监听队列的方法是引用
1 | <listener-container connection-factory="connectionFactory"> <listener ref="spittleListener" method="handleSpittleAlert" queue="spittleAlertQueue" /></listener-container> |
同样,这里可以接受逗号分割的queue ID列表。当然,这需要我们在声明队列的时候,为其指定ID。例如,如下是重新定义的提醒队列,这次指定了ID:
1 | <queue id="spittleAlertQueue" name="spittle.alert.queue" /> |
注意,这里的id属性用来在Spring应用上下文中设置队列的bean ID,而name属性指定了RabbitMQ代理中队列的名称。
小结
异步消息通信与同步RPC相比有几个优点。间接通信带来了应用之间的松散耦合,因此减轻了其中任意一个应用崩溃所带来的影响。此外,因为消息转发给了收件人,因此发送者不必等待响应。在很多情况下,这会提高应用的性能。
虽然JMS为所有的Java应用程序提供了异步通信的标准API,但是它使用起来很繁琐。Spring消除了JMS样板式代码和异常捕获代码,让异步消息通信更易于使用。
在本章中,我们了解了Spring通过消息代理和JMS建立应用程序之间异步通信的几种方式。Spring的JMS模板消除了传统的JMS编程模型所必需的样板式代码,而基于Spring的消息驱动bean可以通过声明bean的方法允许方法响应来自于队列或主题中的消息。我们同样了解了如何通过Spring的JMS invoker为Spring bean提供基于消息的RPC。
在本章中,我们已经看到了如何在应用程序之间使用异步通信。在下一章中,我们将会延续这一话题,了解如何借助WebSocket在基于浏览器的客户端和服务器之间实现异步通信。
使用WebSocket和STOMP实现消息功能
本章内容:
- 在浏览器和服务器之间发送消息
- 在Spring MVC控制器中处理消息
- 为目标用户发送消息
在上一章中,我们看到了如何使用JMS和AMQP在应用程序之间发送消息。异步消息是应用程序之间通用的交流方式。但是,如果某一应用是运行在Web浏览器中,那我们就需要一些稍微不同的技巧了。
WebSocket协议提供了通过一个套接字实现全双工通信的功能。除了其他的功能之外,它能够实现Web浏览器和服务器之间的异步通信。全双工意味着服务器可以发送消息给浏览器,浏览器也可以发送消息给服务器。
- Spring 4.0为WebSocket通信提供了支持,包括:
- 发送和接收消息的低层级API;
- 发送和接收消息的高级API;
- 用来发送消息的模板;
支持SockJS,用来解决浏览器端、服务器以及代理不支持WebSocket的问题。
在本章中,我们将会学习借助Spring的WebSocket功能实现服务器端和基于浏览器的应用之间实现异步通信。我们首先会从如何使用Spring的低层级WebSocket API开始。
使用Spring的低层级WebSocket API
按照其最简单的形式,WebSocket只是两个应用之间通信的通道。位于WebSocket一端的应用发送消息,另外一端处理消息。因为它是全双工的,所以每一端都可以发送和处理消息。如图18.1所示。

图18.1 WebSocket是两个应用之间全双工的通信通道
WebSocket通信可以应用于任何类型的应用中,但是WebSocket最常见的应用场景是实现服务器和基于浏览器的应用之间的通信。浏览器中的JavaScript客户端开启一个到服务器的连接,服务器通过这个连接发送更新给浏览器。相比历史上轮询服务端以查找更新的方案,这种技术更加高效和自然。
为了阐述Spring低层级的WebSocket API,让我们编写一个简单的WebSocket样例,基于JavaScript的客户端与服务器玩一个无休止的“Marco Polo”游戏。服务器端的应用会处理文本消息(“Marco!”),然后在相同的连接上往回发送文本消息(“Polo!”)。
为了在Spring使用较低层级的API来处理消息,我们必须编写一个实现WebSocketHandler的类:
1 | public interface WebSocketHandler { void afterConnectionEstablished(WebSocketSession session) throws Exception; void handleMessage(WebSocketSession session, WebSocketMessage<?> message) throws Exception; void handleTransportError(WebSocketSession session, Throwable exception) throws Exception; void afterConnectionClosed(WebSocketSession session, CloseStatus closeStatus) throws Exception; boolean supportsPartialMessages();} |
可以看到,WebSocketHandler需要我们实现五个方法。相比直接实现WebSocketHandler,更为简单的方法是扩展AbstractWebSocketHandler,这是WebSocketHandler的一个抽象实现。如下的程序清单展现了MarcoHandler,它是AbstractWebSocketHandler的一个子类,会在服务器端处理消息。
程序清单18.1 MarcoHandler处理通过WebSocket传送的文本消息
1 | package marcopolo;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.web.socket.TextMessage;import org.springframework.web.socket.WebSocketSession;import org.springframework.web.socket.handler.AbstractWebSocketHandler;public class MarcoHandler extends AbstractWebSocketHandler { private static final Logger logger = LoggerFactory.getLogger(MarcoHandler.class); protected void handleTextMessage(WebSocketSession session, TextMessage message) throws Exception { logger.info("Received message: " + message.getPayload()); Thread.sleep(2000); session.sendMessage(new TextMessage("Polo!")); }} |
尽管AbstractWebSocketHandler是一个抽象类,但是它并不要求我们必须重载任何特定的方法。相反,它让我们来决定该重载哪一个方法。除了重载WebSocketHandler中所定义的五个方法以外,我们还可以重载AbstractWebSocketHandler中所定义的三个方法:
- handleBinaryMessage()
- handlePongMessage()
- handleTextMessage()
这三个方法只是handleMessage()方法的具体化,每个方法对应于某一种特定类型的消息。
因为MarcoHandler将会处理文本类型的“Marco!”消息,因此我们应该重载handleTextMessage()方法。当有文本消息抵达的时候,日志会记录消息内容,在两秒钟的模拟延迟之后,在同一个连接上返回另外一条文本消息。
MarcoHandler所没有重载的方法都由AbstractWebSocketHandler以空操作的方式(no-op)进行了实现。这意味着MarcoHandler也能处理二进制和pong消息,只是对这些消息不进行任何操作而已。
另外一种方案,我们可以扩展TextWebSocketHandler,不再扩展Abstract-WebSocketHandler:
1 | public class MarcoHandler extends TextWebSocketHandler { ...} |
TextWebSocketHandler是AbstractWebSocketHandler的子类,它会拒绝处理二进制消息。它重载了handleBinaryMessage()方法,如果收到二进制消息的时候,将会关闭WebSocket连接。与之类似,BinaryWebSocketHandler也是AbstractWeb-SocketHandler的子类,它重载了handleTextMessage()方法,如果接收到文本消息的话,将会关闭连接。
尽管你会关心如何处理文本消息或二进制消息,或者二者兼而有之,但是你可能还会对建立和关闭连接感兴趣。在本例中,我们可以重载afterConnectionEstablished()和afterConnectionClosed():
1 | public void afterConnectionEstablished(WebSocketSession session) throws Exception { logger.info("Connection established");}public void afterConnectionClosed(WebSocketSession session, CloseStatus closeStatus) throws Exception { logger.info("Connection closed. Status: " + status);} |
我们通过afterConnectionEstablished()和afterConnectionClosed()方法记录了连接信息。当新连接建立的时候,会调用afterConnectionEstablished()方法,类似
地,当连接关闭时,会调用afterConnectionClosed()方法。在本例中,连接事件仅仅记录了日志,但是如果我们想在连接的生命周期上建立或销毁资源时,这些方法会很有用。
注意,这些方法都是以“after”开头。这意味着,这些事件只能在事件发生后才产生响应,因此并不能改变结果。
现在,已经有了消息处理器类,我们必须要对其进行配置,这样Spring才能将消息转发给它。在Spring的Java配置中,这需要在一个配置类上使用@EnableWebSocket,并实现WebSocketConfigurer接口,如下面的程序清单所示。
程序清单18.2 在Java配置中,启用WebSocket并映射消息处理器
1 | package marcopolo;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.web.socket.config.annotation.EnableWebSocket;import org.springframework.web.socket.config.annotation.WebSocketConfigurer;import org.springframework.web.socket.config.annotation.WebSocketHandlerRegistry; class WebSocketConfig implements WebSocketConfigurer { public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) { registry.addHandler(marcoHandler(), "/marco"); } public MarcoHandler marcoHandler() { return new MarcoHandler(); }} |
registerWebSocketHandlers()方法是注册消息处理器的关键。通过重载该方法,我们得到了一个WebSocketHandlerRegistry对象,通过该对象可以调用addHandler()来注册信息处理器。在本例中,我们注册了MarcoHandler(以bean的方式进行声明)并将其与“/marco”路径相关联。
另外,如果你更喜欢使用XML来配置Spring的话,那么可以使用websocket命名空间:
程序清单18.3 借助websocket命名空间以XML的方式配置WebSocket
1 | <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:websocket="http://www.springframework.org/schema/websocket" xsi:schemaLocation=" http://www.springframework.org/schema/websocket http://www.springframework.org/schema/websocket/spring-websocket.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <websocket:handlers> <websocket:mapping handler="marcoHandler" paths="/marco" /> </websocket:handlers> <bean id="marcoHandler" class="marcopolo.MarcoHandler" /></beans> |
不管使用Java还是使用XML,这就是所需的配置。
现在,我们可以把注意力转向客户端,它会发送“Marco!”文本消息到服务器,并监听来自服务器的文本消息。如下程序清单所展示的JavaScript代码开启了一个原始的WebSocket并使用它来发送消息给服务器。
程序清单18.4 连接到“marco” WebSocket的JavaScript客户端
1 | var url = 'ws://' + window.location.host + '/websocket/marco';var sock = new WebSocket(url);sock.onopen = function() { console.log('Opening'); sayMarco();};sock.onmessage = function(e) { console.log('Received message: ', e.data); setTimeout(function(){ sayMarco() }, 2000);};sock.onclose = function() { console.log('Closing');};function sayMarco() { console.log('Sending Marco!'); sock.send{"Marco!");} |
在程序清单18.4的代码中,所做的第一件事情就是创建WebSocket实例。对于支持WebSocket的浏览器来说,这个类型是原生的。通过创建WebSocket实例,实际上打开了到给定URL的WebSocket。在本例中,URL使用了“ws://”前缀,表明这是一个基本的WebSocket连接。如果是安全WebSocket的话,协议的前缀将会是“wss://”。
WebSocket创建完毕之后,接下来的代码建立了WebSocket的事件处理功能。注意,WebSocket的onopen、onmessage和onclose事件对应于MarcoHandler的afterConnectionEstablished()、handleTextMessage()和afterConnectionClosed()方法。在onopen事件中,设置了一个函数,它会调用sayMarco()方法,在该WebSocket上发送“Marco!”消息。通过发送“Marco!”,这个无休止的Marco Polo游戏就开始了,因为服务器端的MarcoHandler作为响应会将“Polo!”发送回来,当客户端收到来自服务器的消息后,onmessage事件会发送另外一个“Marco!”给服务器。
这个过程会一直持续下去,直到连接关闭。在程序清单18.4中所没有展示的是如果调用sock.close()的话,将会结束这个疯狂的游戏。在服务端也可以关闭连接,或者浏览器转向其他的页面,都会关闭连接。如果发生以上任意的场景,只要连接关闭,都会触发onclose事件。在这里,出现这种情况将会在控制台日志上记录一条信息。
到此为止,我们已经编写完使用Spring低层级WebSocket API的所有代码,包括接收和发送消息的处理器类,以及在浏览器端完成相同功能的JavaScript客户端。如果我们构建这些代码并将其部署到Servlet容器中,那它有可能能够正常运行。
从我选择“可能”这个词,你是不是能够感觉到这里有一点悲观的情绪?这是因为我不能保证它可以正常运行。实际上,它很有可能运行不起来。即便把所有的事情都做对了,诡异的事情依然会困扰我们。
让我们看一下都有什么事情会阻止WebSocket正常运行,并采取一些措施提高成功的几率。
应对不支持WebSocket的场景
WebSocket是一个相对比较新的规范。虽然它早在2011年底就实现了规范化,但即便如此,在Web浏览器和应用服务器上依然没有得到一致的支持。Firefox和Chrome早就已经完整支持WebSocket了,但是其他的一些浏览器刚刚开始支持WebSocket。如下列出了几个流行的浏览器支持WebSocket功能的最低版本:
- Internet Explorer:10.0
- Firefox: 4.0(部分支持),6.0(完整支持)。
- Chrome: 4.0(部分支持),13.0(完整支持)。
- Safari: 5.0(部分支持),6.0(完整支持)。
- Opera: 11.0(部分支持),12.10(完整支持)。
- iOS Safari: 4.2(部分支持),6.0(完整支持)。
- Android Browser: 4.4。
令人遗憾的是,很多的网上冲浪者并没有认识到或理解新Web浏览器的特性,因此升级很慢。另外,有的公司规定使用特定版本的浏览器,这样它们的员工很难(或不可能)使用更新的浏览器。鉴于这些情况,如果你的应用程序使用WebSocket的话,用户可能会无法使用。
服务器端对WebSocket的支持也好不到哪里去。GlassFish在几年前就开始支持一定形式的WebSocket,但是很多其他的应用服务器在最近的版本中刚刚开始支持WebSocket。例如,我在测试上述例子的时候,所使用的就是Tomcat 8的发布候选构建版本。
即便浏览器和应用服务器的版本都符合要求,两端都支持WebSocket,在这两者之间还有可能出现问题。防火墙代理通常会限制所有除HTTP以外的流量。它们有可能不支持或者(还)没有配置允许进行WebSocket通信。
在当前的WebSocket领域,我也许描述了一个很阴暗的前景。但是,不要因为这一些不支持,你就停止使用WebSocket的功能。当它能够正常使用的时候,WebSocket是一项非常棒的技术,但是如果它无法得到支持的话,我们所需要的仅仅是一种备用方案(fallback plan)。
幸好,提到WebSocket的备用方案,这恰是SockJS所擅长的。SockJS是WebSocket技术的一种模拟,在表面上,它尽可能对应WebSocket API,但是在底层它非常智能,如果WebSocket技术不可用的话,就会选择另外的通信方式。SockJS会优先选用WebSocket,但是如果WebSocket不可用的话,它将会从如下的方案中挑选最优的可行方案:
- XHR流。
- XDR流。
- iFrame事件源。
- iFrame HTML文件。
- XHR轮询。
- XDR轮询。
- iFrame XHR轮询。
- JSONP轮询。
好消息是在使用SockJS之前,我们并没有必要全部了解这些方案。SockJS让我们能够使用统一的编程模型,就好像在各个层面都完整支持WebSocket一样,SockJS在底层会提供备用方案。
例如,为了在服务端启用SockJS通信,我们在Spring配置中可以很简单地要求添加该功能。重新回顾一下程序清单18.2中的registerWebSocketHandlers()方法,稍微加一点内容就能启用SockJS:
1 | void registerWebSocketHandlers(WebSocketHandlerRegistry registry) { registry.addHandler(marcoHandler(), "/marco").withSockJS();} |
addHandler()方法会返回WebSocketHandlerRegistration,通过简单地调用其withSockJS()方法就能声明我们想要使用SockJS功能,如果WebSocket不可用的话,SockJS的备用方案就会发挥作用。
如果你使用XML来配置Spring的话,启用SockJS只需在配置中添加<websocket:sockjs>元素即可:
1 | <websocket:handlers> <websocket:mapping handler="marcoHandler" path="/marco" /> <websocket:sockjs /></websocket:handlers> |
要在客户端使用SockJS,需要确保加载了SockJS客户端库。具体的做法在很大程度上依赖于使用JavaScript模块加载器(如require.js或curl.js)还是简单地使用